- PHP Кодировка страницы
- Кодировки скриптов (шаг 1)
- Кодировка таблиц MySQL. (шаг 2)
- Кодировка самой HTML страницы. (Шаг 3)
- Локаль используемая браузером пользователя. (Шаг 4)
- Читайте также похожие статьи:
- Как задать кодировку в htaccess
- Комментарии ( 14 ):
- Базы Данных. Кодировка ввода/вывода.
- Определение кодировки текста в PHP вместо mb_detect_encoding
- Методика тестирования
PHP Кодировка страницы

Здравствуй уважаемый читатель блога LifeExample, кодировка веб страницы это очень интересный зверь, и за частую хищный для начинающих веб мастеров. Я уверен в том, что все новички сталкиваются с проблемой правильного отображения текста на страницах своего сайта. Ты дорогой читатель, наверное встречал в сети интернета ресурсы, на страницах которых отображался не читаемый текст, а кракозябры.
Кракозябрами в среде программирования веб сайтов принято называть символы не соответствующие тем, которые должны быть выведены на страницу. Например, на созданной вами странице должно отображаться приветствие: «Здравствуй читатель моего блога!», а на деле получаете непонятный набор закорючек «Р—РґСЂР°РІСЃС‚РІСѓР№ читатеРСЊ моего Р±РРѕРіР°!» – вот такие закорючки и есть злые КРАКОЗЯБРЫ.
В данной статье мы разберем эту проблему с ног до головы, чтобы больше не возвращаться к танцам с бубном вокруг нечитаемого текста.
И так, чтобы понять откуда появляются подобного рода иероглифы, нам нужно познакомиться с понятием кодировка страницы. Любой текст на компьютере представляется в виде набора байтов, в каждом из этих байтов определенным кодом — закодирован только один единственный символ. Так вот для того чтобы правильно расшифровать или раскодировать набор байтов и представить его в понятном человеку виде, браузеру нужно провести соответствие с одной из кодовых таблиц. Базовой кодировкой является ASCII кодировка, она содержит в себе коды 128 символов латинского алфавита и спец символов вроде скобок и решеток. Именно из ASCII появились первые русскосимвольные кодировки CP866 и KOI8-R, а из них вышла известная сегодняшним вебмастерам кодировка windows-1251. Не смотря на то, что все эти кодировки призваны для отображения русского текста, они все отличаются друг от друга кодами для одинаковых символов. Если текст писался в кодировке CP866, а браузер пытается раскодировать ее с помощью таблицы кодов windows-1251, то в результате мы получим не читаемые слова. Такое часто происходит при отправке сообщений через почтовый сервер.
Приведенные здесь названия кодировок далеко не все что существуют и используются в разных случаях, их намного больше чем вы думаете. С таким обилием кодовых таблиц образовалась проблема совместимости кодировок, и веб мастерам пришлось вставть на борьду с универсализацией кода, что занимало много времени и нервов. На сегодняшний день изобретена панацея для данной проблемы в виде универсальной кодировки utf-8, со временем она вытесняет используемые ранее кодовые таблицы символов, и сейчас уже не для кого не встает вопрос о том в какой кодировке лучше сохранять данные.
Много было сказано относительно эволюции кодировок, и постановке самой задачи, пришло время поговорить о практических моментах.
Существует четыре места на кухне программирования сайта, которые требуют соблюдения единого стандатра кодирования текста.
- Кодировки скриптов.
- Кодировка таблиц MySQL.
- Кодировка самой HTML страницы.
- Локаль используемая браузером пользователя.
Во всех этих составляющих сайта, должна использоваться единая кодировка, какая – решать вам, но я рекомендую utf-8, всетаки она универсальная)
И так теперь подробнее рассмотрим, что нужно сделать для того, чтобы привести к одной кодировке всеперечисленые составляющие.
Кодировки скриптов (шаг 1)
Для того чтобы все скрипты имели одну кодировку, нужно при создании нового скрипта указать желаемую кодировку в настройках вашего редактора. Приведу пример данной процедуры в NotePad++ . При создании нового PHP файла сразу идем в раздел Encoding, он находится в меню, и выбираем Convert to UTF-8 without BOM.
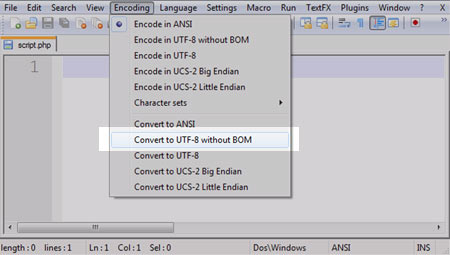
Выбираем именно Convert to UTF-8 without BOM, а не просто Convert to UTF‑8. Приставка without BOM означает то что в первых двух байтах файла будет зашифрована специальная информация о параметре кодировки, в скриптах нам не нужна никакая лишняя информация. В большенстве случаев сохранение с BOM не окажется криминальным, но когданить один из скриптов откажется правильно работать и одной из причин может отазаться именно информация заключенная в первых байтах файла.
Кодировка таблиц MySQL. (шаг 2)
Для того, чтобы узнать какие кодировки используются в ваше MySQL базе, воспользуемся интерфейсом phpMyAdmin. В разделе SQL напишем запрос:
Выглядеть это должно вот так:
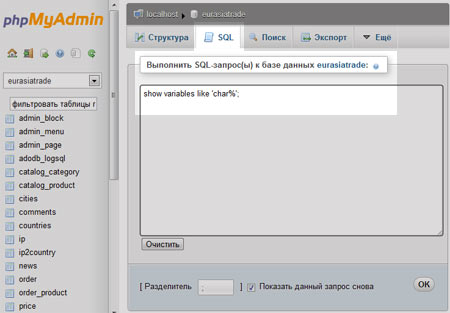
Жмем ОК и получаем информацию о кодировках таблицы
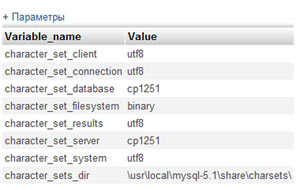
Значения на против character_set_client и character_set_results должны совпадать, так как эти параметры отвечают за кодировку, в которой данные поступают в базу и за кодировку в которой данные берутся из базы.
Если они у вас различаются, то нужно в PHP коде в ручную установить нужную кодировку. Делается это вот такой строчкой:
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение utf8.
Подробнее о том как с помощью PHP работать с базой данных можно прочесть в статье PHP работа с базой данных (Часть 1-3).
Кодировка самой HTML страницы. (Шаг 3)
Теперь данные взятые с базы и данные обрабатываемые в php скрипте, будут совпадать по кодировке, и выводиться в понятном для человека тексте. Но это еще не все, нужно указать кодировку в разделе для мета тегов:
Либо в cкрипте настроек php командой:
Если кодировка HTML будет задана сразу двумя способами, то приоритетным будет задание кодировки из php скрипта.
Также можно глобально задать правило кодировки HTML в файле .htaccess добавив в него строку:
Локаль используемая браузером пользователя. (Шаг 4)
Еще одна важная деталь при корректном отображении текста это установка локали:
При установки такой локали, пердставители других стран использующие другую кодовую страницу в своей операционной системе, будут видеть русский текст.
Мы рассмотрели основные моменты возникновения противоречий в кодировках веб страницы, подведем итоги. Для того чтобы ваш рускоязычный сайт был всегда доступен для чтения, необходимо прописать в PHP скрипте настроек такие строки:
Если у тебя дорогой читатель остались вопросы по данной статье о PHP кодировке страниц, то смело задавай их в комментариях.
Читайте также похожие статьи:

Чтобы не пропустить публикацию следующей статьи подписывайтесь на рассылку по E-mail или RSS ленту блога.
Как задать кодировку в htaccess

Одна из самых частых проблем сайта — это его кодировка. И несмотря на это многие Web-мастера продолжают утверждать, что браузер сам выбирает кодировку. Действительно, он выбирает кодировку сам, но делает это не всегда правильно. Вот это и есть самая распространнёная ошибка с кодировкой: сайт в кодировке, допустим, UTF-8, а браузер настойчиво выбирает windows-1251. Вот как задать жёстко кодировку через файл htaccess, я расскажу в этой небольшой статье.
Для того, чтобы задать кодировку файла в htaccess достаточно написать в нём всего одну строчку:
Если Вам нужна windows-1251, то тогда так:
Всего одна строчка и теперь браузер, независимо от своего предпочтения, будет выбирать указанную кодировку. Сразу говорю, данный способ — это действительно мощный. Вы должны понимать, что раз браузер неправильно распознаёт кодировку Вашего сайта (игнорируя даже мета-тег «ContentType«), значит, на то есть свои причины, поэтому внимательно проверьте: везде ли всё хорошо отображается.
Надеюсь, что этой статьей я помог Вам решить проблему с кодировкой. А в следующей статье я расскажу о проблеме, связанной с кодировкой базы данных. Это тоже весьма частая проблема, которую многие не могут решить.

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Она выглядит вот так:
Комментарии ( 14 ):
Фух норм инструкция, а то вроде все UTF 8, а браузер кракозябры показывает
Базы Данных. Кодировка ввода/вывода.
Кодировка, в которой нужно вывести посетителю данные. Она может отличаться от кодировки файла. Главное помнить: если кодировка вывода отличается от кодировки файла, то и выводимые данные также должны быть перекодированы в эту кодировку( кодировку отправляемого заголовка, проще говоря ). Я не сторонник подобного. Лучше сразу указывать одну кодировку, что бы не тратить время еще и на перекодировку в самом скрипте.
И работает значительно быстрее. Но появилась она только в PHP 5.2.3 и поддерживается MySQL сервером с версией >= 5.0.7. Если используете эту функцию, то подобные запросы можно не отправлять. В эту функцию передается та кодировка, которая указывается в отправляемом заголовке( если есть ) или кодировка самого файла( если такого заголовка нет ). Если кодировка файла и таблицы в БД совпадает, то использовать эту функцию( как и заголовки выше ) нет смысла. Так же хочу обратить внимание читателя на то, что при работе с БД кодировка пишется без дефиса( utf8 ). Будьте внимательны, если не верно указать кодировку, то вывод будет состоять из вопросиков ( . ).
БазЫ данных (кодировка)
Поставил кодировку UTF-8 , но русские буквы не появились. Помогите исправит файл.
Кодировка при выводе данных из базы
Помогите пожалуйста решить проблему. У меня есть база данных, которую мне нужно привязать к.
Кодировка при получении данных из базы PHPBB3
Доброго всем времени суток! Есть форум на движке PHPBB3 и есть сайт, пытаюсь на сайте разместить.
Не работает выборка информации из базы данных. Неправильная кодировка
Здравствуйте. Некорректно работает выборка информации из базы данных (с помощью PHP). Проблема в.
Хотелось бы ещё кое что сказать про кодировку.
Если у вас выводится текст из базы вот так
Краткая
Значит у вас соединение с БД работает в кодировке UTF-8, а страница открыта в браузере в кодировке cp1251.
Решение:
-либо сохраните страницы в кодировке UTF-8 без BOM и укажите в .htacces для сервера apache кодировку
Это позволить сайту работать в UTF-8 кодировке.
-либо выполните запрос в бд сразу после соединения
Это позволит работать сайту в кодировке windows-1251.
Если из базы выводится текст так
�������
то всё с точностью до наоборот 
Предпочтительней работать в кодировке UTF-8.
Например вы захотите использовать AJAX, но в некоторых браухерах он работает только с кодировкой UTF-8.
Или функцию json_encode — она тоже работает с кодировкой UTF-8.
Так же в XML лучше использовать эту кодировку.
Если же у вас такой вывод:
.
Это скорей всего означает что данных в таблице в кириллице нет вообще.
Часто это из за того, что по умолчанию в MySQL используется кодировка latin1.
И если создать таблицу без явного указания другой кодировки, то она будет создана в latin1. А данная кодировка вообще не работает с кириллицей.
Посмотрите что выводит запрос
Определение кодировки текста в PHP вместо mb_detect_encoding
Существует несколько кодировок символов кириллицы.
При создании сайтов в Интернете обычно используют:
- utf-8
- windows-1251
- koi8-r
Еще популярные кодировки:
- iso-8859-5
- ibm866
- mac-cyrillic
Вероятно это не весь список, это те кодировки с которыми я часто сталкиваюсь.
Иногда появляется необходимость определить кодировку текста. И в PHP даже функция для этого есть:
Я протестировал функцию определения кодировки по кодам символов, результат меня удовлетворил и я использовал эту функцию пару лет.
Недавно решил переписать проект где использовал эту функцию, нашел готовый пакет на packagist.org cnpait/detect_encoding, в котором кодировка определяется методом m00t
При этом указанный пакет был установлен более 1200 раз, значит не у меня одного периодически возникает задача определения кодировки текста.
Мне бы установить этот пакет и успокоиться, но я решил «заморочиться».
В общем, сделал свой пакет: onnov/detect-encoding.
Как его использовать написано в README.md
А о его тестировании и сравнении с пакетом cnpait/detect_encoding напишу.
Методика тестирования
Берем большой текст: Tolstoy — Anna Karenina
Всего — 1’701’480 знаков
Убираем все лишнее, оставляем только кириллицу:
Осталось 1’336’252 кирилистических знаков.
В цикле берем часть текста (5, 15, 30,… символов) преобразуем в известную кодировку и пытаемся определить кодировку скриптом. Затем сравниваем правильно или нет.
Вот таблица в которой слева кодировки, сверху количество символов по которому определяем кодировку, в таблице результат достоверности в %%
| letters -> | 5 | 15 | 30 | 60 | 120 | 180 | 270 |
|---|---|---|---|---|---|---|---|
| windows-1251 | 99.13 | 98.83 | 98.54 | 99.04 | 99.73 | 99.93 | 100.0 |
| koi8-r | 99.89 | 99.98 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| iso-8859-5 | 81.79 | 99.27 | 99.98 | 100.0 | 100.0 | 100.0 | 100.0 |
| ibm866 | 99.81 | 99.99 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| mac-cyrillic | 12.79 | 47.49 | 73.48 | 92.15 | 99.30 | 99.94 | 100.0 |
Наихудшая точность с мак-кириллицей, вам нужно как минимум 60 символов, чтобы определить эту кодировку с точностью 92,15%. Кодировка Windows-1251 также имеет очень низкую точность. Это связано с тем, что номера их символов в таблицах сильно пересекаются.
К счастью, кодировки mac-cyrillic и ibm866 не используются для кодирования веб-страниц.
Попробуем без них:
| letters -> | 5 | 10 | 15 | 30 | 60 |
|---|---|---|---|---|---|
| windows-1251 | 99.40 | 99.69 | 99.86 | 99.97 | 100.0 |
| koi8-r | 99.89 | 99.98 | 99.98 | 100.0 | 100.0 |
| iso-8859-5 | 81.79 | 96.41 | 99.27 | 99.98 | 100.0 |
Точность определения высока даже в коротких предложениях от 5 до 10 букв. А для фраз из 60 букв точность определения достигает 100%. А еще, определение кодировки выполняется очень быстро, например, текст длиной более 1 300 000 символов кириллицы проверяется за 0.00096 секунд. (на моем компьютере)
А какие результаты покажет статистический способ описанный m00t:
| letters -> | 5 | 10 | 15 | 30 | 60 |
|---|---|---|---|---|---|
| windows-1251 | 88.75 | 96.62 | 98.43 | 99.90 | 100.0 |
| koi8-r | 85.15 | 95.71 | 97.96 | 99.91 | 100.0 |
| iso-8859-5 | 88.60 | 96.77 | 98.58 | 99.93 | 100.0 |
Как видим результаты определения кодировки хорошие. Скорость работы скрипта высокая, особенно на коротких текстах, на огромных текстах скорость значительно уступает. Текст длиной более 1 300 000 символов кириллицы проверяется за 0.32 секунд. (на моем компьютере).



