- Определение кодировки страницы сайта. Чтение страницы сайта и преобразование в UTF-8 или в Windows-1251
- Кодировка windows 1251 в сайтостроении
- Кодировка windows 1251 в html
- Кодировка windows 1251 в PHP
- Кодировка windows 1251 в htaccess
- PHP Кодировка страницы
- Кодировки скриптов (шаг 1)
- Кодировка таблиц MySQL. (шаг 2)
- Кодировка самой HTML страницы. (Шаг 3)
- Локаль используемая браузером пользователя. (Шаг 4)
- Читайте также похожие статьи:
- html_entity_decode
- Описание
- Список параметров
Определение кодировки страницы сайта.
Чтение страницы сайта и преобразование в UTF-8 или в Windows-1251
При формированнии карт сайтов с помощью сервиса периодически сталкивался с проблемами некорректного указания кодировки страницы или неуказания кодовой страницы вообще. В настоящий момент у меня работает функция анализа кодовой страницы похожая на представленную ниже.
Представленный ниже пример читает страницу, преобразует её в UTF-8, загружает в DOM-объект, получает из него title и выводит его в кодировке windows-1251.
PHP анализ и обработка:
Приведенный пример упрощен и не содержит обработку «трудных» случаев. Полный пример дополнительно:
- понимает, когда кодовая страница в header указанна одна, а в META другая
- содержит обработку двойных мета с разными кодовыми страницами(и такое у меня попадалось)
- «борется» с кривыми страницами
- умеет читать страницы по https даже с «кривыми» и самоподписанными сертификатами
Представленный полный код будет корректно работать на 99% страниц/сайтов в рунете.
Всего за 250 рублей (
3$) Вы можете приобрести готовый скрипт получения кодовой страницы. Код скрипта реализован на PHP, полностью открытый и не использует никаких дополнительных библиотек.
- Соглашение по использованию платной версии:
- Вы можете использовать полученный код в любых своих разработках, вы не обязаны указывать ссылку на источник.
- Вы НЕ имеете права перепродавать её, размещать в свободном или ограниченном доступе, а также публиковать в любом виде.
- Все остальные права сохраняются за автором.
РегистрацияВойти
Войти через VKВойти через FBВойти через GoogleВойти через Яндекс
Кодировка windows 1251 в сайтостроении
Кодировка windows 1251 была создана в начале 90 годов для русификации программных продуктов, выпускаемых корпорацией Microsoft :

- 0xFF (25510) – это код, который зарезервирован для символа «я». В программах, которые не поддерживают чистый 8-ой бит, часто возникают непредсказуемые проблемы;
- Нет псевдографики, которая присутствует в KOI8 , CP866 .
Ниже приведены символы из Code Page 1251 или сокращенно СР1251 ( числа под символами являются кодом в шестнадцатеричной системе такого же символа в Юникоде ):

Кодировка windows 1251 в html
Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина « кодировка страницы ».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:

— между тегом и закрывающим его нужно прописать — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Кодировка windows 1251 в PHP
Ни для кого не является тайной, что генерация страниц проходит путем выборки и использования какой-то части информации, которая хранится в базе данных. При написании сайта на PHP , чаще всего это mysql :

Для согласования расшифровки необходимо выполнить функцию mysql_query(«SET NAMES cp1251») – это означает, что преобразование из машинного кода будет осуществляться согласно таблице cp1251 .
Кодировка windows 1251 в htaccess
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
Для того чтобы для веб-ресурса была задана кодировка виндовс-1251 , необходимо найти ( или создать ) файл .htaccess . Это файл, который хранит в себе дополнительные настройки и описания конфигураций web-сервера.
В нем для установки кодировки следует прописать следующие строки:
- DefaultLanguage ru;
- AddDefaultCharset windows-1251;
- php_value default_charset «cp1251».
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка. Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов.
PHP Кодировка страницы

Здравствуй уважаемый читатель блога LifeExample, кодировка веб страницы это очень интересный зверь, и за частую хищный для начинающих веб мастеров. Я уверен в том, что все новички сталкиваются с проблемой правильного отображения текста на страницах своего сайта. Ты дорогой читатель, наверное встречал в сети интернета ресурсы, на страницах которых отображался не читаемый текст, а кракозябры.
Кракозябрами в среде программирования веб сайтов принято называть символы не соответствующие тем, которые должны быть выведены на страницу. Например, на созданной вами странице должно отображаться приветствие: «Здравствуй читатель моего блога!», а на деле получаете непонятный набор закорючек «Р—РґСЂР°РІСЃС‚РІСѓР№ читатеРСЊ моего Р±РРѕРіР°!» – вот такие закорючки и есть злые КРАКОЗЯБРЫ.
В данной статье мы разберем эту проблему с ног до головы, чтобы больше не возвращаться к танцам с бубном вокруг нечитаемого текста.
И так, чтобы понять откуда появляются подобного рода иероглифы, нам нужно познакомиться с понятием кодировка страницы. Любой текст на компьютере представляется в виде набора байтов, в каждом из этих байтов определенным кодом — закодирован только один единственный символ. Так вот для того чтобы правильно расшифровать или раскодировать набор байтов и представить его в понятном человеку виде, браузеру нужно провести соответствие с одной из кодовых таблиц. Базовой кодировкой является ASCII кодировка, она содержит в себе коды 128 символов латинского алфавита и спец символов вроде скобок и решеток. Именно из ASCII появились первые русскосимвольные кодировки CP866 и KOI8-R, а из них вышла известная сегодняшним вебмастерам кодировка windows-1251. Не смотря на то, что все эти кодировки призваны для отображения русского текста, они все отличаются друг от друга кодами для одинаковых символов. Если текст писался в кодировке CP866, а браузер пытается раскодировать ее с помощью таблицы кодов windows-1251, то в результате мы получим не читаемые слова. Такое часто происходит при отправке сообщений через почтовый сервер.
Приведенные здесь названия кодировок далеко не все что существуют и используются в разных случаях, их намного больше чем вы думаете. С таким обилием кодовых таблиц образовалась проблема совместимости кодировок, и веб мастерам пришлось вставть на борьду с универсализацией кода, что занимало много времени и нервов. На сегодняшний день изобретена панацея для данной проблемы в виде универсальной кодировки utf-8, со временем она вытесняет используемые ранее кодовые таблицы символов, и сейчас уже не для кого не встает вопрос о том в какой кодировке лучше сохранять данные.
Много было сказано относительно эволюции кодировок, и постановке самой задачи, пришло время поговорить о практических моментах.
Существует четыре места на кухне программирования сайта, которые требуют соблюдения единого стандатра кодирования текста.
- Кодировки скриптов.
- Кодировка таблиц MySQL.
- Кодировка самой HTML страницы.
- Локаль используемая браузером пользователя.
Во всех этих составляющих сайта, должна использоваться единая кодировка, какая – решать вам, но я рекомендую utf-8, всетаки она универсальная)
И так теперь подробнее рассмотрим, что нужно сделать для того, чтобы привести к одной кодировке всеперечисленые составляющие.
Кодировки скриптов (шаг 1)
Для того чтобы все скрипты имели одну кодировку, нужно при создании нового скрипта указать желаемую кодировку в настройках вашего редактора. Приведу пример данной процедуры в NotePad++ . При создании нового PHP файла сразу идем в раздел Encoding, он находится в меню, и выбираем Convert to UTF-8 without BOM.
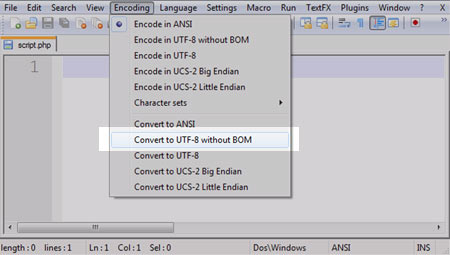
Выбираем именно Convert to UTF-8 without BOM, а не просто Convert to UTF‑8. Приставка without BOM означает то что в первых двух байтах файла будет зашифрована специальная информация о параметре кодировки, в скриптах нам не нужна никакая лишняя информация. В большенстве случаев сохранение с BOM не окажется криминальным, но когданить один из скриптов откажется правильно работать и одной из причин может отазаться именно информация заключенная в первых байтах файла.
Кодировка таблиц MySQL. (шаг 2)
Для того, чтобы узнать какие кодировки используются в ваше MySQL базе, воспользуемся интерфейсом phpMyAdmin. В разделе SQL напишем запрос:
Выглядеть это должно вот так:
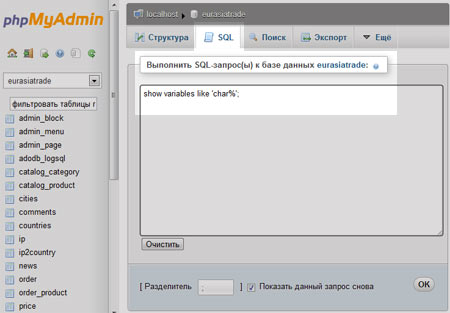
Жмем ОК и получаем информацию о кодировках таблицы
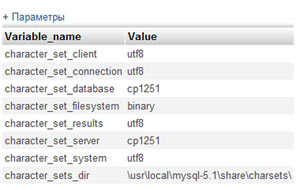
Значения на против character_set_client и character_set_results должны совпадать, так как эти параметры отвечают за кодировку, в которой данные поступают в базу и за кодировку в которой данные берутся из базы.
Если они у вас различаются, то нужно в PHP коде в ручную установить нужную кодировку. Делается это вот такой строчкой:
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение utf8.
Подробнее о том как с помощью PHP работать с базой данных можно прочесть в статье PHP работа с базой данных (Часть 1-3).
Кодировка самой HTML страницы. (Шаг 3)
Теперь данные взятые с базы и данные обрабатываемые в php скрипте, будут совпадать по кодировке, и выводиться в понятном для человека тексте. Но это еще не все, нужно указать кодировку в разделе для мета тегов:
Либо в cкрипте настроек php командой:
Если кодировка HTML будет задана сразу двумя способами, то приоритетным будет задание кодировки из php скрипта.
Также можно глобально задать правило кодировки HTML в файле .htaccess добавив в него строку:
Локаль используемая браузером пользователя. (Шаг 4)
Еще одна важная деталь при корректном отображении текста это установка локали:
При установки такой локали, пердставители других стран использующие другую кодовую страницу в своей операционной системе, будут видеть русский текст.
Мы рассмотрели основные моменты возникновения противоречий в кодировках веб страницы, подведем итоги. Для того чтобы ваш рускоязычный сайт был всегда доступен для чтения, необходимо прописать в PHP скрипте настроек такие строки:
Если у тебя дорогой читатель остались вопросы по данной статье о PHP кодировке страниц, то смело задавай их в комментариях.
Читайте также похожие статьи:

Чтобы не пропустить публикацию следующей статьи подписывайтесь на рассылку по E-mail или RSS ленту блога.
html_entity_decode
(PHP 4 >= 4.3.0, PHP 5, PHP 7, PHP 8)
html_entity_decode — Преобразует HTML-сущности в соответствующие им символы
Описание
html_entity_decode() является противоположностью функции htmlentities() . Она преобразует HTML-сущности в строке string в соответствующие им символы.
Если быть точнее, то эта функция преобразует все сущности (в том числе все числовые сущности), которые а) обязательно верны для выбранного типа документа — то есть, для XML эта функция не преобразует именованные сущности, которые могут быть определены в каком-нибудь DTD — и б) их символы находятся в кодировке, соответствующей выбранной и разрешены в выбранном типе документа. Все другие сущности остаются без изменений.
Список параметров
Битовая маска, состоящая из одного или более флагов, которые указывают, как обращаться с кавычками и какой тип документа использовать. По умолчанию маска принимает значение ENT_COMPAT | ENT_HTML401 .
| Имя константы | Описание |
|---|---|
| ENT_COMPAT | Преобразуются двойные кавычки, одинарные остаются без изменений. |
| ENT_QUOTES | Преобразуются и двойные, и одинарные кавычки. |
| ENT_NOQUOTES | Оставить как двойные, так и одинарные кавычки без изменений. |
| ENT_HTML401 | Обрабатывать код как HTML 4.01. |
| ENT_XML1 | Обрабатывать код как XML 1. |
| ENT_XHTML | Обрабатывать код как XHTML. |
| ENT_HTML5 | Обрабатывать код как HTML 5. |
Необязательный аргумент, определяющий кодировку, используемую при конвертации символов.
Если не указан, то значение по умолчанию для encoding зависит от конфигурационной опции default_charset.
Хотя этот аргумент является технически необязательным, настоятельно рекомендуется указать правильное значение для вашего кода, опция конфигурации default_charset может быть задана неверно для входных данных.
Поддерживаются следующие кодировки:
| Кодировка | Псевдонимы | Описание |
|---|---|---|
| ISO-8859-1 | ISO8859-1 | Западно-европейская Latin-1. |
| ISO-8859-5 | ISO8859-5 | Редко используемая кириллическая кодировка (Latin/Cyrillic). |
| ISO-8859-15 | ISO8859-15 | Западно-европейская Latin-9. Добавляет знак евро, французские и финские буквы к кодировке Latin-1 (ISO-8859-1). |
| UTF-8 | 8-битная Unicode, совместимая с ASCII. | |
| cp866 | ibm866, 866 | Кириллическая кодировка, применяемая в DOS. |
| cp1251 | Windows-1251, win-1251, 1251 | Кириллическая кодировка, применяемая в Windows. |
| cp1252 | Windows-1252, 1252 | Западно-европейская кодировка, применяемая в Windows. |
| KOI8-R | koi8-ru, koi8r | Русская кодировка. |
| BIG5 | 950 | Традиционный китайский, применяется в основном на Тайване. |
| GB2312 | 936 | Упрощённый китайский, стандартная национальная кодировка. |
| BIG5-HKSCS | Расширенная Big5, применяемая в Гонконге. | |
| Shift_JIS | SJIS, SJIS-win, cp932, 932 | Японская кодировка. |
| EUC-JP | EUCJP, eucJP-win | Японская кодировка. |
| MacRoman | Кодировка, используемая в Mac OS. | |
| » | Пустая строка активирует режим определения кодировки из файла скрипта (Zend multibyte), default_charset и текущей локали (см. nl_langinfo() и setlocale() ) в указанном порядке. Не рекомендуется к использованию. |
Замечание: Остальные кодировки не поддерживаются, вместо них будет применена кодировка по умолчанию и сгенерировано предупреждение.



