- Python beautifulsoup: установка и использование, примеры
- beautifulsoup4-helpers 0.0.1
- Navigation
- Project links
- Statistics
- Maintainers
- Classifiers
- Project description
- beautifulsoup4-helpers
- Installing
- Examples
- Project details
- Project links
- Statistics
- Maintainers
- Classifiers
- Release history Release notifications | RSS feed
- Download files
- BeautifulSoup4 can’t be installed in python3.5 on Windows7
- Использование библиотеки beautifulsoup в Python
- Введение
- Инструменты
- Реализация
- Сбор заголовков последних технических новостей
- Проверка источника данных
- Извлечение веб-страницы
- Использование BeautifulSoup
- Извлечение заголовка и тела страницы
- Поиск HTML-элементов
- Поиск HTML-элементов по имени класса
- Извлечение текста из HTML-элементов
- Руководство по синтаксическому анализу HTML с помощью BeautifulSoup в Python
- Этический веб-скрапинг
- Обзор Beautiful Soup
- Переход к определенным тегам
- Поиск тегов
- Получение всего текста
- Beautiful Soup в действии — очистка списка книг
- Вывод
Python beautifulsoup: установка и использование, примеры
Прежде всего, создадим виртуальное окружение. Назвать его можно, например, parser
Подробнее о виртуальном окружении и необходимых для его работы пакетах
(parser) admin@desktop:/
В терминале после активации появляется указанное ранее имя.
Как установить beautifulsoup python
BeautifulSoup является частью бибилотеки bs4, парсер также требует requests, все устанавливается через pip из окружения
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1 urllib3-1.23 beautifulsoup4-4.6.3 bs4-0.0.1
Установка завершена, теперь можно перейти к созданию скрипта
Создается объект BeautifulSoup, в скобках указываются два параметра.
Первый — результат применения метода text к содержимому переменной page. Переменная page содержит текст страницы, путь к которой задан.
Второй аргумент — html.parser
С данными далее можно производить любые манипуляции.
Пример форматирования результата полученного с помощью BeautifulSoup
Добавим в скрипт такие строки
Вызов скрипта из консоли
Екатеринбург
Скрипт спарсил главную страницу Яндекса и получил содержимое тега с классом geolink__reg из HTML кода. Класс выбран для демонстрации при визуальном анализе исходного кода (CTRL+U в браузере).
В данном случае в нем находится город, определенный при помощи geoip
Здесь используется метод prettify, который позволяет создавать отформатированное дерево тегов с результатами поиска.
Теперь закомментируем последний print и вместо него
Если вызвать скрипт сейчас можно увидеть, что он отдает только сам контент, в данном случае — имя города.
Екатеринбург
Это достигнуто использованием contents[0], все лишние тэги удалены. Результаты парсинга можно сохранять в csv файлы или обычные текстовые документы. Записывать можно не все, а выбирать только нужное содержимое работая с ним как с текстом.
beautifulsoup4-helpers 0.0.1
pip install beautifulsoup4-helpers Copy PIP instructions
Released: Nov 8, 2020
Frequently used functions for html parsing with beautifulsoup4 https://pypi.org/project/beautifulsoup4/
Navigation
Project links
Statistics
View statistics for this project via Libraries.io, or by using our public dataset on Google BigQuery
License: MIT License (MIT)
Author: eugen1j
Tags python3, beautifulsoup4_helpers, parser, html
Requires: Python >=3.7.0
Maintainers
Classifiers
- Development Status
- 3 — Alpha
- License
- OSI Approved :: MIT License
- Operating System
- MacOS
- Microsoft :: Windows
- Unix
- Programming Language
- Python
- Python :: 3.7
Project description
beautifulsoup4-helpers
Frequently used functions for html parsing with beautifulsoup4
Installing
Examples
See more examples in tests.py
Project details
Project links
Statistics
View statistics for this project via Libraries.io, or by using our public dataset on Google BigQuery
License: MIT License (MIT)
Author: eugen1j
Tags python3, beautifulsoup4_helpers, parser, html
Requires: Python >=3.7.0
Maintainers
Classifiers
- Development Status
- 3 — Alpha
- License
- OSI Approved :: MIT License
- Operating System
- MacOS
- Microsoft :: Windows
- Unix
- Programming Language
- Python
- Python :: 3.7
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you’re not sure which to choose, learn more about installing packages.
BeautifulSoup4 can’t be installed in python3.5 on Windows7
I have downloaded beautifulsoup4-4.5.3.tar.gz from https://www.crummy.com/software/BeautifulSoup/bs4/download/4.5/ and unzipped it to my python work directory(which is not my python install directory).
However, when I run
in my IDLE the error massage popped out:
I tried these methods but the error massage above keeps popping out
- open setup.py in my IDLE and run it(gives === RESTART: D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3\setup.py === in IDLE windows, but from bs4 import BeautifulSoup didn’t work)
- use cmd and go to D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3, run pip uninstall beautifulsoup4 then run pip install beautifulsoup4 ;it shows that I have successfully installed beautifulsoup4-4.5.3 in cmd line, however, error massage still appearred in IDLE after from bs4 import BeautifulSoup
- use cmd and go to D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3, run pip3 uninstall beautifulsoup4 then run pip3 install beautifulsoup4 ; useless as above
- run pip install bs4 —ignore-installed ,useless as above
- run setup.py install ,useless as above
- run 2to3 -w bs4 in cmd line under D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3, returns ‘2to3’ is not recognized as an internal or external command,operable program or batch file.
what should I do?
beside, pip show bs4 gives this
under my C:\Users\myname\AppData\Local\Programs\Python\Python35-32\Lib\site-packages directory, I can see three beautifulsoup related directories:beautifulsoup4-4.5.3.dist-info, bs4 and bs4-0.0.1-py3.5.egg-info, but from bs4 import BeautifulSoup keep throwing out wrong message
Использование библиотеки beautifulsoup в Python
Это руководство для начинающих по использованию библиотеки beautifulsoup для парсинга данных с веб сайтов.
Введение
Веб парсинг это метод программирования для извлечения данных с веб-сайтов. Процесс получения данных с веб-сайтов может быть выполнен вручную, но это медленный и утомительный процесс, когда данных много. Web Scraping обеспечивает более автоматизированный и простой способ извлечения информации с веб-сайтов.
Веб парсинг это больше, чем просто получение данных: этот метод также может помочь вам архивировать данные и отслеживать изменения в данных онлайн.
Он также известен как веб скрейпинг или веб паук.
В интернете очень много информации на эту тему, и она растет довольно быстро. Люди парсят интернет по многим причинам и вот некоторые из них:
- Мониторинг изменения цен в режиме онлайн.
- Сбор списка недвижимости.
- Извлечение последних новостей с новостного сайта.
- Мониторинг погодных данных.
- Исследование чего-либо.
- Извлечение большого объема данных для интеллектуального анализа данных и так далее.
Все сводится к тому, какие данные вы хотите получить или отследить в интернете.
Инструменты
Существует множество инструментов и языков программирования для очистки контента в интернете, но Python обеспечивает плавный и простой процесс. Веб-скрейпинг может быть выполнен на Python с помощью таких библиотек, как Requests, BeautifulSoup, Scrapy и Selenium.
Beautifulsoup это лучший выбор при запуске веб-скрейпинга в Python, поэтому мы будем использовать BeautifulSoup4 и библиотеку запросов Python для Web Scraping.
Не все веб-сайты разрешают собирать данные, поэтому перед сбором вам следует проверить политику веб-сайта.
Реализация
Есть всего три шага в очистке веб-страницы:
- Проверка веб-страницы.
- Извлечение веб-страницы.
- Простая очистка веб-страницы.
Сбор заголовков последних технических новостей
habr.com предоставляет последние новости из технической индустрии, поэтому сегодня я буду парсить последние заголовки новостей с их домашней страницы.
Проверка источника данных
Итак, вы должны иметь некоторые базовые знания HTML. Чтобы ознакомиться с веб-страницей habr.com, сначала посетите ее сайт habr.com, затем в вашем браузере нажмите CTRL + U, чтобы просмотреть исходный код веб-страницы. Просматриваемый исходный код это тот же самый код, из которого мы будем собирать наши данные.
Обладая некоторыми базовыми знаниями в области HTML, вы можете проанализировать исходный код и найти HTML-разделы или элементы, которые содержат некоторые данные, такие как заголовки новостей, обзор новостей, дата статьи и так далее.
Извлечение веб-страницы
Чтобы собрать информацию с веб-страницы, вы должны сначала извлечь (получить или загрузить) страницу. Но обратите внимание, что компьютеры не видят веб-страницы так, как мы, люди, то есть красивые макеты, цвета, шрифты и тому подобное.
Компьютеры видят и понимают веб-страницы как код, то есть исходный код, который мы видим, когда просматриваем исходный код в браузере, нажимая CTRL + U, как мы это делали при проверке веб-страницы.
Чтобы получить веб-страницу с помощью Python, я буду использовать библиотеку requests, которую вы можете установить с помощью pip:
Чтобы получить веб-страницу с помощью библиотеки запросов, я пишу код:
Переменная response содержит ответ, который мы получаем после отправки запроса на https://www.habr.com/.
response.status_code возвращает код ответа, указывающий, был ли запрос успешным или нет. Код состояния 200 указывает на то, что запрос был успешным, 4** означает ошибку клиента (ошибку с вашей стороны) и 5** означает ошибку сервера.
response.content возвращает содержимое ответа, которое является исходным кодом веб-страницы, и это тот же исходный код, который доступен вам при просмотре его в веб-браузере.
Использование BeautifulSoup
После того, как я получил веб-страницу и доступ к ее исходному коду, мне нужно разобрать ее с помощью BeautifulSoup.
Beautiful Soup это библиотека Python для извлечения данных из HTML-и XML-файлов. Я буду использовать ее для извлечения необходимых нам данных из нашего исходного кода HTML.
Устанавливаем BeautifulSoup через pip:
Прежде чем сделать какое-либо извлечение, я должен разобрать HTML, который у нас есть:
Класс BeautifulSoup требует двух аргументов: исходного кода HTML страницы, который хранится в response.content, и HTML-parser.
HTML-parser это простой модуль синтаксического анализа HTML, встроенный в Python и BeautifulSoup, который нужен для разбора response.content (исходный код HTML).
Извлечение заголовка и тела страницы
После синтаксического анализа с помощью BeautifulSoup анализируемый HTML-код хранится в переменной Soup, которая является основой всего извлечения, которое мы собираемся сделать. Давайте начнем с извлечения заголовка страницы, элементов head и body:
soup.title возвращает элемент title веб-страницы в формате html(…). Аналогично soup.head и soup.body возвращают элементы head и body веб-страницы.
Поиск HTML-элементов
Выборка только заголовков, head и body веб-страницы по-прежнему дает нам слишком много нежелательных данных. Нам нужны только некоторые данные из тела HTML, такие как поиск определённых HTML-элементов, например, div, a, p, footer, img, и так далее. Моя цель собрать заголовки новостей с веб-страницы. Когда я проводил проверку, вы заметили, что новостные статьи хранились с разбивкой по тегам. Давайте посмотрим, будет ли полезно найти все элементы a на веб-странице:
Поиск всех тэгов a это еще один шаг ближе к цели, но мне все равно нужно быть более конкретным и находить только те элементы a с нужными нам данными.
Как вы можете видеть выше, заголовки новостей находятся в элементах a с именем класса post__title_link, то есть:
Таким образом, нам нужно будет найти только элементы a с классом post__title_link.
Поиск HTML-элементов по имени класса
Чтобы найти все элементы a с классом post__title_link, я пишу следующий код:
ищет все элементы a названием класса post__title_link и возвращает их списком.
Затем мы перебираем возвращенный список и извлекаем из него все элементы, поскольку он содержит искомый текст:
Мы почти закончили, у меня есть список элементов с нашими новостными заголовками в них. Мы должны извлечь их из HTML-элемента (извлечь текст из элементов).
Извлечение текста из HTML-элементов
В BeautifulSoup для извлечения текста мы используем атрибут .text для получения текстовых данных из HTML-элемента:
Ура! Мы спарсили последние заголовки новостей из technewsworld.com. Обратите внимание, что ваши заголовки новостей будут отличаться от моих, так как главная страница всегда обновляется последними новостями.
Эта небольшая программа, которую мы написали, может служить автоматизированным способом отслеживания последних изменений от technewsworld.com, потому что каждый раз, когда мы запускаем эту программу, мы получаем последние изменения с главной страницы.
Если вы ищите способ системно подойти к обучению языка программирования Python, рекомендую записаться на курсы онлайн обучения.
Поделиться записью в социальных сетях
Руководство по синтаксическому анализу HTML с помощью BeautifulSoup в Python

Веб-скрапинг — это программный сбор информации с различных веб-сайтов. Несмотря на то, что существует множество библиотек и фреймворков на разных языках, которые могут извлекать веб-данные, Python уже давно стал популярным выбором из-за множества опций для парсинга веб-страниц.
Эта статья даст вам ускоренный курс по парсингу веб-страниц в Python с помощью Beautiful Soup — популярной библиотеки Python для синтаксического анализа HTML и XML.
Этический веб-скрапинг
Веб-скрапинг повсеместен и дает нам данные, как если бы мы получали их с помощью API. Однако, как хорошие граждане Интернета, мы обязаны уважать владельцев сайтов. Вот несколько принципов, которых должен придерживаться веб-парсер:
- Не заявляйте, что извлеченный контент принадлежит вам. Владельцы веб-сайтов иногда тратят много времени на создание статей, сбор сведений о продуктах или сбор другого контента. Мы должны уважать их труд и оригинальность.
- Не парсите веб-сайт, который не хочет этого. Веб-сайты иногда поставляются с файлом robots.txt , который определяет части веб-сайта, которые можно получить. У многих веб-сайтов также есть Условия использования, которые могут не разрешать парсинг. Мы должны уважать веб-сайты, которые не хотят что-бы их контент парсили.
- Есть ли уже доступный API? Прекрасно, нам не нужно писать парсер. API-интерфейсы создаются для предоставления доступа к данным контролируемым способом, определенным владельцами данных. Мы предпочитаем использовать API, если они доступны.
- Отправка запросов на веб-сайт может отрицательно сказаться на его работе. Веб-парсер, который делает слишком много запросов, может быть таким же изнурительным, как и DDOS-атака. Мы должны выполнять чистку ответственно, чтобы не нарушать нормальную работу веб-сайта.
Обзор Beautiful Soup
HTML-содержимое веб-страниц можно проанализировать и очистить с помощью Beautiful Soup. В следующем разделе мы рассмотрим те функции, которые полезны для очистки веб-страниц.
Что делает Beautiful Soup таким полезным, так это множество функций, которые он предоставляет для извлечения данных из HTML. На этом изображении ниже показаны некоторые функции, которые мы можем использовать:
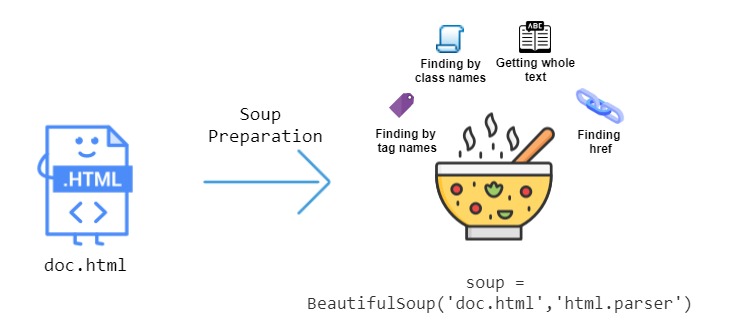
Давайте поработаем и посмотрим, как мы можем анализировать HTML с помощью Beautiful Soup. Рассмотрим следующую HTML-страницу, сохраненную в файл как doc.html :
Следующие фрагменты кода протестированы на Ubuntu 20.04.1 LTS . Вы можете установить модуль BeautifulSoup , набрав в терминале следующую команду:
HTML-файл doc.html необходимо подготовить. Это делается путем передачи файла конструктору BeautifulSoup , давайте воспользуемся для этого интерактивной оболочкой Python, чтобы мы могли мгновенно распечатать содержимое определенной части страницы:
Теперь мы можем использовать Beautiful Soup для навигации по нашему веб-сайту и извлечения данных.
Переход к определенным тегам
Из объекта soup, созданного в предыдущем разделе, получим тег заголовка doc.html :
Вот разбивка каждого компонента, который мы использовали для получения названия:
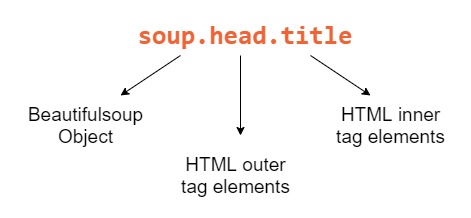
Beautiful Soup — мощный инструмент, потому что наши объекты Python соответствуют вложенной структуре HTML-документа, который мы очищаем.
Чтобы получить текст первого тега , введите следующее:
Чтобы получить заголовок в HTML теге body (обозначается классом «title»), введите в терминале следующее:
Для глубоко вложенных HTML-документов навигация может быстро стать утомительной. К счастью, Beautiful Soup поставляется с функцией поиска, поэтому нам не нужно перемещаться, чтобы получить элементы HTML.
Поиск тегов
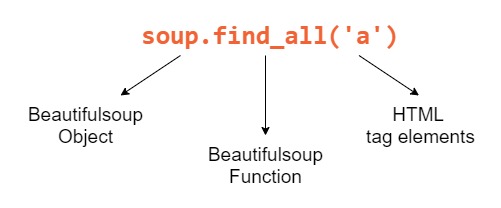
Метод find_all() принимает HTML-тег в качестве строкового аргумента и возвращает список элементов, которые соответствуют указанной поисковой строке. Например, если мы хотим, найти все теги a в doc.html :
Мы увидим этот список тегов a в качестве вывода:
Вот разбивка каждого компонента, который мы использовали для поиска тега:
Мы также можем искать теги определенного класса, указав аргумент class_ . Beautiful Soup использует class_ , потому что class является зарезервированным ключевым словом в Python. Поищем все теги a , у которых есть класс element:
Поскольку у нас есть только две ссылки с классом «element», вы увидите следующий результат:
Что, если бы мы хотели получить ссылки, встроенные в теги a ? Давайте получим атрибут ссылки href с помощью опции find() . Он работает точно так же как find_all() , но возвращает первый соответствующий элемент вместо списка. Введите это в свою оболочку:
Функции find() и find_all() также принимают регулярное выражение вместо строки. За кулисами текст будет фильтроваться с использованием метода скомпилированного регулярного выражения search() . Например:
Список после итерации выбирает теги, начинающиеся с символа b , который включает и :
Мы рассмотрели наиболее популярные способы получения тегов и их атрибутов. Иногда, особенно для менее динамичных веб-страниц, нам просто нужен текст. Посмотрим, как мы сможем это получить!
Получение всего текста
Функция get_text() извлекает весь текст из HTML — документа. Получим весь текст HTML-документа:
Ваш результат должен быть таким:
Иногда печатаются символы новой строки, поэтому ваш вывод также может выглядеть так:
Теперь, когда мы понимаем, как использовать Beautiful Soup, давайте очистим веб-сайт!
Beautiful Soup в действии — очистка списка книг
Теперь, когда мы освоили компоненты Beautiful Soup, пришло время применить наши знания на практике. Давайте создадим парсер для извлечения данных с https://books.toscrape.com/ и сохранения их в файл CSV. Сайт содержит случайные данные о книгах и является отличным местом для проверки ваших методов парсинга.
Сначала создайте новый файл с именем scraper.py . Импортируем все библиотеки, которые нам нужны для этого скрипта:
В упомянутых выше модулях:
- requests — выполняет URL-запрос и получает HTML-код сайта
- time — ограничивает, сколько раз мы очищаем страницу одновременно
- csv — помогает нам экспортировать очищенные данные в файл CSV
- re — позволяет нам писать регулярные выражения, которые пригодятся для выбора текста на основе его шаблона
- bs4 — модуль парсинга для парсинга HTML
Вы уже установили bs4 , а time , csv и re являются встроенными пакетами в Python. Вам нужно будет установить только модуль requests следующим образом:
Прежде чем начать, вам нужно понять, как структурирован HTML-код веб-страницы. В вашем браузере перейдите по адресу http://books.toscrape.com/catalogue/page-1.html. Затем щелкните правой кнопкой мыши компоненты веб-страницы, которые нужно очистить, и нажмите кнопку проверки, чтобы понять иерархию тегов, как показано ниже.
Это покажет вам базовый HTML-код того, что вы проверяете. На следующем рисунке показаны эти шаги:
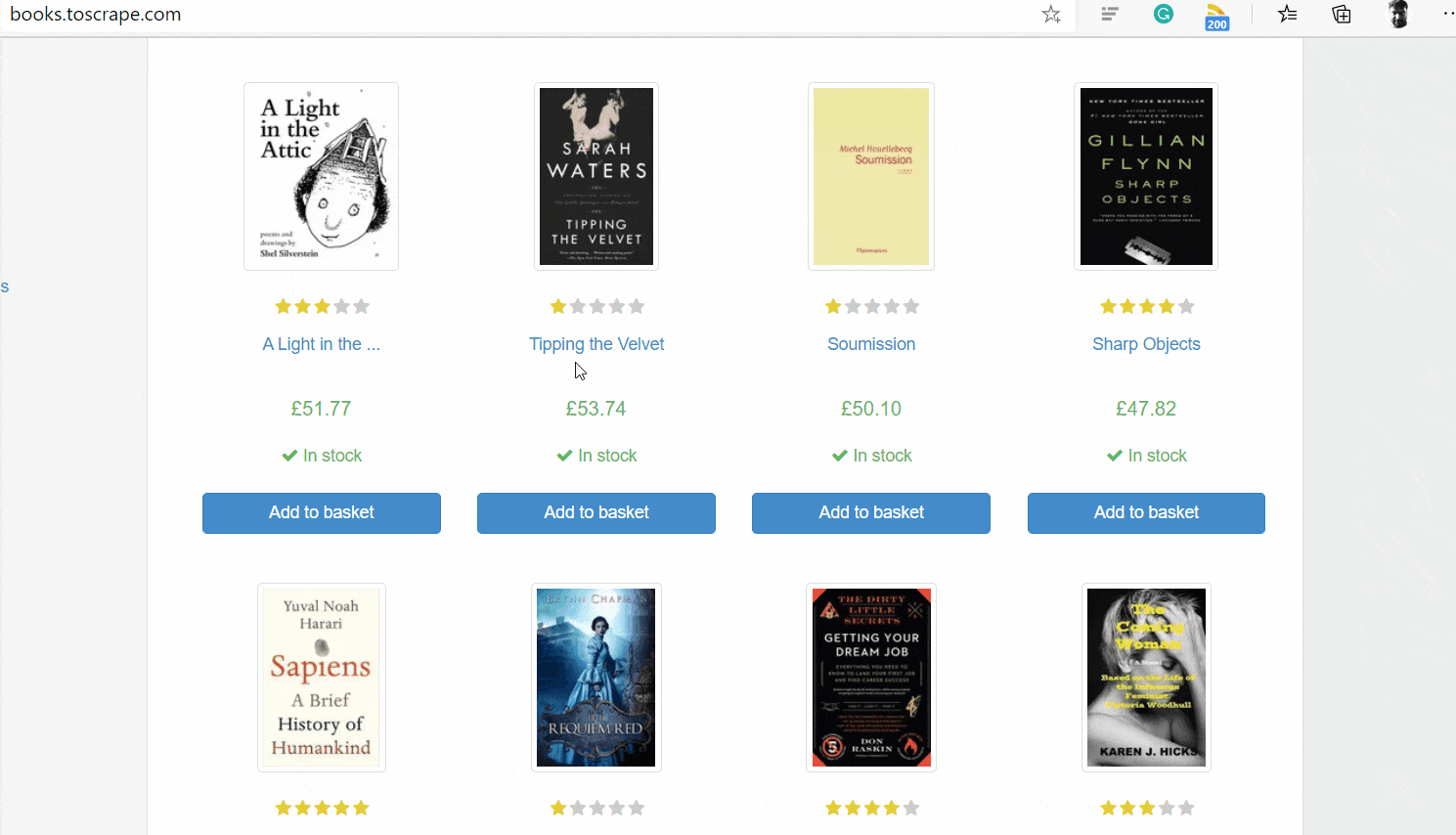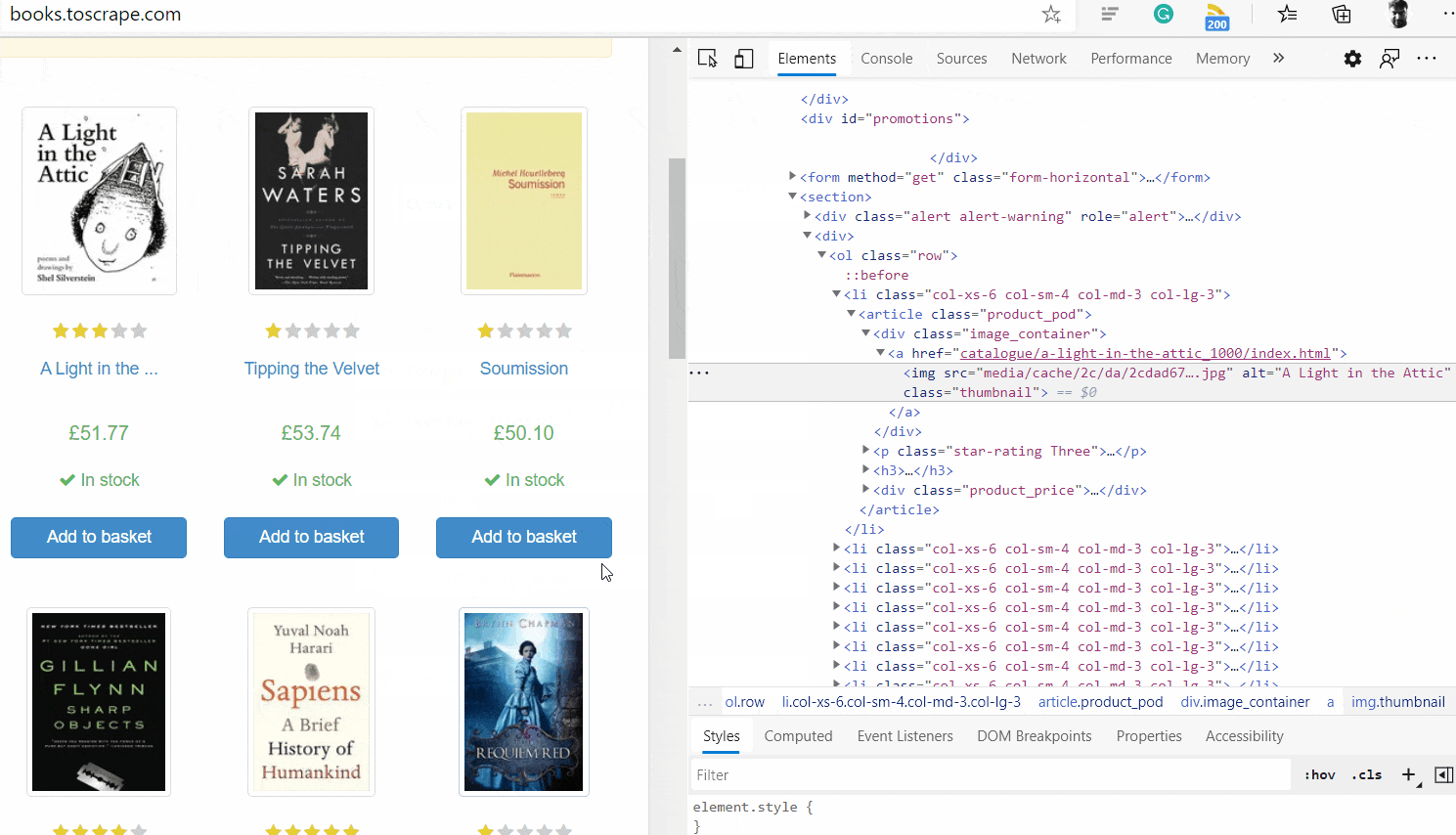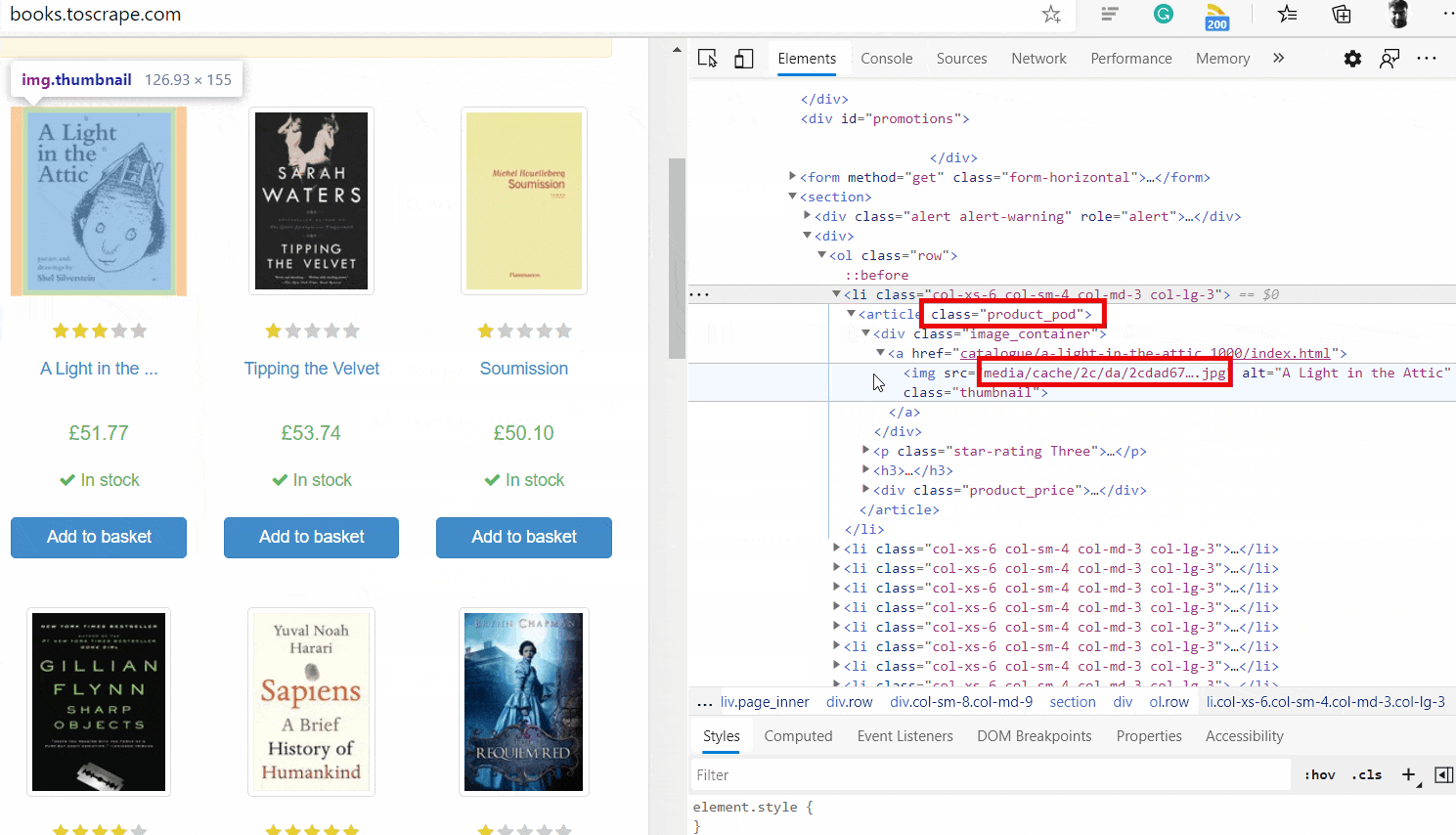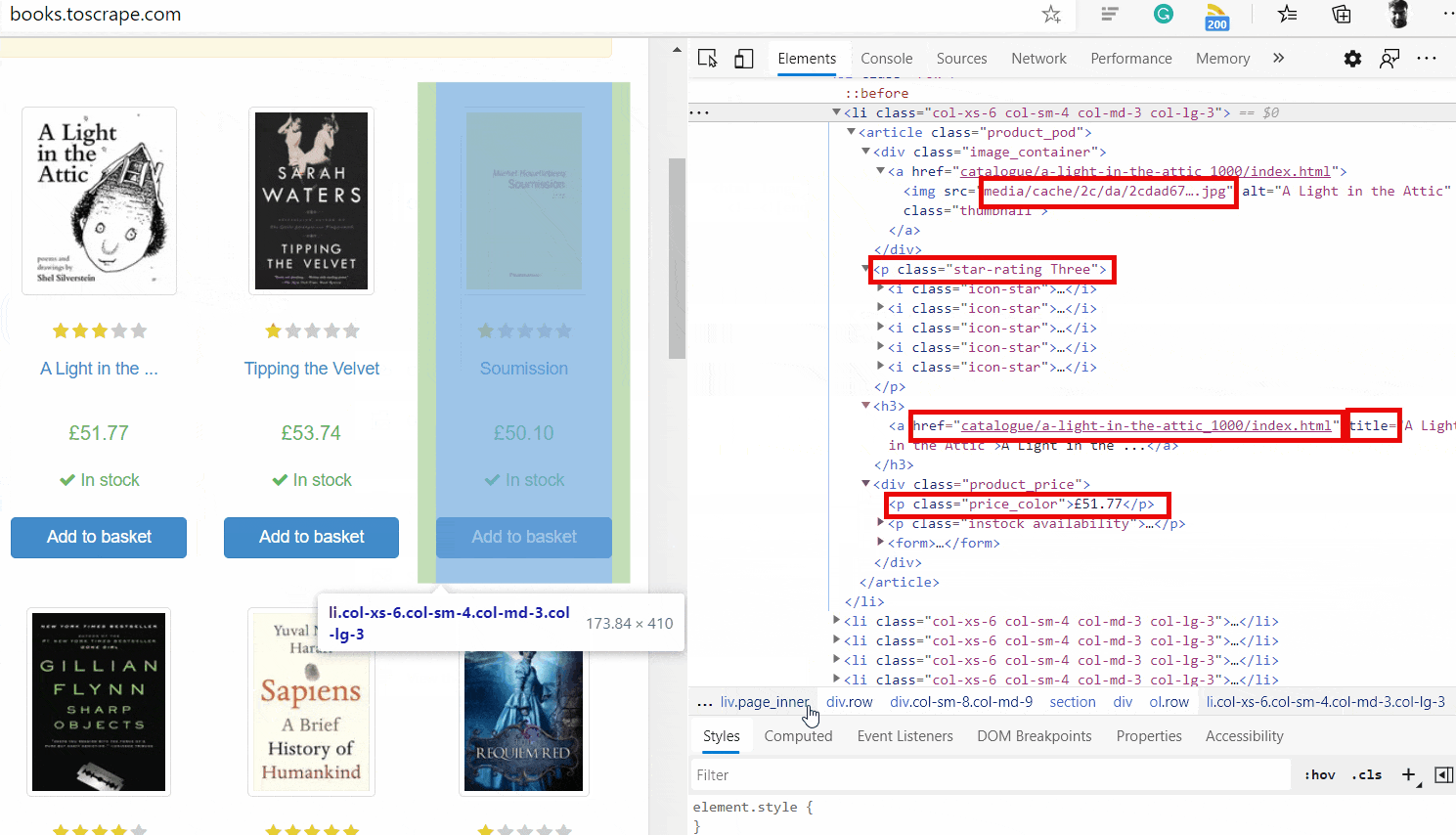
Изучив HTML, мы узнаем, как получить доступ к URL-адресу книги, изображению обложки, заголовку, рейтингу, цене и другим полям из HTML. Давайте напишем функцию, которая очищает элемент книги и извлекает его данные:
Последняя строка приведенного выше фрагмента указывает на функцию для записи списка очищенных строк в файл CSV. Давайте добавим эту функцию сейчас:
Поскольку у нас есть функция, которая может очищать страницу и экспортировать в CSV, нам нужна другая функция, которая просматривает веб-сайт с разбивкой на страницы, собирая данные о книгах на каждой странице.
Для этого давайте посмотрим на URL-адрес, для которого мы пишем этот парсер:
Единственным изменяющимся элементом URL-адреса является номер страницы. Мы можем динамически форматировать URL-адрес, чтобы он стал исходным URL-адресом:
Этот строковый URL-адрес с номером страницы можно получить с помощью метода requests.get() . Затем мы можем создать новый объект BeautifulSoup. Каждый раз, когда мы получаем объект soup, проверяется наличие кнопки «next», чтобы мы могли остановиться на последней странице. Мы отслеживаем счетчик номера страницы, который увеличивается на 1 после успешного извлечения страницы.
Функция browse_and_scrape() , вызывается рекурсивно, пока функция soup.find(«li»,class_=»next») не вернет None . На этом этапе код очистит оставшуюся часть веб-страницы и завершит работу.
Для последней части пазла мы запускаем процесс парсинга. Мы определяем seed_url и вызываем browse_and_scrape() для получения данных. Это делается в блоке if __name__ == «__main__» :
Вы можете выполнить сценарий, как показано ниже, в вашем терминале и получить вывод как:
Очищенные данные можно найти в текущем рабочем каталоге под именем файла allBooks.csv . Вот пример содержимого файла:
Вывод
В этом уроке мы узнали об этике написания хороших парсеров. Затем мы использовали Beautiful Soup для извлечения данных из HTML-файла с помощью свойств объекта Beautiful Soup и его различных методов, таких как find() , find_all() и get_text() . Затем мы создали парсер, который извлекает список книг в Интернете и экспортирует его в CSV.
Очистка веб-страниц — полезный навык, который помогает в различных действиях, таких как извлечение данных, таких как API, выполнение контроля качества на веб-сайте, проверка неработающих URL-адресов на веб-сайте и многое другое.



