- Введение в каналы и именованные каналы в Linux
- Linux pipes tips & tricks
- Pipe — что это?
- Логика
- Простой дебаг
- Исходный код, уровень 1, shell
- Исходный код, уровень 2, ядро
- Tips & trics
- named pipes в Unix
- How To Use Pipes And Named Pipes In Linux, Explained With Examples
- How does a pipe work in Linux
- What is a named pipe in Linux
- When to use regular or named pipes
- An introduction to pipes and named pipes in Linux
- Moving data between commands? Use a pipe to make the process quick and easy.
- Subscribe now
- pipe.png
- redirection.png
- create-named-pipe.png
- verify-output.png
Введение в каналы и именованные каналы в Linux
Оригинал: An introduction to pipes and named pipes in Linux
Автор: Archit Modi
Дата публикации: 23 августа 2018 года
Перевод: А. Кривошей
Дата перевода: апрель 2019 г.
В Linux команда pipe позволяет отправлять вывод одной команды в другую. Каналы, как предполагает термин, могут перенаправлять стандартный вывод, ввод или ошибку одного процесса другому для дальнейшей обработки.
Синтаксис для команды pipe или команды pipe без имени — символ | между любыми двумя командами:
Здесь канал не может быть доступен в другом сеансе; он создается временно, чтобы обеспечить выполнение Command-1 и перенаправить стандартный вывод. Он удаляется после успешного выполнения.
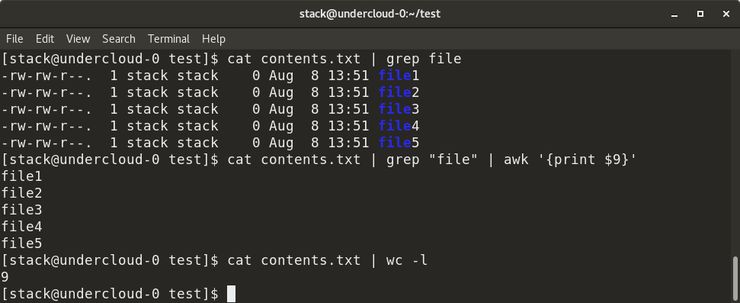
В приведенном выше примере файл contents.txt содержит список всех файлов в определенном каталоге, то есть вывод команды ls -al. Сначала мы подбираем имена файлов с помощью ключевого слова «file» из contents.txt по каналу (как показано), поэтому выходные данные команды cat предоставляются в качестве входных данных для команды grep. Затем мы добавляем канал для выполнения команды awk, которая отображает 9-й столбец из отфильтрованного вывода команды grep. Мы также можем подсчитать количество строк в content.txt с помощью команды wc -l.
Именованный канал может работать, пока система не будет перезагружена, или пока он не будет удален. Это специальный файл, который использует механизм FIFO (первым пришел, первым вышел). Он может использоваться как обычный файл; то есть вы можете писать в него, читать из него, а также открывать или закрывать его. Чтобы создать именованный канал, используется команда:
Она создает файл именованного канала, который можно использовать даже в нескольких сеансах оболочки.
Другой способ создать именованный канал FIFO — использовать следующую команду:
Чтобы перенаправить стандартный вывод любой команды другому процессу, используйте символ >. Чтобы перенаправить стандартный ввод любой команды, используйте символ
Источник
Linux pipes tips & tricks
Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Исходный код, уровень 1, shell
Т. к. лучшая документация — исходный код, обратимся к нему. Bash использует Yacc для парсинга входных команд и возвращает ‘command_connect()’, когда встречает символ ‘|’.
parse.y:
Также здесь мы видим обработку пары символов ‘|&’, что эквивалентно перенаправлению как stdout, так и stderr в конвеер. Далее обратимся к command_connect():make_cmd.c:
где connector это символ ‘|’ как int. При выполнении последовательности команд (связанных через ‘&’, ‘|’, ‘;’, и т. д.) вызывается execute_connection():execute_cmd.c:
PIPE_IN и PIPE_OUT — файловые дескрипторы, содержащие информацию о входном и выходном потоках. Они могут принимать значение NO_PIPE, которое означает, что I/O является stdin/stdout.
execute_pipeline() довольно объемная функция, имплементация которой содержится в execute_cmd.c. Мы рассмотрим наиболее интересные для нас части.
execute_cmd.c:
Таким образом, bash обрабатывает символ конвейера путем системного вызова pipe() для каждого встретившегося символа ‘|’ и выполняет каждую команду в отдельном процессе с использованием соответствующих файловых дескрипторов в качестве входного и выходного потоков.
Исходный код, уровень 2, ядро
Обратимся к коду ядра и посмотрим на имплементацию функции pipe(). В статье рассматривается ядро версии 3.10.10 stable.
fs/pipe.c (пропущены незначительные для данной статьи участки кода):
Если вы обратили внимание, в коде идет проверка на флаг O_NONBLOCK. Его можно выставить используя операцию F_SETFL в fcntl. Он отвечает за переход в режим без блокировки I/O потоков в конвеере. В этом режиме вместо блокировки процесс чтения/записи в поток будет завершаться с errno кодом EAGAIN.
Максимальный размер блока данных, который будет записан в конвейер, равен одной странице памяти (4Кб) для архитектуры arm:
arch/arm/include/asm/limits.h:
Для ядер >= 2.6.35 можно изменить размер буфера конвейера:
Максимально допустимый размер буфера, как мы видели выше, указан в файле /proc/sys/fs/pipe-max-size.
Tips & trics
В примерах ниже будем выполнять ls на существующую директорию Documents и два несуществующих файла: ./non-existent_file и. /other_non-existent_file.
Перенаправление и stdout, и stderr в pipe
или же можно использовать комбинацию символов ‘|&’ (о ней можно узнать как из документации к оболочке (man bash), так и из исходников выше, где мы разбирали Yacc парсер bash):
Перенаправление _только_ stderr в pipe
Shoot yourself in the foot
Важно соблюдать порядок перенаправления stdout и stderr. Например, комбинация ‘>/dev/null 2>&1′ перенаправит и stdout, и stderr в /dev/null.
Получение корректного кода завершения конвейра
По умолчанию, код завершения конвейера — код завершения последней команды в конвеере. Например, возьмем исходную команду, которая завершается с ненулевым кодом:
И поместим ее в pipe:
Теперь код завершения конвейера — это код завершения команды wc, т.е. 0.
Обычно же нам нужно знать, если в процессе выполнения конвейера произошла ошибка. Для этого следует выставить опцию pipefail, которая указывает оболочке, что код завершения конвейера будет совпадать с первым ненулевым кодом завершения одной из команд конвейера или же нулю в случае, если все команды завершились корректно:
Shoot yourself in the foot
Следует иметь в виду “безобидные” команды, которые могут вернуть не ноль. Это касается не только работы с конвейерами. Например, рассмотрим пример с grep:
Здесь мы печатаем все найденные строки, приписав ‘new_’ в начале каждой строки, либо не печатаем ничего, если ни одной строки нужного формата не нашлось. Проблема в том, что grep завершается с кодом 1, если не было найдено ни одного совпадения, поэтому если в нашем скрипте выставлена опция pipefail, этот пример завершится с кодом 1:
В больших скриптах со сложными конструкциями и длинными конвеерами можно упустить этот момент из виду, что может привести к некорректным результатам.
Источник
named pipes в Unix
Я давно читал про них, ещё когда учился основам юникс, но как-то не было нужды с ними работать. И, вот, нужда возникла.
Некая программа (допустим, foo) не умеет писать вывод в stdout, только в файл. Даже «-» в качестве имени файла всего лишь создаёт файл с названием «-» [большинство умных программ под unix знают, что одиночный минус вместо имени файла означает вывод в stdout]. Аналогично она отвергает и /dev/stdout.
Другая же программа, обрабатывающая результаты первой, допустим, bar, читает из stdin и пишет в stdout. (если быть точным, первое — это трейсер специального вида, дающий двоичный дамп, а второе — конвертор, печатающий их же в человекочитаемом виде).
Нужно их объединить в конвеер.
Некрасивый вариант — использование обычного файла. Записал, прочитал.
Есть куда более красивый вариант — это именованные пайпы. Так как у пайпа есть имя, мы можем передать его как файл первой программе, а потом передать содержимое другой.
Выглядит это так:
Пайп в файловой системе выглядит так:
(акцент на букву ‘p’ первым символом).
Как это работает? Фактически, fifo aka named pipe — это «обыкновенный pipe», примерно такой, который кодируется палкой «|». Однако, у него есть ИМЯ и это имя можно указывать всюду, где требуется файл.
Программа, которая пишет в именованный пайп, ведёт себя с ним как с файлом. Т.е. пишет себе и пишет. Программа, которая читает — аналогично. Читает себе и читает. Чтение идёт в том порядке, как была осуществлена запись (FIFO — first in first out). Положения относительно пайпа (слева/справа) определяются тем, кто читает, а кто пишет.
Важная же особенность пайпа — способность тормознуть читающую/пищущую программу, если буфер пуст/переполнен.
Рассмотрим на примере чтения. Программа пишет в пайп одну строчку в секунду. Программа чтения читает с максимально возможной скоростью. Программа «вычитывает» всё, что было в буфере, и посылает следующий запрос. Ядро этот запрос задерживает до того момента, пока не появятся данные. Таким образом, можно не париться с синхронизацией — появятся данные, программа-обработчик получит управление обратно из read() и обработает очередную порцию данных.
Источник
How To Use Pipes And Named Pipes In Linux, Explained With Examples
One of the most powerful shell operators in Linux is the pipe. In this article we will see how regular and named pipes work, how to use them and how they differ from each other.
The vertical bar symbol | denotes a pipe. Because of the pipe, you can take the output from one command and feed it to another command as input. In other words, a pipe is a form of redirection that is used in Linux to send the output of one program to another program for further processing.
Of course, you’re not limited to a single piped command. You can stack them as many times as you like.
The syntax for the pipe or unnamed pipe command is the | character between any two commands:
How does a pipe work in Linux
To see how pipe work, let’s take a look at examples bellow.
Let’s say we have a directory full of many different types of files. We want to know how many files of a certain type are in this directory. We can get a list of files easily using ls :
To separate the type of file we are interested in, we will use grep . We want to find files that have the word “txt” in their name or file extension.
We will use the special shell character | to direct the output of ls to grep .
The output of ls was not sent to the terminal window. Therefore the result is not displayed on the screen, and is instead redirected to the input of the grep command. The output we see above comes from grep , which is the last command in this chain.
Now, let’s start extending our chain. We can count files “txt” by adding the wc command . We will use the -l option (number of lines) with wc .
grep is no longer the last command in the chain, so we do not see its output. The output of grep is fed into the wc command. The output that we see in the terminal window comes from wc . wc reports that there are 2 files “txt” in the directory.
What is a named pipe in Linux
As the name itself suggests, these are pipes with names. One of the key differences between regular pipes and named pipes is that named pipes have a presence in the file system. That is, they show up as files.
The named pipe in Linux is a method for passing information from one computer process to another using a pipe which is given a specific name. Named pipes are also known as FIFO, which stands for First In, First Out.
You can create a named pipe using the mkfifo command. For example:
You can tell if a file is a named pipe by the p bit in the file permissions section.
The named pipes are actually files on the file system itself. Unlike a standard pipe, a named pipe is accessed as part of the filesystem, just like any other type of file.
The named pipe content resides in memory rather than being written to disk. It is passed only when both ends of the pipe have been opened. And you can write to a pipe multiple times before it is opened at the other end and read. By using named pipes, you can establish a process in which one process writes to a pipe and another reads from a pipe without much concern about trying to time or carefully orchestrate their interaction.
To see how named pipe work, let’s take a look at examples bellow. Let’s first create our named pipe:
Now let’s consume messages with this pipe.
Open another terminal window, write a message to this pipe:
Now in the first window you can see the “hi” printed out:
Because it is a pipe and message has been consumed, if we check the file size, you can see it is still 0:
Since a named pipe is just a file in Linux, to remove one we can use the rm command. Therefore, to remove the pipe we created in the previous examples, we would run:
When to use regular or named pipes
Using a regular pipe instead of a named pipe in Linux depends on the characteristics we’re looking for. Some of them can be persistence, two-way communication, having a filename, creating a filter, and restricting access permissions among others.
For example, if we want to filter the output of a command multiple times, using an anonymous pipe seems the most appropriate option. On the other hand, if we need a filename and we don’t want to store data on disk, what we’re looking for is a named pipe.
In conclusion, the next time you’re working with commands at the Linux terminal and find yourself moving data between commands, hopefully a pipe will make the process quick and easy.
For more about pipe command in Linux, consult its manual page.
Источник
An introduction to pipes and named pipes in Linux
Moving data between commands? Use a pipe to make the process quick and easy.

Subscribe now
Get the highlights in your inbox every week.
In Linux, the pipe command lets you sends the output of one command to another. Piping, as the term suggests, can redirect the standard output, input, or error of one process to another for further processing.
The syntax for the pipe or unnamed pipe command is the | character between any two commands:
Command-1 | Command-2 | …| Command-N
Here, the pipe cannot be accessed via another session; it is created temporarily to accommodate the execution of Command-1 and redirect the standard output. It is deleted after successful execution.
pipe.png
A named pipe can last until as long as the system is up and running or until it is deleted. It is a special file that follows the FIFO (first in, first out) mechanism. It can be used just like a normal file; i.e., you can write to it, read from it, and open or close it. To create a named pipe, the command is:
This creates a named pipe file that can be used even over multiple shell sessions.
Another way to create a FIFO named pipe is to use this command:
To redirect a standard output of any command to another process, use the > symbol. To redirect a standard input of any command, use the symbol.
redirection.png
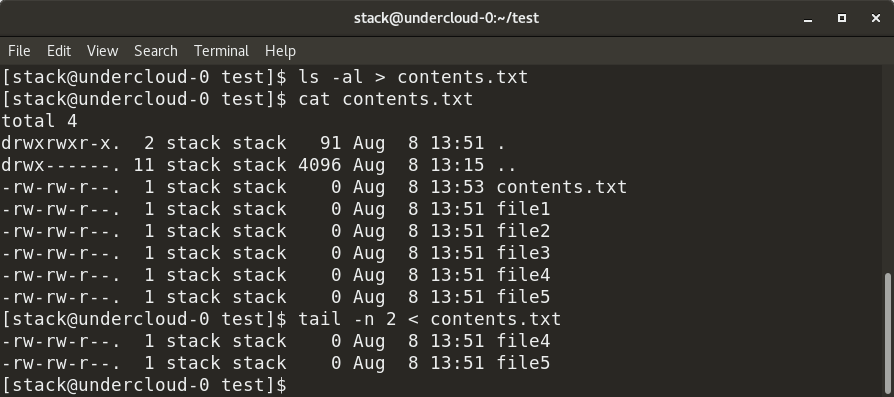
As shown above, the output of the ls -al command is redirected to contents.txt and inserted in the file. Similarly, the input for the tail command is provided as contents.txt via the symbol.
create-named-pipe.png
verify-output.png
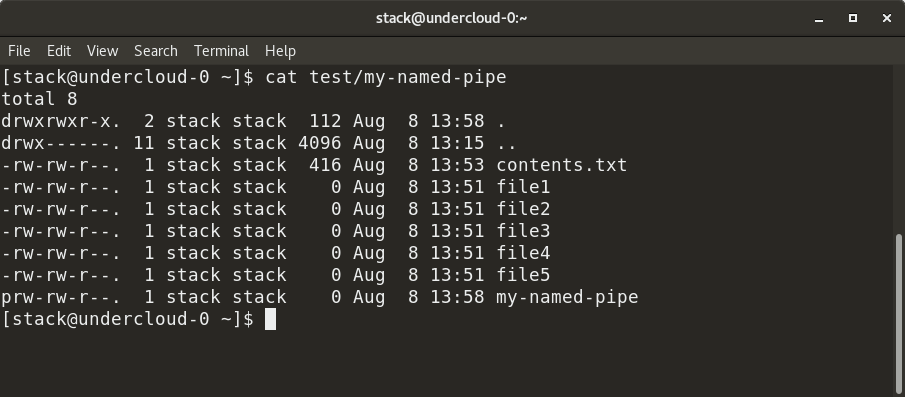
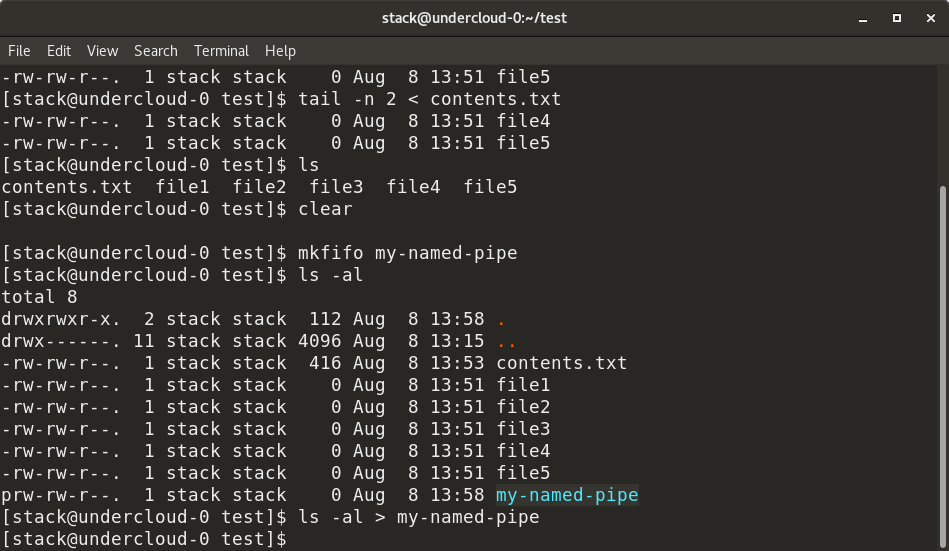
Here, we have created a named pipe, my-named-pipe , and redirected the output of the ls -al command into the named pipe. We can the open a new shell session and cat the contents of the named pipe, which shows the output of the ls -al command, as previously supplied. Notice the size of the named pipe is zero and it has a designation of «p».
So, next time you’re working with commands at the Linux terminal and find yourself moving data between commands, hopefully a pipe will make the process quick and easy.
Источник



