Piping in Unix or Linux
A pipe is a form of redirection (transfer of standard output to some other destination) that is used in Linux and other Unix-like operating systems to send the output of one command/program/process to another command/program/process for further processing. The Unix/Linux systems allow stdout of a command to be connected to stdin of another command. You can make it do so by using the pipe character ‘|’.
Pipe is used to combine two or more commands, and in this, the output of one command acts as input to another command, and this command’s output may act as input to the next command and so on. It can also be visualized as a temporary connection between two or more commands/ programs/ processes. The command line programs that do the further processing are referred to as filters.
This direct connection between commands/ programs/ processes allows them to operate simultaneously and permits data to be transferred between them continuously rather than having to pass it through temporary text files or through the display screen.
Pipes are unidirectional i.e data flows from left to right through the pipeline.
Syntax :
Example :
1. Listing all files and directories and give it as input to more command.
Output :
The more command takes the output of $ ls -l as its input. The net effect of this command is that the output of ls -l is displayed one screen at a time. The pipe acts as a container which takes the output of ls -l and gives it to more as input. This command does not use a disk to connect standard output of ls -l to the standard input of more because pipe is implemented in the main memory.
In terms of I/O redirection operators, the above command is equivalent to the following command sequence.
Output :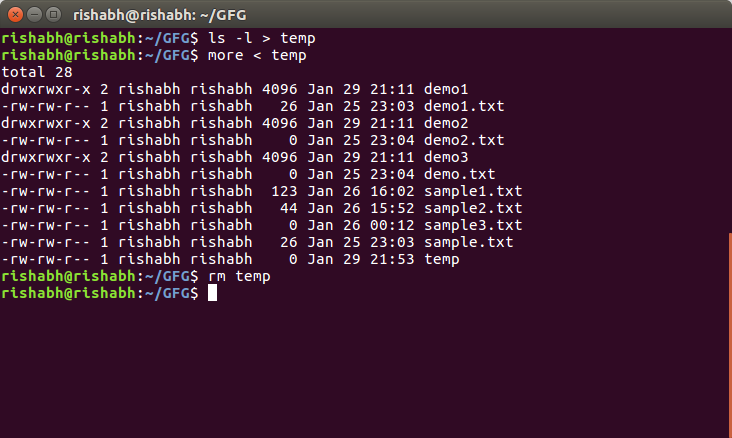
Output of the above two commands is same.
2. Use sort and uniq command to sort a file and print unique values.
This will sort the given file and print the unique values only.
Output :
3. Use head and tail to print lines in a particular range in a file.
This command select first 7 lines through (head -7) command and that will be input to (tail -5) command which will finally print last 5 lines from that 7 lines.
Output :
4. Use ls and find to list and print all lines matching a particular pattern in matching files.
This command select files with .txt extension in the given directory and search for pattern like “program” in the above example and print those ine which have program in them.
Output :
5. Use cat, grep, tee and wc command to read the particular entry from user and store in a file and print line count.
This command select Rajat Dua and store them in file2.txt and print total number of lines matching Rajat Dua
Output :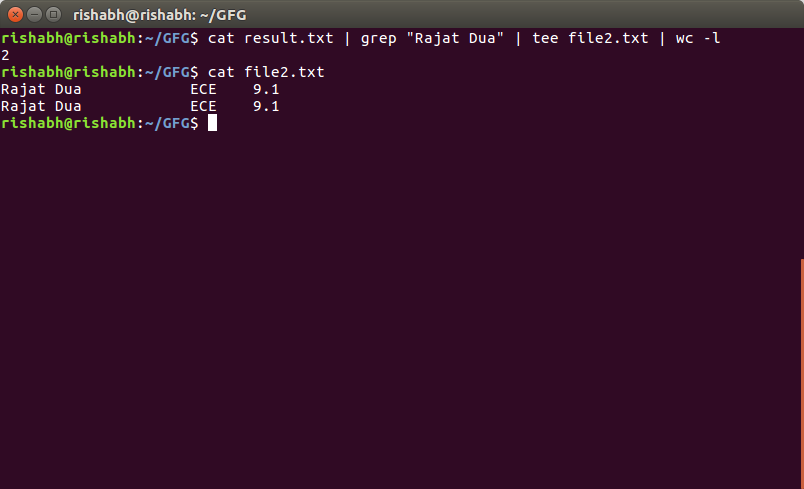
Источник
Linux pipes tips & tricks
Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Исходный код, уровень 1, shell
Т. к. лучшая документация — исходный код, обратимся к нему. Bash использует Yacc для парсинга входных команд и возвращает ‘command_connect()’, когда встречает символ ‘|’.
parse.y:
Также здесь мы видим обработку пары символов ‘|&’, что эквивалентно перенаправлению как stdout, так и stderr в конвеер. Далее обратимся к command_connect():make_cmd.c:
где connector это символ ‘|’ как int. При выполнении последовательности команд (связанных через ‘&’, ‘|’, ‘;’, и т. д.) вызывается execute_connection():execute_cmd.c:
PIPE_IN и PIPE_OUT — файловые дескрипторы, содержащие информацию о входном и выходном потоках. Они могут принимать значение NO_PIPE, которое означает, что I/O является stdin/stdout.
execute_pipeline() довольно объемная функция, имплементация которой содержится в execute_cmd.c. Мы рассмотрим наиболее интересные для нас части.
execute_cmd.c:
Таким образом, bash обрабатывает символ конвейера путем системного вызова pipe() для каждого встретившегося символа ‘|’ и выполняет каждую команду в отдельном процессе с использованием соответствующих файловых дескрипторов в качестве входного и выходного потоков.
Исходный код, уровень 2, ядро
Обратимся к коду ядра и посмотрим на имплементацию функции pipe(). В статье рассматривается ядро версии 3.10.10 stable.
fs/pipe.c (пропущены незначительные для данной статьи участки кода):
Если вы обратили внимание, в коде идет проверка на флаг O_NONBLOCK. Его можно выставить используя операцию F_SETFL в fcntl. Он отвечает за переход в режим без блокировки I/O потоков в конвеере. В этом режиме вместо блокировки процесс чтения/записи в поток будет завершаться с errno кодом EAGAIN.
Максимальный размер блока данных, который будет записан в конвейер, равен одной странице памяти (4Кб) для архитектуры arm:
arch/arm/include/asm/limits.h:
Для ядер >= 2.6.35 можно изменить размер буфера конвейера:
Максимально допустимый размер буфера, как мы видели выше, указан в файле /proc/sys/fs/pipe-max-size.
Tips & trics
В примерах ниже будем выполнять ls на существующую директорию Documents и два несуществующих файла: ./non-existent_file и. /other_non-existent_file.
Перенаправление и stdout, и stderr в pipe
или же можно использовать комбинацию символов ‘|&’ (о ней можно узнать как из документации к оболочке (man bash), так и из исходников выше, где мы разбирали Yacc парсер bash):
Перенаправление _только_ stderr в pipe
Shoot yourself in the foot
Важно соблюдать порядок перенаправления stdout и stderr. Например, комбинация ‘>/dev/null 2>&1′ перенаправит и stdout, и stderr в /dev/null.
Получение корректного кода завершения конвейра
По умолчанию, код завершения конвейера — код завершения последней команды в конвеере. Например, возьмем исходную команду, которая завершается с ненулевым кодом:
И поместим ее в pipe:
Теперь код завершения конвейера — это код завершения команды wc, т.е. 0.
Обычно же нам нужно знать, если в процессе выполнения конвейера произошла ошибка. Для этого следует выставить опцию pipefail, которая указывает оболочке, что код завершения конвейера будет совпадать с первым ненулевым кодом завершения одной из команд конвейера или же нулю в случае, если все команды завершились корректно:
Shoot yourself in the foot
Следует иметь в виду “безобидные” команды, которые могут вернуть не ноль. Это касается не только работы с конвейерами. Например, рассмотрим пример с grep:
Здесь мы печатаем все найденные строки, приписав ‘new_’ в начале каждой строки, либо не печатаем ничего, если ни одной строки нужного формата не нашлось. Проблема в том, что grep завершается с кодом 1, если не было найдено ни одного совпадения, поэтому если в нашем скрипте выставлена опция pipefail, этот пример завершится с кодом 1:
В больших скриптах со сложными конструкциями и длинными конвеерами можно упустить этот момент из виду, что может привести к некорректным результатам.
Источник
Working with pipes on the Linux command line

I’m sorry to inform you, but the command line didn’t die off with the dinosaurs, nor did it disappear with the dodo or the carrier pigeon. The Linux command line is alive and well, and still going strong. It is an efficient way of quickly gathering and processing information, creating new scripts, and configuring systems.
One of the most powerful shell operators is the pipe ( | ). The pipe takes output from one command and uses it as input for another. And, you’re not limited to a single piped command—you can stack them as many times as you like, or until you run out of output or file descriptors.
One of the main purposes of piping is filtering. You use piping to filter the contents of a large file—to find a particular string or word, for example. This purpose is why the most popular use for pipes involves the commands grep and sort . But, you’re not limited to those cases. You can pipe the output to any command that accepts stream input. Let’s look at a theoretical example as an illustration of how this process works:
Both cmd1 and cmd2 are command line utilities that output their results to the screen ( stdout ). When you pipe one command’s output to another, however, the information from cmd1 doesn’t produce output to the screen. The pipe redirects that output as input to cmd2 .
Note: Don’t confuse pipe ( | ) redirection with file redirection ( > ) and ( ). (An example of file redirection: cmd1 > file or cmd1 .) File redirection either sends output to a file instead of the screen, or pulls input from a file.
Let’s look at some real-world examples of how piping works.
Checking on NICs
Let’s say that you need to know if one of your network interface cards (NICs) has an IP address beginning with 192:
$ ifconfig | grep 192
inet 192.168.1.96 netmask 255.255.255.0 broadcast 192.168.1.255
You can also find out which live NICs you have on a system with a simple pipe to grep :
$ ifconfig | grep UP
enp0s3: flags=4163 mtu 1500
lo: flags=73 mtu 65536
You could also grep for «RUNNING» or «RUN» to display the same information.
Examining permissions
Maybe you want to find out how many directories under /etc are writeable by root:
$ sudo ls -lR | grep drwx
The results are too long to list here, but as you can see from your displayed list, there are a lot of them. You still need to find out how many there are, and a visual count would take a long time. An easy option is to pipe the results of your ls command to the wc (word count) command:
$ sudo ls -lR | grep drwx | wc -l
The -l switch displays the number of lines. Your count might be different. This listing is from a fresh «RHEL 8 server no GUI» install.
[Want to try out Red Hat Enterprise Linux? Download it now for free.]
Counting files
You don’t have to use grep all the time. For example, you can list the number of files in the /etc directory with this:
Again, your results might look different, but you know something is wrong if the command returns a small number of files.
Identifying processes
You can also perform complex tasks using pipes. To list the process IDs (PIDs) for all systemd -related processes:
$ ps -ef | grep systemd | awk ‘< print $2 >‘
The awk command’s $2 output isolates the second (PID) column from the ps command. Note that the last entry, PID 17242 , is actually the PID for the grep command displaying this information, as you can see from the full listing results here:
khess 17242 7505 0 09:40 pts/0 00:00:00 grep —color=auto systemd
To remove this entry from your results, use the pipe operator again:
$ ps -ef | grep systemd | awk ‘< print $2 >‘ | grep -v grep
The -v switch tells the grep command to invert or ignore lines that contain the string that follows—in this case any line containing the word «grep.»
Sorting results
Another popular use of the pipe operator is to sort your results by piping to the sort command. Say that you want to sort the list of names in contacts.txt . First, let’s look at the contents as they are in the file before sorting:
Bob Jones
Leslie Smith
Dana David
Susan Gee
Leonard Schmidt
Linda Gray
Terry Jones
Colin Doe
Jenny Case
Now, sort the list:
$ cat contacts.txt | sort
Bob Jones
Colin Doe
Dana David
Jenny Case
Leonard Schmidt
Leslie Smith
Linda Gray
Susan Gee
Terry Jones
You can reverse the sort order with the -r switch:
$ cat contacts.txt | sort -r
Terry Jones
Susan Gee
Linda Gray
Leslie Smith
Leonard Schmidt
Jenny Case
Dana David
Colin Doe
Bob Jones
Was the output for either of these what you expected? By default, the sort command performs a dictionary sort on the first word or column, which is why Bob Jones and Terry Jones are not listed one after the other.
You can sort by the second column with the -k switch, specifying the column you want to sort on, which in our list is column two:
$ cat contacts.txt | sort -k2
Jenny Case
Dana David
Colin Doe
Susan Gee
Linda Gray
Bob Jones
Terry Jones
Leonard Schmidt
Leslie Smith
If you have a long contact list and you think that this list contains duplicate entries, you can pipe your list to sort and then uniq to remove those duplicates:
$ cat contacts.txt | sort | uniq
This command only displays unique entries, but it doesn’t save the results. To sort the file, filter unique entries, and then save the new file, use this:
$ cat contacts.txt | sort -k2 | uniq > contact_list.txt
Remember that the pipe operator and the file redirect operators do different things.
Wrapping up
Now that you’ve had a taste of the command line’s power, do you think you can handle the responsibility? Command line utilities have more flexibility than their graphical counterparts do. And for some tasks, there are no graphical equivalents.
The best way to learn command line behavior is to experiment. For example, the sort command didn’t do what you thought it should until you explored further. Don’t forget to use the power of your manual ( man ) pages to find those «hidden» secret switches and options that turn command line frustration into command line success.
Источник



