- Команда Grep в Linux (поиск текста в файлах)
- Командный синтаксис grep
- Искать строку в файлах
- Инвертировать соответствие (исключить)
- Использование Grep для фильтрации вывода команды
- Рекурсивный поиск
- Показать только имя файла
- Поиск без учета регистра
- Искать полные слова
- Показать номера строк
- Подсчет совпадений
- Бесшумный режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск нескольких строк (шаблонов)
- Строки печати перед матчем
- Печатать строки после матча
- Выводы
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Рекурсивно найти слово в файлах и папках Linux
- Найти фразу в файлах рекурсивно через консоль
- Поиск слова через Midnight Commander
- Поиск строки во всех файлах директории на Linux
Команда Grep в Linux (поиск текста в файлах)
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
- OPTIONS — Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.
- PATTERN — Шаблон поиска.
- FILE — Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или —invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или —recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или —dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или —files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
Результат будет выглядеть примерно так:
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или —ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или —word-regexp ).
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
Показать номера строк
Параметр -n (или —line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или —count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
Бесшумный режим
-q (или —quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте символ $ (доллар), чтобы найти выражение в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте расширение . (точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используйте [^ ] для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и т. Д., Но не будет соответствовать строкам, содержащим cola ,
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
Строки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или —before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или —after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Рекурсивно найти слово в файлах и папках Linux
Великая сила grep
2 минуты чтения
Дистрибутив Linux, несмотря на версию и вид, имеет множество графических оболочек, которые позволяют искать файлы. Большинство из их них позволяют искать сами файлы, но, к сожалению, они редко позволяют искать по содержимому. А особенно рекурсивно. В статье покажем два способа того, как можно рекурсивно найти файлы, которые содержат ту или иную фразу. Поиск будет осуществлен по папкам и директориям внутри этих папок.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Найти фразу в файлах рекурсивно через консоль
Все просто. Открываем серверную консоль, подключившись по SSH. А далее, вводим команду:
Например, команда может выглядеть вот так:
Команда найдет и выведет все файлы, которые содержат фразу merionet в директории /home/user/merion и во всех директориях, внутри этой папки. Мы используем следующие ключи:
- -i — игнорировать регистра текста (большие или маленькие буквы);
- -R — рекурсивно искать файлы в сабдиректориях;
- -I — показывать названия файлов, вместо их содержимого;
Так же, вам могут быть полезны следующие ключи:
- -n — показать номер строки, в которой находится фраза;
- -w — показать место, где слово попадается;

Поиск слова через Midnight Commander
Так же, в консоли сервера, дайте команду:
Эта команда запустит Midnight Commander. Кстати, если он у вас не установлен, его можно просто установить через yum:
Открыв mc, во вкладке Command выберите Find File и заполните поисковую форму как показано ниже:
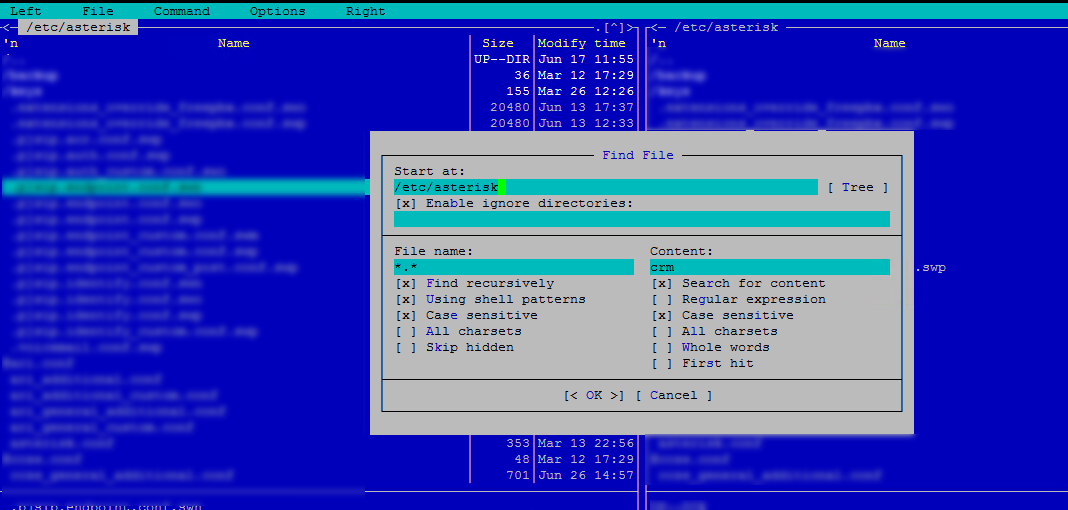
- Start at: — директория, где нужно осуществлять поиск;
- File name: — маска поиска. Например, искать только в файлах расширения txt будет — *.txt;
- Content — сама фраза;
Нажимаем OK и получаем результат:
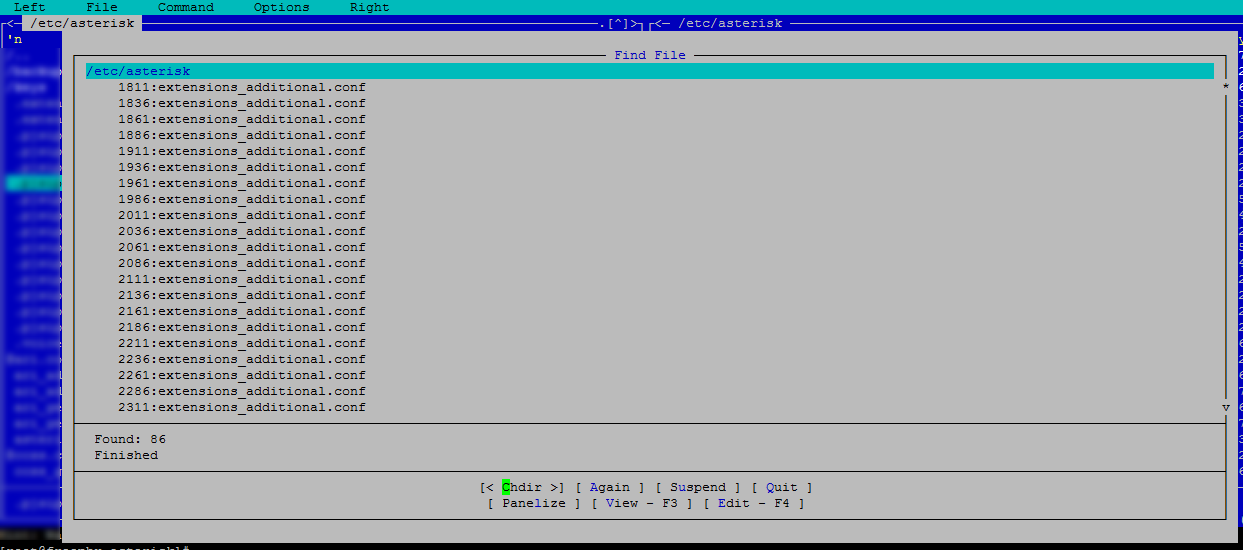
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
Поиск строки во всех файлах директории на Linux

В Linux сложные вещи делаются очень просто. Это, наверное, можно взять как слоган для всех операционных систем на ядре Linux. Как же много времени может экономить операционная система для занятого человека.
Вот, к примеру, такое простое действие как поиск одной фразы во всех документах компьютера. Для «голой» Windows – это непомерная задача. Конечно же что-то похожее реализовано в более свежих версиях Windows 7 и Windows 8, но их реализация настолько далеко от совершенства, что даже и вспоминать о них не хочется.
В Linux все проще.
Если быть точным, то просто в разы проще.
Для операционной системы Windows есть конечно же всевозможные текстовые редакторы, которые умеют искать точные вхождения фразы в файлах одной директории и ее поддиректориях. Но для этого нужно загрузить и установить этот редактор. Короче одни сложности.
В Linux всё мегапросто. Поиск строки во всех файлах можно организовать всего лишь одной командой в консоли:
где фраза – это фраза, а , путь_до_директории – это то место откуда нужно начать поиски.
Поиск этой командой будет организован таим образом, что все вложенные директории любого уровня будут скрупулезно просмотрены на предмет точного вхождения искомой фразы.
Для меня, как для человека, который отвечает за работу целого сектора, поиск затерянной служебной записки, которая была написана фиг знает когда и кем, такой простой способ поиска – это сродни золотому Граалю.
Кстати, для того, чтобы запустить поиск по все директории документов нужно исполнить команду:
Фраза для поиска приведена для примера и эта команда, к сожалению, у меня ничего не нашла.
Источник



