- 1С в СУБД PostgreSQL на сервере Windows Server 2012
- Обязательный софт
- Необязательный, но желательный софт, который надежно работает в данной связке
- Если не ограничиваться исключительно тестированием, дополнительно надо будет приобрести.
- 6 шагов для организации работы 1С в СУБД PostgreSQL на сервере Windows Server 2012
- Установка 1С 8.2 и 8.3 на PostgreSQL в Windows
- Установка и настройка сервера 1С Предприятие
- Установка PostgreSQL
- Создание базы 1С на Постгри
- База знаний Try 2 Fix beta
- Настройка Сервера 1С:Предприятие 8.3 и PostgreSQL 9.4.2-1.1C. Полная инструкция
- Этап 0. Вводные данные.
- Этап 1. Установка Сервера 1С:Предприятие (64-bit) для Windows
- Этап 2. Установка PostgreSQL и pgAdmin.
- Этап 3. Создание информационной базы 1С.
- Эти статьи будут Вам интересны
- Ярлык Мой компьютер в Windows 10
- Установка МФУ HP MFP132nw на Windows Server 2008R2
- Установка компонентов для разработки ПО для Windows CE 6.0 (Visual Studio 2005 + Windows Embedded CE 6.0)
- База знаний «Try 2 Fix» Beta
- Заметки сисадмина о интересных вещах из мира IT, инструкции и рецензии. Настраиваем Компьютеры/Сервера/1С/SIP-телефонию в Москве
- Настройка PostgreSQL для работы в связке с 1С 8.х на платформе Windows Server 2012, объём БД более 200 Гб
1С в СУБД PostgreSQL на сервере Windows Server 2012
Обязательный софт
1. Установочный дистрибутив Windows Server 2012 standart, который можно скачать с официального сайта и бесплатно использовать 180 дней
2. Установочный дистрибутив 1С:Предприятие.
3. Установочный дистрибутив PostgreSQL (пропатченный разработчиками 1С). Этот дистрибутив есть на дисках ИТС программы 1С.
Необязательный, но желательный софт, который надежно работает в данной связке
1. Антивирус COMODO, который можно взять на официальном сайте бесплатно и свободном доступе
2. Программа Effector saver для организации резервного копирования.
3. Программа резервного копирования PostgreSQL Backup
4. Программа CCleaner
Если не ограничиваться исключительно тестированием, дополнительно надо будет приобрести.
1. Лицензионную Windows Server 2012 standart
2. Лицензии для доступа к серверу (это не физические (программные) фишки, а чисто юридические (просто бумаги).
3. Клиентские лицензии терминального доступа (на устройство или на пользователя)
4. Лицензионную программу 1С: Предприятие с аппаратными или программными ключами защиты
5. Серверный ключ защиты 1С
6 шагов для организации работы 1С в СУБД PostgreSQL на сервере Windows Server 2012
2. Поднятие терминального сервера в Windows Server 2012 standart
3. Установка 1С 8.х в файловом варианте (с учетом дальнейшего перехода на клиент-серверный режим работы)
6. Настройка резервного копирования с помощью программ Effector saver и PostgreSQL Backup. Установка антивируса COMODO

+7 (900) 947-32-32
Продажа кровельных материалов в пгт. Анна Воронежской области
Установка 1С 8.2 и 8.3 на PostgreSQL в Windows
PostgreSQL — достаточно современная и популярная СУБД в мире. Её не обошла и фирма 1С, выбрав в качестве одной из поддерживаемых для работы СУБД. Рассмотрим инструкцию по установке PostgreSQL и её первоначальной настройки для 1С 8.3 под ОС Windows.
PostgreSQL — бесплатная программа, это является одним из решающих факторов по выбору данной СУБД.
Для установки сервера нам понадобится два архива — сервера 1С предприятия (х86-64) и дистрибутив PostgreSQL. В нашем примере платформа версии 8.3.4, а СУБД 9.1.2. Их лучше взять из официальных источников 1С — диска или сайта ИТС.
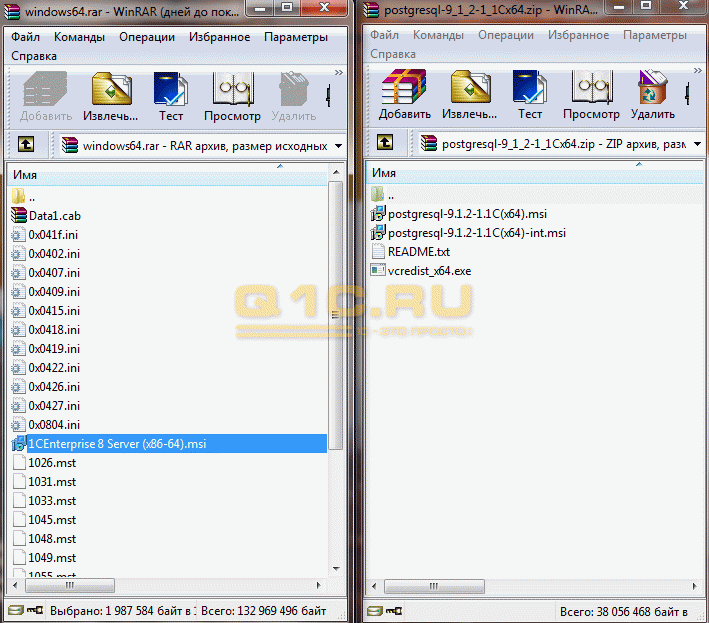
Установка и настройка сервера 1С Предприятие
Первым делом установим сервер 1C предприятия 8.3 (или 8.2). Для этого запустим файл setup.exe из архива. Установка мало чем отличается от обычной установки клиентского приложения, за исключением некоторых особенностей:
1. Не забудьте выбрать в компонентах нужные пункты:
Если вы только начинаете программировать в 1С или просто хотите систематизировать свои знания — попробуйте Школу программирования 1С нашего друга Владимира Милькина. Пошаговые и понятные уроки даже для новичка с поддержкой учителя.
Попробуйте бесплатно по ссылке >>
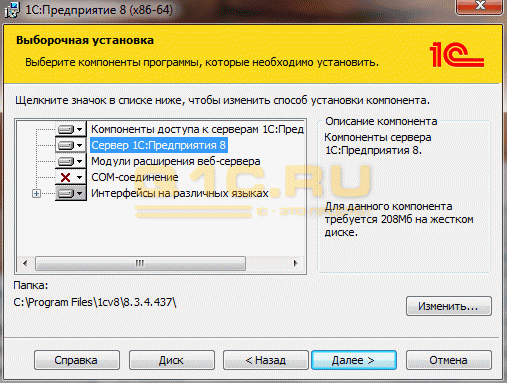
2. Указать, от чьего имени будет запускаться приложение. Рекомендуется создавать нового пользователя «USR1Cv8». У этого пользователя должны быть установлены нужные права:
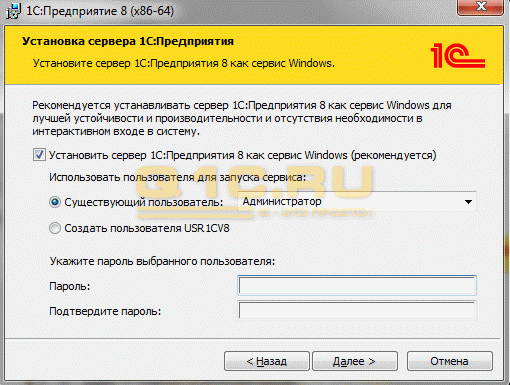
После установки части 1С можно приступить к работе с СУБД.
Установка PostgreSQL
Запустите файл postgresql-9.1.2-1.1C(x64).msi, в папке windows выбрать подпапку 64 или 86, в зависимости от разрядности ОС. Можно оставить практически всё по умолчанию. Необходимо обратить внимание на следующие моменты:
1. Так же, как с 1С 8.3, СУБД устанавливается как сервис. Необходимо проверить права у используемого пользователя. Система по умолчанию создаст нового пользователя, от чего имени будет запускать службу:
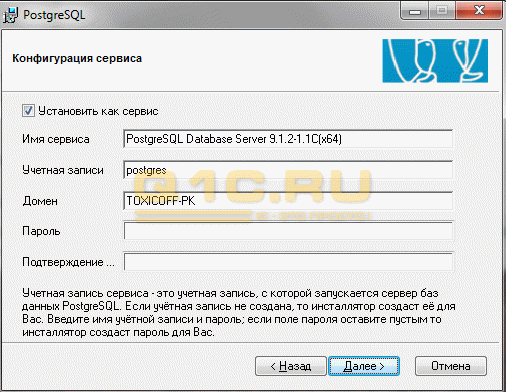
2. Настройка кластера 1C. Здесь необходимо указать пароль для пользователя:

Для выполнения данного пункта должна быть запущена служба «Вторичный вход в систему» (secondary logon). Если он не запущен, его следует запустить в списке всех сервисов:
 Далее — все настройки по умолчанию.
Далее — все настройки по умолчанию.
Создание базы 1С на Постгри
Создание базы — очень простой процесс. В списке баз необходимо нажать «Добавить», выбрать пункт «Создание новой информационной базы», указать название базы и выбрать вариант расположения — «На сервере 1С: Предприятия», где заполнить настройки подобно указанным на скриншоте:

Где пароль и имя пользователя те, которые Вы указывали на этапе настройки кластера.
Вот и всё — можно работать с системой.
Другие статьи по 1С:
К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области.
База знаний
Try 2 Fix beta
Настройка Сервера 1С:Предприятие 8.3 и PostgreSQL 9.4.2-1.1C. Полная инструкция

В этой инструкции мы расскажем (и покажем) как настроить связку 1С:Предприятие 8.3 и PostgreSQL 9.4.2 с момента установки обоих сервисов, вплоть до создания информационной базы. Про тюнинг данной связки можно прочитать в другой нашей статье.
Этапы, которые нам предстоит пройти:
- Установка Сервера 1С:Предприятие (64-bit) для Windows
- Установка PostgreSQL 9.4.2-1.1С
- Создание Информационной базы данных.
Подробнее под катом!
Этап 0. Вводные данные.
Имя сервера — 1CServer
Имя учётной записи сервера — Администратор
Пароль учётной записи — 123456Ab
Имя учётной записи 1С на сервере — USR1CV8
Пароль учётной записи 1С на сервере — 123456Cd
Имя учётной записи PostgreSQL на сервере — postgres
Пароль учётной записи PostgreSQL на сервере — 123456Ef
Имя суперюзера PostgreSQL — postgres
Пароль суперюзера PostgreSQL — 1234
Имя тестовой базы данных — testdb
Этап 1. Установка Сервера 1С:Предприятие (64-bit) для Windows
- Заходим на сайт users.v8.1c.ru.
- Переходим в раздел Технологические дистрибутивы >Технологическая платформа 8.3 >8.3.8.2197 (не очень важно, но подальше от последней) >Cервер 1С:Предприятия (64-bit) для Windows >Скачать дистрибутив.
- Загружаем архив windows64.rar. Распаковываем его.
- Начинаем установку через setup.exe.
- Просто проходим через каждый пункт до пункта «Установить сервер 1С:Предприятие 8 как сервис…». В данном пункте галочка должна стоять, радио-кнопку надо переключить в положение «Создать пользователя USR1CV8». Пароль может быть любым, но отвечающим политикам безопасности сервера Windows. В нашем примере это 123456Cd.

- Дальше опять никаких откровений — просто везде нажимаем «Далее». На этом мы пока завершаем работу с Сервером 1С:Предприятие и переходим к установке PostgreSQL.

Этап 2. Установка PostgreSQL и pgAdmin.
- Невероятных ссылок, откуда скачать PostgreSQL не будет — это наш любимый сайт https://releases.1c.ru, раздел «Технологические дистрибутивы». Скачиваем, ставим. Не забываем установить MICROSOFT VISUAL C++ 2010 RUNTIME LIBRARIES WITH SERVICE PACK 1, который идёт в архиве с дистрибутивом. Сами попались на это: не установили, испытали много боли.
- Ставим всё на «Далее», кроме следующих моментов. Устанавливаем, как сервис (галочка) и задаём параметры дляучётной записи Windows, не PostgreSQL (учётка, от имени которой будет работать служба). В нашем случае это postgres и 123456Ef. Пароль должен отвечать политикам безопасности сервера Windows.
- Инициализируем кластер базы данных (галочка). А вот здесь задаём параметры учётной записи для PostgreSQL! Важно: у Вас должна быть запущена служба «Secondary Logon» (или на локализированных ОС: «Вторичный вход в систему»). Кодировка UTF8 — это тоже важно! На этом этапе Имя суперюзера postgres, а пароль 1234.
- Дальше ничего интересного. Далее…
- pgAdmin в этой сборке староват. Идём на https://www.postgresql.org/ftp/pgadmin3/release/. На момент написания статьи самая свежая версия 1.22.1. Качаем её, ставим. Заходим.


Этап 3. Создание информационной базы 1С.
- Перед выполнением следующих операций, отключите IPv6 на Вашем сетевом интерфейсе: Центр управления сетями и общим доступом >Подключение по локальной сети >Свойства > Снимите галочку с Протокол Интернета версии 6 (TCP/IPv6).
- Запускаем клиентское 1С:Предприятие и добавляем новую базу данных.
- Создание новой информационной базы > Создание информационной базы без конфигурации (для примера, у Вас может быть любая конфигурация) > На сервере 1С:Предприятие >
- Заполняем все поля в соответствии с нашим примером (Этап 0):
Кластер серверов 1С:Предприятие: 1CServer
Имя информационной базы в кластере: testbd
Защищённое соединение: Выключено
Тип СУБД: PostgreSQL
Сервер баз данных: 1CServer
Имя базы данных: testbd
Пользователь базы данных: postgres
Пароль пользователя: 1234 - Далее, далее. Запускаем созданную базу в режиме предприятия — всё работает!
Ещё раз напоминаем, что PostgreSQL можно неплохо разогнать. Подробности в нашей статье.
И не забудьте про резервное копирование баз данных 1С!
Если с базой данных возникли какие-то проблемы, возможно, Вам поможет внутреннее или внешнее тестирование.
Базы данных 1С можно публиковать на веб-серверах!
Эти статьи будут Вам интересны
Ярлык Мой компьютер в Windows 10
По некой необъяснимой причине ярлык «Мой компьютер» или «Компьютер», или «Этот компьютер» исчез с рабочего стола в Windows 10. И вернуть его так же просто как это было в Windows 7 (перетаскиванием из меню «Пуск») или Windows XP уже не получается. Но мы поможем справиться с этой бедой.
Установка МФУ HP MFP132nw на Windows Server 2008R2
28 декабря 2016 ВК Tw Fb
Как ни странно, стандартными способами в стиле «Скачал драйверы — установил — забыл» такую связку не настроить. После загрузки «Полнофункционального ПО и драйверов для HP LaserJet Pro MFP M130nw-M132nw» программа установки выдаёт сообщение о том, что у нас неподходящая ОС. Через «Устройства и принтеры → Добавить сетевой принтер. » тоже ничего не сделать: драйверов для этой свежей модели МФУ нет на серверах Microsoft. Используем джедайские методы!
Установка компонентов для разработки ПО для Windows CE 6.0 (Visual Studio 2005 + Windows Embedded CE 6.0)
В статье рассказываем как развернуть среду разработки программного обеспечения для Windows CE 6.0. Ничего сложного, конечно же, нет, но за годы, прошедшие с момента релиза Microsoft Visual Studio 2005 и Windows Embedded CE 6.0, эти компоненты обросли наборами дополнений, которые тоже необходимы. И устанавливать их надо в определённой последовательности. В качестве ОС мы выбрали Windows XP Pro SP3, так как наши устанавливаемые пакеты разрабатывались под неё.
База знаний «Try 2 Fix» Beta
Все материалы свободны
к распространению с обязательным
указанием источника
Заметки сисадмина о интересных вещах из мира IT, инструкции и рецензии. Настраиваем Компьютеры/Сервера/1С/SIP-телефонию в Москве
Настройка PostgreSQL для работы в связке с 1С 8.х на платформе Windows Server 2012, объём БД более 200 Гб
PostgreeSQL может работать с большими базами данных, не уступая по скорости и надёжности MSSQL. Всё зависит от настроек этой СУБД в файле postgresql.conf . Единственный минус – скорость разворачивания большой БД через dt-шник (10 часов) и скорость создания копии БД (5 часов c помощью pgdump при работающих пользователях, но ПЛЮС – всего 1 час выгрузкой в dt-шник из конфигуратора при неработающих пользователях).
У нас тяжёлая конфигурация 1С КА 1.1.80.1, 50 одновременно работающих пользователей. Более 1 млн. проводок при закрытии месяца. Время закрытия месяца сравнимо с MSSQL и составляет в среднем 2 часа. Время отмены закрытия месяца – всего 10 минут! Ликвидированы зависания PostgreSQL. Всё за счет настроек файла postgesql.conf.
# Оптимальные настройки для сервера PostgreeSQL сборки postgresql-9.4.2-1.1C с тяжелыми базами данных и тяжёлыми запросами (подробное описание)
# Процессоры: Intel (R) Xeon (R) E5620 2.4 GHz (2 процессора по 8 ядер каждый) х64
# ОЗУ: 48 ГБ 1068MHz
# Дисковый массив уровня RAID 10: 4 диска по 800 ГБ, сумарный объем дискового массива 1600 ГБ
# ОС: Windows Server 2012 R2 Standard х64
# База данных: 1С КА текущий объем 215 ГБ, суммарный объём всех планируемых баз данных 1500 ГБ
# Сервер 1С 8.3.8.2137 х64 запущен на этой же машине.
# Текущее распределение памяти в ОС смотрим в Диспетчере задач закладка Производительность-> Память:
# Используется: Доступно: Выделено: КЭШИРОВАНО: Выгружаемый Пул: Невыгружаемый пул:
# 15,2 ГБ 30,7 ГБ 15,6/54,9 ГБ 30,5 ГБ 484 МБ 85,3 МБ
# Итак, необходимые настройки postgresql.conf
effective_cache_size = 30GB # чуть меньше 2/3 от доступного объема памяти (=текущий размер кэша ОС см. КЭШИРОВАНО=30,5 ГБ в Диспетчере задач)
#PostgreSQL в своих планах запросов опирается на кэширование файлов, осуществляемое операционной системой. Этот параметр соответствует максимальному размеру объекта, который может поместиться в системный кэш. Это значение используется только для оценки. effective_cache_size можно установить в 1/2 – 2/3 от объёма имеющейся в наличии оперативной памяти, если вся она отдана в распоряжение PostgreSQL.
#Начиная с версии PostreSQL 8.2 изменена работа оптимизатора запросов. Теперь она существенно зависит от размера выделенной PostreSQL оперативной памяти.
#При использовании сборки PostgreSQL-9.4.2-1.1C при работе с 1С:Предприятием 8 рекомендуется увеличить значение параметра effective_cache_size в конфиргурационном файле postgresql.conf до предела.
# В нашем данном случае предельный размер определяется Кэшем ОС = 30,5 Гб после запуска службы сервера PostgreSQL. Значение параметра корректируем по мере уменьшения кэша ОС в процессе работы системы, а также уменьшение может потребоваться, если мы увеличим параметры, изменяющие распределение памяти ,например, shared_buffers.
shared_buffers = 6GB # 1/8 RAM или больше (но не более 1/4). В нашем случае сложные запросы, тяжелые транзакции, 48 ГБ ОЗУ, но такого объема пока хватает (можно как в рекомендации: от 1/8 RAM = 6GB до 1/4 RAM = 12GB). При большом количестве строк данных записываемых в одной транзакции объем буфера должен быть увеличен, иначе PostgreSQL вылетит по ошибке. К примеру, для 1С поводом увеличить буфер является запись свыше 5000-6000 строк в табличную часть одного документа с помощью обработки и последующая запись или проведение этого документа.
#На выделенных серверах полезным объемом будет значение от 8 МБ до 2 ГБ. Объем может быть выше, если у вас большие активные порции базы данных, сложные запросы, большое число одновременных соединений, длительные транзакции, вам доступен большой объем оперативной памяти или большее количество процессоров. И, конечно же, не забываем об остальных приложениях. Выделив слишком много памяти для базы данных, мы можем получить ухудшение производительности.
# Объём совместно используемой памяти, выделяемой PostgreSQL для кэширования данных, определяется числом страниц (shared_buffers) по 8 килобайт каждая. Следует учитывать, что операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память. Размер shared_buffers зависит от многих факторов, для начала можно принять следующие значения:
#8–16 Мб – Обычный настольный компьютер с 512 Мб и небольшой базой данных
#80–160 Мб – Небольшой > сервер, предназначенный для обслуживания базы данных с объёмом оперативной памяти 1 Гб и базой данных около 10 Гб.
#400 Мб – Сервер с несколькими процессорами, с объёмом памяти в 8 Гб и базой данных занимающей свыше 100 Гб обслуживающий несколько сотен активных соединений одновременно.
#Примеры:
#Laptop, Celeron processor, 384 МБ RAM, база данных 25 МБ: 12 МБ
#Athlon server, 1 ГБ RAM, база данных поддержки принятия решений 10 ГБ: 200 МБ
#Quad PIII server, 4 ГБ RAM, 40 ГБ, 150 соединений, «тяжелые» транзакции: 1 ГБ
#Quad Xeon server, 8 ГБ RAM, 200 ГБ, 300 соединений, «тяжелые» транзакции: 2 ГБ
#Intel Xeon server, 48 ГБ RAM, 800 ГБ, 100 соединений, «тяжелые» транзакции: 6 ГБ
#Если объём буфера недостаточен для хранения часто используемых рабочих данных, то они будут постоянно писаться и читаться из кэша ОС или с диска, что крайне отрицательно скажется на производительности.
#В то же время не следует устанавливать это значение слишком большим: это НЕ вся память, которая нужна для работы PostgreSQL, это только размер разделяемой между процессами PostgreSQL памяти, которая нужна для выполнения активных операций. Она должна занимать меньшую часть оперативной памяти вашего компьютера, так как PostgreSQL полагается на то, что операционная система кэширует файлы, и не старается дублировать эту работу. Кроме того, чем больше памяти будет отдано под буфер, тем меньше останется операционной системе и другим приложениям, что может привести к своппингу.
#К сожалению, чтобы знать точное число shared_buffers, нужно учесть количество оперативной памяти компьютера, размер базы данных, число соединений и сложность запросов, так что лучше воспользуемся несколькими простыми правилами настройки.
#Для тонкой настройки параметра установите для него большое значение и потестируйте базу при обычной нагрузке. Проверяйте использование разделяемой памяти при помощи ipcs или других утилит(например, free или vmstat). Рекомендуемое значение параметра будет примерно в 1,2 -2 раза больше, чем максимум использованной памяти. Обратите внимание, что память под буфер выделятся при запуске сервера, и её объём при работе не изменяется. Учтите также, что настройки ядра операционной системы могут не дать вам выделить большой объём памяти.
max_connections = 100 # максимальное число клиентских подключений, которые могут подсоединяться к базе данных одновременно (взято с запасом)
# не может быть бесконечным. Каждое подсоединение порождает ещё один процесс postmaster, что, естественно, требует ресурсов. Средней «паршивости» современный однопроцессорный компьютер со стандартным наполнении без особых проблем может обслуживать 100-200 соединений, но, например, 600 активных соединений будут уже явной проблемой. Любая попытка подсоединиться сверх указанного лимита приведёт к отказу от обслуживания. Плохо написанная программа в цикле открывающая, но не закрывающая за собой соединения, легко создаст проблему. Если число клиентов жёстко ограничено, то имеет смысл уменьшить этот параметр до минимально возможного значения.
maintenance_work_mem = 2024MB # увеличить до рекомендуемого размера не позволяет сам сервер PostgreSQL, при увеличении служба сервера не стартует. (рекомендуемый размер 1/4 RAM = 12GB)
# Эта память используется для выполнения операций по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и для добавления внешних ключей (FOREGIN KEY). Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске. Как и в случае work_mem эта переменная может быть установлена прямо во время выполнения запроса.
work_mem = 2024MB # увеличить до рекомендуемого размера не позволяет сам сервер PostgreSQL, при увеличении служба сервера не стартует. (рекомендуемый размер 1/20 RAM = 2,4GB)
# Под каждый запрос можно выделить личный ограниченный объём памяти для работы. Этот объём может использоваться для сортировки, объединения и других подобных операций. При превышении этого объёма сервер начинает использовать временные файлы на диске, что может существенно замедлить скорость обработки запросов. Предел для work_mem можно вычислить, разделив объём доступной памяти (физическая память минус объём занятый под другие программы и под совместно используемые страницы shared_buffers) на максимальное число одновременно используемых активных соединений. При необходимости, например, выполнения очень объёмных операций, допустимый лимит можно изменять прямо во время выполнения запроса. Поэтому нет нужды изначально задавать теоретический предел.
temp_buffers = 2024MB # увеличить до рекомендуемого размера не позволяет сам сервер PostgreSQL, при увеличении служба сервера не стартует. (рекомендуемый размер 1/20 RAM = 2,4GB)
# Буфер под временные объекты, в основном для временных таблиц.
wal_sync_method = open_datasync # наилучший по тесту для Windows (для Линукс = fdatasync)
# На производительность PostgreSQL оказывает существенное влияние производительность дисковой системы. В конфигурационном файле postgresql.conf есть несколько параметров, значения которых могут оказать существенное влияние на производительность:
#fsync
#По умолчанию, параметр fsync включен. Это означает, что при выполнении операции COMMIT данные сразу переписываются из кеша операционной системы на диск, тем самым гарантируется консистентность при возможном аппаратном сбое. Обратной стороной этого является снижение производительности операций записи на диск, поскольку при этом не используются возможности отложенной записи данных операционной системы.
#Отрицательное влияние включенного fsync можно уменьшить, отключив его, положившись на надежность вашего оборудования, или правильно подобрав параметр wal_sync_method – метод, который используется для принудительной записи данных на диск.
#Возможные значения:
#open_datasync – запись данных методом open() с параметром O_DSYNC,
#fdatasync – вызов метода fdatasync() после каждого commit,
#fsync_writethrough – вызывать fsync() после каждого commit игнорирую паралельные процессы,
#fsync – вызов fsync() после каждого commit,
#open_sync – запись данных методом open() с параметром O_SYNC.
#Не все методы доступны на определенных платформах. Выбор метода зависит от операционной системы под управлением, которой работает PostgreSQL.
#В состав PostgreSQL входит утилита pg_test_fsync, с помощью которой можно определить оптимальное значение параметра wal_sync_method.
#Она выполняет серию дисковых тестов с использованием различных методов синхронизации. В результате этого теста получаются оценки производительности #дисковой системы, по которым можно определить оптимальный метод синхронизации для данной опереционной системы
checkpoint_segments = 24 #можно до 32 – подбирается экспериментально
#Журнал транзакций PostgreSQL работает следующим образом: все изменения в файлах данных (в которых находятся таблицы и индексы) производятся только после того, как они были занесены в журнал транзакций, при этом записи в журнале должны быть гарантированно записаны на диск.
#В этом случае нет необходимости сбрасывать на диск изменения данных при каждом успешном завершении транзакции: в случае сбоя БД может быть восстановлена по записям в журнале. Таким образом, данные из буферов сбрасываются на диск при проходе контрольной точки: либо при заполнении нескольких (параметр checkpoint_segments, по умолчанию 3) сегментов журнала транзакций, либо через определённый интервал времени (параметр checkpoint_timeout, измеряется в секундах, по умолчанию 300).
#Изменение этих параметров прямо не повлияет на скорость чтения, но может принести большую пользу, если данные в базе активно изменяются.
#1 Уменьшение количества контрольных точек: checkpoint_segments
#Если в базу заносятся большие объёмы данных, то контрольные точки могут происходить слишком часто2. При этом производительность упадёт из-за постоянного сбрасывания на диск данных из буфера.
#Для увеличения интервала между контрольными точками нужно увеличить количество сегментов журнала транзакций (checkpoint_segments). Данный параметр определяет количество сегментов (каждый по 16 МБ) лога транзакций между контрольными точками. Этот параметр не имеет особого значения для базы данных, предназначенной преимущественно для чтения, но для баз данных со множеством транзакций увеличение этого параметра может оказаться жизненно необходимым. В зависимости от объема данных установите этот параметр в диапазоне от 12 до 256 сегментов и, если в логе появляются предупреждения (warning) о том, что контрольные точки происходят слишком часто, постепенно увеличивайте его. Место, требуемое на диске, вычисляется по формуле (checkpoint_segments * 2 + 1) * 16 МБ, так что убедитесь, что у вас достаточно свободного места. Например, если вы выставите значение 32, вам потребуется больше 1 ГБ дискового пространства.
#Следует также отметить, что чем больше интервал между контрольными точками, тем дольше будут восстанавливаться данные по журналу транзакций после сбоя.
checkpoint_completion_target = 0.9 # рекомендуемое максимальное значение
# Чтобы избежать “завала” большим количеством системных операций дискового ввода/вывода из-за взрывного количества операций записи страниц, запись заполненных буферов во время контрольной точки “размазывается” на определённый период времени. Этот период управляется параметром checkpoint_completion_target, который задаётся как часть интервала контрольной точки. Количество данных ввода/вывода согласуется так, чтобы контрольная точка завершалась, когда данная часть checkpoint_segments сегментов WAL будет израсходована с момента старта контрольной точки или когда заданная часть checkpoint_timeout секунд истечёт, смотря какое событие из вышеуказанных наступит быстрее. С значением 0.5, заданным по умолчанию, PostgreSQL может ожидать завершения каждой контрольной точки примерно половину времени перед стартом следующей контрольной точки. На системах, которые очень близки к максимальному потоку данных ввода/вывода во время обычного функционирования, вы возможно захотите увеличить checkpoint_completion_target, чтобы снизить загрузку по вводу/выводу, возникающую из-за контрольных точек. Недостаток такого подхода состоит в том, что пролонгированные контрольные точки влияют на время восстановления, потому что при восстановлении нужно будет использовать большее количество сегментов WAL. Хотя значение checkpoint_completion_target может быть установлено столь высоким как 1.0, лучше оставить его поменьше (по крайней мере, предположительно, меньше 0.9), так как контрольные точки включают некоторые другие операции, помимо записи заполненных буферов. Установка значения 1.0 вполне вероятно приведёт к тому, что контрольные точки не будут завершаться вовремя, что приведёт к потере производительности из-за неожиданного изменения количества необходимых сегментов WAL.
default_statistics_target = 300 # количество записей, просматриваемых при сборе статистики по таблицам. По умолчанию – 100, 1С рекомендует от 1000 до 10000 при зависании запросов к БД
#Этот параметр задаёт объём статистики, собираемой командой ANALYZE. Увеличение параметра заставит эту команду работать дольше, но может позволить оптимизатору строить более быстрые планы запросов, используя полученные дополнительные данные. Объём статистики для конкретного поля может быть задан командой ALTER TABLE …SET STATISTICS.
constraint_exclusion = partition # включаем партиционирование таблиц только для партиционированных таблиц
#Начиная с 8.4 версии PostgreSQL «constraint_exclusion» может быть «on», «off» и «partition». По умолчанию (и рекомендуется) ставить «constraint_exclusion» не «on», и не «off», а «partition», который будет проверять «CHECK» только на партиционированых таблицах.
#ну и 1С-специфические настройки:
escape_string_warning = off #чтобы лог не засорялся соответствующими предупреждениями по \
standard_conforming_strings = off # отключение \ как спецсимвола
#Следующие ниже настройки используются, если база начала подвисать:
join_collapse_limit = 6 # по умолчанию 8 . Внимание. Для 1С не стоит устанавливать значение этого параметра равным 1, как в рекомендациях фирмы 1С. Иначе сложные запросы с большим количеством соединений и источников данных станут надолго зависать. Примером для КА являются: документ Инвентаризационная опись основных средств, Отчет по временным разницам и т.п., поскольку данные отчеты используют множество соединений с таблицами регистров сведений.
#Задаёт максимальное количество элементов в списке FROM, до достижения которого планировщик будет сносить в него явные конструкции JOIN (за исключением FULL JOIN). При меньших значениях сокращается время планирования, но план запроса может стать менее эффективным.
#По умолчанию эта переменная имеет то же значение, что и from_collapse_limit, и это приемлемо в большинстве случаев. При значении, равном 1, предложения JOIN переставляться не будут, так что явно заданный в запросе порядок соединений определит фактический порядок, в котором будут соединяться отношения. Так как планировщик не всегда выбирает оптимальный порядок соединений, опытные пользователи могут временно задать для этой переменной значение 1, а затем явно определить желаемый порядок.
seq_page_cost = 0.1 # стоимость последовательного чтения страниц
#Задаёт приблизительную стоимость чтения одной страницы с диска, которое выполняется в серии последовательных чтений. Значение по умолчанию равно 1.0. Это значение можно переопределить для таблиц и индексов в определённом табличном пространстве, установив одноимённый параметр табличного пространства (см. ALTER TABLESPACE).
random_page_cost = 0.4 # стоимость случайного чтения страниц
#Задаёт приблизительную стоимость чтения одной произвольной страницы с диска. Значение по умолчанию равно 4.0. Это значение можно переопределить для таблиц и индексов в определённом табличном пространстве, установив одноимённый параметр табличного пространства (см. ALTER TABLESPACE).
cpu_operator_cost = 0.00025 # стоимость одного оператора запроса
#Задаёт приблизительную стоимость обработки оператора или функции при выполнении запроса. Значение по умолчанию — 0.0025
max_locks_per_transaction = 248 # 64 по умолчанию. Пришлось увеличить этот параметр одновременно с shared_buffers из-за записи более 5000 строк в табличной части одного документа 1С. При заданном по умолчанию параметре PostgreSQL вылетала по ошибке.
#Общая таблица блокировок отслеживает блокировки для max_locks_per_transaction * (max_connections + max_prepared_transactions) объектов (например, таблиц); таким образом, в любой момент времени может быть заблокировано не больше этого числа различных объектов. Этот параметр управляет средним числом блокировок объектов, выделяемым для каждой транзакции; отдельные транзакции могут заблокировать и больше объектов, если все они умещаются в таблице блокировок. Заметьте, что это не число строк, которое может быть заблокировано; их количество не ограничено. Значение по умолчанию, 64, как показала практика, вполне приемлемо, но может возникнуть потребность его увеличить, если запросы обращаются ко множеству различных таблиц в одной транзакции, как например, запрос к родительской таблице со многими потомками. Этот параметр можно задать только при запуске сервера.
Остальные настройки пока по умолчанию.
Сервер postgresql_9.6.1_4.1C_x64 RAM20Гб/1C/TS:
shared_buffers = 2048MB
effective_cache_size = 6GB
max_connections = 100
maintenance_work_mem = 1024MB
work_mem = 256MB
temp_buffers = 256MB
wal_sync_method = open_datasync
default_statistics_target = 300
escape_string_warning = off
standard_conforming_strings = off



