- Курс молодого бойца PostgreSQL
- 1. Использование временных таблиц
- 2. Часто используемый сокращенный синтаксис Postgres
- 3. Общие табличные выражения (CTE). Конструкция WITH
- 4. Функция array_agg(MyColumn).
- 5. Ключевое слово RETURNIG *
- 6. Сохранение результата запроса в файл
- 7. Выполнение запроса на другой базе
- 8. Функция similarity
- 9. Оконные функции OVER() (PARTITION BY __ ORDER BY __ )
- 10. Множественный шаблон для LIKE
- 11. Несколько полезных функций
- 12. Экранирование символов
- Заключение
- Резервное копирование и восстановление PostgreSQL: pg_dump, pg_restore, wal-g
- Создание резервных копий и восстановление из командной строки
- Утилита pg_dump
- Утилита pg_dumpall
- Утилита pg_restore
- Утилита pg_basebackup
- Утилита wal-g
- Утилита pgAdmin
- Работа с облачной базой данных в панели управления Selectel
- Заключение
Курс молодого бойца PostgreSQL

Хочу поделиться полезными приемами работы с PostgreSQL (другие СУБД имеют схожий функционал, но могут иметь иной синтаксис).
Постараюсь охватить множество тем и приемов, которые помогут при работе с данными, стараясь не углубляться в подробное описание того или иного функционала. Я любил подобные статьи, когда обучался самостоятельно. Пришло время отдать должное бесплатному интернет самообразованию и написать собственную статью.
Данный материал будет полезен тем, кто полностью освоил базовые навыки SQL и желает учиться дальше. Советую выполнять и экспериментировать с примерами в pgAdmin‘e, я сделал все SQL-запросы выполнимыми без разворачивания каких-либо дампов.
1. Использование временных таблиц
При решении сложных задач трудно поместить решение в один запрос (хотя, многие стараются так сделать). В таких случаях удобно помещать какие-либо промежуточные данные во временную таблицу, для использования их в дальнейшем.
Такие таблицы создаются как обычные, но с ключевым словом TEMP, и автоматически удаляются после завершения сессии.
Ключ ON COMMIT DROP автоматически удаляет таблицу (и все связанные с ней объекты) при завершении транзакции.
2. Часто используемый сокращенный синтаксис Postgres
- Преобразование типов данных.
Выражение:
можно записать менее громоздко:
- Сокращенная запись конструкции (I)LIKE ‘%text%’
LIKE воспринимает шаблонные выражения. Подробности в мануале
оператор LIKE можно заменить на
* (две тильды со звездочкой)
Поиск регулярными выражениями (имеет отличный от LIKE синтаксис)
оператор
* (одна тильда и звездочка) регистронезависимая версия
Приведу пример поиска разными способами строк, которые содержат слово text
| Cокращенный синтаксис | Описание | Аналог (I)LIKE |
|---|---|---|
| Проверяет соответствие выражению с учётом регистра | LIKE ‘%text%’ | |
| Проверяет соответствие выражению без учёта регистра | ILIKE ‘%text%’ | |
| ! ‘%text%’ | Проверяет несоответствие выражению с учётом регистра | NOT LIKE ‘%text%’ |
| ! * ‘%text%’ | Проверяет несоответствие выражению без учёта регистра | NOT ILIKE ‘%text%’ |
3. Общие табличные выражения (CTE). Конструкция WITH
Очень удобная конструкция, позволяет поместить результат запроса во временную таблицу и тут же использовать ее.
Примеры будут примитивны, чтобы уловить суть.
a) Простой SELECT
Таким способом можно ‘оборачивать’ какие-либо запросы (даже UPDATE, DELETE и INSERT, об этом будет ниже) и использовать их результаты в дальнейшем.
b) Можно создать несколько таблиц, перечисляя их нижеописанным способом
c) Можно даже вложить вышеуказанную конструкцию в еще один (и более) WITH
По производительности следует сказать, что не стоит помещать в секцию WITH данные, которые будут в значительной степени фильтроваться последующими внешними условиями (за пределами скобок запроса), ибо оптимизатор не сможет построить эффективный запрос. Удобнее всего положить в CTE результаты, к которым требуется несколько раз обращаться.
4. Функция array_agg(MyColumn).
Значения в реляционной базе хранятся разрозненно (атрибуты по одному объекту могут быть представлены в нескольких строках). Для передачи данных какому-либо приложению часто возникает необходимость собрать данные в одну строку (ячейку) или массив.
В PostgreSQL для этого существует функция array_agg(), она позволяет собрать в массив данные всего столбца (если выборка из одного столбца).
При использовании GROUP BY в массив попадут данные какого-либо столбца относительно каждой группы.
Сразу опишу еще одну функцию и перейдем к примеру.
array_to_string(array[], ‘;’) позволяет преобразовать массив в строку: первым параметром указывается массив, вторым — удобный нам разделитель в одинарных кавычках (апострофах). В качестве разделителя можно использовать
Выдаст результат:
Выполним обратное действие. Разложим массив в строки при помощи функции UNNEST, заодно продемонстрирую конструкцию SELECT columns INTO table_name. Помещу это в спойлер, чтобы статья не сильно разбухала.
5. Ключевое слово RETURNIG *
указанное после запросов INSERT, UPDATE или DELETE позволяет увидеть строки, которых коснулась модификация (обычно сервер сообщает лишь количество модифицированных строк).
Удобно в связке с BEGIN посмотреть на что именно повлияет запрос, в случае неуверенности в результате или для передачи каких либо id на следующий шаг.
Можно использовать в связке с CTE, организую безумный пример.
Таким образом, выполнится удаление данных, и удаленные значения передадутся на следующий этап. Все зависит от вашей фантазии и целей. Перед применением сложных конструкций обязательно изучите документацию вашей версии СУБД! (при параллельном комбинировании INSERT, UPDATE или DELETE существуют тонкости)
6. Сохранение результата запроса в файл
У команды COPY много разных параметров и назначений, опишу самое простое применение для ознакомления.
7. Выполнение запроса на другой базе
Не так давно узнал, что можно адресовать запрос к другой базе, для этого есть функция dblink (все подробности в мануале)
Если возникает ошибка:
«ERROR: function dblink(unknown, unknown) does not exist»
необходимо выполнить установку расширения следующей командой:
8. Функция similarity
Функция определения схожести одного значения к другому.
Использовал для сопоставления текстовых данных, которые были похожи, но не равны друг другу (имелись опечатки). Сэкономил уйму времени и нервов, сведя к минимуму ручную привязку.
similarity(a, b) выдает дробное число от 0 до 1, чем ближе к 1, тем точнее совпадение.
Перейдем к примеру. С помощью WITH организуем временную таблицу с вымышленными данными (и специально исковерканными для демонстрации функции), и будем сравнивать каждую строку с нашим текстом. В примере ниже будем искать то, что больше похоже на ООО «РОМАШКА» (подставим во второй параметр функции).
Получим следующий результат:
Если возникает ошибка
«ERROR: function similarity(unknown, unknown) does not exist»
необходимо выполнить установку расширения следующей командой:
Сортируем по similarity DESC. Первыми результатами видим наиболее похожие строки (1— полное сходство).
Необязательно выводить значение similarity в SELECT, можно просто использовать его в условии WHERE similarity(c_name, ‘ООО «РОМАШКА»’) >0.7
и самим задавать устраивающий нас параметр.
P.S. Буду признателен, если подскажете какие еще есть способы сопоставления текстовых данных. Пробовал убирать регулярными выражениями все кроме букв/цифр, и сопоставлять по равенству, но такой вариант не срабатывает, если присутствуют опечатки.
9. Оконные функции OVER() (PARTITION BY __ ORDER BY __ )
Почти описав в своем черновике этот очень мощный инструмент, обнаружил (с грустью и радостью), что подобная качественная статья на эту тему уже существует. Не вижу смысла дублировать информацию, поэтому рекомендую обязательно ознакомиться с данной статьей (ссылка — habrahabr.ru/post/268983/, автору низкий поклон ) тем, кто еще не умеет пользоваться оконными функциями SQL.
10. Множественный шаблон для LIKE
Задача. Необходимо отфильтровать список пользователей, имена которых должны соответствовать определенным шаблонам.
Как всегда, представлю простейший пример:
Имеем запрос, который выполняет свою функцию, но становится громоздким при большом количестве фильтров.
Продемонстрирую, как сделать его более компактным:
Можно проделать интересные трюки, используя подобный подход.
Напишите в комментариях, если есть мысли, как еще можно переписать исходный запрос.
11. Несколько полезных функций
NULLIF(a,b)
Возникают ситуации, когда определенное значение нужно трактовать как NULL.
Например, строки нулевой длины ( » — пустые строки) или ноль(0).
Можно написать CASE, но лаконичнее использовать функцию NULLIF, которая имеет 2 параметра, при равенстве которых возвращается NULL, иначе выводит исходное значение.
COALESCE выбирает первое не NULL значение
GREATEST выбирает наибольшее значение из перечисленных
LEAST выбирает наименьшее значение из перечисленных
PG_TYPEOF показывает тип данных столбца
PG_CANCEL_BACKEND останавливаем нежелательные процессы в базе
12. Экранирование символов
Начну с основ.
В SQL строковые значения обрамляются ‘ апострофом (одинарной кавычкой).
Числовые значения можно не обрамлять апострофами, а для разделения дробной части нужно использовать точку, т.к. запятая будет воспринята как разделитель
результат:
Все хорошо, до тех пор пока не требуется выводить сам знак апострофа ‘
Для этого существуют два способа экранирования (известных мне)
результат одинаковый:
В PostgreSQL существуют более удобный способ использовать данные, без экранирования символов. В обрамленной двумя знаками доллара $$ строке можно использовать практически любые символы.
получаю данные в первозданном виде:
Если этого мало, и внутри требуется использовать два символа доллара подряд $$, то Postgres позволяет задать свой «ограничитель». Стоит лишь между двумя долларами написать свой текст, например:
Увидим наш текст:
Для себя этот способ открыл не так давно, когда начал изучать написание функций.
Заключение
Надеюсь, данный материал поможет узнать много нового начинающим и «средничкам». Сам я не являюсь разработчиком, а могу лишь назвать себя любителем SQL, поэтому то, как использовать описанные приемы — решать Вам.
Желаю успехов в изучении SQL. Жду комментариев и благодарю за прочтение!
UPD. Вышло продолжение
Источник
Резервное копирование и восстановление PostgreSQL: pg_dump, pg_restore, wal-g


Задача резервного копирования — одна из основных при сопровождении и поддержке PostgreSQL. Для резервного копирования логической схемы и данных можно использовать как встроенные инструменты СУБД, так и внешние. В этой статье мы разберем оба варианта.
Для начала подготовим сервер. Для демо-стенда закажем виртуальный сервер в Облачной платформе. Для этого откроем панель управления my.selectel.ru, перейдем в меню Облачная платформа и нажмем на кнопку Создать сервер.
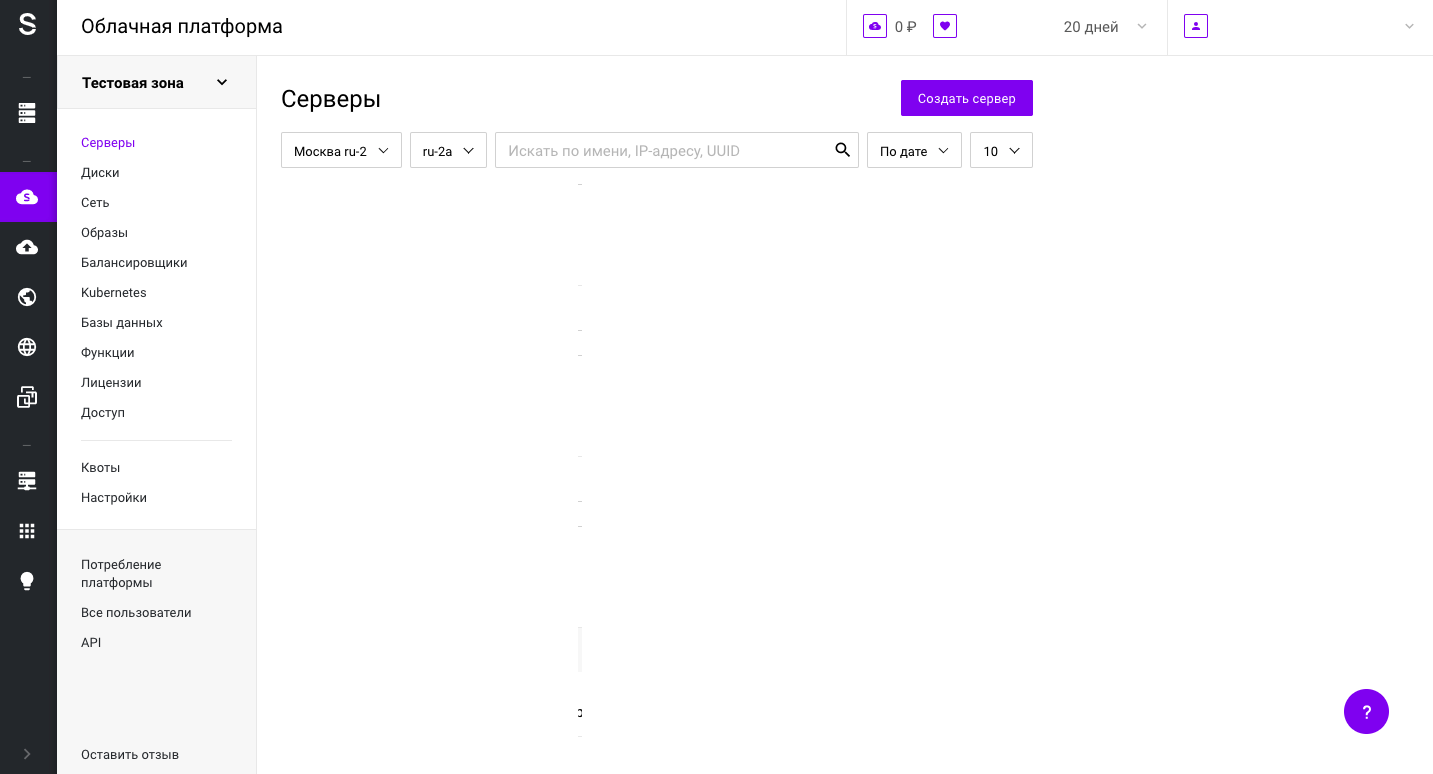
В статье будем использовать виртуальный сервер с конфигурацией 2 vCPU, 4 ГБ RAM и 10 ГБ HDD с операционной системой CentOS 8 64-bit.
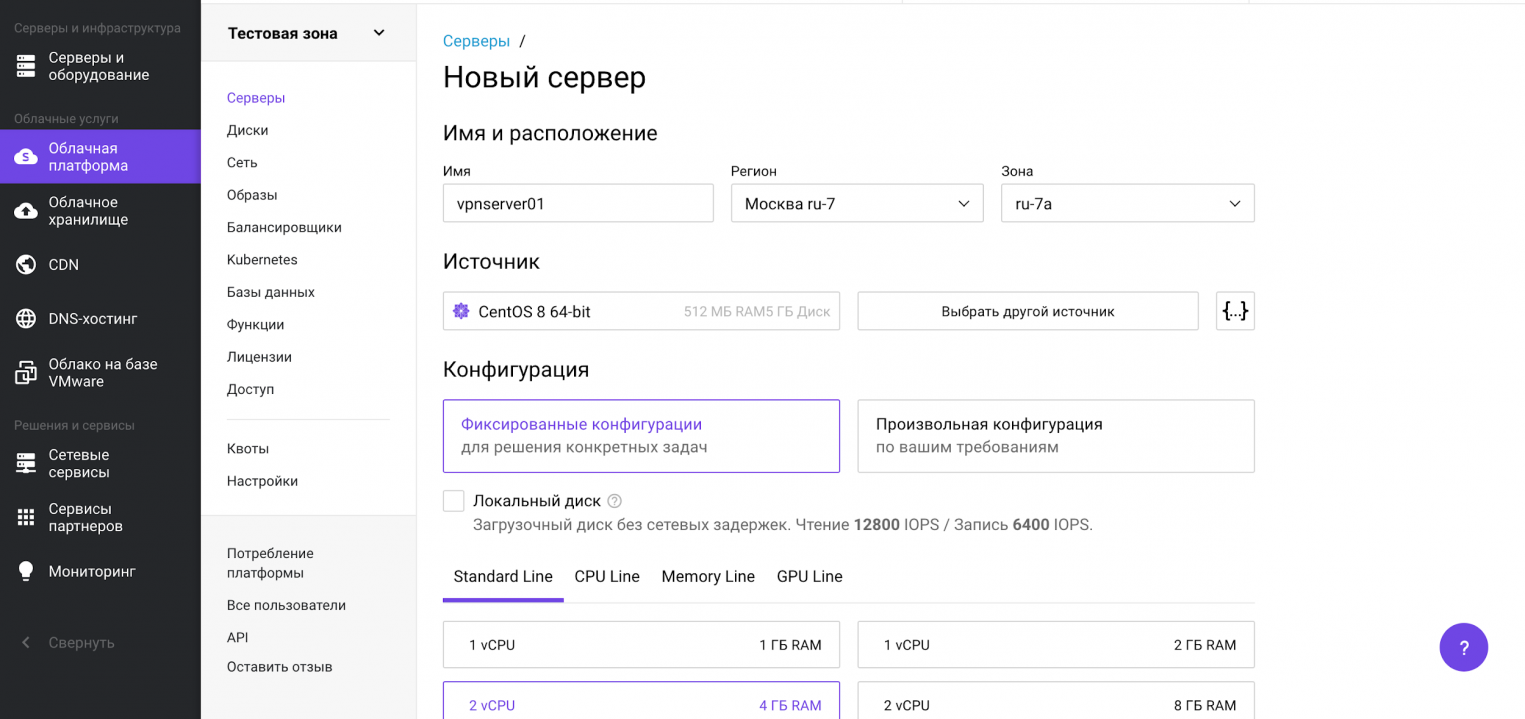
Теперь прокрутим представление ниже, где находятся настройки сети. Важно, чтобы у сервера был внешний плавающий IP-адрес для доступа извне.
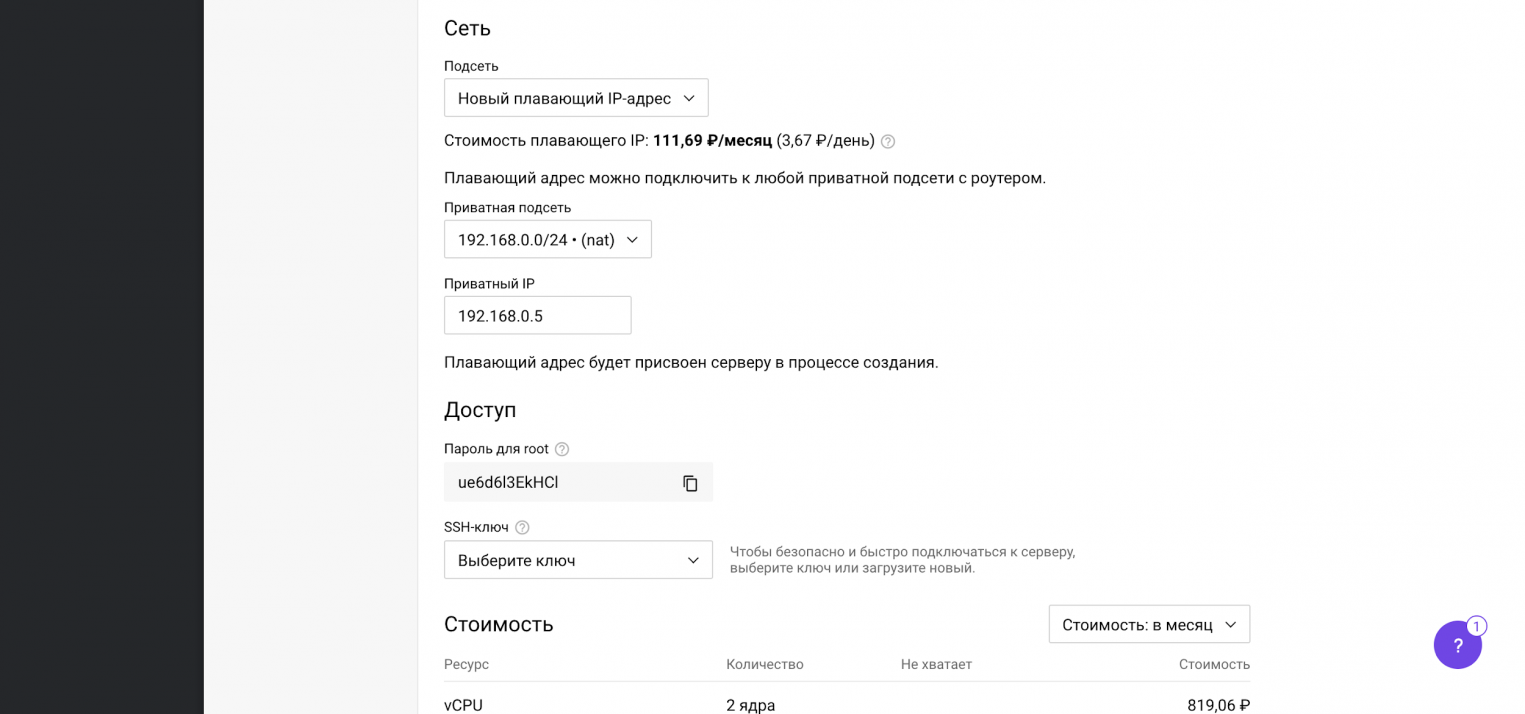
После выбора операционной системы, конфигурации сервера и выполнения сетевых настроек переходим к завершению заказа и нажимаем на кнопку Создать. Через несколько минут сервер будет готов.
Перед началом демонстрации возможностей резервного копирования, мы подготовили PostgreSQL. Для целей наполнения базы данных и создания непрерывного потока записи, развернули там Zabbix (некоторое время назад публиковали о нем статью).
Создание резервных копий и восстановление из командной строки
В этом разделе мы расскажем как сделать дамп базы данных PostgreSQL в консоли при подключении по SSH, разберем синтаксис и покажем примеры использования утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g.
Утилита pg_dump
В PostgreSQL есть встроенный инструмент для создания резервных копий — утилита pg_dump. Утилита имеет простой синтаксис:
В простейшем случае достаточно указать имя базы данных, которую в дальнейшем нужно будет восстановить. Резервная копия создается следующей командой:
Если требуется авторизация под определенным пользователем, можно воспользоваться ключом -U:
Ключ -U определяет пользователя, а -W обязывает ввести пароль.
Чтобы сэкономить место на диске, можно сразу же сжимать дамп:
Резервное копирование обычно выполняется по расписанию, например, ежедневно в 3 часа ночи. Нижеприведенный пример скрипта не только выполняет бэкап, но и удаляет все файлы старше 61 дня (за исключением 15-го числа месяца).
Чтобы настроить регулярное выполнение, выполним следующую команду в планировщике crontab:
Чтобы выполнить аналогичную команду на удаленном сервере, достаточно добавить ключ -h:
Ключ -t задает таблицу, для которой нужно создать резервную копию:
При помощи специальных ключей можно создавать резервные копии структуры данных или непосредственно данных:
У утилиты pg_dump также есть ключи для сохранения дампа в другие форматы. Чтобы сохранить копию в виде бинарного файла используются ключи -Fc:
Чтобы создать архив — -Ft:
Чтобы сохранить в directory-формате — -Fd:
Резервное копирование в виде каталогов позволяет выполнять процесс в многопоточном режиме.
Ниже мы перечислим возможные параметры утилиты pg_dump.
-d , —dbname=имя_бд — база данных, к которой выполняется подключение.
-h , —host=сервер — имя сервера.
-p , —port=порт — порт для подключения.
-U , —username=пользователь) — учетная запись, используемое для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой генерируется резервная копия.
-a, —data-only — вывод только данных, вместо схемы объектов (DDL).
-b, —blobs — параметр добавляет в выгрузку большие объекты.
-c, —clean — добавление команд DROP перед командами CREATE в файл резервной копии.
-C, —create — генерация реквизитов для подключения к базе данных в файле резервной копии.
-E , —encoding=кодировка — определение кодировки резервной копии.
-f , —file=файл — задает имя файла, в который будет сохраняться вывод утилиты.
-F , —format=формат — параметр определяет формат резервной копии. Доступные форматы:
- p, plain) — формирует текстовый SQL-скрипт;
- c, custom) — формирует резервную копию в архивном формате;
- d, directory) — формирует копию в directory-формате;
- t, tar) — формирует копию в формате tar.
-j , —jobs=число_заданий — параметр активирует параллельную выгрузку для одновременной обработки нескольких таблиц (равной числу заданий). Работает только при выгрузке копии в формате directory.
-n , —schema=схема — выгрузка в файл копии только определенной схемы.
-N , —exclude-schema=схема — исключение из выгрузки определенных схем.
-o, —oids — добавляет в выгрузку идентификаторы объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация создания команд, определяющих владельцев объектов в базе данных.
-s, —schema-only —добавление в выгрузку только схемы данных, без самих данных.
-S , —superuser=пользователь — учетная запись привилегированного пользователя, которая должна использоваться для отключения триггеров.
-t , —table=таблица — активация выгрузки определенной таблицы.
-T , —exclude-table=таблица —исключение из выгрузки определенной таблицы.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии pg_dump.
-Z 0..9, —compress=0..9 — установка уровня сжатия данных. 0 — сжатие выключено.
Утилита pg_dumpall
Утилита pg_dumpall реализует резервное копирование всего экземпляра (кластера или инстанса) базы данных без указания конкретной базы данных на инстансе. По принципу схожа с pg_dump. Добавим, что только утилиты pg_dump и pg_dumpall предоставляют возможность создания логической копии данных, остальные утилиты, рассматриваемые в этой статье, позволяют создавать только бинарные копии.
Чтобы сразу сжать резервную копию экземпляра базы данных, нужно передать вывод на архиватор gzip:
Ниже приведены параметры, с которыми может вызываться утилита pg_dumpall.
-d , —dbname=имя_бд — имя базы данных.
-h , —host=сервер — имя сервера.
-p , —port=порт — TCP-порт, на который принимаются подключения.
-U , —username=пользователь — имя пользователя для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role= — роль, от имени которой генерируется резервная копия.
-a, —data-only — создание резервной копии без схемы данных.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-f , —file=имя_файла — активация направления вывода в указанный файл.
-g, —globals-only — выгрузка глобальных объектов без баз данных.
-o, —oids — выгрузка идентификаторов объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация генерации команд, устанавливающих принадлежность объектов, как в исходной базе данных.
-r, —roles-only — выгрузка только ролей без баз данных и табличных пространств.
-s, —schema-only — выгрузка только схемы без самих данных.
-S , —superuser=имя_пользователя — привилегированный пользователь, используемый для отключения триггеров.
-t, —tablespaces-only — выгрузка табличных пространства без баз данных и ролей.
-v, —verbose — режим подробного логирования.
-V (—version — вывод версии утилиты pg_dumpall.
Утилита pg_restore
Утилита позволяет восстанавливать данные из резервных копий. Например, чтобы восстановить только определенную БД (в нашем примере zabbix), нужно запустить эту утилиту с параметром -d:
Чтобы этой же утилитой восстановить определенную таблицу, нужно использовать ее с параметром -t:
Также утилитой pg_restore можно восстановить данные из бинарного или архивного файла. Соответственно:
При восстановлении можно одновременно создать новую базу:
Восстановить данные из дампа также возможно при помощи psql:
Если для подключения нужно авторизоваться, вводим следующую команду:
Ниже приведен синтаксис утилиты pg_restore.
-h , —host=сервер — имя сервера, на котором работает база данных.
-p , —port=порт — TCP-порт, через база данных принимает подключения.
-U , —username=пользователь — имя пользователя для подключения..
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой выполняется восстановление резервная копия.
— расположение восстанавливаемых данных.
-a, —data-only — восстановление данных без схемы.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-C, —create — создание базы данных перед запуском процесса восстановления.
-d , —dbname=имя_бд — имя целевой базы данных.
-e, —exit-on-error — завершение работы в случае возникновения ошибки при выполнении SQL-команд.
-f , —file=имя_файла — файл для вывода сгенерированного скрипта.
-F , —format=формат — формат резервной копии. Допустимые форматы:
- p, plain — формирует текстовый SQL-скрипт;
- c, custom — формирует резервную копию в архивном формате;
- d, directory — формирует копию в directory-формате;
- t, tar — формирует копию в формате tar.
-I , —index=индекс — восстановление только заданного индекса.
-j , —jobs=число-заданий — запуск самых длительных операций в нескольких параллельных потоках.
-l, —list) — активация вывода содержимого архива.
-L , —use-list=файл-список — восстановление из архива элементов, перечисленных в файле-списке в соответствующем порядке.
-n , —schema=схема — восстановление объектов в указанной схеме.
-O, —no-owner — деактивация генерации команд, устанавливающих владение объектами по образцу исходной базы данных.
-P , —function=имя-функции(тип-аргумента[, …]) — восстановление только указанной функции.
-s, —schema-only — восстановление только схемы без самих данных.
-S , —superuser=пользователь — учетная запись привилегированного пользователя, используемая для отключения триггеров.
-t , —table=таблица — восстановление определенной таблицы.
-T , —trigger=триггер — восстановление конкретного триггера.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии утилиты pg_restore.
Утилита pg_basebackup
Утилитой pg_basebackup можно выполнять резервное копирования работающего кластера баз данных PostgreSQL. Результирующий бинарный файл можно использовать для репликации или восстановления на определенный момент в прошлом. Утилита создает резервную копию всего экземпляра базы данных и не дает возможности создавать слепки данных отдельных сущностей. Подключение pg_basebackup к PostgreSQL выполняется при помощи протокола репликации с полномочиями суперпользователя или с правом REPLICATION.
Для выполнения резервного копирования локальной базы данных достаточно передать утилите pg_basebackup параметр -D, обозначающий директорию, в которой будет сохранена резервная копия:
Чтобы создать сжатые файлы из табличных пространств, добавим параметры -Ft и -z:
То же самое, но со сжатием bzip2 и для экземпляра базы с общим табличным пространством:
Ниже приведен синтаксис утилиты pg_basebackup.
-d , —dbname=строка_подключения — определение базы данных в виде строки для подключения.
-h , —host=сервер — имя сервера с базой данных.
-p , —port=порт — TCP-порт, через база данных принимает подключения.
-s , —status-interval=интервал — количество секунд между отправками статусных пакетов.
-U , —username=пользователь — установка имени пользователя для подключения.
-w, —no-password — отключение запроса на ввод пароля.
-W, —password — принудительный запрос пароля.
-V, —version — вывод версии утилиты pg_basebackup.
-?, —help — вывод справки по утилите pg_basebackup.
-D каталог, —pgdata=каталог — директория записи данных.
-F , —format=формат — формат вывода. Допустимые варианты:
- p, plain — значение для записи выводимых данных в текстовые файлы;
- t, tar — значение, указывающее на необходимость записи в целевую директорию в формате tar.
-r , —max-rate=скорость_передачи — предельная скорость передачи данных в Кб/с.
-R, —write-recovery-conf — записать минимальный файл recovery.conf в директорию вывода.
-S , —slot=имя_слота — задание слота репликации при использовании WAL в режиме потоковой передачи.
-T , —tablespace-mapping=каталог_1=каталог_2 — активация миграции табличного пространства из одного каталога в другой каталог при копировании.
—xlogdir=каталог_xlog — директория хранения журналов транзакций.
-X , —xlog-method=метод — активация вывода файлов журналов транзакций WAL в резервную копию на основе следующих методов:
- f, fetch — включение режима сбора файлов журналов транзакций при окончании процесса копирования;
- s, stream — включение передачи журнала транзакций в процессе создания резервной копии.
-z, —gzip — активация gzip-сжатия результирующего tar-файла.
-Z , —compress=уровень — определение уровня сжатия механизмом gzip.
-c , —checkpoint=fast|spread — активация режима реперных точек.
-l , —label=метка — установка метки резервной копии.
-P, —progress — активация в вывод отчета о прогрессе.
-v, —verbose — режим подробного логирования.
Утилита wal-g
Wal-g — утилита для резервного копирования и восстановления базы данных PostgreSQL. При помощи wal-g можно выполнять сохранение резервных копий на хранилищах S3 или просто на файловой системе. Ниже мы разберем установку, настройку и работу с утилитой. Покажем как выполнить резервное копирование в Облачное хранилище S3 от Selectel.
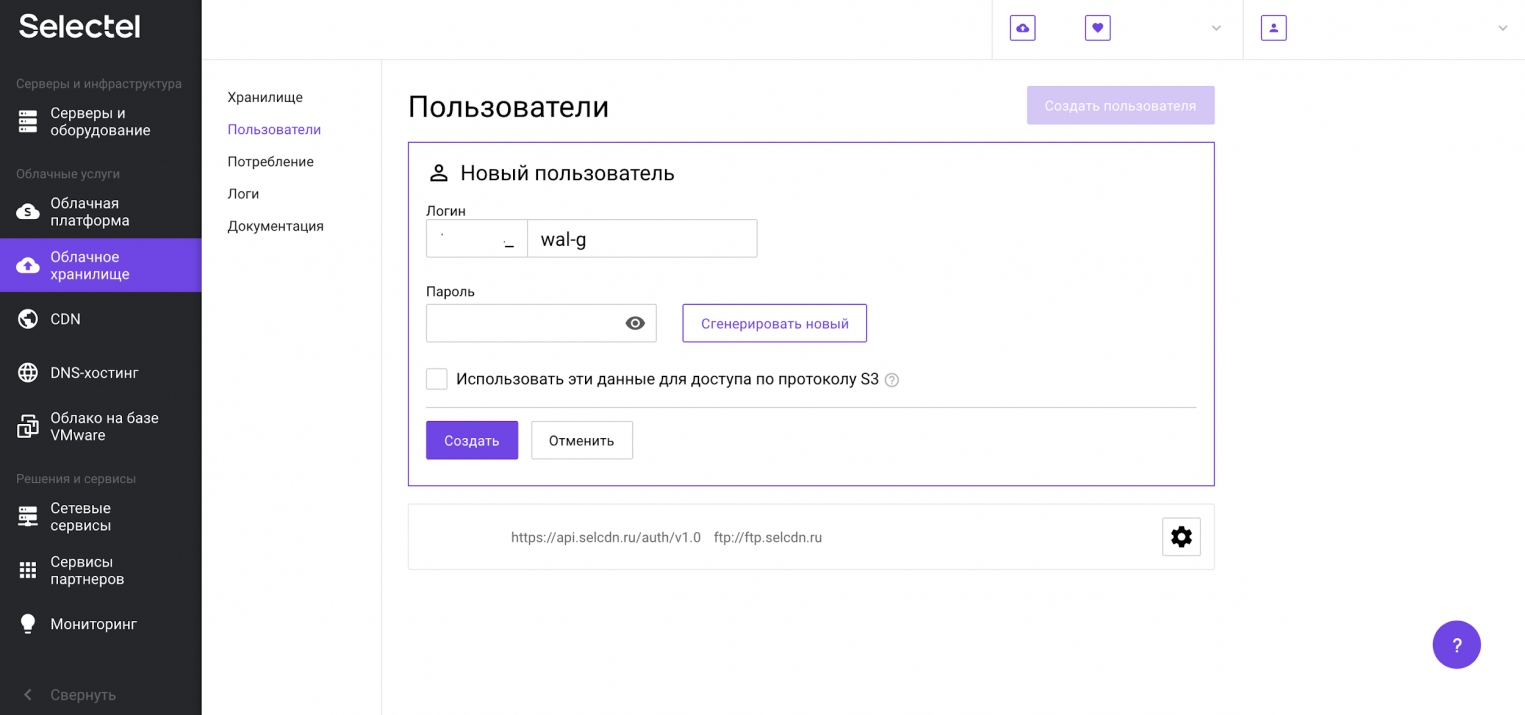
Создадим пользователя для облачного хранилища, учетные данные которого будем потом использовать для сохранения резервной копии. Перейдем в меню Пользователи и нажмем кнопку Создать пользователя:
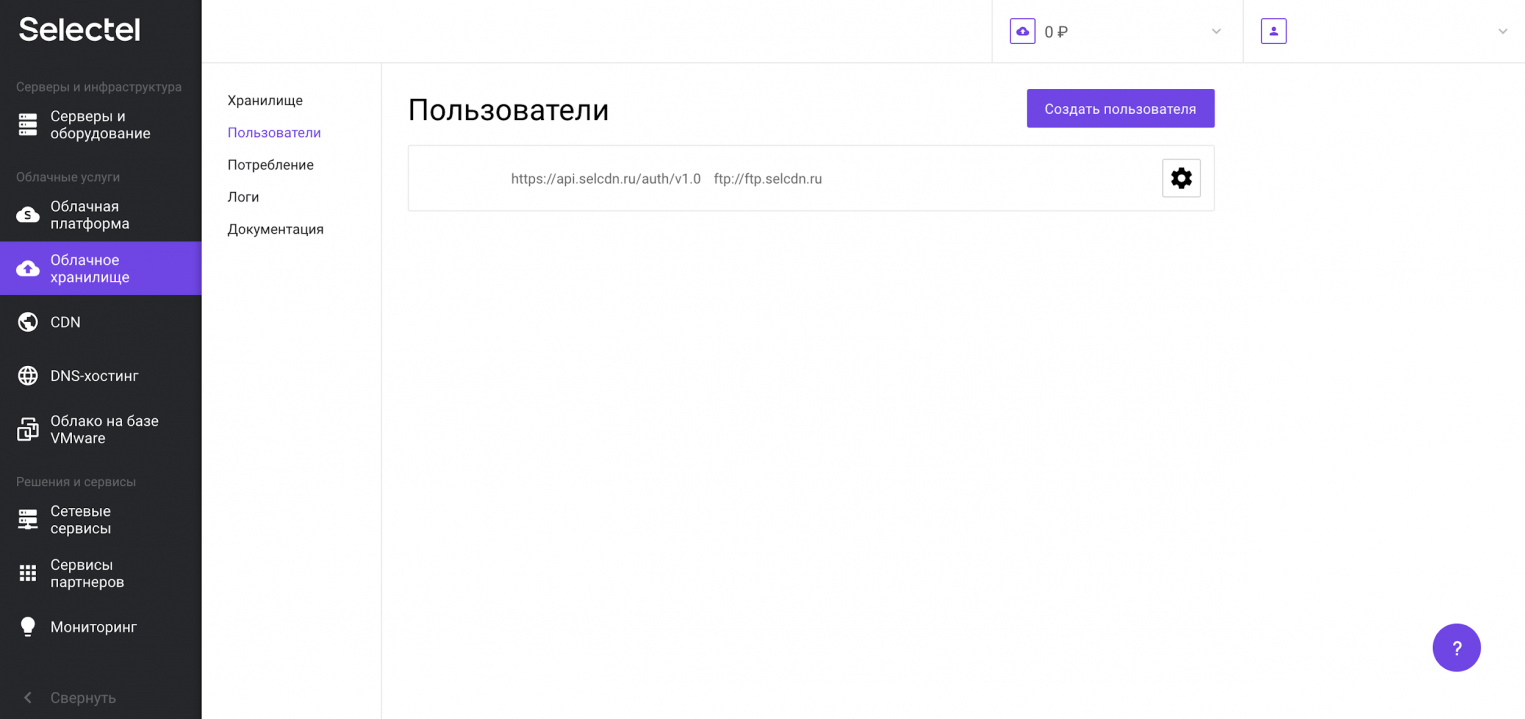
Дополнительную информацию можно получить в нашей Базе знаний. Первую часть логина изменить нельзя — это идентификатор пользователя в панели управления. Вторая часть логина задается произвольно. Например, 123456_wal-g:
Теперь перейдем к установке wal-g. Скачаем готовый установочный пакет из репозитория на github.com, распакуем и скопируем папку содержающую исполняемые файлы:
Заполним конфигурационный файл wal-g и изменим его владельца на учетную запись postgres:
Далее настроим автоматизированное создание резервных копий в PostgreSQL и перезагрузим процессы базы данных:
Теперь проверим корректность проведения настроек и загрузим резервную копию в хранилище:
После выполнения процесса резервного копирования, в созданном контейнере появится директория с резервными копиями баз данных:
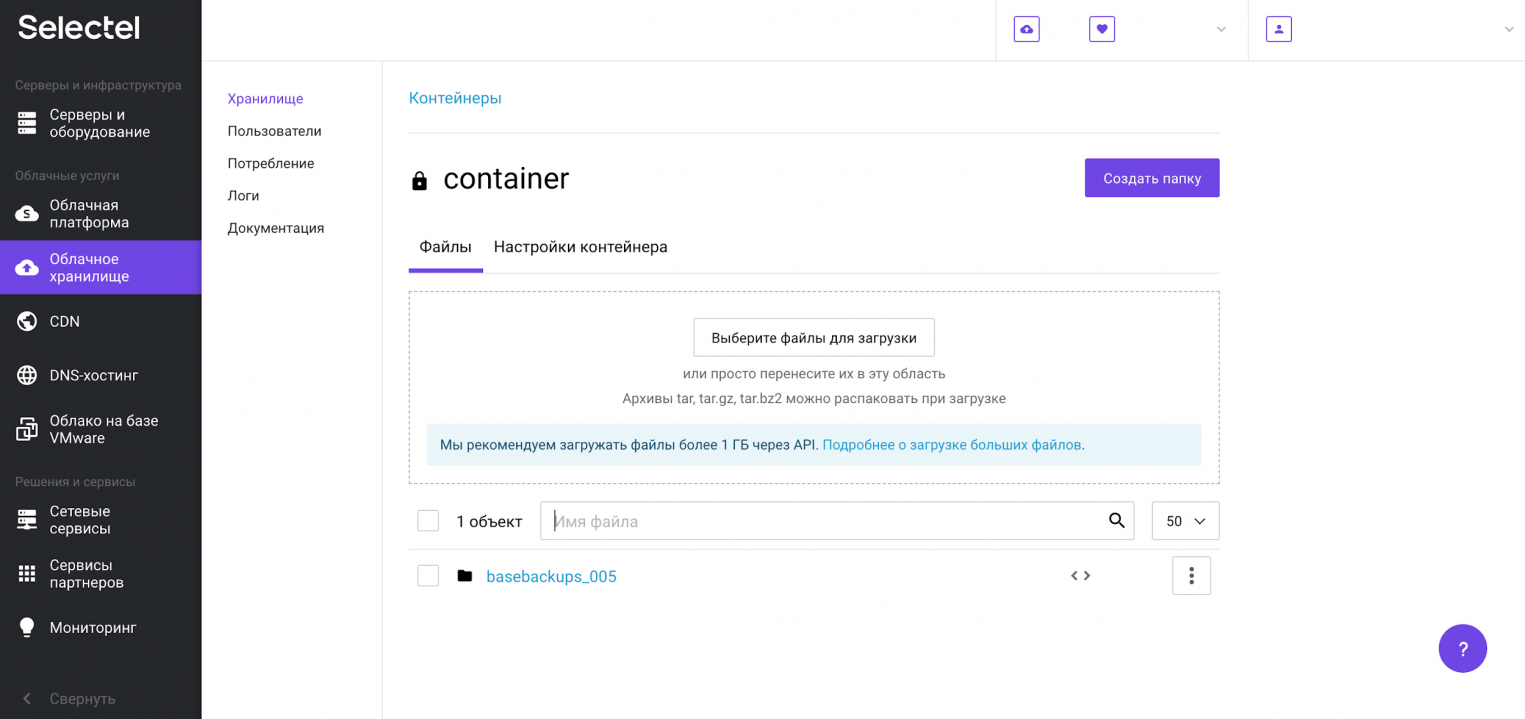
Такой процесс в продакшене может выполняться при помощи планировщика заданий на регулярной основе.
Утилита pgAdmin
Управлять созданием резервных копий возможно также и в графическом интерфейсе. Для этого мы будем использовать утилиту pgAdmin. Актуальную версию для Windows или другой поддерживаемой ОС можно свободно скачать с официального сайта.
После скачивания утилиту нужно установить и запустить. Она работает в виде веб-приложения через браузер.
После добавления сервера с базой данных, в интерфейсе появляется возможность создания резервной копии. Аналогичным образом здесь же можно выполнить восстановление из резервной копии.
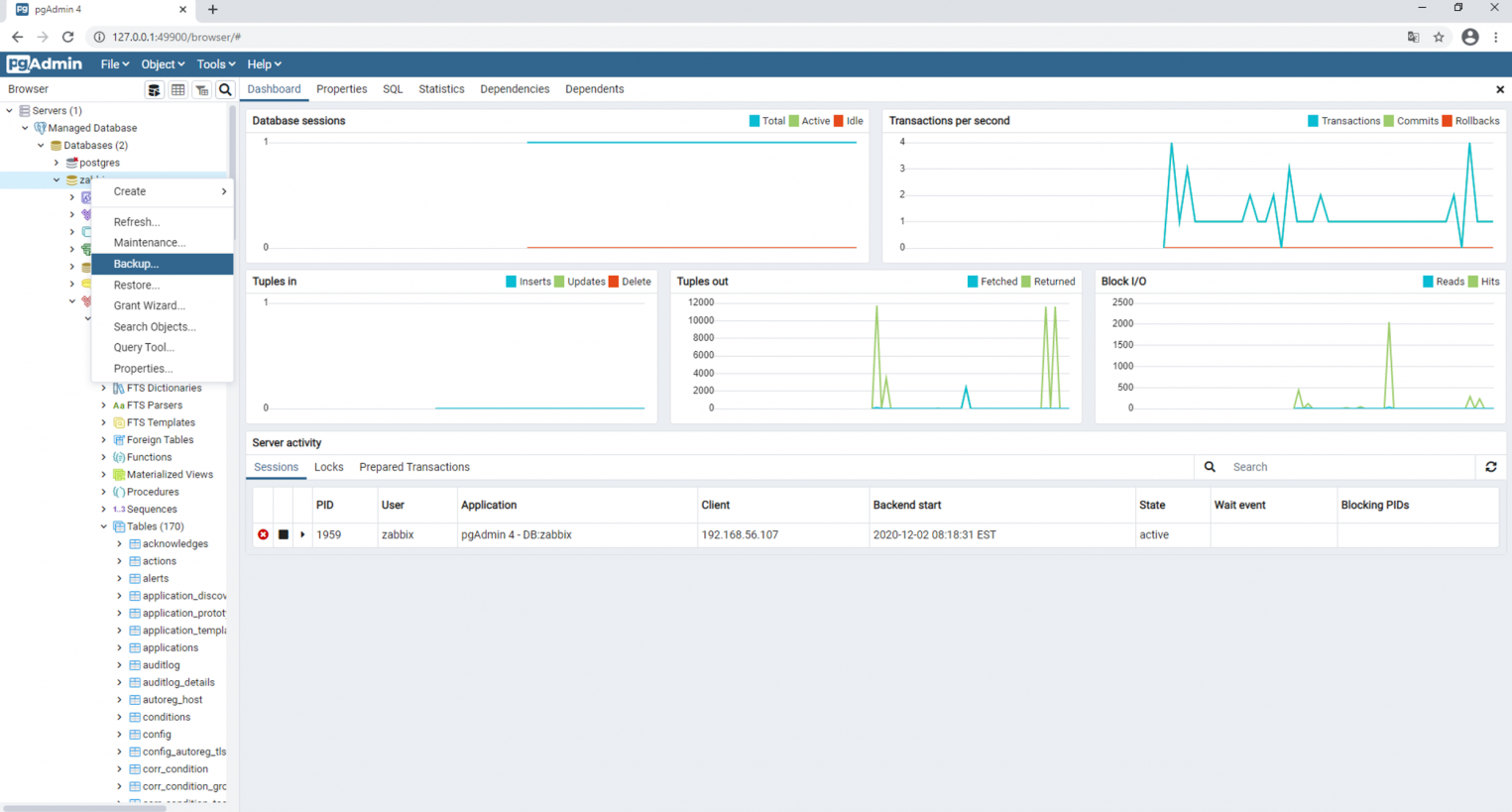
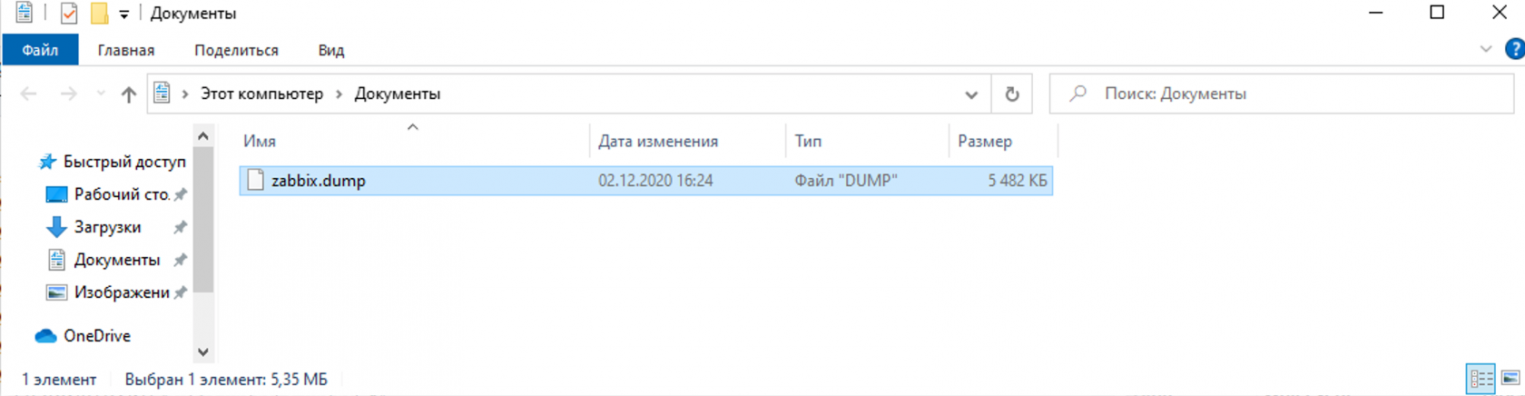
После выполнения команды Backup резервная копия сохраняется в заранее определенную директорию.
Работа с облачной базой данных в панели управления Selectel
В Облачной платформе Selectel есть возможность создавать управляемые базы данных (Managed Databases). Такие БД разворачиваются в несколько кликов мыши, однако, их основные преимущества — автоматическое резервное копирование, отказоустойчивость, быстрое масштабирование и управление различными характеристиками из графического интерфейса. Ниже мы создадим экземпляр управляемой базы данных, создадим резервную копию базы данных на виртуальном сервере и восстановим ее в управляемую базу данных.
Чтобы создать управляемую базу данных, перейдем в меню Базы данных и нажмем кнопку Создать кластер:
Появится форма создания кластера. Здесь можно выбрать версию PostgreSQL, конфигурацию кластера, настройки сети, режим пулинга и размер пула.
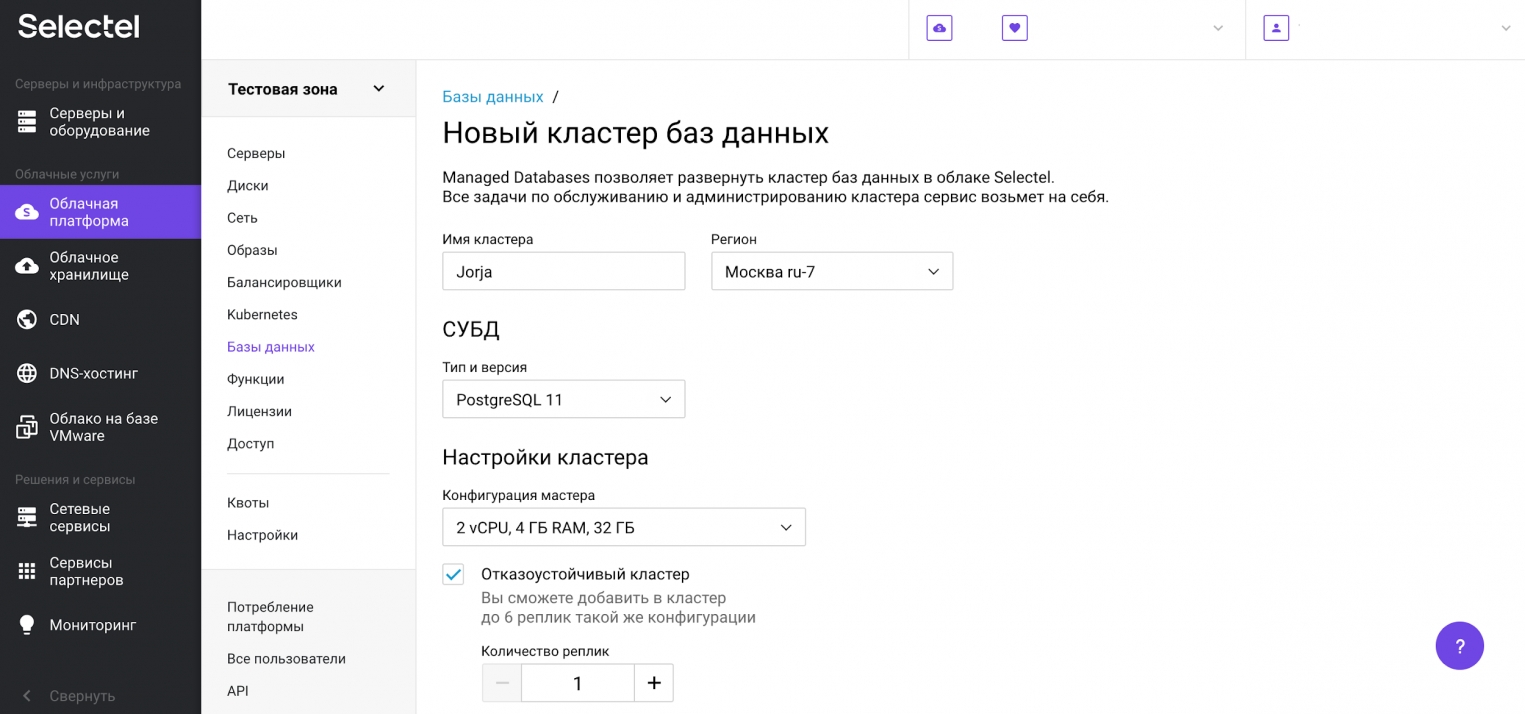
Обращаем внимание на блок Резервные копии, в котором указаны частота резервного копирования, время и срок хранения выгрузок. «Под капотом» используется механизм wal-g, о котором мы писали выше.
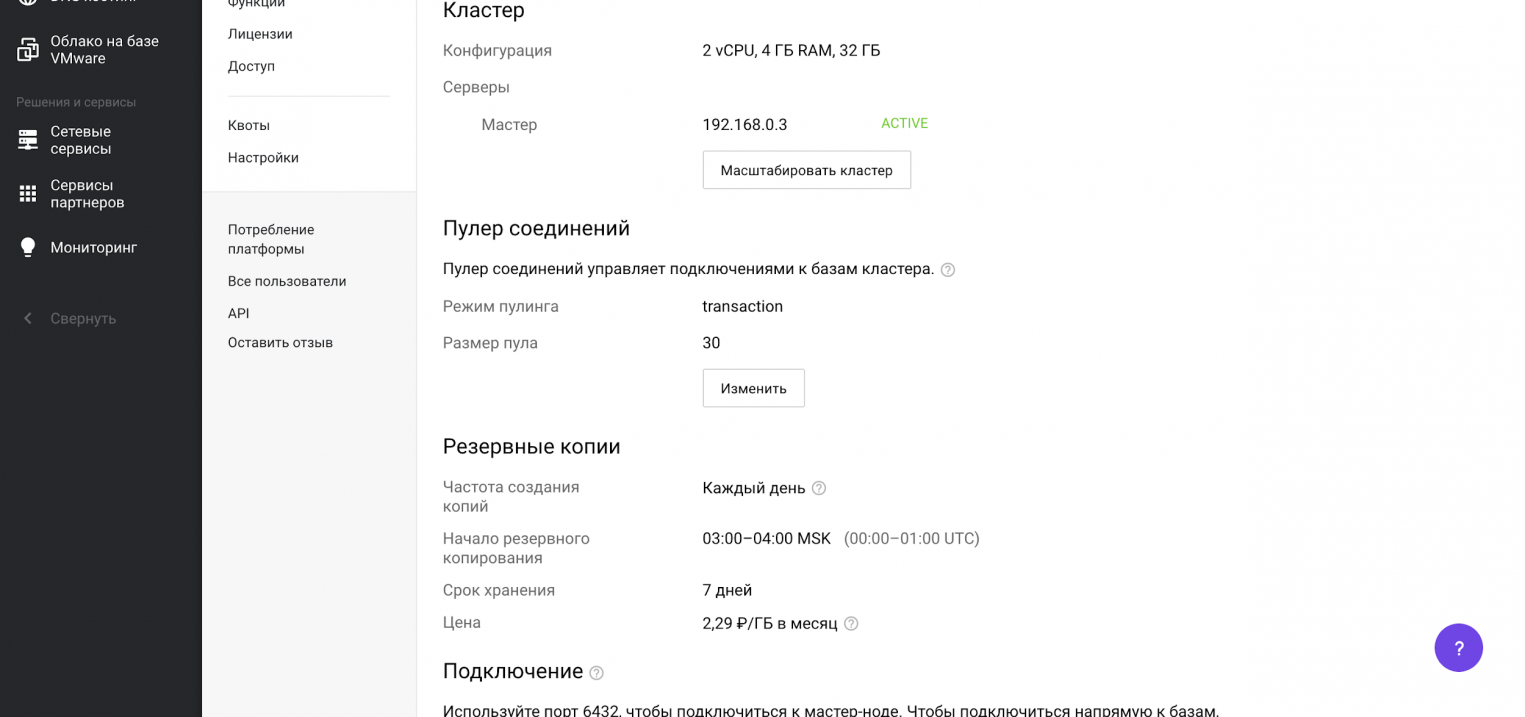
Автоматическое создание резервных копий отключить нельзя.
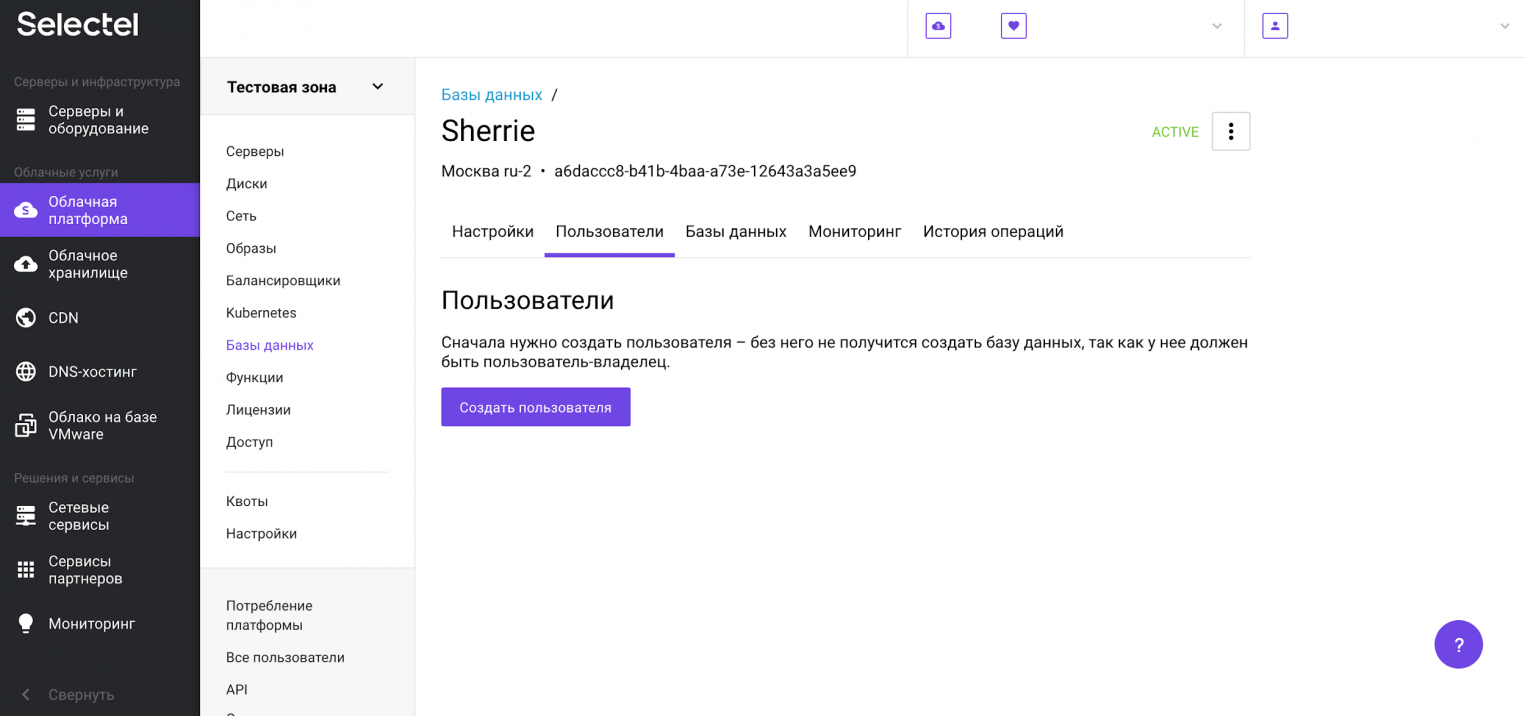
Следующий шаг — создание пользователя, от имени которого мы позже будем обращаться к базе данных. Для этого перейдем на вкладку Пользователи и нажмем на кнопку Создать пользователя.
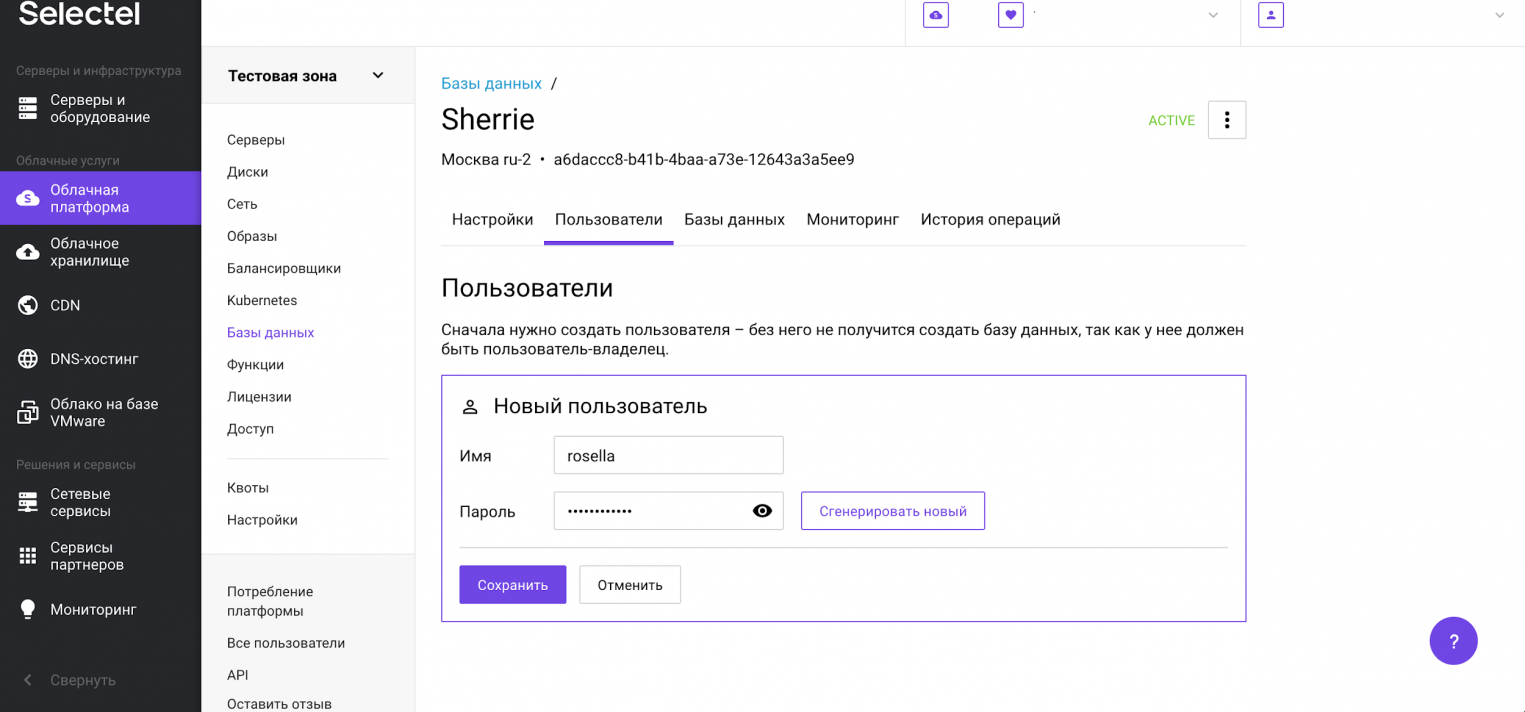
После этого появится приглашение ввести имя пользователя и пароль. После ввода этих данных нажимаем Сохранить.
Пользователь создан и отображается в списке пользователей.
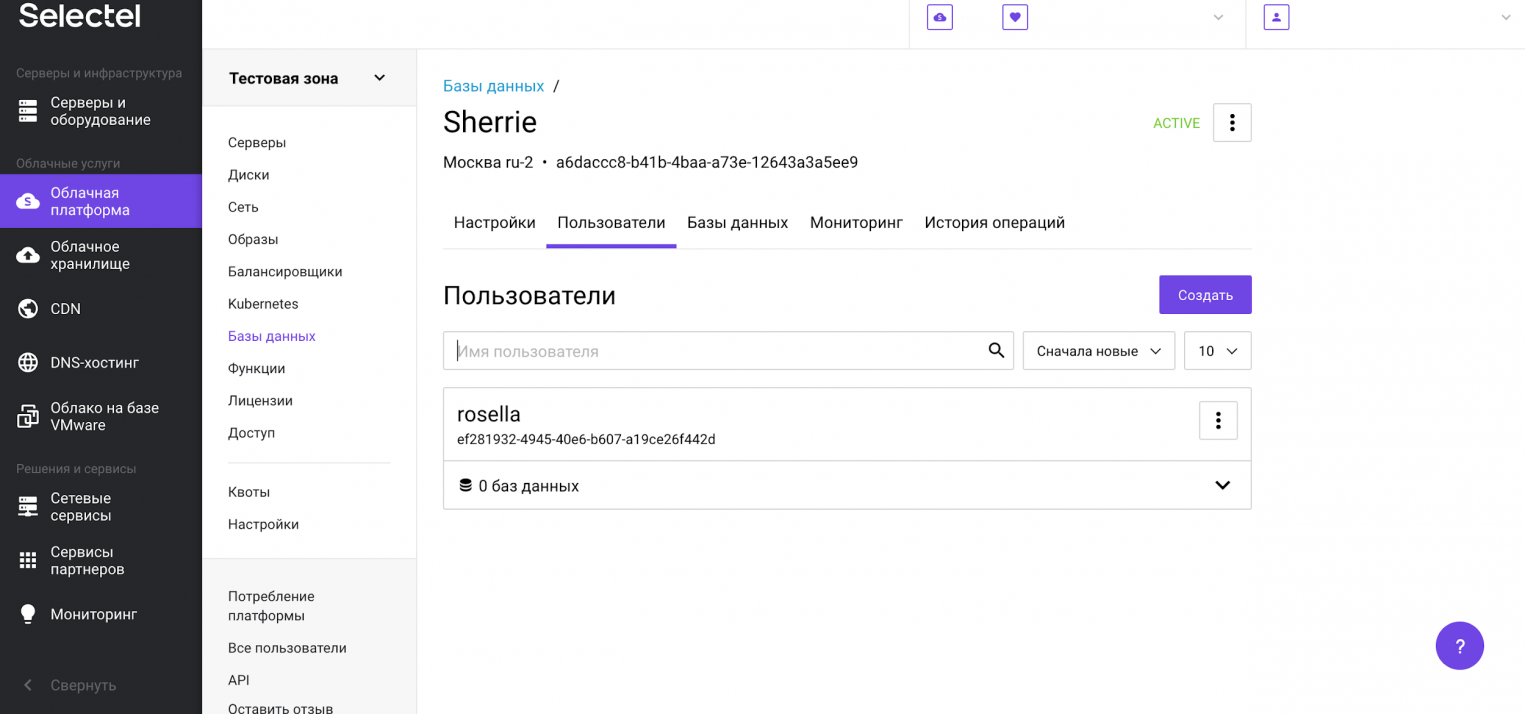
Теперь создадим базу данных. Для этого перейдем на вкладку Базы данных и нажмем на кнопку Создать базу данных.
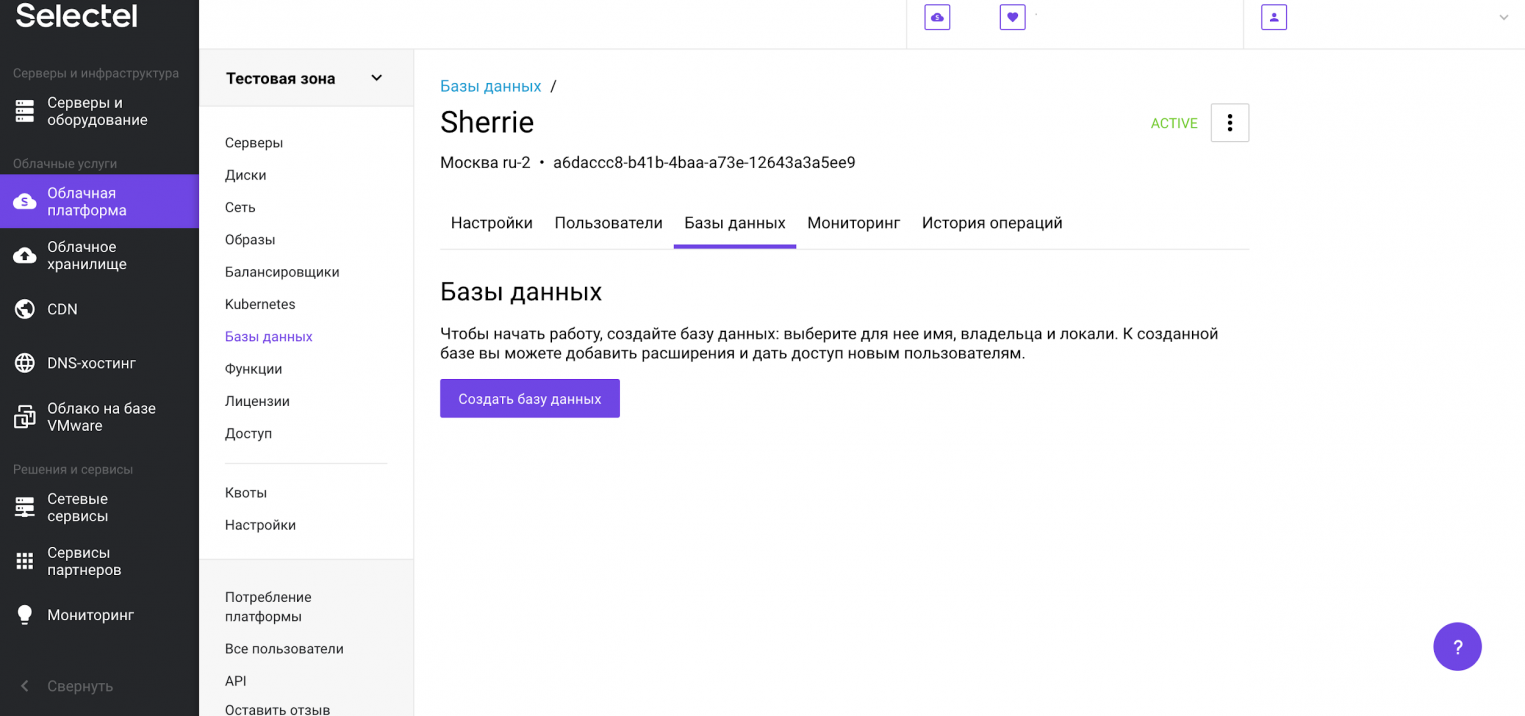
Заполняем необходимые поля и нажимаем кнопку Сохранить.
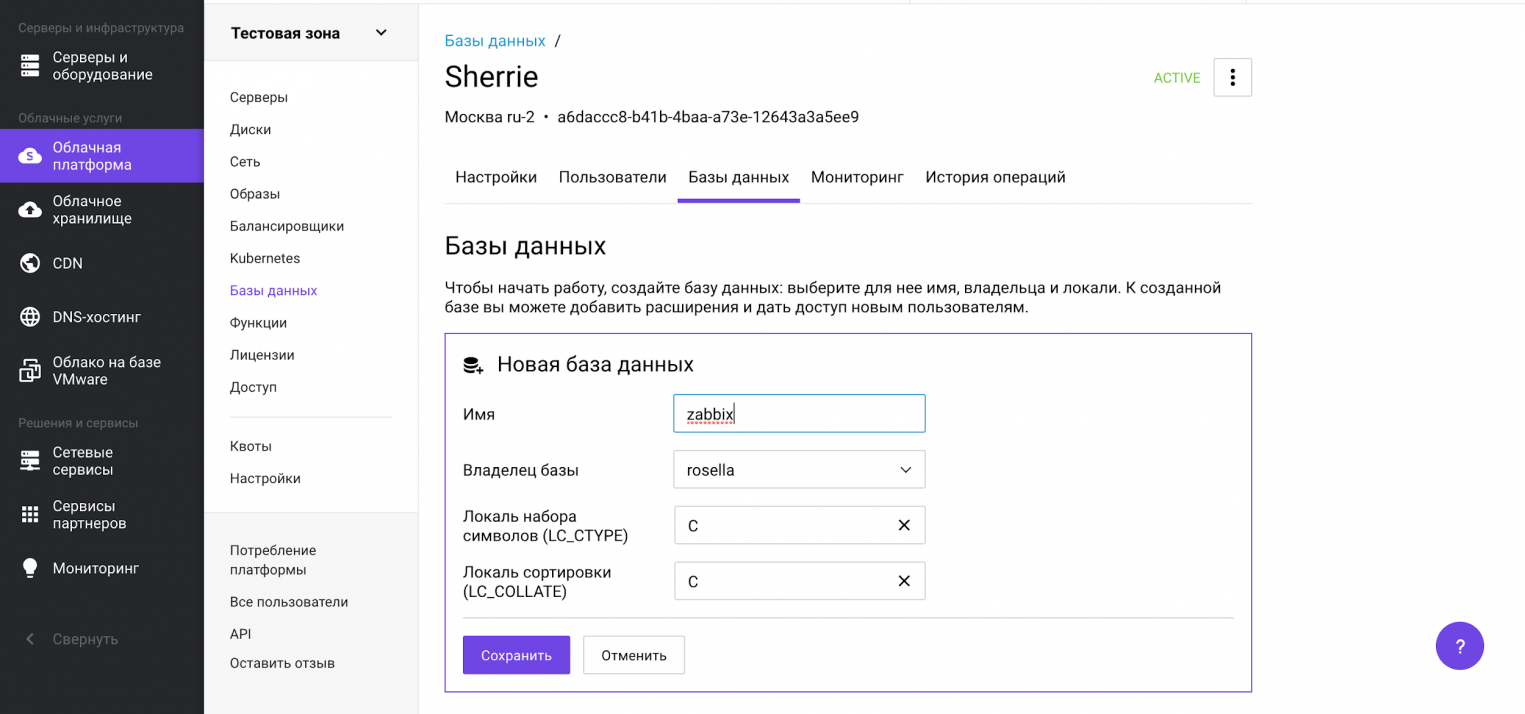
База данных создана и отображается в списке баз данных.
Теперь проверим возможность подключения. Для этого откроем консоль и вводим реквизиты:
В консоли должно появиться приглашение к вводу SQL-запроса или других управляющих команд.

Выполним резервное копирование при помощи команды pg_dump:
И следом резервное восстановление в созданную управляемую базу данных:
В результате выполнения команды выше мы восстановили резервную копию в управляемую базу данных.
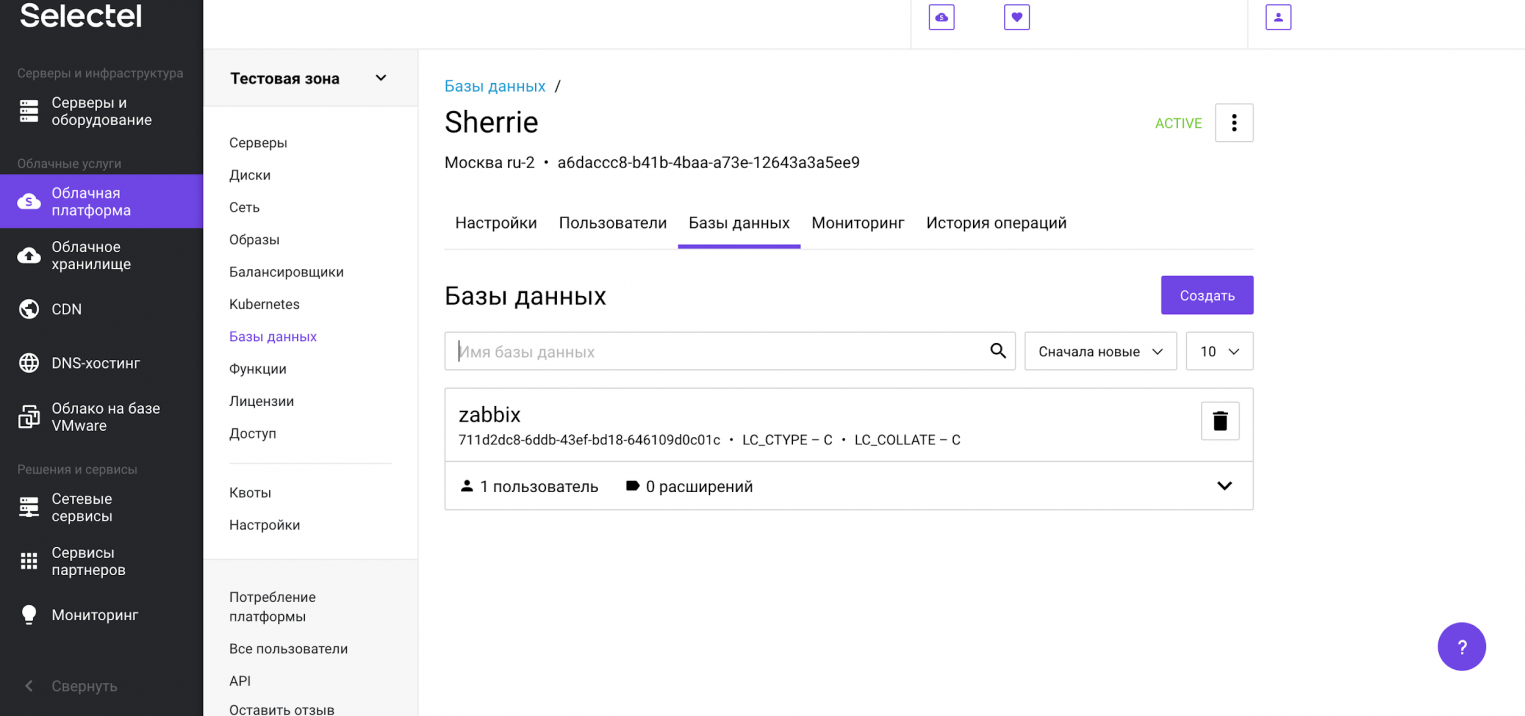
Чтобы воспользоваться восстановлением из резервной копии, которая автоматически создается на платформе Selectel, необходимо нажать на символ с тремя точками. В открывшемся меню нужно нажать на опцию Восстановить. После этого появится модальное окно, в котором можно выбрать резервную копию, а также дату и время, на которое нужно восстановить базу данных. Это так называемый Point-in-Time Recovery из WAL-файлов.
Услуга «Управляемые базы данных в облаке» позволяет перенести существующий кластер PostgreSQL на сервис управляемых баз данных бесшовно и без простоя, обратившись в техническую поддержку. Инженеры Selectel готовы помочь с переносом, а также проконсультировать по всем связанным с этим процессом вопросам.
Заключение
Мы рассмотрели возможности выполнения резервного копирования и показали отличия утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g. Вы увидели как можно создать управляемую базу данных, чтобы переложить часть административных задач на облачного провайдера.
Узнать подробнее об управляемых базах данных можно в документации Selectel.
Источник



