- Ppid linux ��� ���
- 6.2. Использование getpid() и getppid()
- 6.3. Порождение процесса
- 6.4. Замена образа процесса
- Как найти родительский процесс в Linux
- Как найти идентификатор родительского процесса (PPID) в Linux
- Как найти PPID с помощью команды pstree в Linux
- Как найти PPID с помощью команды ps
- Заключение
- Delightly Linux
- What are PID and PPID?
- What is the PPID?
- Why is the PPID Important?
- pstree
Ppid linux ��� ���
Эта глава открывает большую и очень важную для Linux-программиста тему многозадачности. Описать все сразу не получится, поэтому мы будем неоднократно возвращаться к многозадачности в последующих главах книги. Пристегните ремни покрепче!
Наберите в своей оболочке следующую команду:
На экран будут выведен список всех работающих в системе процессов. Если хотите посчитать количество процессов, наберите что-нибудь, набодобие этого:
Первое число — это количество работающих в системе процессов. Пользователи KDE могут воспользоваться программой kpm, а пользователи Gnome — программой gnome-system-monitor для получения информации о процессах. На то он и Linux, чтобы позволять пользователю делать одно и то же разными способами.
Возникает вопрос: «Что такое процесс?». Процессы в Linux, как и файлы, являются аксиоматическими понятиями. Иногда процесс отождествляют с запущенной программой, однако это не всегда так. Будем считать, что процесс — это рабочая единица системы, которая выполняет что-то. Многозадачность — это возможность одновременного сосуществования нескольких процессов в одной системе.
Linux — многозадачная операционная система. Это означает что процессы в ней работают одновременно. Естественно, это условная формулировка. Ядро Linux постоянно переключает процессы, то есть время от времени дает каждому из них сколько-нибудь процессорного времени. Переключение происходит довольно быстро, поэтому нам кажется, что процессы работают одновременно.
Одни процессы могут порождать другие процессы, образовывая древовидную структуру. Порождающие процессы называются родителями или родительскими процессами, а порожденные — потомками или дочерними процессами. На вершине этого «дерева» находится процесс init, который порождается автоматически ядром в процесссе загрузки системы.
К каждому процессу в системе привязана пара целых неотрицательных чисел: идентификатор процесса PID (Process IDentifier) и идентификатор родительского процесса PPID (Parent Process IDentifier). Для каждого процесса PID является уникальным (в конкретный момент времени), а PPID равен идентификатору процесса-родителя. Если ввести в оболочку команду ps -ef, то на экран будет выведен список процессов со значениями их PID и PPID (вторая и третья колонки соотв.). Вот, например, что творится у меня в системе:
Надо отметить, что процесс init всегда имеет идентификатор 1 и PPID равный 0. Хотя в реальности процесса с идентификатором 0 не существует. Дерево процессов можно также пресставить в наглядном виде при помощи опции —forest программы ps:
Если вызвать программу ps без аргументов, то будет выведен список процессов, принадлежащих текущей группе, то есть работающих под текущим терминалом. О том, что такое терминалы и группы процессов, будет рассказано в последующих главах.
6.2. Использование getpid() и getppid()
Процесс может узнать свой идентификатор (PID), а также родительский идентификатор (PPID) при помощи системных вызовов getpid() и getppid().
Системные вызовы getpid() и getppid() имеют следующие прототипы:
Для использования getpid() и getppid() в программу должны быть включены директивой #include заголовочные файлы unistd.h и sys/types.h (для типа pid_t). Вызов getpid() возвращает идентификатор текущего процесса (PID), а getppid() возвращает идентификатор родителя (PPID). pid_t — это целый тип, размерность которого зависит от конкретной системы. Значениями этого типа можно оперировать как обычными целыми числами типа int.
Рассмотрим теперь простую программу, которая выводит на экран PID и PPID, а затем «замирает» до тех пор, пока пользователь не нажмет .
Проверим теперь, как работает эта программа. Для этого откомпилируем и запустим ее:
Теперь, не нажимая , откроем другое терминальное окно и проверим, правильность работы системных вызовов getpid() и getppid():
6.3. Порождение процесса
Как уже говорилось ранее, процесс в Linux — это нечто, выполняющее программный код. Этот код называют образом процесса (process image). Рассмотрим простой пример, когда вы находитесь в оболочке bash и выполняете команду ls. В этом случае происходит следующее. Образ программы-оболочки bash выполняется в процессе #1. Затем вы вводите команду ls, и оболочка определяет, что нужно запустить внешнюю программу (/bin/ls). Тогда процесс #1 создает свою почти точную копию, процесс #2, который выполняет тот же самый программный код. После этого процесс #2 заменяет свой текущий образ (оболочку) другим образом (программой /bin/ls). В итоге получаем отдельный процесс, выполняющий отдельную программу.
«К чему такая путаница?» — спросите вы. Зачем сначала «клонировать» процесс, а затем заменять в нем образ? Не проще ли все делать одной-единственной операцией? Ответы на подобные вопросы дать тяжело, но, как правило, с опытом прихоидит понимание того, что подобная схема является одной из граней красоты Unix-систем.
Попробуем все-таки разобраться, почему в Unix-системах порождение процесса отделено от запуска программы. Для этого выясним, что же происходит с данными при «клонировании» процесса. Итак, каждый процесс хранит в своей памяти различные данные (переменные, файловые дескрипторы и проч.). При порождении нового процесса, потомок получает точную копию данных родителя. Но как только новый процесс создан, родитель и потомок уже распоряжаются своими копиями по своему усмотрению. Это позволяет распараллелить программу, заставив ее выполнять какой-нибудь трудоемкий алгоритм в отдельном процессе.
Может быть кто-то из вас слышал про то, что в Linux есть потоки, которые позволяют в одной программе реализовывать параллельное выполнение нескольких функций. Опять же возникает вопрос: «Если есть потоки, зачем вся эта головомойка с клонированиями и заменой образов?». А дело в том, что потоки работают с общими данными и выполняются в одной программе. Если в потоке произошло что-то страшное, то это, как правило, отражается на всей программе в целом. Хотя технически потоки реализованы в Linux на базе процессов, но процесс все же является более независимой единицей. Крах дочернего процесса никак не отражается на работе родителя, если сам родитель этого не пожелает.
По правде сказать, программисты редко прибегают к методике распараллеливания одной программы при помощи процессов. Но суть в том, что в Unix-системах программист обладает полной свободой выбора стратегии многозадачности. И это здорово!
Разберемся теперь с тем, как на практике происходит «клонирование» процессов. Для этого используется простой системный вызов fork(), прототип которого находится в файле unistd.h:
Если fork() завершается с ошибкой, то возвращается -1. Это редкий случай, связанный с нехваткой памяти или превышением лимита на количество процессов. Но если разделение произошло, то программе нужно позаботиться об идентификации своего «Я», то есть определении того, где родитель, а где потомок. Это делается очень просто: в родительский процесс fork() возвращает идентификатор потомка, а потомок получает 0. Следующий пример демонстрирует то, как это происходит.
Проверяем, что получилось:
Обратите внимание, что поскольку после вызова fork() программу выполняли уже два независимых процесса, то сообщение родителя вполне могло бы появиться первым.
6.4. Замена образа процесса
Итак, теперь мы умеем порождать процессы. Научимся теперь заменять образ текущего процесса другой программой. Для этих целей используется системный вызов execve(), который объявлен в заголовочном файле unistd.h вот так:
Все очень просто: системный вызов execve() заменяет текущий образ процесса программой из файла с именем path, набором аргументов argv и окружением envp. Здесь следует только учитывать, что path — это не просто имя программы, а путь к ней. Иными словами, чтобы запустить ls, нужно в первом аргументе указать «/bin/ls».
Массивы строк argv и envp обязательно должны заканчиваться элементом NULL. Кроме того, следует помнить, что первый элемент массива argv (argv[0]) — это имя программы или что-либо иное. Непосредственные аргументы программы отсчитываются от элемента с номером 1.
В случае успешного завершения execve() ничего не возвращает, поскольку новая программа получает полное и безвозвратное управление текущим процессом. Если произошла ошибка, то по традиции возвращается -1.
Рассмотрим теперь пример программы, которая заменяет свой образ другой программой.
Итак, данная программа выводит свой PID и передает безвозвратное управление программе cat без аргументов и без окружения. Проверяем:
Программа вывела идентификатор процесса и замерла в смиренном ожидании. Откроем теперь другое терминальное окно и проверим, что же творится с нашим процессом:
Итак, мы убедились, что теперь процесс 30150 выполняет программа cat. Теперь можно вернуться в исходное окно и нажатием Ctrl+D завершить работу cat.
И, наконец, следующий пример демонстрирует запуск программы в отдельном процессе.
Обратите внимание, что поскольку execve() не может возвращать ничего кроме -1, то для обработки возможной ошибки вовсе не обязательно создавать ветвление. Иными словами, если вызов execve() возвратил что-то, то это однозначно ошибка.
Источник
Как найти родительский процесс в Linux
Во время выполнения программы ядро создает процесс, который помогает сохранять детали выполнения программы в системной памяти. Когда программа выполняется, она становится процессом для системы. Итак, мы можем сказать, что процесс — это программа, пока он не выполняется.
Процесс, созданный ядром, известен как » родительский процесс «, а все процессы, производные от родительского процесса, называются » дочерними процессами «. Один процесс может состоять из нескольких дочерних процессов, имеющих уникальный PID, но с одним и тем же PPID.
У новичка может возникнуть вопрос: в чем разница между PID и PPID?
Мы уже обсуждали PID в большинстве наших статей, если вы новичок, не беспокойтесь!
В системах Linux одновременно выполняется несколько процессов. Иногда процесс может иметь один поток (блок выполнения внутри процесса) или несколько потоков. Процессы имеют разные состояния; они могут находиться в состоянии ожидания, готовности или работы. Все дело в том, как пользователь или ядро расставляют приоритеты. Итак, эти процессы идентифицируются уникальными номерами, которые мы называем идентификатором процесса (PID). Уникальные номера для родительских процессов называются PPID, и каждый родительский процесс может иметь несколько дочерних процессов с их уникальными идентификаторами. PID дочерних процессов отличаются, поскольку они представляют собой отдельные исполнительные единицы, но имеют один и тот же идентификатор родительского процесса ( PPID ).
Нам нужен PPID, когда дочерний процесс создает проблемы и не работает должным образом. В этом случае это может повлиять на работу других процессов, а также на систему. Здесь, чтобы остановить непрерывно работающий процесс, необходимо убить его родительский процесс.
Давайте проверим, как мы можем найти PPID:
Как найти идентификатор родительского процесса (PPID) в Linux
У нас есть несколько подходов к поиску PPID запущенного процесса в системах Linux:
- Использование команды «pstree»
- Использование команды «ps»
Как найти PPID с помощью команды pstree в Linux
Команда » pstree » — хороший подход для определения идентификатора родительского процесса (PPID), поскольку она показывает отношения родитель-потомок в древовидной иерархии.
Введите в терминале просто команду » pstree » с параметром » -p «, чтобы проверить, как он отображает все запущенные родительские процессы вместе с их дочерними процессами и соответствующими PID.

Он показывает родительский идентификатор вместе с идентификаторами дочерних процессов.
Давайте рассмотрим пример „Mozilla Firefox“, чтобы получить его PPID вместе с полной иерархией процессов. Выполните в терминале следующую команду:

( grep — это инструмент командной строки, который помогает искать определенную строку)
В упомянутых результатах мы видим, что 3528 — это PPID процесса » Firefox «, а все остальные — дочерние процессы.
Чтобы распечатать в терминале только идентификатор родительского процесса, выполните указанную команду:

Как найти PPID с помощью команды ps
Утилита команды » ps » — это еще один способ обрабатывать информацию из файловой системы » / proc » и отслеживать ее.
С помощью этой команды пользователь также может найти PPID и PID запущенного процесса.
Выполните следующую команду » ps » вместе с параметром » ef «, чтобы отобразить подробную информацию о процессах, включая PPID :

Если вы хотите отобразить PPID определенного процесса с подробностями, выполните указанную команду » ps » с помощью » grep «:

( опция » -f » используется для перечисления деталей процесса)
А чтобы получить только PPID » Firefox «, используйте следующий синтаксис:
Итак, найдите PPID » firefox » с помощью команды:

Заключение
При каждом выполнении программы ядро создает процесс, который загружает детали выполнения в память. Этот созданный процесс известен как родительский процесс, имеющий один или несколько потоков. Каждому процессу ядро автоматически присваивает уникальный PPID и PID.
При работе с системой Linux следует знать PPID запущенных процессов. Проблема с дочерним процессом может повлиять на другие процессы. В таких случаях нам может потребоваться убить родительский процесс.
Идентификаторы PPID запущенных процессов можно определить несколькими способами. Самый простой подход — использовать команду » ps » и » pstree «.
Выше мы видели, как с помощью этих двух командных инструментов можно узнать PPID конкретного процесса.
Источник
Delightly Linux
What are PID and PPID?
⌚ June 25, 2012  If you have ever opened System Monitor or top you no doubt noticed a column named ID or PID containing a list of numbers. You might even see a value called PPID. What do these numbers mean?
If you have ever opened System Monitor or top you no doubt noticed a column named ID or PID containing a list of numbers. You might even see a value called PPID. What do these numbers mean?
Here is a short explanation of these Linux terms.
In Linux, an executable stored on disk is called a program, and a program loaded into memory and running is called a process. When a process is started, it is given a unique number called process ID (PID) that identifies that process to the system. If you ever need to kill a process, for example, you can refer to it by its PID. Since each PID is unique, there is no ambiguity or risk of accidentally killing the wrong process (unless you enter the wrong PID).
If you open top (in a terminal, type top and press enter), the PID column lists the process IDs of all processes currently loaded into memory regardless of state (sleeping, zombie, etc.). Both daemons (system processes) and user processes (processes you started either automatically or manually) have their own process IDs. The PIDs are not always assigned in numerical order, so it’s normal to see what appears to be a random selection of numbers.

One very important process is called init. init is the grandfather of all processes on the system because all other processes run under it. Every process can be traced back to init, and it always has a PID of 1. The kernel itself has a PID of 0.
What is the PPID?
In addition to a unique process ID, each process is assigned a parent process ID (PPID) that tells which process started it. The PPID is the PID of the process’s parent.
For example, if process1 with a PID of 101 starts a process named process2, then process2 will be given a unique PID, such as 3240, but it will be given the PPID of 101. It’s a parent-child relationship. A single parent process may spawn several child processes, each with a unique PID but all sharing the same PPID.
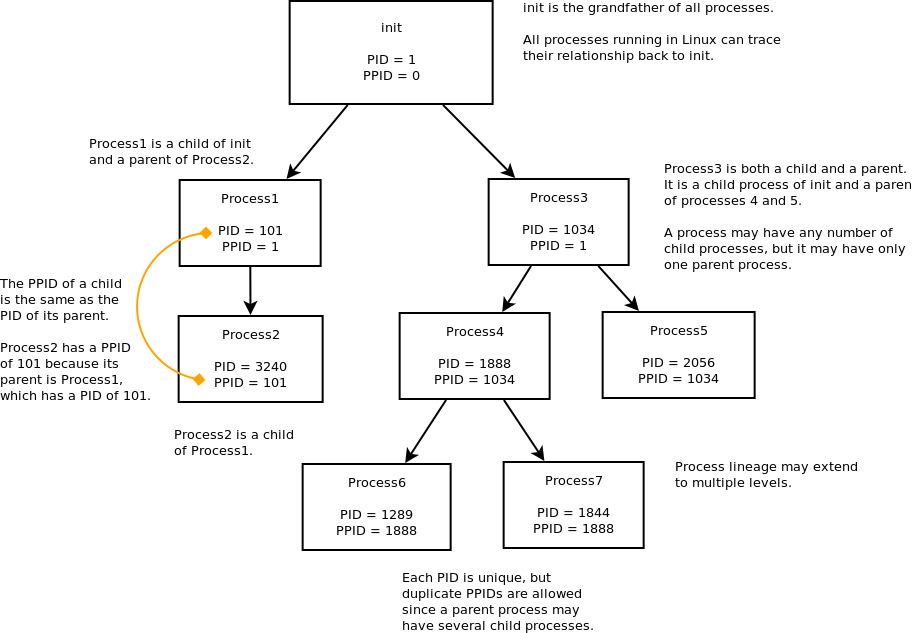
Why is the PPID Important?
Occasionally, processes go bad. You might try to quit a program only to find that it has other intentions. The process might continue to run or use up resources even though its interface closed. Sometimes, this leads to what is called a zombie process, a process that is still running, but dead.
One effective way to kill a zombie process is to kill its parent process. This involves using the ps command to discover the PPID of the zombie process and then sending a kill signal to the parent. Of course, any other children of the parent process will be killed as well.
pstree
pstree is a useful program that shows the relationship of all processes in a tree-like structure.

Give it a try to see how processes are arranged on your system. Processes do not float by themselves somewhere in memory. Each one has a reason for its existence, and a tree view helps show how it relates to others.
pstree supports options to adjust the output, so check man pstree for more details. Entering the following command lists the PID with each process and organizes processes by their ancestors (numerically) to show their relationship with each other.
For simpler process management and a better way to see how processes are organized, have a look at the program htop, which displays PID, optional PPID, process tree view, and much more information in glorious color!
Htop showing processes arranged in tree view along with PID and PPID.
Источник



