- Мониторинг списка запущенных процессов в Zabbix
- Введение
- Подготовка сервера к мониторингу процессов
- Настройка мониторинга за процессами
- Проверка отправки списка процессов
- Заключение
- ZABBIX — Настраиваем мониторинг служб
- ZABBIX — Настраиваем мониторинг служб.
- Создаём элемент данных.
- Мониторим статус процесса в Windows
Мониторинг списка запущенных процессов в Zabbix

В стандартных шаблонах Zabbix есть триггеры на загрузку процессора, а так же на превышение максимально допустимого числа процессов. Триггеры эти практически бесполезны, если у вас плавающая нагрузка. Допустим, вы получаете уведомление о том, что у вас сильно нагружен процессор. Через 10 минут нагрузка прошла, а вы не успели зайти на сервер и посмотреть, чем он был нагружен в это время. Вот эту проблему я и решаю своим велосипедом, которым делюсь в статье.
Введение
Рассказываю подробно, что я хочу получить в конце статьи. В стандартном шаблоне Zabbix для Linux есть несколько триггеров. Они могут немного отличаться в названиях, в зависимости от версии шаблона, но смысл один и тот же:
- High CPU utilization
- Load average is too high
- Too many processes on hostname
Я хочу получить информацию о запущенных процессах на хосте в момент срабатывания триггера. Это позволит мне спокойно посмотреть, что создает нагрузку, когда у меня будет возможность. Мне не придется идти руками в консоль хоста и пытаться ловить момент, когда опять появится нагрузка.
В дефолтной конфигурации у Zabbix нет готовых инструментов, чтобы реализовать желаемое. Вы можете настроить мониторинг процесса или группы процессов в Zabbix. Но это не то, что нужно. Можно настроить автообнаружение всех процессов и мониторить их. Чаще всего это тоже не нужно, а подобный мониторинг будет генерировать большую нагрузку и сохранять кучу данных в базу. Особенно если на сервере регулярно запущено несколько сотен процессов.
Моя задача посмотреть на список процессов именно в момент нагрузки. Более того, мне даже не нужны все процессы, достаточно первой десятки самых активных, нагружающих больше всего систему. Я буду реализовывать этот мониторинг следующим образом:
- Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
- Разрешаю на zabbix agent запуск внешних команд.
- Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
Приступаем к реализации задуманного. Я буду настраивать описанную схему на Zabbix Server версии 5.2. Если у вас его нет, читайте мою статью по установке и настройке zabbix. В качестве подопытной системы будет выступать Centos. Так же предлагаю мои статьи по ее установке и предварительной настройке.
Подготовка сервера к мониторингу процессов
Первым делом идем на целевой сервер и изменяем конфигурацию zabbix-agent. Нам надо активировать следующую опцию:
Не забудьте после этого перезапустить агента.
Предупреждаю, что подобная настройка — огромная дыра в безопасности сервера. Используйте на свой страх и риск. Чтобы у вас не было проблем с этим, настоятельно рекомендую ограничивать доступ к порту агента на сервере на уровне firewall только с сервера мониторинга. Так же в обязательном порядке использовать шифрованное соединение между сервером и агентом. Вообще, это универсальное правило при настройке мониторинга. В идеале, так надо делать всегда. Я стараюсь все это настраивать при работе мониторинга через интернет. Если проигнорировать данное предупреждение и оставить все в открытом доступе, то через разрешенные удаленные команды вам могут залить на сервер зловред.
Далее проверим команду, которая будет формировать список процессов для отправки на сервер мониторинга. Я предлагаю использовать вот такую конструкцию, но вы можете придумать что-то свое.
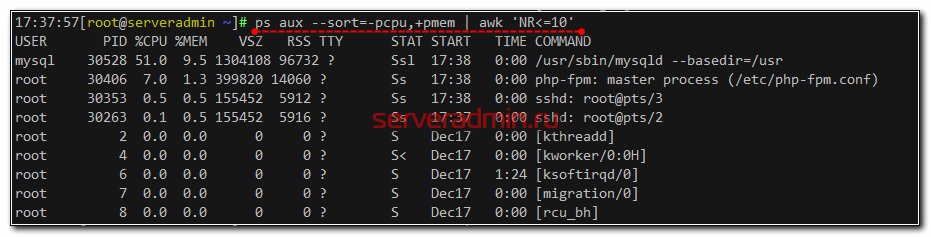
Получаем список запущенных процессов, отсортированный по потреблению cpu и ограниченный первыми десятью строками. В данный момент на сервере с агентом нам делать нечего. Перемещаемся в web интерфейс Zabbix Server.
Настройка мониторинга за процессами
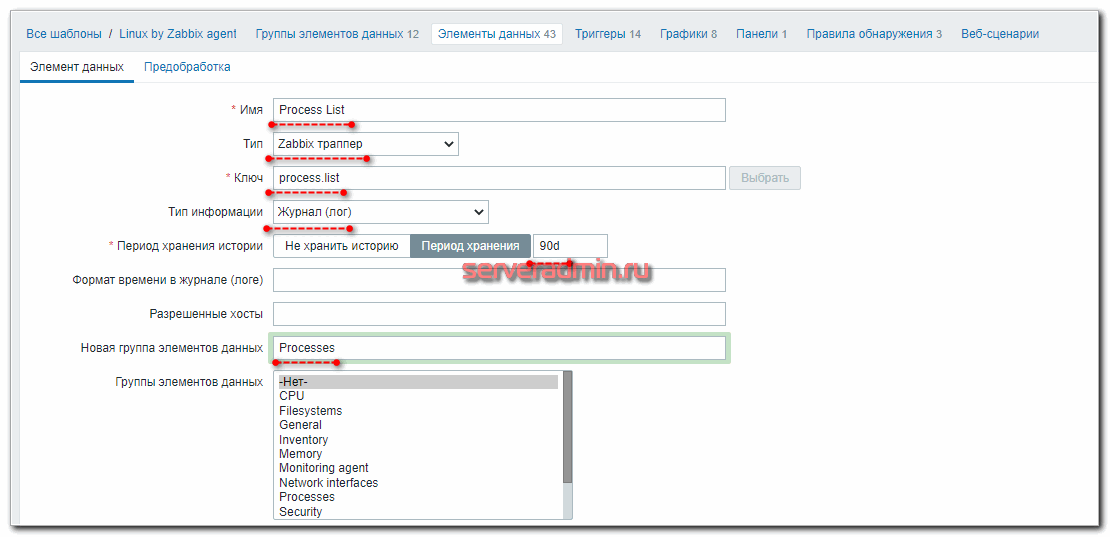
На Zabbix сервере идем в стандартный шаблон Linux и добавляем туда 2 новых айтема:
- Process List — список процессов, ограниченный десятью с самой высокой нагрузкой на cpu. Сюда будем записывать информацию о процессах на сервере при срабатывании триггеров на повышенную нагрузку CPU.
- Full Process List — полный список всех процессов. Сюда запишем полный список всех процессов, когда сработает триггер на превышение максимально допустимого количества запущенных процессов на сервере.
Так выглядит первый айтем. Второй сделайте по аналогии.
Теперь идем на сервер с агентом и пробуем отправку данных в данный айтем. Для этого нам нужен будет zabbix_sender. Если у вас его нет, то установите.
Отправку данных проверяем следующим образом:
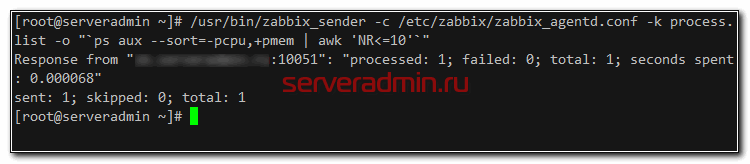
Я не буду подробно останавливаться на формате запросов с помощью zabbix_sender. Все это хорошо описано в документации. Теперь идем в веб интерфейс сервера и в разделе Последние данные смотрим на список процессов, который нам пришел с целевого сервера.
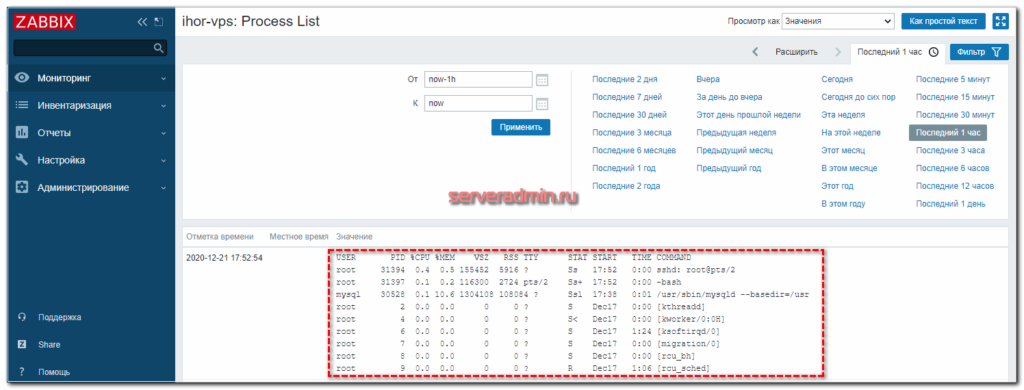
Ровно то, что нам было нужно. То же самое можно проверить с айтемом Full Process List, убрав в команде | awk ‘NR Настройка -> Действия и добавляем новое.
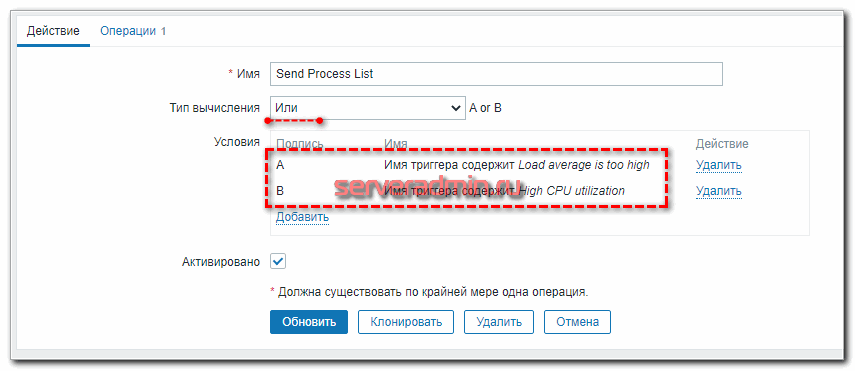
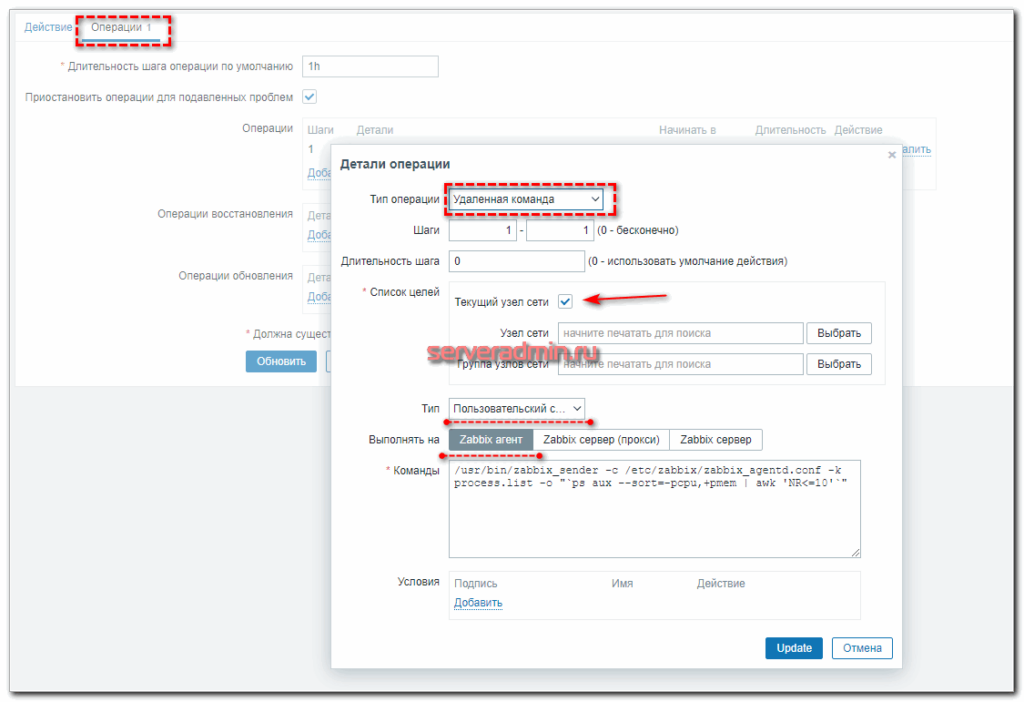
Сохраняйте действие и можно проверять.
Проверка отправки списка процессов
Теперь проверим, как все это будет работать. Для этого идем на целевой сервер и нагружаем его чем-нибудь. Я для примера запустил в двух разных консолях по команде:
Они достаточно быстро нагрузили единственное ядро тестового сервера, так что оставалось только подождать активации триггера. Через 5 минут это случилось.
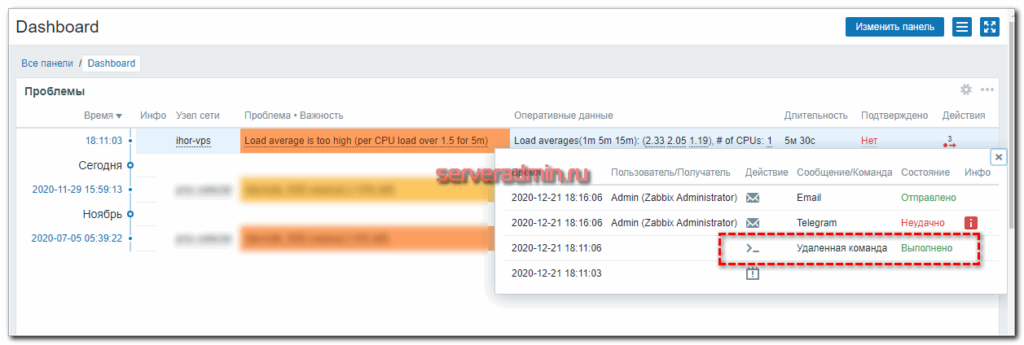
Иду в раздел Последние данные и вижу там список процессов, которые нагрузили мой сервер.
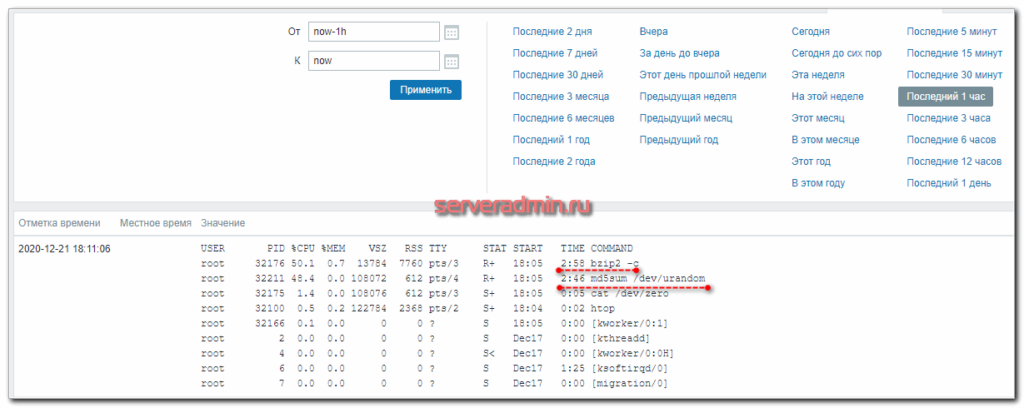
Что мне в итоге и требовалось. Теперь нет нужды каким-то образом проверять, что конкретно нагружает сервер. В момент пиковой нагрузки я получу список запущенных процессов в отдельный айтем. Для полного списка процессов все делается по аналогии.
Заключение
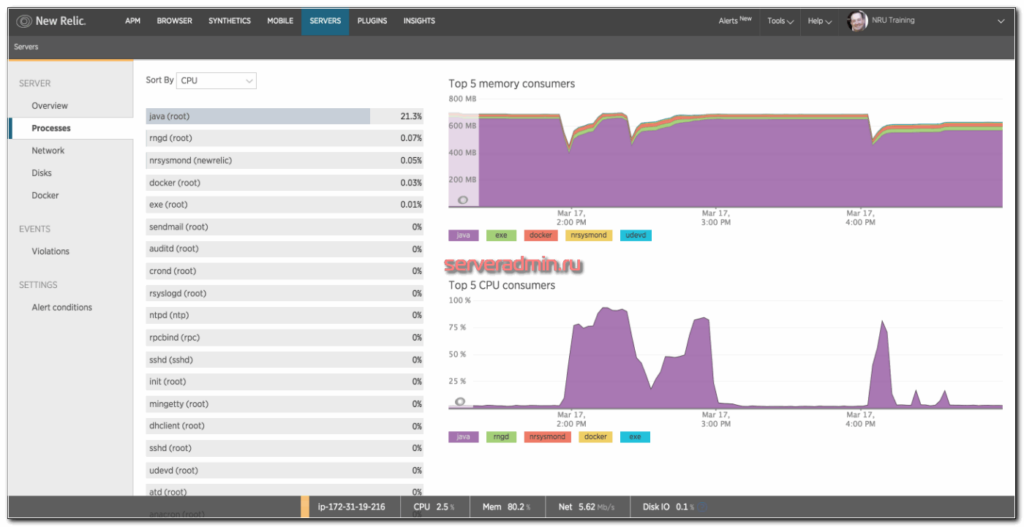
Вот такую реализацию я придумал, когда потребовалось решить задачу. Один сервер постоянно донимал оповещениями по ночам. Нужно было понять, что его дергает в это время. Жаль, что у Zabbix из коробки нет реализации подобного информирования. Помню лет 5 назад был бесплатный тариф у мониторинга NewRelic. Можно было поставить агент мониторинга на сервер и потом смотреть очень удобные отчеты в веб интерфейсе. Никаких настроек не нужно было, все работало из коробки. Там были отражены все запущенные процессы на сервере на временном ряду со всеми остальными метриками. Это было очень удобно. Я нигде в бесплатном софте не видел такой реализации. Это примерно вот так выглядело.
Кстати, в первоначальной версии действия я просто отправлял список процессов на почту. Мне показалось это удобным. Можно было сразу же в почте, в соседнем письме с триггером, посмотреть список процессов. Но потом решил, что удобнее все же хранить историю в одном месте на сервере и настроил сбор данных туда. Хотя можно делать и то, и другое. Например, в действии можно указать другую команду к исполнению:
И вам на почту придет список запущенных процессов после активации триггера.
ZABBIX — Настраиваем мониторинг служб
 Всем привет, часто возникает необходимость настроить мониторинг различные службы и всегда знать если что-то упало. В данной статье расскажу о том как настроить мониторинг служб по средствам Zabbix.
Всем привет, часто возникает необходимость настроить мониторинг различные службы и всегда знать если что-то упало. В данной статье расскажу о том как настроить мониторинг служб по средствам Zabbix.
ZABBIX — Настраиваем мониторинг служб.
Создаём элемент данных.
Для начала необходимо выбрать наш шаблон, к которому привязан интересующий нас узел сети, если его нет создаём, о том как создать шаблон можете прочитать тут: ZABBIX — Новый шаблон. В нашем случае шаблон у нас уже есть с привязанным к нему узлом сети. Переходим в “Настройка” -> “Шаблоны” -> Выбираем наш шаблон ->Выбираем “Элементы данных” и нажимаем кнопку “Создать элемент данных”
Zabbix-создаём элементы данных
Дальше необходимо вписать наши условия, оставляем все пункты по умолчанию, кроме “Имя” и “Ключ”. Вписываем любое угодное нам имя и в поле ключ нажимаем “Выбрать”
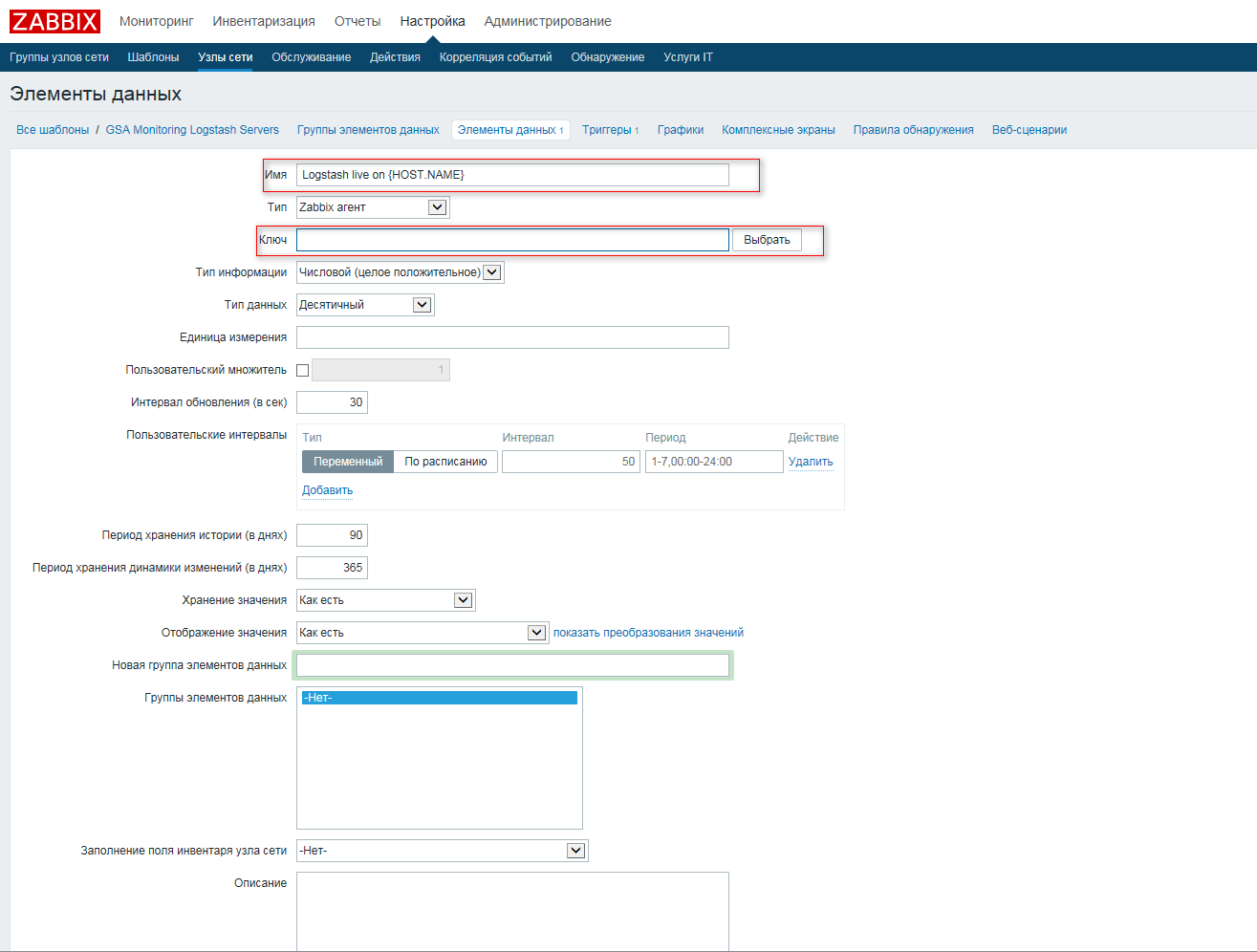
Ищем в списке ключ “proc.num[ , , , ]”, выбираем его.
Вот что про данный ключ пишут в документации Zabbix-а:
| proc.num[ , , , ] | ||||
|---|---|---|---|---|
| Количество процессов. | Целое число | имя – имя процесса (по умолчанию “все процессы”) пользователь – имя пользователя (по умолчанию “все пользователи”) состояние – возможные значения: all (по умолчанию), run, sleep, zomb cmdline – фильтр по командной строке (является регулярным выражением) | Примеры ключей: ⇒ proc.num[,mysql] – количество процессов выполняемых под пользователем mysql ⇒ proc.num[apache2,www-data] – количество процессов apache2 выполняемых под пользователем www-data ⇒ proc.num[,oracle,sleep,oracleZABBIX] – количество процессов в спящем состоянии выполняемых под oracle и имеющих oracleZABBIX в содержимом командной строкиСмотрите заметки по выбору процессов с параметрами имя и cmdline (специфика для Linux).В Windows, поддерживаются только параметры имя и пользователь. | |
Затем нам необходимо указать необходимые параметры для ключа. К примеру мы хотим настроить мониторинг демона под названием “sendsms”, тогда ключ у нас будет таким:
Мониторим статус процесса в Windows
В сегодняшней части по работе с сервером мониторинга Zabbix я разберу как мониторить наличие запущенного в системе определенного процесса , к примеру: службы Web-сервера для видеонаблюдения (ПО Intellect, процесс: WebServer.run), 1С сервера и т. д. Как всегда нужно начать с самого малого, а именно я рассмотрю как мониторить наличие запущенного процесса софтфона от Манго — Центр обработки вызовов он же ЦОВ. Имя процесса в диспетчере задач оси Windows 7 Professional SP1 значится, как mpoint.exe → только вот в их при работе программы целых два, но это ничего страшно. Данной заметкой я хочу понять, как работают встроенных средства самого Zabbix, а не задействование внешних обработок прописываемых на агентах. По возможности лучше использовать инструменты из коробки дабы потом проще было вспоминать (если конечно забудете), как и для чего используется.
Создаю новый элемент поведения:
http://IP&DNS — user&pass — Administration — General — Value mapping — Create value map —
- Name: Статус процесса в Диспетчере задач
- Mapping:
- Value: 0 — Mapped to: Процесс не запущен
- Value: 1 — Mapped to: Процесс запущен
и не забываем нажать Save для сохранения внесенных изменений.
Затем создаю в дефолтном шаблоне Template OS Windows новый элемент данных:
http://IP&DNS — user&pass — Configuration — Templates — Template OS Windows — Items — Create Item
- Name: Check Process TSOV
- Type: Zabbix agent
- Key: proc.num[mpoint.exe]
- Type of information: Numeric(unsigned)
- Data type: decimal
- Update interval (in sec): 30
- History storage period (in days): 90
- Trend storage period (in days): 365
- Applications: Processes
- Description: Центр обработки вызовов (ЦОВ)
- Enabled: отмечаю галочкой
По окончании настройки нового элемента данных не забываем нажать Save.
Затем перехожу в заведенный на мониторинг хост и создаю триггер на изменение поведения нацеленного элемента данных в нем:
http://IP&DNS — user&pass — Configuration — Hosts — Group (выбираю свою группу Windows Workstation) — затем перехожу в хост W7X86 — Triggers — Create Trigger
Вкладка: Trigger
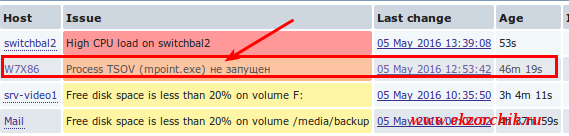
- Name: Process TSOV (mpoint.exe) не запущен
- Expression:
- Severity: Average
- Enabled: отмечаю галочкой
И не забываю нажать Save для применения настроек
Затем все также находясь в настройках хоста создаю описание для формирования графика по этому элементу данных:
http://IP&DNS — user&pass — Configuration — Hosts — Group (выбираю свою группу Windows Workstation) — затем перехожу в хост W7X86 — Graphs — Create graph
вкладка: Graph
- Name: Check Status process TSOV
- Y axis MIN value: Fixed = 0
- Y asis MAX value: Fixed = 2
Items — Add — нахожу созданный шагами ранее элемент данных Check Process TSOV, отмечаю его галочкой после нажимаю Select, Save и того получается:
- W7X86: Check Process TSOV (Function: all), Draw style: Line, Y axis side (Left) Colour: C80000
Теперь если на рабочей станции завершить процесс, то график будет следующим:
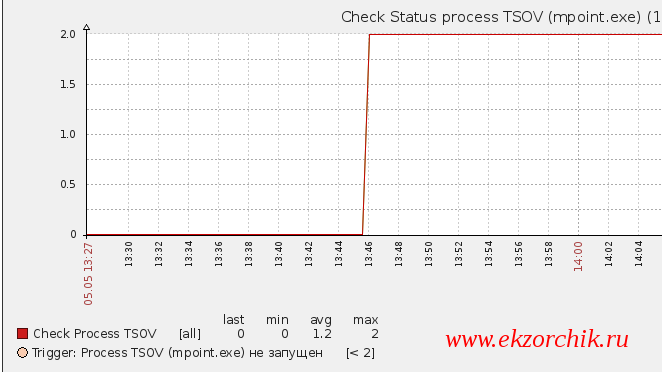
, т. е. Значение — 2 это когда в системе два запущенных процесса (а только так работает ЦОВ от Манго), а 0 — это когда ни одного процесса не запущено (т. е. Его нет в «Диспетчере задач») и также сработал trigger (триггер) на возникнувшее событие:
http://IP&DNS — user&pass — Monitoring — Dashboard
Если же нужно мониторить не количество процессов в «Диспетчере задач», то в элементе данных нужно добавить значение:
- Show Value: выбираем тот шаблон который создали выше именуемый, как: «Статус процесса в Диспетчере задач»
В настройках триггера хоста шаблон проверки будет таким:
А в настройках графика:
- Name: Check Status process TSOV
- Y axis MIN value: Fixed = 0
- Y asis MAX value: Fixed = 2
- Items: W7X86: Check Process TSOV (Function: all)
На заметку: лучше создать элемент данных не в дефолтном шаблоне, с создать свой ориентированный на определенную группу хостов на которых общие составляющие и триггеры с использование переменных окружения.

Вот пример для процесса WebServer.run ответственного за возможность через браузер подключиться к сервере видеонаблюдения с целью просмотра камер согласно должностным обязанностям за своими отделами:

Вот что мне и требовалось сделать. Для чего я именно на рабочей станции мониторю как каким-то процессом, дело в том, что у нас в компании имеется CallCenter который пользуется данным ПО для обработки звонков клиентов с последующим переводом на соответствующие отделы. А порой уже довольно часто у Манго наблюдаются различные проблемы при работе, доступ в интернет с рабочих станций на сервера Манго полный, но использование ЦОВ как софтфона это сущий геморрой по возникающим ошибкам для меня как системного администратора — я ведь ничего не могу сделать, сервис то ведь в облаке (ну где-то там и палец вверх). Обращения к поддержке результата решения не дают, а только в ответ слышу это будет исправлено в следующем релизе, давайте заведем заявку и все по такому же принципу. А так я буду уже знать что что-то уже случилось. На этом я прощаюсь, с уважением автор блога — ekzorchik.



