Processor Queue Length — Самый важный счетчик ЦП
 Счетчик Processor Queue Length является одной из самых важных метрик центрального процессора и показывает сколько запросов в данный момент находится в очереди к ЦП . Я не упоминал о нем в своих недавних статьях (Счетчики производительности процессора и Анализ счетчиков производительности CPU), ведь в них главным образом идет речь о счетчиках из двух групп — Процессор (Processor) и Сведения о процессоре (Processor Information), а Processor Queue Length (Длина очереди процессора) принадлежит группе Система (System).
Счетчик Processor Queue Length является одной из самых важных метрик центрального процессора и показывает сколько запросов в данный момент находится в очереди к ЦП . Я не упоминал о нем в своих недавних статьях (Счетчики производительности процессора и Анализ счетчиков производительности CPU), ведь в них главным образом идет речь о счетчиках из двух групп — Процессор (Processor) и Сведения о процессоре (Processor Information), а Processor Queue Length (Длина очереди процессора) принадлежит группе Система (System).
Если вам интересны счетчики производительности Windows, рекомендую обратиться к основной статье тематики — Счетчики производительности.
Processor Queue Length
Показания счетчика действительно очень важны для поиска проблем с производительностью процессора. Постоянное наличие большой очереди запросов к ЦП явно свидетельствует о том, что процессор не справляется с обработкой данных и является узким местом. Тем не менее до конца непонятно какие показания счетчика считаются явно плохими и указывающими на проблему, а какие являются нормой. В интернете вы не найдете исчерпывающей информации по этому вопросу, большинство ресурсов ограничивается простым описанием принципа работы счетчика, который и так очевиден.
На основе реальных данных попробуем разобраться что можно считать плохим или хорошим.
О чем реально может говорить большое количество запросов в очереди к ЦП в конкретный момент времени?
- Что ЦП как минимум задействован в работе и не простаивает. Это очевидный момент;
- Что ЦП по каким-либо причинам не смог переварить запросы в короткий промежуток времени и в связи с этим образовалась очередь;
- Какое-то приложение\оборудование генерирует запросы к ЦП;
- Какое-то приложение\драйверы имеют не слишком оптимизированный код и в связи с этим ЦП проводит много времени в ожидании между потоками.
Первый пункт в комментариях не нуждается, а вот второй нужно рассмотреть более детально. Обратимся к графику загрузки CPU реального сервера.
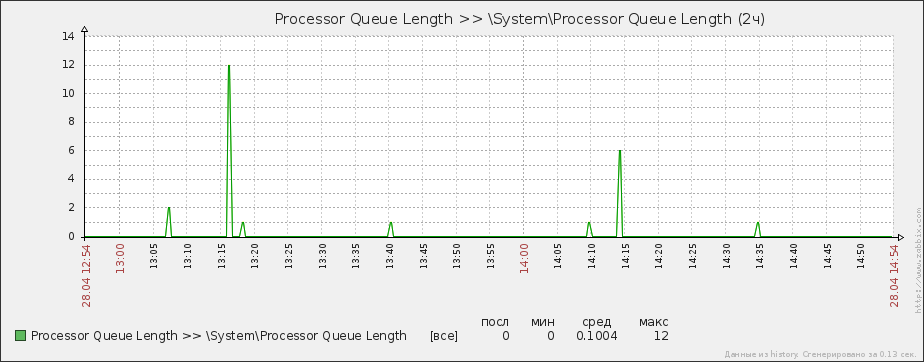
Вверху вы можете увидеть график длины очереди процессора на сервере Exchange 2013. Вылезают очень неприятные пики, в то время как по общеизвестным рекомендациям не должны встречаться ситуации, когда очередь составляет больше двукратного количества центральных процессоров на сервере (у меня один ЦП, значит максимальная очередь — 2, в разных источниках критической называют длину очереди 10 для одного CPU). Но теперь обратим внимание на загрузку ЦП, а именно на счетчик % Processor Time:
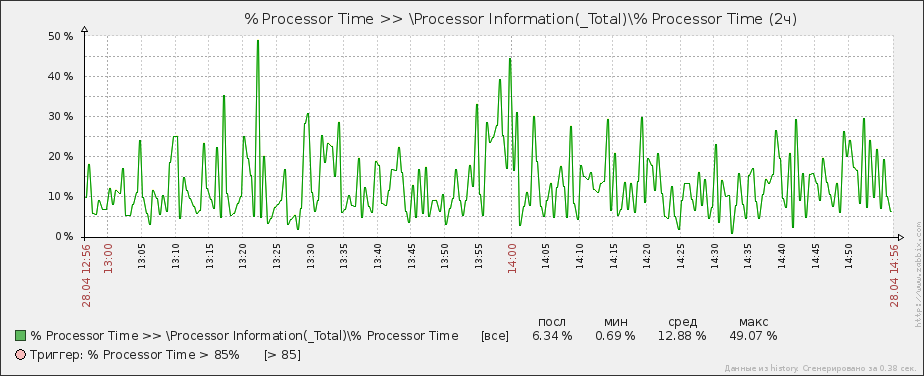
Как вы можете заметить, на графике даже пиковые значения загрузки ЦП не достигают и 50%, а это практически идеально подобранная производительность ЦП для тех задач, которые решает сервер — одновременно нет лишних простоев, но есть и запас производительности для периодов повышенной загрузки. В итоге делаем вывод:
Краткосрочные высокие значения очереди CPU являются нормой
Для примера рассмотрим ещё один график, но уже другого сервера — сервера СУБД MS SQL.
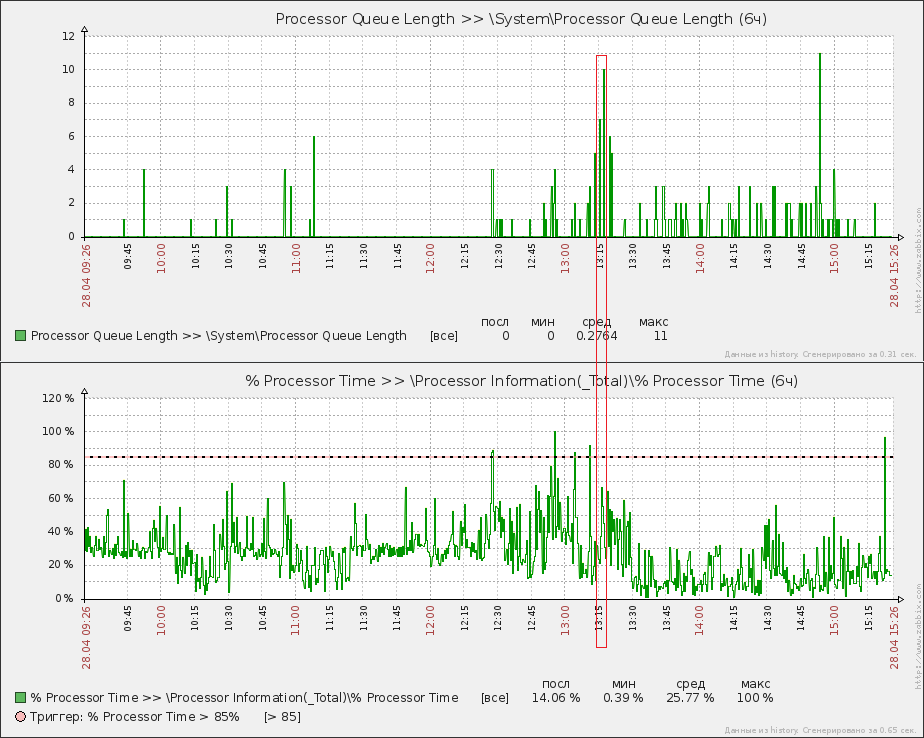
Пиковые значения очереди тут встречаются уже значительно чаще, но, надо отметить, они не совпадают с периодами максимальной загрузки ЦП (показательный случай выделен красной рамкой), а наоборот встречаются в моменты сравнительно низкой загрузки. В периоды своей низкой загрузки ЦП значительно чаще переходит в состояния пониженного энергопотребления и из этого можно сделать вывод, что, возможно, это тоже является причиной возникновения очередей.
То есть, как бы это парадоксально ни звучало, но графики говорят о том, что очередь может возникать во время простоев ЦП и причиной этому являются переходы В и выходы Из состояний пониженного энергопотребления. В этом случае анализируйте показания счетчиков % C1 Time, % C2 Time, % C3 Time, C1 Transitions/sec, C2 Transitions/sec, C3 Transitions/sec. Отключайте на уровне bios сам функционал перехода.
Хорошо, два примера выше иллюстрируют нормальное поведение ЦП, но что тогда считать проблемой? Есть у меня пример и на этот случай:
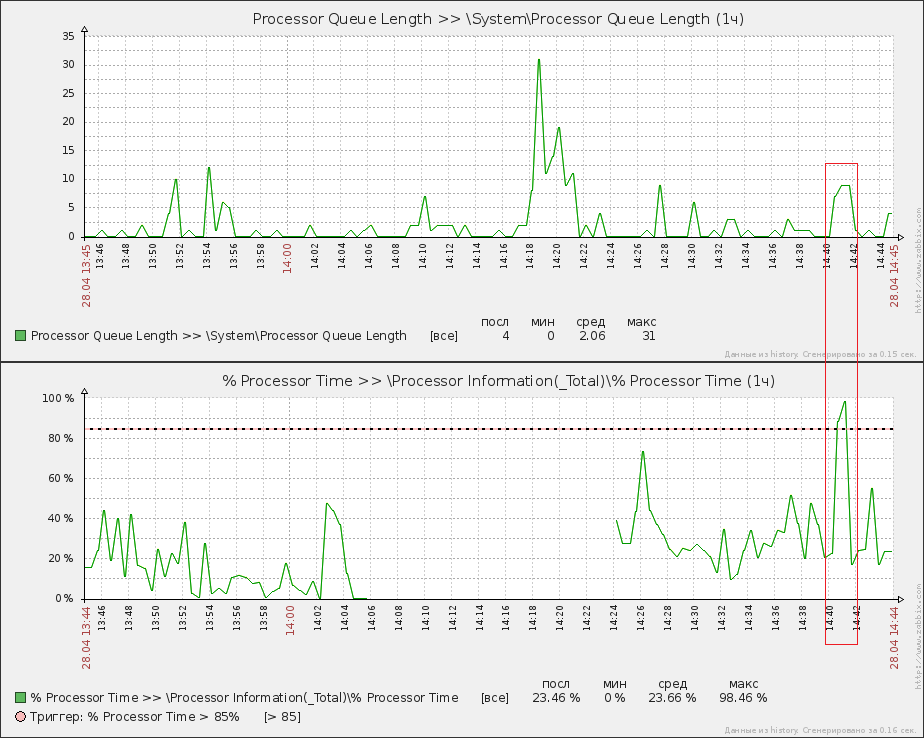
Это график одного из серверов, который выполняет требовательные к CPU задачи и на графиках явно видны ситуации, когда процессору не хватало мощности для обработки всего объема. В какой-то момент времени начались даже проблемы с доступностью данных счетчика % Processor Time — на нижнем графике есть достаточно большой пробел. По данным на графиках косвенно можно сделать вывод, что загрузка ЦП в момент очереди выше 10 была больше критической. Это подтверждает момент, когда очередь процессора стабильно находилась на уровне 6-8 единиц и % Processor Time показал загрузку >85% (на графике период выделен красной рамкой). Делаем вывод: проблемой является состояние, когда очередь ЦП находится стабильно выше 2. Ключевое слово стабильно.
Стоит отметить, что в каждом конкретном случае критическими могут быть разные значения. Главным критерием должна быть отзывчивость приложения. Например если сервер 1С стал регулярно выдавать средние значения очереди в 3 единицы, но пользователи при этом не заметили ухудшений вообще, то можно оставить все как есть. Если же пользователи стали резко жаловаться на тормоза программы и вы действительно заметили увеличение времени реакции ПО при выполнении обычных задач, вам нужно увеличить процессорную мощность.
Обращать внимание на Processor Queue Length > 2 в течение 5 минут. Критическим будет значение очереди >10 в течение 5 минут
На этом все, делитесь своим опытом в комментариях.
Processor Queue Length counter
According to Microsoft Processor Queue Length is a number Number of threads in the processor queue. Unlike the disk counters, this counter counters, this counter shows ready threads only, not threads that are running. A sustained processor queue of greater than two threads generally indicates processor congestion. There is a single queue for processor time even on computers with multiple processors. Therefore, if a computer has multiple processors, you need to divide this value by the number of processors servicing the workload. A sustained processor queue of less than 10 threads per processor is normally acceptable, dependent of the workload. This property displays the last observed value only; it is not an average.
The clearest symptom of a processor bottleneck is a sustained or recurring queue of more than two threads. Although queues are most likely to develop when the processor is very busy, they can develop when utilization is well below 90 percent. This can happen if requests for processor time arrive randomly and if threads demand irregular amounts of time from the processor.
For busy systems that experience processor utilization in the 80 to 90 percent range and use thread scheduling, the queue length should range from one to three threads per processor. For example, on a four-processor (4P) system, the expected range of processor queue length on a system with high CPU activity is 4 to 12. On systems with lower CPU utilization, the processor queue length is typically 0 or 1.
If the processor queue length exceeds the value recommended above, it generally indicates that there are more threads than the current processor can service in an optimal way. Reducing the number of threads or providing more CPU power, either by adding processors or upgrading to faster processors, are optional methods of shortening the processor queue.
Our System Monitor II gadget will show you your Processor Queue Length in a real time.
Анализ загруженности оборудования для Windows
Для своевременного обнаружения узких мест в оборудовании необходимо проводить постоянный мониторинг загруженности всех основных аппаратных компонентов системы. К ним в первую очередь относятся:
- Все рабочие сервера кластера 1С:Предприятия
- Сервер СУБД
- Клиентские рабочие станции, работающие под большой нагрузкой
Для каждого из этих компьютеров необходимо настроить сбор информации по загруженности оборудования.
Сбор информации по загруженности оборудования
Во время работы системы рекомендуется осуществлять постоянный мониторинг и запись основных показателей загруженности оборудования. Для этого можно использовать разные средства, в данной статье будет рассказано, как это можно сделать с помощью Performance Monitor, входящего в состав операционной системы Windows, и ЦКК – Центра контроля качества, типовой конфигурации, входящая в Корпоративный инструментальный пакет.
Настройка сборка данных в Performance Monitor (Windows Server 2012 R2)
Для запуска Performance Monitor выберите соответствующий пункт меню раздела Administrative Tools контрольной панели Windows.
Добавьте в список наборов счетчиков (Data Collector Sets) новый набор (User Defined – пользовательский):

Настройка будет осуществляться вручную – в диалоговом окне нужно выбрать соответствующий пункт и нажать «Далее»:
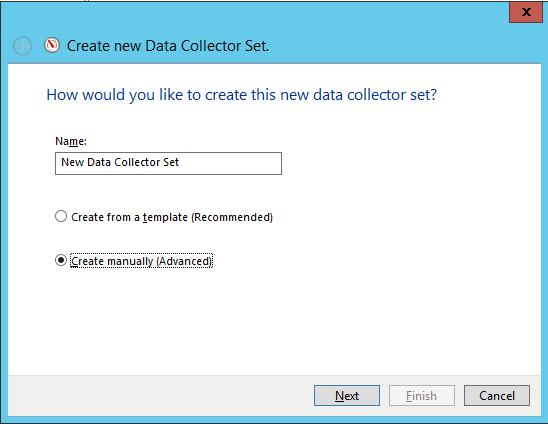
Выберите, какие именно данные будут собираться. Нас интересуют Счетчики производительности:
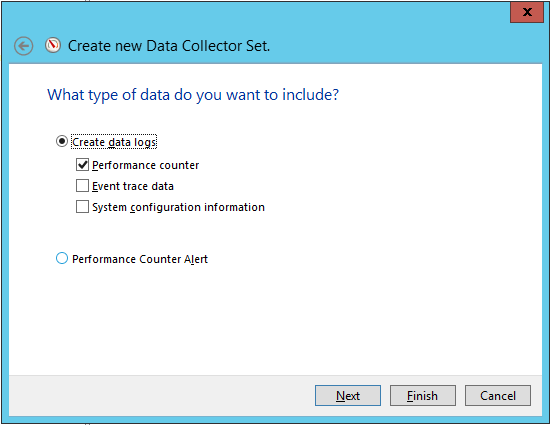
На следующем шаге выбираются сами счетчики, которые будут входить в набор.

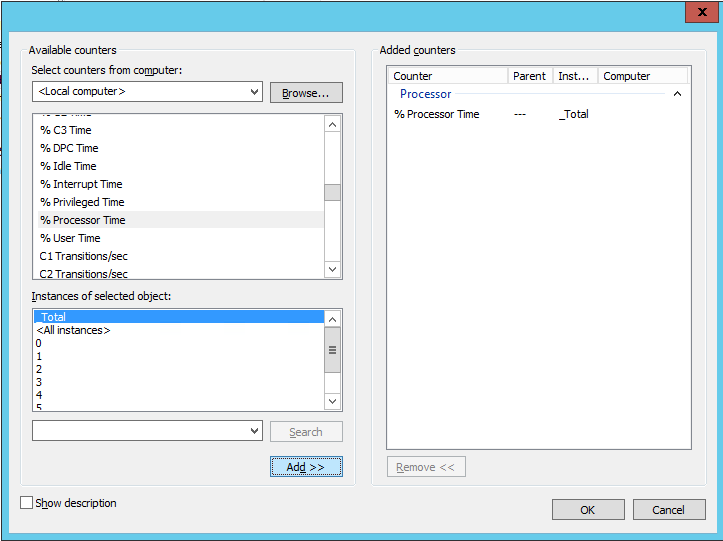
Мы рекомендуем в обязательном порядке собирать данные по следующим счетчикам:
«\Processor(_Total)\Interrupts/sec»
«\LogicalDisk(_Total)\% Free Space»
«\Memory\Available Mbytes»
«\PhysicalDisk(_Total)\Avg. Disk Queue Length»
«\PhysicalDisk(_Total)\Avg. Disk Sec/Read»
«\PhysicalDisk(_Total)\Avg. Disk Sec/Write»
«\Processor(_Total)\% Idle Time»
«\Processor(_Total)\% Processor Time»
«\Processor(_Total)\% User Time»
«\System\Context Switches/sec»
«\System\File Read Bytes/sec»
«\System\Context Switches/sec»
«\System\File Read Bytes/sec»
«\System\File Write Bytes/sec»
«\System\Processes»
«\System\Processor Queue Length»
«\System\Threads»
Состав счетчиков может меняться в зависимости от роли компьютера. Например, для сервера приложений 1С:Предприятие к перечисленным выше стоит добавить показатели работы процессов 1с:Предприятие:
«\Process(«1cv8*»)\% Processor Time»
«\Process(«1cv8*»)\Private Bytes»
«\Process(«1cv8*»)\Virtual Bytes»
«\Process(«ragent*»)\% Processor Time»
«\Process(«ragent*»)\Private Bytes»
«\Process(«ragent*»)\Virtual Bytes»
«\Process(«rphost*»)\% Processor Time»
«\Process(«rphost*»)\Private Bytes»
«\Process(«rphost*»)\Virtual Bytes»
«\Process(«rmngr*»)\% Processor Time»
«\Process(«rmngr*»)\Private Bytes»
«\Process(«rmngr*»)\Virtual Bytes»
Обратите внимание, что имена счетчиков могут незначительно отличаться в зависимости от версии вашей операционной системы
Рекомендуемая частота получения значений для рабочей системы – один раз в 15 секунд. В нагрузочных тестах рекомендуем собирать счетчики чаще, например, один раз в 1 секунду, т.к. длительность каждого непрерывного нагрузочного теста обычно не превышает десятка часов, а анализировать более детальные данные удобнее.По окончании выбора нажмите «Далее», укажите директорию хранения логов, при необходимости – пользователя, от имени которого будет запускаться процесс сборщика, и сохраните набор.
Откройте для дальнейшего редактирования его свойства (например, кликнув по нему в списке двойным щелчком мыши):

Можно выбрать формат файла логирования: бинарный удобен, если планируется анализировать графические данные, CSV – если планируется как-либо программно обрабатывать данные. В данном примере выбран бинарный.
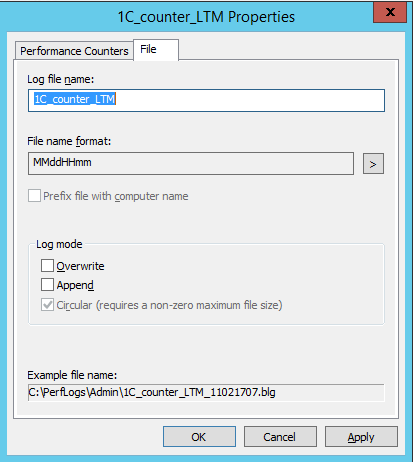
На закладке «Files» можно настроить шаблон имени файлов и режим записи. Для сохраненного набора также можно настроить расписание и задать ограничения и условия окончания сбора.

В данном случае замер не стартует автоматически, но на продуктивных площадках рекомендуется не забыть настроить планировщик задач на автозапуск выбранного счетчика, например, каждый час, если сбор данных ещё не запущен.
После сохранения можно запустить замер (при помощи кнопки Start контекстного меню).
Создать набор счетчиков Performance Monitor и управлять сбором данных можно не только интерактивно, но и при помощи консольной утилиты logman. Подробно работа с ней описана на сайте Microsoft https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/logman
Команда создания набора будет выглядеть так:
logman create counter 1C_counter -f bincirc -c «\Processor(_Total)\Interrupts/sec» «\LogicalDisk(_Total)\% Free Space» «\Memory\Available Mbytes» «\PhysicalDisk(_Total)\Avg. Disk Queue Length» «\PhysicalDisk(_Total)\Avg. Disk Sec/Read» «\PhysicalDisk(_Total)\Avg. Disk Sec/Write» «\Processor(_Total)\% Idle Time» «\Processor(_Total)\% Processor Time» «\Processor(_Total)\% User Time» «\System\Context Switches/sec» «\System\File Read Bytes/sec» «\System\Context Switches/sec» «\System\File Read Bytes/sec» «\System\File Write Bytes/sec» «\System\Processes» «\System\Processor Queue Length» «\System\Threads» -si 5 -v mmddhhmm
Анализ сохраненного замера
Для просмотра данных откройте бинарный файл замера .blg, по умолчанию Windows откроет такой тип при помощи Performance Monitor:
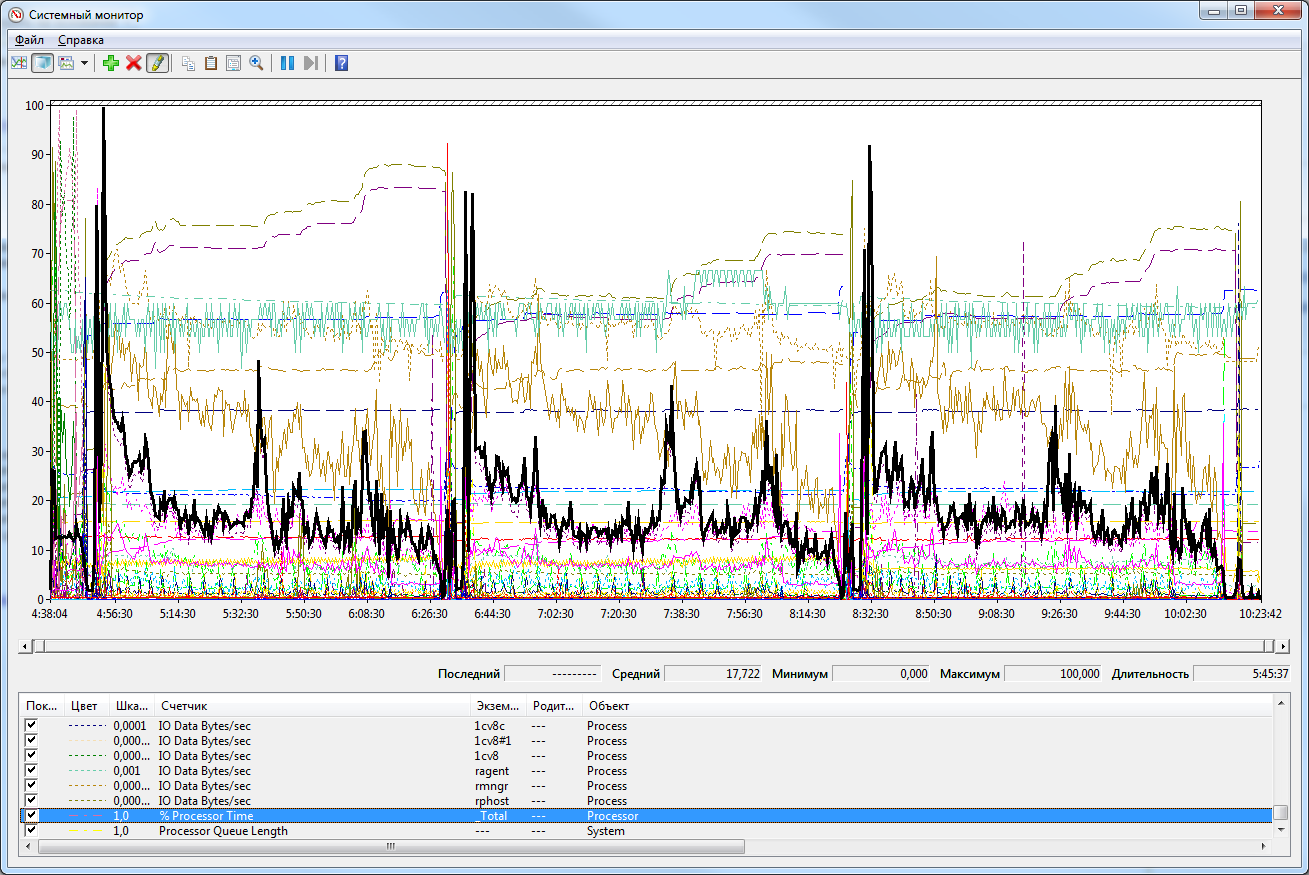
Выделить график, относящийся к конкретному счетчику, можно, встав на линию графика либо на строку счетчика в списке снизу. Для него при этом отобразятся среднее, минимальное, максимальное и последнее значение за период замера:

Интерес представляют, как правило, среднее значение и «пики» — максимум / минимум в зависимости от смысла счетчика.
Ниже в таблице приведены описания и предельные значения некоторых из них:



