- Как узнать загрузку процессора и памяти в Linux — команда vmstat
- Как нужно оценивать производительность?
- Синтаксис команды vmstat
- Опции vmstat
- Примеры использования vmstat
- Заключение
- увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- Re: увидеть загрузку процессора из консоли?
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Загрузка ЦПУ в Linux — насколько варит ваш котелок
- Методы проверки
- Проверяем загрузку процессора с помощью команды top
- Немного более модный способ: htop
- Прочие способы проверки степени загрузки ЦПУ
- Как настроить оповещения о слишком высокой нагрузке на процессор
- Заключение
Как узнать загрузку процессора и памяти в Linux — команда vmstat
Производительность (или непроизводительность) систем очень сложно оценивать «на глаз» или даже с секундомером. Ведь даже если это и получится, то из виду будут упущены ключевые детали, предоставляющие информацию о том, почему производительность может быть именно такой, а не больше (или меньше). Для выяснения причин стоит углубиться в анализ этой самой производительности более основательно. И для этих целей существуют специализированные утилиты, одной из которых является vmstat – довольно популярный инструмент (после команды top разве что), которым пользуются многие системные администраторы Linux.
Как нужно оценивать производительность?
Вообще, производительность и/или быстродействие — величины постоянные только для конкретного (и довольно короткого) промежутка времени для конкретной системы. Для более объективной оценки необходимо проводить многочисленные «замеры» в разное время в течении довольно длительного (месяц и более) периода.
Немаловажно и то, что анализ следует проводить без использования всевозможных «синтетических» тестов — т. е. только в условиях реальной и пиковой нагрузки, возникающей во время реальный задач, предусмотренных техпроцессом, регламентом в рамках реальной «производственной» необходимости. Очень часто именно в таких условиях можно выявить ошибки в конфигурации системы, приводящие к ограничениям в использовании программно-аппаратных ресурсов.
Синтаксис команды vmstat
Утилитой vmstat можно анализировать не только использование процессора, но также память — оперативную и/или дисковую. Синтаксис команды следующий:
Основными аргументами являются delay – время (в секундах), в течение которого следует производить замер, а также count – количество замеров или отчётов. Если дать команду vmstat без указания количества замеров, то она будет выводить отчёты, пока не будет прервано её выполнение сочетанием клавиш .
Вывод vmstat разбит на столбцы, которые объединены в следующие категории:
- procs – информация о процессах;
- memory – состояние оперативной памяти;
- swap – состояние виртуальной памяти (раздел или файл подкачки);
- io – активность устройств хранения (диски, флешки и т. д.);
- system – общая активность системы;
- cpu – использование центрального процессора.
Как уже было отмечено выше, эти категории объединяют колонки из вывода vmstat по соответствующему типу информации. Стоит рассмотреть их по отдельности. Для раздела procs:
- r – количество процессов в обрабатываемой процессором очереди;
- b – количество процессов, стоящих в очереди на выполнение операций ввода/вывода.
Для раздела memory:
- free – размер свободной памяти. То же значение, которое определяется командой free;
- swpd – количество блоков, которые были перемещены в Swap;
- buff – буферы памяти;
- cache – кеш памяти.
- si – общее количество блоков, считываемых системой из Swap;
- so – общее количество блоков, перемещаемых системой в Swap.
- bi – количество блоков в секунду, считываемых с диска;
- bo – количество блоков в секунду, записанных на диск.
- in – частота (количество в секунду) системных прерываний;
- cs – частота переключений между задачами.
- us – используемое (в процентах) время для выполнения «пользовательских» (т. е. не принадлежащих ядру) задач;
- sy — используемое (в процентах) время для выполнения задач ядра;
- id – время (в процентах) в простое;
- wa — время (в процентах), отведённое на ожидание операций ввода/вывода.
Опции vmstat
Доступные для vmstat опции приведены в следующей таблице:
| Опция | Назначение |
| -a, — active | Выводит активную и неактивную память. Доступно начиная с ядра версии 2.5.41 и выше. |
| -f, — forks | Выводит количество системных вызовов fork, vfork и rfork, а также страниц виртуальной памяти, используемых этими вызовами. |
| -m, — slabs | Количество используемой динамической памяти для ядра. |
| -n, —one-header | Отображает заголовок таблицы результатов только один раз, а не периодически. |
| -s, — stats | Переключение режима отображения вывода. |
| -d, — disk | Выводит статистику использования диска. |
| -w | Для больших объёмов данных увеличивает визуально ширину столбцов. |
| -p, — partition device | Выводит статистику использования раздела. Необходимо указывать раздел device. |
| -S, —unit character | Выводит статистику в указанных единицах [k, K, m, M] – в килобитах, килобайтах, мегабитах и мегабайтах соответственно. |
| — t, —timestamp | Добавлять к выводу время замеров. |
| — D, —disk-sum | Выводит общую статистику по использованию дисков. |
Примеры использования vmstat
Несмотря на то, что опции vmstat и позволяют получить ценные сведения, однако в большинстве случаев системные администраторы их практически не используют. Чаще всего использование vmstat сводится к следующему (что вполне достаточно):
Вообще, сервер общего назначения считается хорошо отбалансирован в плане нагрузки, если около 50% времени он тратит на обработку пользовательских задач и ещё столько же — на работу системных вызовов, взаимодействующих с ядром. Простои в системе должны быть — это потенциал для увеличения нагрузки, но в то же время они (простои) не должны быть слишком большими — это значит, что мощности сервера расходуются впустую.
Из приведённого примера следует, что центральный процессор практически постоянно переключается между высоконагруженными режимами и периодами почти полного простоя. Таким образом, можно сделать вывод, что необходима настройка используемого в работе сервера ПО и системной конфигурации для более равномерного распределения нагрузки.
Заключение
Как можно видеть, даже без использования графических приложений с графиками и диаграммами, обычная команда vmstat способна дать наглядную картину происходящего, касающегося использования ресурсов системы. Ну а самые объективные и достоверные результаты анализа производительности могут зависеть от применяемой для каждого конкретного случая методики.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
увидеть загрузку процессора из консоли?
А есть ли прога, показывающая текущую загрузку процессора (в процентах) в консоли? Их иксов таких навалов, а вот если доступна только консоль, как увидеть загрузку?
Re: увидеть загрузку процессора из консоли?
Re: увидеть загрузку процессора из консоли?
еще uptime поможет — тоже man почитай

Re: увидеть загрузку процессора из консоли?
uptime показывает какую то странную загрузку — число может быть как больше 1, так и меньше.
top — мгновенную (которая существенно может измениться через полсекунды).
А есть то, что среднюю загрузку показывает?
Re: увидеть загрузку процессора из консоли?
uptime показывает загрузку на момент обращения, среднюю за 5 и среднюю за 15 минут — это, соответственно и есть три выводимые им цифры — load average: 0.01, 0.13, 0.12. Типа все наглядно.
Re: увидеть загрузку процессора из консоли?
только топ умеет проценты мгновенные показывать, а в лоад аверидж среднее то среднее но совсем другое — как уже сказано оно может быть больше 1. Ну то есть по моему программы которая усредняет эту мгновенную загрузку которую выдает топ пока не написали.
Re: увидеть загрузку процессора из консоли?
ну то есть если Н процессов использующие полностью все свои кванты, то лоад авг будет около Н, а загрузка цпу вне зависимости от Н 100%=1.
Re: увидеть загрузку процессора из консоли?
cat /proc/loadavg 0.53 0.40 0.40 1/101 1710
а что означают последние два столбика цифр?
По поводу загрузки вообще — а как же в иксах тогда считают эту загрузку? Там чуть ли не в реальном времени ее рисуют в окошке.
Re: увидеть загрузку процессора из консоли?
Re: увидеть загрузку процессора из консоли?
> а что означают последние два столбика цифр?
1/101 — всего 101 процесс, из них 1 не спит.
1710 — у меня такое ощущение что это порядковый номер открытия этого файла /proc/loadavg — зачем это не представляю..
Re: увидеть загрузку процессора из консоли?
А вот интересно, возможно ли расчитать загрузку процессора в процентах? Или это нереально в силу того, что многозадачность тут по другому реализована (чем в виндовсах)? В них же в таскменеджере видно график загрузки, хотелось бы нечто подобное строить.
tload конечно вещь интересная, но мне нужны цифры, график я сам построю.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Загрузка ЦПУ в Linux — насколько варит ваш котелок
Понимать состояние ваших серверов с точки зрения их загрузки и производительности — крайне важная задача. В этой статье мы опишем несколько самых популярных методов для проверки и мониторинга загрузки ЦПУ на Linux хосте.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps


Методы проверки
Проверяем загрузку процессора с помощью команды top
Отличным способом проверки загрузки является команда top. Вывод этой команды выглядит достаточно сложным, зато если вы в нем разберетесь, то точно сможете понять какие процессы занимают большую часть ваших вычислительных мощностей.
Команда состоит всего из трех букв: top
У вас откроется окно в терминале, которое будет отображать запущенные сервисы в реальном времени, долю системных ресурсов, которую эти сервисы потребляют, общую сводку по загрузке CPU и т.д
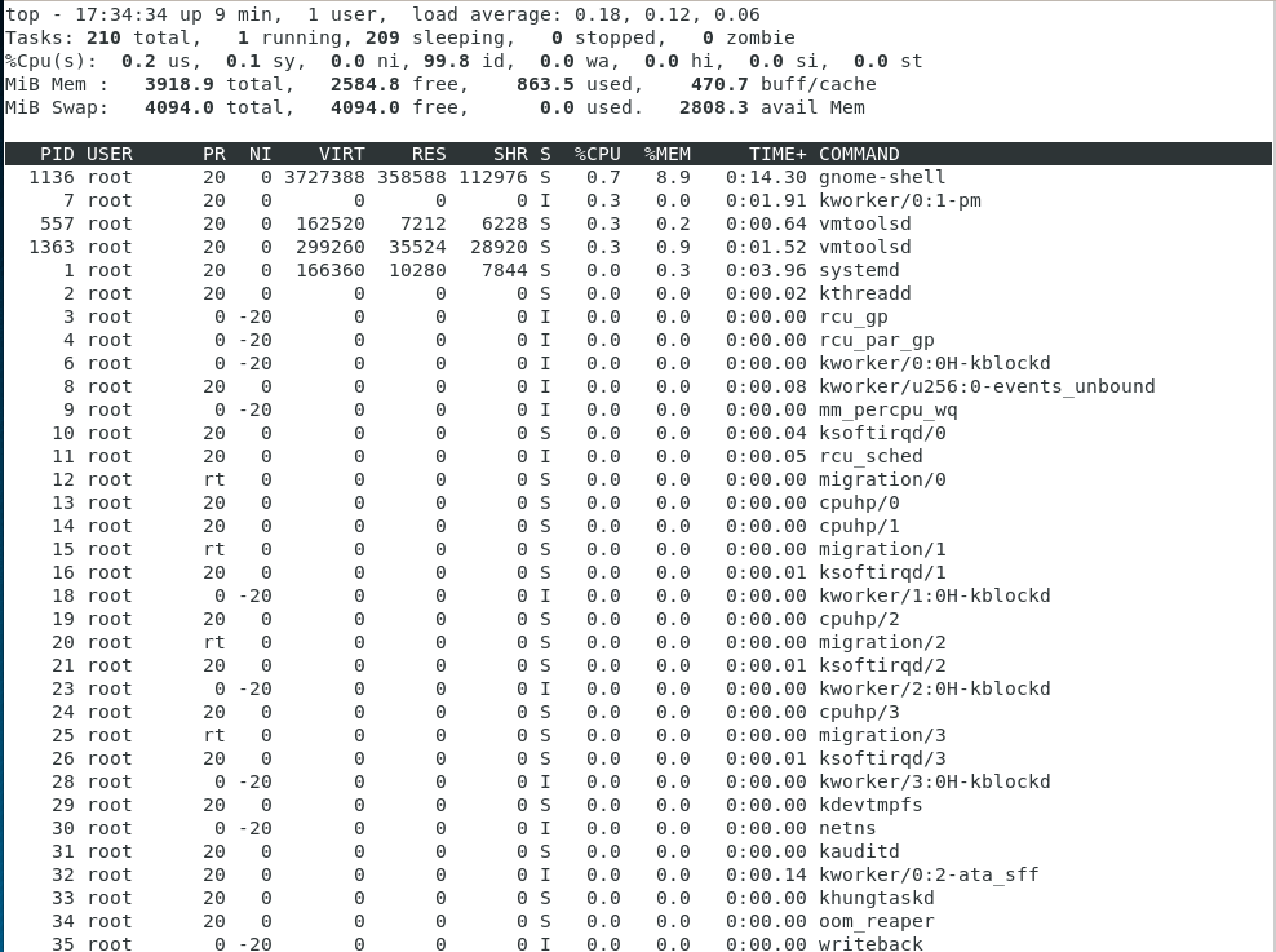
Будем идти по порядку: первая строчка отображает системное время, аптайм, количество активных пользовательских сессий и среднюю загруженность системы. Средняя загруженность для нас особенно важна, т.к дает понимание о среднем проценте утилизации ресурсов за некоторые промежутки времени.
Три числа показывают среднюю загрузку: за 1, 5 и 15 минут соответственно. Считайте, что эти числа — это процентная загрузка, т.е 0.2 означает 20%, а 1.00 — стопроцентную загрузку. Это звучит и выглядит достаточно логично, но иногда там могут проскакивать странные значения — вроде 2.50. Это происходит из-за того, что этот показатель не прямое значение загрузки процессора, а нечто вроде общего количества «работы», которое ваша система пытается выполнить. К примеру, значение 2.50 означает, что текущая загрузка равна 250% и ваша система на 150% перегружена.
Вторая строчка достаточна понятна и просто показывает количество задач, запущенных в системе и их текущий статус.
Третья строчка позволит вам отследить загрузку ЦПУ с подробной статистикой. Но здесь нужно сделать некоторые комментарии:
- us: процент времени, когда ЦПУ был загружен и которое было затрачено на user space (созданные/запущенные пользователем процессы)
- sy: процент времени, когда ЦПУ был загружен и которое было затрачено на на kernel (системные процессы)
- ni: процент времени, когда ЦПУ был загружен и которое было затрачено на приоритезированные пользовательские процессы (системные процессы)
- id: процент времени, когда ЦПУ не был загружен
- wa: процент времени, когда ЦПУ ожидал отклика от устройств ввода — вывода (к примеру, ожидание завершения записи информации на диск)
- hi: процент времени, когда ЦПУ получал аппаратные прерывания (например, от сетевого адаптера)
- si: процент времени, когда ЦПУ получал программные прерывания (например, от какого-то приложения адаптера)
- st: сколько процентов было «украдено» виртуальной машиной — в случае, если гипервизору понадобилось увеличить собственные ресурсы
Следующие две строчки показывают сколько занято/свободно оперативно памяти и файла подкачки, и не так релевантны относительно задачи проверки нагрузки на процессор. Под информацией о памяти вы увидите список процессов и процент ЦПУ, который они тратят.
Также вы можете нажимать на кнопку t, чтобы прокручивать между различными вариантами вывода информации и использовать кнопку q для выхода из top
Немного более модный способ: htop
Существует более удобная утилита под названием htop, которая предоставляет достаточно удобный интерфейс с красивым форматированием. Установка утилиты экстремально проста:
Для Ubuntu и Debian:
sudo apt-get install htop
Для CentOS и Red Hat:
yum install htop
dnf install htop
После установки просто введите команду ниже:

Как видно на скриншоте, htop гораздо лучше подходит для простой проверки степени загрузки процессора. Выход также осуществляется кнопкой q
Прочие способы проверки степени загрузки ЦПУ
Есть еще несколько полезных утилит, и одна из них (а точнее целый набор) называется sysstat.
Установка для Ubuntu и Debian:
sudo apt-get install sysstat
Установка для CentOS и Red Hat:
yum install sysstat
Как только вы установите systat, вы сможете выполнить команду mpstat — опять же, практически тот же вывод, что и у top, но в гораздо лаконичнее.

Следующая утилита в этом пакете это sar. Она наиболее полезна, если вы ее вводите вместе с каким-нибудь числом, например 6. Это определяет временной интервал, через который команда sar будет выводить информацию о загрузке ЦПУ.

К примеру, проверяем загрузку ЦПУ каждые 6 секунд:
Если же вы хотите остановить вывод после нескольких итераций, например 10, добавьте еще одно число:
Так вы также увидите средние значения за 10 выводов.
Как настроить оповещения о слишком высокой нагрузке на процессор
Одним из самых правильных способов является написание простого bash скрипта, который будет отправлять вам алерты о слишком высокой степени утилизации системных ресурсов.
Скрипт будет использовать обработчик sed и среднюю загрузку от команды sar. Как только нагрузка на сервер будет превышать 85%, администратор будет получать письмо на электронную почту. Соответственно, значения в скрипте можно изменить под ваши требования — к примеру поменять тайминги, выводить алерт в консоль, отправлять оповещения в лог и т.д.
Естественно, для выполнения этого скрипта нужно будет запустить его по крону:
Для ежеминутного запуска введите:
Заключение
Соответственно, лучшим способом будет комбинировать эти способы — например использовать htop при отладке и экспериментах, а для постоянного контроля держать запущенным скрипт.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена
Источник



