- Узнаём данные S.M.A.R.T. в Linux. Контроль состояния HDD или SSD
- База знаний wiki
- Содержание
- Проверка состояния жестких дисков в Linux
- Задача:
- Решение:
- Как проверить работоспособность SSD/HDD в Linux
- Проверка работоспособности SSD накопителя с помощью Smartctl
- Ubuntu
- RHEL и CentOS
- FEDORA
- Проверка работоспособности SSD/HDD
- Проверка работоспособности SSD/HDD дисков с помощью Gnome
- Установка Gnome Disks
- Заключение
- LINUX — Жизнь в консоли ЕСТЬ.
- Главное меню
- Последние статьи
- Счетчики
- SMART. Смотрим состояние жесткого диска.
- S.M.A.R.T. (англ. Self-Monitoring, Analysis and Reporting Technology) —
- А теперь немного о параметрах, выводимых программой.
- Критичные атрибуты:
- Некритичные атрибуты:
Узнаём данные S.M.A.R.T. в Linux. Контроль состояния HDD или SSD
Дата добавления: 07 июля 2012

S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology) — это технология, предоставляющая пользователю различные данные о текущем состоянии жесткого диска или твердотельного накопителя. Анализируя данные S.M.A.R.T., пользователь может оценить состояние своих накопителей и решить, требуют ли они замены или ещё смогут работать долго и без сбоев.
Консольный способ: smartmontools
Узнать данные S.M.A.R.T. в чистом виде нам поможет утилита под названием smartmontools .
Приведем пример установки для дистрибутивов на основе Debian:
Количество атрибутов может отличаться в зависимости от модели диска.
В этой таблице нам нужно смотреть на значение поля RAW_VALUE для нужного атрибута. Именно оно показывает текущее значение атрибута.
Наиболее важные показатели:
Raw_Read_Error_Rate — количество ошибок чтения. Ненулевое значение должно сильно насторожить, а большие значение и вовсе говорят о скором выходе диска из строя. Известно, что на дисках Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5? большое значение в этом поле является нормальным. Для остальных же дисков в идеале значение должно быть равно нулю;
Spin_Up_Time — время раскрутки диска. Измеряется в миллисекундах т.е. в моём случае это 1.3 секунды. Чем меньше — тем лучше. Большие значения говорят о низкой отзывчивости;
Start_Stop_Count — количество циклом запуска/остановки шпинделя;
Reallocated_Sector_Ct — количество перераспределённых секторов. Большое значение говорит о большом количестве ошибок диска;
Seek_Error_Rate — количество ошибок позиционирования. Большое значение говорит о плохом состоянии диска;
Power_On_Hours — количество наработанных часов во включённом состоянии. По нему можно узнать сколько проработал диск во включённом состоянии. Довольно полезно, например, если покупать ноутбук с витрины и хочется узнать долго ли он там стоял;
Power_Cycle_Count — количество включений/выключений диска;
Spin_Retry_Count — количество попыток повторной раскрутки. Большое значение говорит о плохом состоянии диска;
Temperature_Celsius — температура диска в градусах Цельсия. При слишком высокой температуре диски могут быстрее выйти из строя;
Reallocated_Event_Count — количество операций перераспределения секторов;
Offline_Uncorrectable — количество неисправных секторов. Большое значение говорит о повреждённой поверхности.
Более наглядный графический способ: gnome-disk-utility
В графическом варианте и с описанием атрибутов, данные SMART представляет программа gnome-disk-utility . В русской локализации в меню она называется как «дисковая утилита». В английской локализации известна как «Disks».
Пример установки для дистрибутивов на основе Debian:
Запускаем программу. 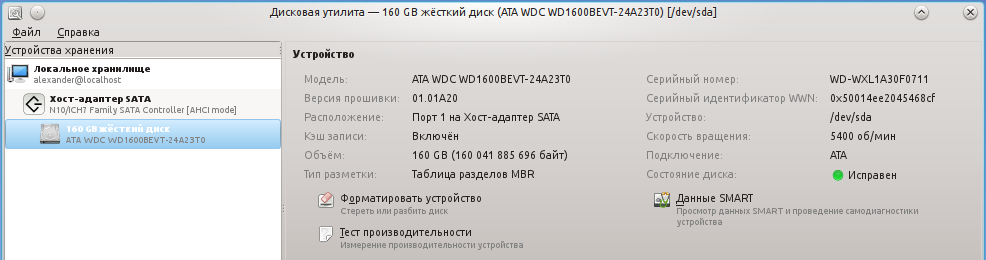
В поле «состояние диска» уже можно увидеть оценку состояния диска на основе данных S.M.A.R.T. Чтобы увидеть значение конкретных атрибутов нажимаем на кнопку «Данные SMART»: 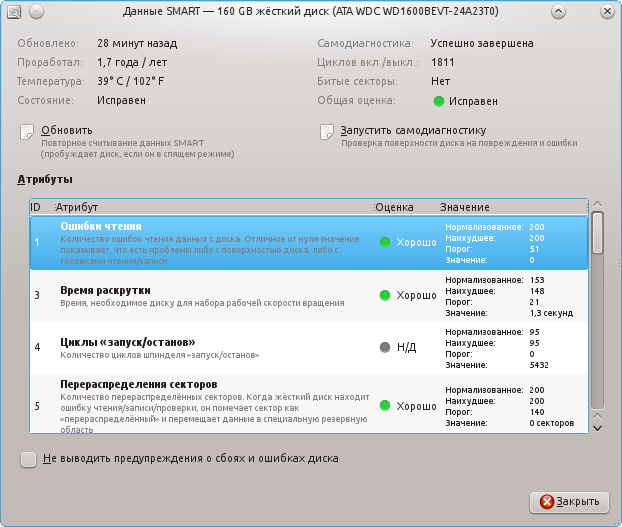
Пример данных о SSD (Твёрдотельном накопителе): 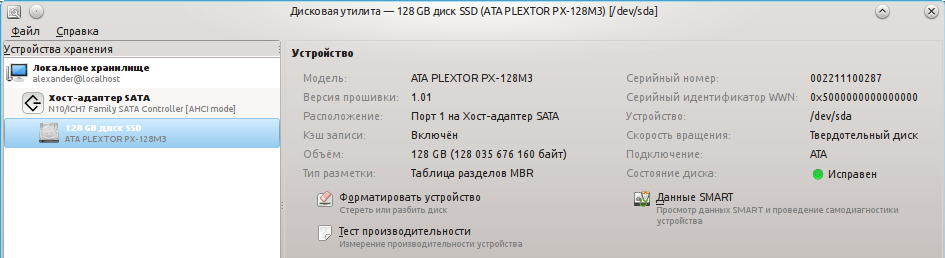
S.M.A.R.T.: 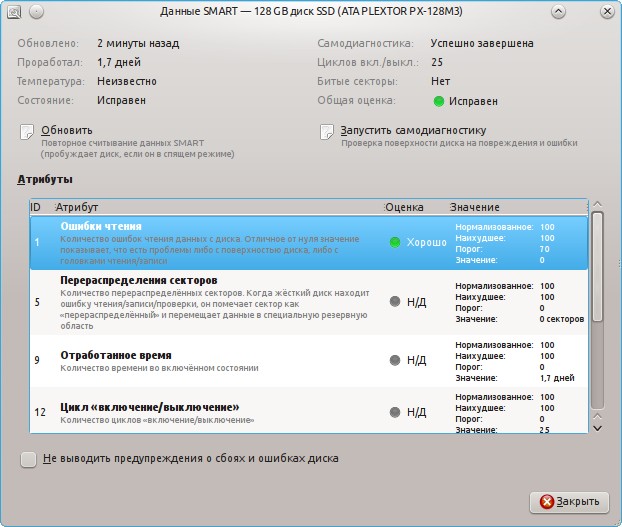
Здесь всё понятно и наглядно. Также присутствует описание атрибутов и оценка их показаний. Проблемные значения будут выделены красным цветом.
Источник
База знаний wiki
Продукты
Статьи
Содержание
Проверка состояния жестких дисков в Linux
Слова для поиска: проверка дисков, hdparm, badblocks, smart, smartctl, iostat, mdstat
Задача:
Проверить состояние жестких дисков на выделенном сервере, наличие сбойных блоков на HDD, анализ S.M.A.R.T
Решение:
В этой статье будут рассмотрены способы проверки и диагностики HDD в Linux. Полученная информация поможет проанализировать состояние жестких дисков, и, если это необходимо, заменить носитель до того, как он вышел из строя неожиданно и в самый не подходящий для этого момент.
Задуматься о состоянии HDD следует по некоторым признакам поведения системы в целом: резко выросла общая нагрузка на дисковую подсистему, упала скорость чтения/записи, другие проблемы косвенно указывающие что с HDD что-то не то.
Ниже я приведу основные команды, выполнять их необходимо из-под учётной записи root
Чтобы получить список подключенных HDD в систему, выполнить:
Мы получим листинг всех подключенных накопителей, их размер и имена устройств в системе.
Для того, чтобы посмотреть какие устройства и куда смонтированы, выполнить:
Узнать сколько на каждом из смонтированном носителе занято пространства, выполнить:
Если мы используем софтовых RAID, его состояние мы можем проверить следующей командой:
Если всё в порядке, то мы увидим что-то подобное:
Из вывода видно состояние raid (active), название устройства raid (md0) и какие устройства в него включены (sdb1[0] sdc1[1]), какой именно raid собран (raid1), в нём два диска и они оба работают в raid ([2/2] [UU])
Смотрим скорость чтения с накопителя
Где /dev/sdX — имя устройства которое необходимо проверить.
Полезной программой для анализа нагрузки на диски является iostat, входящей в пакет sysstat Ставим:
Теперь смотрим вывод iostat по всем дискам в системе:
С интервалом 10 секунд:
Или по определённому накопителю:
Полученные данные покажут нам нагрузку на устройства хранения, статистику по вводу/выводу, процент утилизации накопителя.
Переходим непосредственно к проверке накопителей. Проверка на наличие сбойных блоков осуществляется при помощи программы badblocks. Для проверки жесткого диска на бэдблоки, выполнить:
Где /dev/sdX — имя устройства которое необходимо проверить. Если программа обнаружит наличие сбойных блоков, она выведет их количество на консоль. Выполнение данной операции может занять продолжительное время (до нескольких часов) и желательно её выполнение на размонтированной файловой системе, либо в режиме read-only.
Для того, чтобы записать сбойные блоки, выполняем:
Где /tmp/badblock — файл куда программа запишет номера сбойных блоков.
Теперь при помощи программы e2fsck мы можем пометить сбойные блоки и они будут в дальнейшем игнорироваться системой. ВНИМАНИЕ! Данная операция должна проводиться на размонтированной файловой системе, либо в режиме read-only! Проверенное устройство и устройство на накотором будут помечаться сбойные блоки должно быть одно и тоже!
Если были обнаружены сбойные блоки на диске, есть тенденция появления новых бэдблоков, необходимо задуматься о скорейшем копировании данных и замене данного носителя. Приведённые выше команды помогут выявить сбойные блоки и пометить их как таковые, но не спасут «сыпящийся» диск.
Также в своём инструментарии полезно использовать данные полученные из S.M.A.R.T. дисков.
Ставим пакет smartmontools
Получаем данные S.M.A.R.T. жесткого диска:
Где /dev/sdX — имя устройства которое необходимо проверить.
Вы получите вывод атрибутов S.M.A.R.T., значение каждого из которых хорошо описаны в Википедии
Для сохранности данных настоятельно рекомендуем делать backup (резервное копирование). Это поможет в кратчайшие сроки восстановить необходимые данные и настройки в форс-мажорных обстоятельствах.
Источник
Как проверить работоспособность SSD/HDD в Linux
SMART (Технология самоконтроля, анализа и отчетности) — это функция, включенная во все современные жесткие диски и твердотельные накопители для мониторинга и тестирования надежности. Он проверяет различные атрибуты диска, чтобы обнаружить возможность отказа диска. Существуют различные инструменты, которые доступны в Linux и Windows для выполнения интеллектуальных тестов работоспособности.
Из этой инструкции вы узнаете, как проверить работоспособность SSD/HDD в Linux с помощью CLI и GUI
Здесь объясняются два метода:
- Использование Smartctl
- Использование Gnome disk
Проверка работоспособности SSD накопителя с помощью Smartctl
Smartctl — это утилита командной строки, которая может быть использована для проверки состояния жесткого диска или SSD с поддержкой S.M.A.R.T в системе Linux.
Утилита Smartctl utility tool поставляется вместе с пакетом smartmontools.Smartmontools доступна по умолчанию во всех дистрибутивах Linux, включая Ubuntu, RHEL, Centos и Fedora.
Как установить smartmontools в Linux:
Ubuntu
$ sudo apt install smartmontools
Запустите службу с помощью следующей команды.
RHEL и CentOS
$ sudo yum install smartmontools
FEDORA
$ sudo dnf install smartmontools
Служба Smartd запустится автоматически после успешной установки.
Если вдруг Smartd не запустился, сделать это можно командой:
Проверка работоспособности SSD/HDD
Чтобы проверить общее состояние введите команду:
Опишу команды подробнее:
d – Указывает тип устройства.
ata – тип устройства ATA, используйте scsi для типа устройства SCSI.
H – Проверяет устройство, чтобы сообщить о его состоянии и работоспособности.
 Проверка общего состояния
Проверка общего состояния
Полученный результат указывает на то, что диск исправен. Если устройство сообщает о неисправном состоянии работоспособности, это означает, что устройство уже вышло из строя или может выйти из строя очень скоро.
Это указывает на неудачное использование и появляется возможность получить дополнительную информацию.
Вы можете увидеть следующие атрибуты:
[ID 5] Reallocated Sectors Count – Количество секторов, перераспределенных из-за ошибок чтения.
[ID 187] Reported Uncorrect – Количество неисправимых ошибок при доступе к сектору чтения/записи.
[ID 230] Индикатор износа носителя – Текущее состояние работы диска на основе срока службы.
Если вы видите 100 — это лучшее значение. А если видите 0 — это ХУДШЕЕ значение.
Дополнительные сведения см. в разделе Сведения о интеллектуальных атрибутах.
Чтобы инициировать расширенный тест (long), выполните следующую команду:
Чтобы выполнить самотестирование, введите команду:
Чтобы найти результат самопроверки диска, используйте эту команду.
Чтобы оценить время выполнения теста, выполните следующую команду.
Вы можете распечатать журналы ошибок диска с помощью команды:
Проверка работоспособности SSD/HDD дисков с помощью Gnome
С помощью утилиты GNOME disks вы можете получить информацию о ваших SSD-дисков. Можете отформатировать диски, создать образ диска, выполнить стандартные тесты SSD-дисков и восстановить образ диска.
Установка Gnome Disks
В Ubuntu 20.04 приложение GNOME поставляется с установленным инструментом GNOME disk. Если вы не можете найти инструмент, используйте следующую команду для его установки.
$ sudo apt-get install gnome-disk-utility
GNOME Disk теперь установлен, далее вы можете перейти в меню рабочего стола и запустить его. Из приложения вы можете просмотреть все подключенные диски. А также можете использовать следующую команду для запуска приложения GNOME Disk.
Для того чтоб выполнить тест, запустите GNOME disks и выберите диск, который вы хотите протестировать. Вы можете найти быструю оценку дисков, таких как размер, разделение, серийный номер, температура и работоспособность. Нажмите на значок шестеренки и выберите SMART Data & Self-tests.
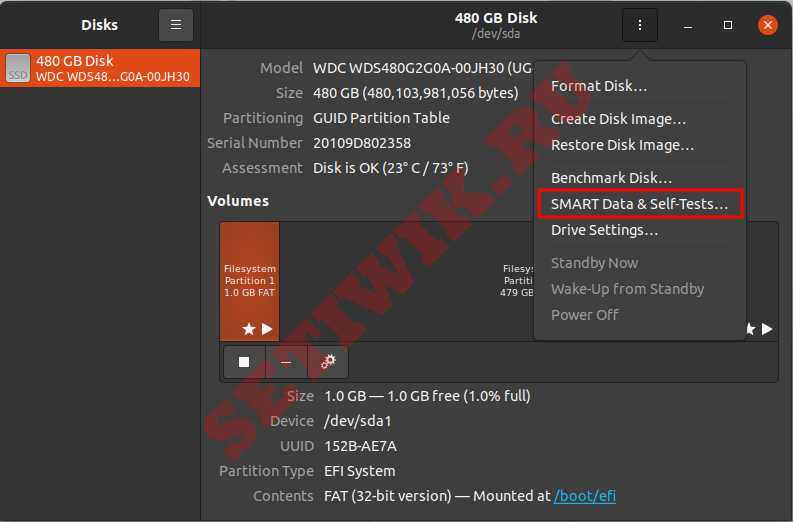 GNOME disks данные и самопроверки
GNOME disks данные и самопроверки
В новом окне вы можете найти результаты последнего теста. В правом верхнем углу окна вы можете обнаружить, что интеллектуальная опция включена. Если SMART отключен, его можно включить, нажав на ползунок. Чтобы начать новый тест, нажмите на кнопку Начать тестирование.
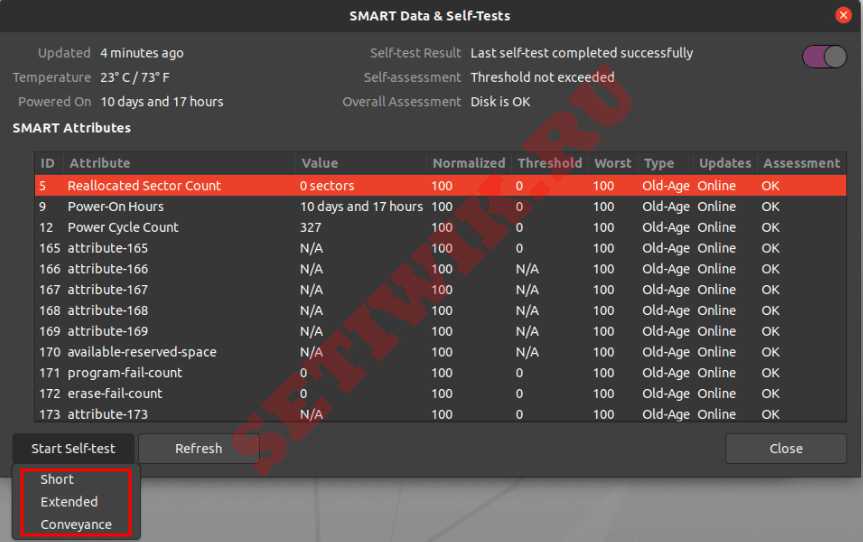 GNOME disks работает самотестирование
GNOME disks работает самотестирование
Как только будет нажата кнопка Начать Тестирование, появится выпадающее меню для выбора типа тестов:
- Короткие
- Расширенные
- Транспортировочные.
Выберите тип теста и введите свой пароль sudo. На индикаторе прогресса можно увидеть процент завершения теста.
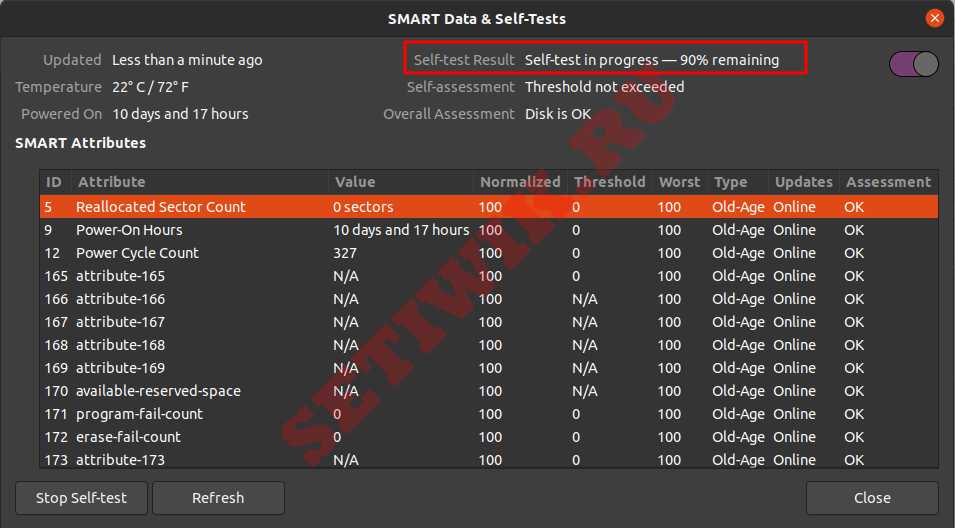 Результат самопроверки
Результат самопроверки
Заключение
В этой инструкции я объяснил основную концепцию технологии S. M. A. R. T,. Кроме того, я рассказал о том, как установить утилиту командной строки smartctl компьютер с Linux и как ее можно использовать для мониторинга работоспособности жестких дисков. У вас также есть представление о утилите GNOME Disks utility tool для мониторинга SSD-накопителей. Надеюсь, что эта статья поможет вам контролировать ваши SSD-диски с помощью утилиты smartctl и GNOME Disks.
Источник
LINUX — Жизнь в консоли ЕСТЬ.
Главное меню
Последние статьи
Счетчики
SMART. Смотрим состояние жесткого диска.
S.M.A.R.T. (англ. Self-Monitoring, Analysis and Reporting Technology) —
технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Ставим утилиту для просмотра SMART:
sudo su
apt-get install smartmontools
Смотрим названия жестких дисков в системе:
fdisk -l
Информация о диске, в том числе, поддерживает ли SMART:
smartctl -i /dev/sda
где /dev/sda «имя» диска
smartctl —smart=on /dev/sda
smartctl —all /dev/sda
А теперь немного о параметрах, выводимых программой.
Каждый атрибут имеет величину — Value. Value Изменяется в диапазоне от 0 до 255 (задается производителем). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше.
Raw Value — это значение атрибута во внутреннем формате производителя значение малоинформативно для всех кроме сервисманов.
Threshold — минимальное возможное значение атрибута, при котором гарантируется безотказная работа накопителя.
Если VALUE стало меньше THRESH — Атрибут считается failed и отображается в столбце WHEN_FAILED. При значении атрибута меньше Threshold очень вероятен сбой в работе или полный отказ.
WORST — минимальное нормализованное значение. Это минимальное значение которое достигалось с момента включения SMART на диске.
Атрибуты бывают критически важными (Pre-fail) и некритически важными (Old_age). Выход критически важного параметра за пределы Threshold фактический означает выход диска из строя, выход за переделы допустимых значений некритически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность.
Критичные атрибуты:
Raw Read Error Rate — частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time — время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся немаксимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например просадка по вольтажу блока питания.
Spin Up Retry Count — число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно немаксимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate — частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count — число операций переназначения секторов. SMART в современных дисках способен произвести анализ сектора на стабильность работы «на лету» и в случае признания его сбойным, произвести его переназначение.
Некритичные атрибуты:
Start/Stop Count — полное число запусков/остановов шпинделя. Гарантировано мотор диска способен перенести лишь определенное число включений/выключений. Это значение выбирается в качестве Treshold. Первые модели дисков со скоростью вращения 7200 оборотов/мин имели ненадежный двигатель, могли перенести лишь небольшое их число и быстро выходили из строя.
Power On Hours — число часов проведенных во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF). Обычно величина MTBF огромна, и маловероятно, что этот параметр достигнет критического порога. Но даже в этом случае выход из строя диска совершенно не обязателен.
Drive Power Cycle Count — количество полных циклов включения-выключения диска. По этому и предыдущему атрибуту можно оценить, например, сколько использовался диск до покупки.
Temperatue — Здесь хранятся показания встроенного термодатчика. Температура имеет огромное влияние на срок службы диска (даже если она находится в допустимых пределах). Вернее имеет влияние не на срок службы диска а на частоту возникновения некоторых типов ошибок, которые влияют на срок службы.
Current Pending Sector Count — Число секторов, являющихся кандидатами на замену. Они не были еще определенны как плохие, но считывание их отличается от чтения стабильного сектора, так называемые подозрительные или нестабильные сектора.
Uncorrectable Sector Count — число ошибок при обращении к сектору, которые не были скорректированы. Возможными причинами возникновения могут быть сбои механики или порча поверхности.
UDMA CRC Error Rate — число ошибок, возникающих при передаче данных по внешнему интерфейсу. Могут быть вызваны некачественными кабелями, нештатными режимами работы.
Write Error Rate — показывает частоту ошибок происходящих при записи на диск. Может служить показателем качества поверхности и механики накопителя.
Источник



