- Документация Beautiful Soup¶
- Техническая поддержка¶
- Быстрый старт¶
- Установка Beautiful Soup¶
- Проблемы после установки¶
- Установка парсера¶
- BeautifulSoup4 can’t be installed in python3.5 on Windows7
- ImportError: No module named bs4 in Windows
- 4 Answers 4
- Облегчаем себе жизнь с помощью BeautifulSoup4
- Начало
- Практика
- Документация Beautiful Soup¶
- Техническая поддержка¶
- Быстрый старт¶
- Установка Beautiful Soup¶
- Проблемы после установки¶
- Установка парсера¶
- Приготовление супа¶
- Виды объектов¶
- Атрибуты¶
- Многозначные атрибуты¶
- NavigableString ¶
- BeautifulSoup ¶
- Комментарии и другие специфичные строки¶
- Навигация по дереву¶
- Проход сверху вниз¶
- Навигация с использованием имен тегов¶
Документация Beautiful Soup¶

Beautiful Soup — это библиотека Python для извлечения данных из файлов HTML и XML. Она работает с вашим любимым парсером, чтобы дать вам естественные способы навигации, поиска и изменения дерева разбора. Она обычно экономит программистам часы и дни работы.
Эти инструкции иллюстрируют все основные функции Beautiful Soup 4 на примерах. Я покажу вам, для чего нужна библиотека, как она работает, как ее использовать, как заставить ее делать то, что вы хотите, и что нужно делать, когда она не оправдывает ваши ожидания.
Эта документация относится к Beautiful Soup версии 4.9.2. Примеры в документации работают одинаково на Python 2.7 и Python 3.8.
Возможно, вы ищете документацию для Beautiful Soup 3. Если это так, имейте в виду, что Beautiful Soup 3 больше не развивается, и что поддержка этой версии будет прекращена 31 декабря 2020 года или немногим позже. Если вы хотите узнать о различиях между Beautiful Soup 3 и Beautiful Soup 4, читайте раздел Перенос кода на BS4.
Эта документация переведена на другие языки пользователями Beautiful Soup:
Техническая поддержка¶
Если у вас есть вопросы о Beautiful Soup или возникли проблемы, отправьте сообщение в дискуссионную группу. Если ваша проблема связана с разбором HTML-документа, не забудьте упомянуть, что говорит о нем функция diagnose() .
Быстрый старт¶
Вот HTML-документ, который я буду использовать в качестве примера в этой документации. Это фрагмент из «Алисы в стране чудес» :
Прогон документа через Beautiful Soup дает нам объект BeautifulSoup , который представляет документ в виде вложенной структуры данных:
Вот несколько простых способов навигации по этой структуре данных:
Одна из распространенных задач — извлечь все URL-адреса, найденные на странице в тегах :
Другая распространенная задача — извлечь весь текст со страницы:
Это похоже на то, что вам нужно? Если да, продолжайте читать.
Установка Beautiful Soup¶
Если вы используете последнюю версию Debian или Ubuntu Linux, вы можете установить Beautiful Soup с помощью системы управления пакетами:
$ apt — get install python — bs4 (для Python 2)
$ apt — get install python3 — bs4 (для Python 3)
Beautiful Soup 4 публикуется через PyPi, поэтому, если вы не можете установить библиотеку с помощью системы управления пакетами, можно установить с помощью easy_install или pip . Пакет называется beautifulsoup4 . Один и тот же пакет работает как на Python 2, так и на Python 3. Убедитесь, что вы используете версию pip или easy_install , предназначенную для вашей версии Python (их можно назвать pip3 и easy_install3 соответственно, если вы используете Python 3).
$ pip install beautifulsoup4
( BeautifulSoup — это не тот пакет, который вам нужен. Это предыдущий основной релиз, Beautiful Soup 3. Многие программы используют BS3, так что он все еще доступен, но если вы пишете новый код, нужно установить beautifulsoup4 .)
Если у вас не установлены easy_install или pip , вы можете скачать архив с исходным кодом Beautiful Soup 4 и установить его с помощью setup.py .
$ python setup.py install
Если ничего не помогает, лицензия на Beautiful Soup позволяет упаковать библиотеку целиком вместе с вашим приложением. Вы можете скачать tar-архив, скопировать из него в кодовую базу вашего приложения каталог bs4 и использовать Beautiful Soup, не устанавливая его вообще.
Я использую Python 2.7 и Python 3.8 для разработки Beautiful Soup, но библиотека должна работать и с более поздними версиями Python.
Проблемы после установки¶
Beautiful Soup упакован как код Python 2. Когда вы устанавливаете его для использования с Python 3, он автоматически конвертируется в код Python 3. Если вы не устанавливаете библиотеку в виде пакета, код не будет сконвертирован. Были также сообщения об установке неправильной версии на компьютерах с Windows.
Если выводится сообщение ImportError «No module named HTMLParser», ваша проблема в том, что вы используете версию кода на Python 2, работая на Python 3.
Если выводится сообщение ImportError «No module named html.parser», ваша проблема в том, что вы используете версию кода на Python 3, работая на Python 2.
В обоих случаях лучше всего полностью удалить Beautiful Soup с вашей системы (включая любой каталог, созданный при распаковке tar-архива) и запустить установку еще раз.
Если выводится сообщение SyntaxError «Invalid syntax» в строке ROOT_TAG_NAME = u'[document]’ , вам нужно конвертировать код из Python 2 в Python 3. Вы можете установить пакет:
$ python3 setup.py install
или запустить вручную Python-скрипт 2to3 в каталоге bs4 :
$ 2to3 — 3.2 — w bs4
Установка парсера¶
Beautiful Soup поддерживает парсер HTML, включенный в стандартную библиотеку Python, а также ряд сторонних парсеров на Python. Одним из них является парсер lxml. В зависимости от ваших настроек, вы можете установить lxml с помощью одной из следующих команд:
$ apt — get install python — lxml
$ pip install lxml
Другая альтернатива — написанный исключительно на Python парсер html5lib, который разбирает HTML таким же образом, как это делает веб-браузер. В зависимости от ваших настроек, вы можете установить html5lib с помощью одной из этих команд:
$ apt — get install python — html5lib
$ pip install html5lib
Эта таблица суммирует преимущества и недостатки каждого парсера:
BeautifulSoup4 can’t be installed in python3.5 on Windows7
I have downloaded beautifulsoup4-4.5.3.tar.gz from https://www.crummy.com/software/BeautifulSoup/bs4/download/4.5/ and unzipped it to my python work directory(which is not my python install directory).
However, when I run
in my IDLE the error massage popped out:
I tried these methods but the error massage above keeps popping out
- open setup.py in my IDLE and run it(gives === RESTART: D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3\setup.py === in IDLE windows, but from bs4 import BeautifulSoup didn’t work)
- use cmd and go to D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3, run pip uninstall beautifulsoup4 then run pip install beautifulsoup4 ;it shows that I have successfully installed beautifulsoup4-4.5.3 in cmd line, however, error massage still appearred in IDLE after from bs4 import BeautifulSoup
- use cmd and go to D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3, run pip3 uninstall beautifulsoup4 then run pip3 install beautifulsoup4 ; useless as above
- run pip install bs4 —ignore-installed ,useless as above
- run setup.py install ,useless as above
- run 2to3 -w bs4 in cmd line under D:\python\beautifulsoup4-4.5.3\beautifulsoup4-4.5.3, returns ‘2to3’ is not recognized as an internal or external command,operable program or batch file.
what should I do?
beside, pip show bs4 gives this
under my C:\Users\myname\AppData\Local\Programs\Python\Python35-32\Lib\site-packages directory, I can see three beautifulsoup related directories:beautifulsoup4-4.5.3.dist-info, bs4 and bs4-0.0.1-py3.5.egg-info, but from bs4 import BeautifulSoup keep throwing out wrong message
ImportError: No module named bs4 in Windows
I am trying to create a script to download the captcha from my website. I think the code works except from that error, when I run it in cmd (I am using windows not Linux) I receive the following:
I tried using pip install BeautifulSoup4 but then I receive a syntax error at install.
Here is the script:
The problem according to this answer must be due to the fact I have not activated the virtualenv, and THEN install BeautifulSoup4.
I don’t think this information will be of any help but I saved my python text in a notepad.py and the run it using cmd.


4 Answers 4
I had the same problem until a moment ago. Thanks for the post and comments! According to @Martin Vseticka ‘s suggestion I checked if I have the pip.exe file in my python folders. I run python 2.7 and 3.7 simultaneously. I didn’t have it in the python 2.7 folder but in the 3.7. So in the command line I changed the directory to where the pip.exe file was located. Then I ran «pip install BeautifulSoup4» and it worked. See enclosed screen shot. 
I did a fresh install of Python 3.5 on my Windows 8.1 (64b) machine and then run:
test.py contains only:
I received no error.

I could install bs4, but still got an error message like yours. My operation system is 64 bit, and I only had this issue after I installed the latest Python in «32 bit» version. So I removed the 32 bit one, then I can import the bs4 again, and it still works after I install the latest Python in 64 version. Hope it helps.

I have python3.7 32bit and python3.7 64 bit installed on Windows 10. For this app, I am using the 32 bit version. I was getting the following error:
when I was trying to ‘import bs4’ from my app.py. Someone said: «Make sure your pip and your python are both 32 bits», but omitted to explicitly say how, so here it is:
Delete your virtual environment if it exists.
Create a new venv using python -m venv venv , but explicitly call it from your 32bit python directory like this: C:\Users\me\AppData\Local\Programs\Python\Python37-32\python -m venv my_venv
install the requirements by explicitly calling the 32bit version like this:
Облегчаем себе жизнь с помощью BeautifulSoup4
Приветствую всех. В этой статье мы сделаем жизнь чуточку легче, написав легкий парсер сайта на python, разберемся с возникшими проблемами и узнаем все муки пайтона что-то новое.
Статья ориентирована на новичков, таких же как и я.
Начало
Для начала разберем задачу. Взял я малоизвестный сайт новостей об Израиле, так как сам проживаю в этой стране, и хочется читать новости без рекламы и не интересных новостей. И так, имеется сайт, на котором постятся новости: есть новости помеченные красным, а есть обычные. Те что обычные — не представляют собой ничего интересного, а отмеченные красным являются самым соком. Рассмотрим наш сайт.
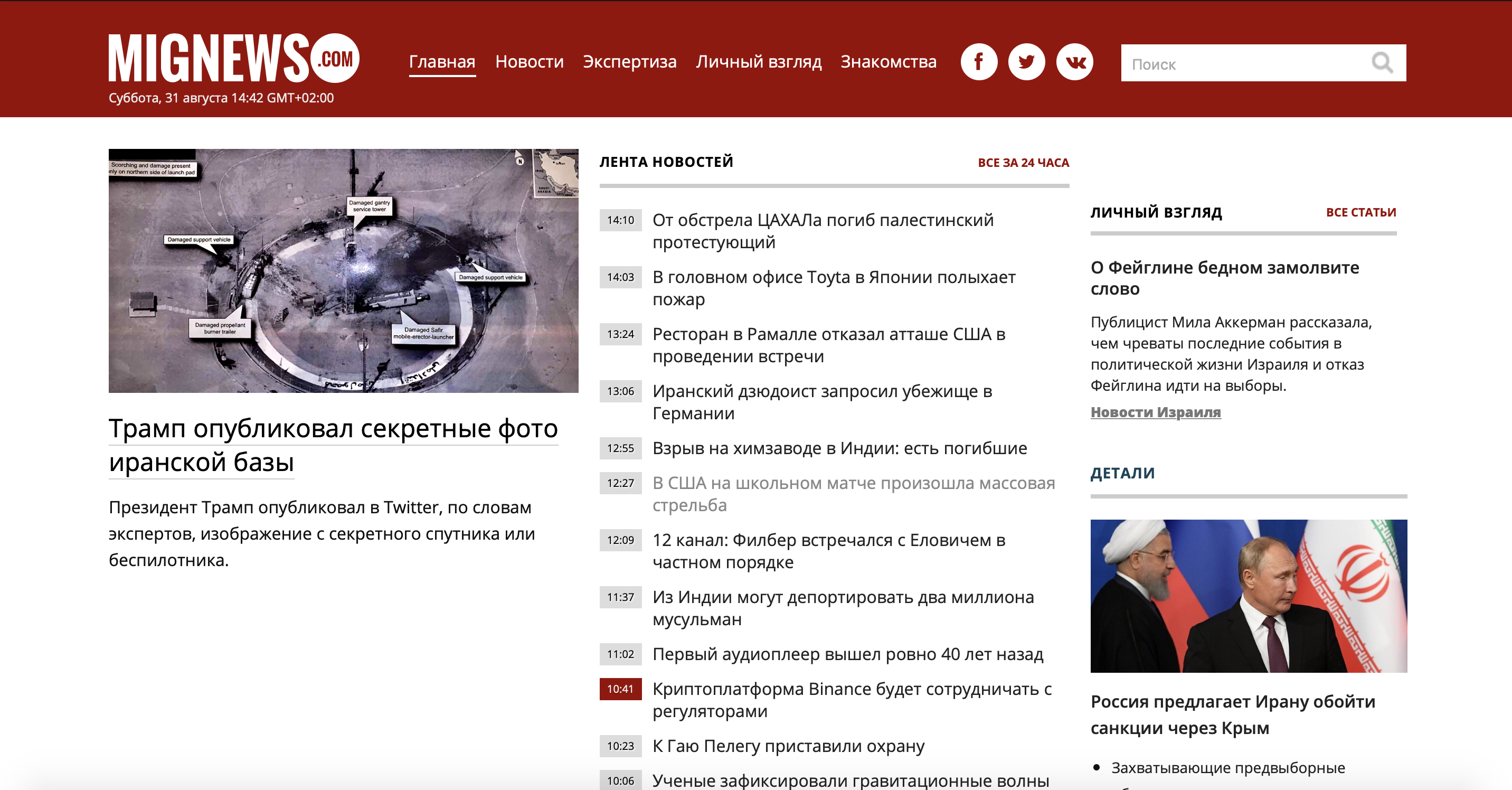
Как видно сайт достаточно большой и есть много ненужной информации, а ведь нам нужно использовать лишь контейнер новостей. Давайте использовать мобильную версию сайта,
чтобы сэкономить себе же время и силы.

Как видите, сервер отдал нам красивый контейнер новостей (которых, кстати, больше чем на основном сайте, что нам на руку) без рекламы и мусора.
Давайте рассмотрим исходный код, чтобы понять с чем мы имеем дело.

Как видим каждая новость лежит по-отдельности в тэге ‘a’ и имеет класс ‘lenta’. Если мы откроем тэг ‘a’, то заметим, что внутри есть тэг ‘span’, в котором находится класс ‘time2’, либо ‘time2 time3’, а также время публикации и после закрытия тэга мы наблюдаем сам текст новости.
Что отличает важную новость от неважной? Тот самый класс ‘time2’ или ‘time2 time3’. Новости помеченые ‘time2 time3’ и являются нашими красными новостями. Раз уж суть задачи понятна, перейдем к практике.
Практика
Для работы с парсерами умные люди придумали библиотеку «BeautifulSoup4», в которой есть еще очень много крутых и полезных функций, но об этом в следующий раз. Нам также понадобиться библиотека Requests позволяющая отправлять различные http-запросы. Идем их скачивать.
(убедитесь, что стоит последняя версия pip)
Переходим в редактор кода и импортируем наши библиотеки:
Для начала сохраним наш URL в переменную:
Теперь отправим GET()-запрос на сайт и сохраним полученное в переменную ‘page’:
Код вернул нам статус код ‘200’, значит это, что мы успешно подключены и все в полном порядке.
Теперь создадим два списка (позже я объясню для чего они нужны):
Самое время воспользоваться BeautifulSoup4 и скормить ему наш page, указав в кавычках как он нам поможет ‘html.parcer’:
Если попросить его показать, что он там сохранил:
Нам вылезет весь html-код нашей страницы.
Теперь воспользуемся функцией поиска в BeautifulSoup4:
Давайте разберём поподробнее, что мы тут написали.
В ранее созданный список ‘news’ (к которому я обещал вернуться), сохраняем все с тэгом ‘а’ и классом ‘news’. Если попросим вывести в консоль все, что он нашел, он покажет нам все новости, что были на странице:

Как видите, вместе с текстом новостей вывелись теги ‘a’, ‘span’, классы ‘lenta’ и ‘time2’, а также ‘time2 time3’, в общем все, что он нашел по нашим пожеланиям.
Тут мы в цикле for перебираем весь наш список новостей. Если в новости мы находим тэг ‘span’ и класc ‘time2 time3’, то сохраняем текст из этой новости в новый список ‘filteredNews’.
Обратите внимание, что мы используем ‘.text’, чтобы переформатировать строки в нашем списке из ‘bs4.element.ResultSet’, который использует BeautifulSoup для своих поисков, в обычный текст.
Однажды я застрял на этой проблеме надолго в силу недопонимания работы форматов данных и неумения использовать debug, будьте осторожны. Таким образом теперь мы можем сохранять эти данные в новый список и использовать все методы списков, ведь теперь это обычный текст и, в общем, делать с ним, что нам захочется.
Выведем наши данные:
Вот что мы получаем:

Мы получаем время публикации и лишь интересные новости.
Дальше можно построить бот в Телеге и выгружать туда эти новости, либо создать виджет на рабочий стол с актуальными новостями. В общем, можно придумать удобный для себя способ узнавать о новостях.
Надеюсь эта статья поможет новичкам понять, что можно делать с помощью парсеров и поможет им немного продвинуться вперед с обучением.
Спасибо за внимание, был рад поделиться опытом.
Документация Beautiful Soup¶

Beautiful Soup — это библиотека Python для извлечения данных из файлов HTML и XML. Она работает с вашим любимым парсером, чтобы дать вам естественные способы навигации, поиска и изменения дерева разбора. Она обычно экономит программистам часы и дни работы.
Эти инструкции иллюстрируют все основные функции Beautiful Soup 4 на примерах. Я покажу вам, для чего нужна библиотека, как она работает, как ее использовать, как заставить ее делать то, что вы хотите, и что нужно делать, когда она не оправдывает ваши ожидания.
Примеры в этой документации работают одинаково на Python 2.7 и Python 3.2.
Возможно, вы ищете документацию для Beautiful Soup 3. Если это так, имейте в виду, что Beautiful Soup 3 больше не развивается, и что поддержка этой версии будет прекращена 31 декабря 2020 года или немногим позже. Если вы хотите узнать о различиях между Beautiful Soup 3 и Beautiful Soup 4, читайте раздел Перенос кода на BS4.
Эта документация переведена на другие языки пользователями Beautiful Soup:
Техническая поддержка¶
Если у вас есть вопросы о Beautiful Soup или возникли проблемы, отправьте сообщение в дискуссионную группу. Если ваша проблема связана с разбором HTML-документа, не забудьте упомянуть, что говорит о нем функция diagnose() .
Быстрый старт¶
Вот HTML-документ, который я буду использовать в качестве примера в этой документации. Это фрагмент из «Алисы в стране чудес» :
Прогон документа через Beautiful Soup дает нам объект BeautifulSoup , который представляет документ в виде вложенной структуры данных:
Вот несколько простых способов навигации по этой структуре данных:
Одна из распространенных задач — извлечь все URL-адреса, найденные на странице в тегах :
Другая распространенная задача — извлечь весь текст со страницы:
Это похоже на то, что вам нужно? Если да, продолжайте читать.
Установка Beautiful Soup¶
Если вы используете последнюю версию Debian или Ubuntu Linux, вы можете установить Beautiful Soup с помощью системы управления пакетами:
$ apt-get install python-bs4 (для Python 2)
$ apt-get install python3-bs4 (для Python 3)
Beautiful Soup 4 публикуется через PyPi, поэтому, если вы не можете установить библиотеку с помощью системы управления пакетами, можно установить с помощью easy_install или pip . Пакет называется beautifulsoup4 . Один и тот же пакет работает как на Python 2, так и на Python 3. Убедитесь, что вы используете версию pip или easy_install , предназначенную для вашей версии Python (их можно назвать pip3 и easy_install3 соответственно, если вы используете Python 3).
$ pip install beautifulsoup4
( BeautifulSoup — это, скорее всего, не тот пакет, который вам нужен. Это предыдущий основной релиз, Beautiful Soup 3. Многие программы используют BS3, так что он все еще доступен, но если вы пишете новый код, нужно установить beautifulsoup4 .)
Если у вас не установлены easy_install или pip , вы можете скачать архив с исходным кодом Beautiful Soup 4 и установить его с помощью setup.py .
$ python setup.py install
Если ничего не помогает, лицензия на Beautiful Soup позволяет упаковать библиотеку целиком вместе с вашим приложением. Вы можете скачать tar-архив, скопировать из него в кодовую базу вашего приложения каталог bs4 и использовать Beautiful Soup, не устанавливая его вообще.
Я использую Python 2.7 и Python 3.2 для разработки Beautiful Soup, но библиотека должна работать и с более поздними версиями Python.
Проблемы после установки¶
Beautiful Soup упакован как код Python 2. Когда вы устанавливаете его для использования с Python 3, он автоматически конвертируется в код Python 3. Если вы не устанавливаете библиотеку в виде пакета, код не будет сконвертирован. Были также сообщения об установке неправильной версии на компьютерах с Windows.
Если выводится сообщение ImportError “No module named HTMLParser”, ваша проблема в том, что вы используете версию кода на Python 2, работая на Python 3.
Если выводится сообщение ImportError “No module named html.parser”, ваша проблема в том, что вы используете версию кода на Python 3, работая на Python 2.
В обоих случаях лучше всего полностью удалить Beautiful Soup с вашей системы (включая любой каталог, созданный при распаковке tar-архива) и запустить установку еще раз.
Если выводится сообщение SyntaxError “Invalid syntax” в строке ROOT_TAG_NAME = u'[document]’ , вам нужно конвертировать код из Python 2 в Python 3. Вы можете установить пакет:
$ python3 setup.py install
или запустить вручную Python-скрипт 2to3 в каталоге bs4 :
Установка парсера¶
Beautiful Soup поддерживает парсер HTML, включенный в стандартную библиотеку Python, а также ряд сторонних парсеров на Python. Одним из них является парсер lxml. В зависимости от ваших настроек, вы можете установить lxml с помощью одной из следующих команд:
$ apt-get install python-lxml
$ pip install lxml
Другая альтернатива — написанный исключительно на Python парсер html5lib, который разбирает HTML таким же образом, как это делает веб-браузер. В зависимости от ваших настроек, вы можете установить html5lib с помощью одной из этих команд:
$ apt-get install python-html5lib
$ pip install html5lib
Эта таблица суммирует преимущества и недостатки каждого парсера:
| Парсер | Типичное использование | Преимущества | Недостатки |
| html.parser от Python | BeautifulSoup(markup, «html.parser») |
|
|
| HTML-парсер в lxml | BeautifulSoup(markup, «lxml») |
|
|
| XML-парсер в lxml | BeautifulSoup(markup, «lxml-xml») BeautifulSoup(markup, «xml») |
|
|
| html5lib | BeautifulSoup(markup, «html5lib») |
|
|
Я рекомендую по возможности установить и использовать lxml для быстродействия. Если вы используете версию Python 2 более раннюю, чем 2.7.3, или версию Python 3 более раннюю, чем 3.2.2, необходимо установить lxml или html5lib, потому что встроенный в Python парсер HTML просто недостаточно хорош в старых версиях.
Обратите внимание, что если документ невалиден, различные парсеры будут генерировать дерево Beautiful Soup для этого документа по-разному. Ищите подробности в разделе Различия между парсерами.
Приготовление супа¶
Чтобы разобрать документ, передайте его в конструктор BeautifulSoup . Вы можете передать строку или открытый дескриптор файла:
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
Затем Beautiful Soup анализирует документ, используя лучший из доступных парсеров. Библиотека будет использовать HTML-парсер, если вы явно не укажете, что нужно использовать XML-парсер. (См. Разбор XML.)
Виды объектов¶
Beautiful Soup превращает сложный HTML-документ в сложное дерево объектов Python. Однако вам придется иметь дело только с четырьмя видами объектов: Tag , NavigableString , BeautifulSoup и Comment .
Объект Tag соответствует тегу XML или HTML в исходном документе:
У объекта Tag (далее «тег») много атрибутов и методов, и я расскажу о большинстве из них в разделах Навигация по дереву и Поиск по дереву. На данный момент наиболее важными особенностями тега являются его имя и атрибуты.
У каждого тега есть имя, доступное как .name :
Если вы измените имя тега, это изменение будет отражено в любой HTML- разметке, созданной Beautiful Soup:
Атрибуты¶
У тега может быть любое количество атрибутов. Тег id = «boldest»> имеет атрибут “id”, значение которого равно “boldest”. Вы можете получить доступ к атрибутам тега, обращаясь с тегом как со словарем:
Вы можете получить доступ к этому словарю напрямую как к .attrs :
Вы можете добавлять, удалять и изменять атрибуты тега. Опять же, это делается путем обращения с тегом как со словарем:
Многозначные атрибуты¶
В HTML 4 определено несколько атрибутов, которые могут иметь множество значений. В HTML 5 пара таких атрибутов удалена, но определено еще несколько. Самый распространённый из многозначных атрибутов — это class (т. е. тег может иметь более одного класса CSS). Среди прочих rel , rev , accept-charset , headers и accesskey . Beautiful Soup представляет значение(я) многозначного атрибута в виде списка:
Если атрибут выглядит так, будто он имеет более одного значения, но это не многозначный атрибут, определенный какой-либо версией HTML- стандарта, Beautiful Soup оставит атрибут как есть:
Когда вы преобразовываете тег обратно в строку, несколько значений атрибута объединяются:
Вы можете отключить объединение, передав multi_valued_attributes = None в качестве именованного аргумента в конструктор BeautifulSoup :
Вы можете использовать get_attribute_list , того чтобы получить значение в виде списка, независимо от того, является ли атрибут многозначным или нет:
Если вы разбираете документ как XML, многозначных атрибутов не будет:
Опять же, вы можете поменять настройку, используя аргумент multi_valued_attributes :
Вряд ли вам это пригодится, но если все-таки будет нужно, руководствуйтесь значениями по умолчанию. Они реализуют правила, описанные в спецификации HTML:
NavigableString ¶
Строка соответствует фрагменту текста в теге. Beautiful Soup использует класс NavigableString для хранения этих фрагментов текста:
NavigableString похожа на строку Unicode в Python, не считая того, что она также поддерживает некоторые функции, описанные в разделах Навигация по дереву и Поиск по дереву. Вы можете конвертировать NavigableString в строку Unicode с помощью unicode() :
Вы не можете редактировать строку непосредственно, но вы можете заменить одну строку другой, используя replace_with() :
NavigableString поддерживает большинство функций, описанных в разделах Навигация по дереву и Поиск по дереву, но не все. В частности, поскольку строка не может ничего содержать (в том смысле, в котором тег может содержать строку или другой тег), строки не поддерживают атрибуты .contents и .string или метод find() .
Если вы хотите использовать NavigableString вне Beautiful Soup, вам нужно вызвать метод unicode() , чтобы превратить ее в обычную для Python строку Unicode. Если вы этого не сделаете, ваша строка будет тащить за собой ссылку на все дерево разбора Beautiful Soup, даже когда вы закончите использовать Beautiful Soup. Это большой расход памяти.
BeautifulSoup ¶
Объект BeautifulSoup представляет разобранный документ как единое целое. В большинстве случаев вы можете рассматривать его как объект Tag . Это означает, что он поддерживает большинство методов, описанных в разделах Навигация по дереву и Поиск по дереву.
Вы также можете передать объект BeautifulSoup в один из методов, перечисленных в разделе Изменение дерева, по аналогии с передачей объекта Tag . Это позволяет вам делать такие вещи, как объединение двух разобранных документов:
Поскольку объект BeautifulSoup не соответствует действительному HTML- или XML-тегу, у него нет имени и атрибутов. Однако иногда бывает полезно взглянуть на .name объекта BeautifulSoup , поэтому ему было присвоено специальное «имя» .name “[document]”:
Комментарии и другие специфичные строки¶
Tag , NavigableString и BeautifulSoup охватывают почти все, с чем вы столкнётесь в файле HTML или XML, но осталось ещё немного. Пожалуй, единственное, о чем стоит волноваться, это комментарий:
Объект Comment — это просто особый тип NavigableString :
Но когда он появляется как часть HTML-документа, Comment отображается со специальным форматированием:
Beautiful Soup определяет классы для всего, что может появиться в XML-документе: CData , ProcessingInstruction , Declaration и Doctype . Как и Comment , эти классы являются подклассами NavigableString , которые добавляют что-то еще к строке. Вот пример, который заменяет комментарий блоком CDATA:
Навигация по дереву¶
Вернемся к HTML-документу с фрагментом из «Алисы в стране чудес»:
Я буду использовать его в качестве примера, чтобы показать, как перейти от одной части документа к другой.
Проход сверху вниз¶
Теги могут содержать строки и другие теги. Эти элементы являются дочерними ( children ) для тега. Beautiful Soup предоставляет множество различных атрибутов для навигации и перебора дочерних элементов.
Обратите внимание, что строки Beautiful Soup не поддерживают ни один из этих атрибутов, потому что строка не может иметь дочерних элементов.
Навигация с использованием имен тегов¶
Самый простой способ навигации по дереву разбора — это указать имя тега, который вам нужен. Если вы хотите получить тег , просто напишите soup.head :
Вы можете повторять этот трюк многократно, чтобы подробнее рассмотреть определенную часть дерева разбора. Следующий код извлекает первый тег внутри тега :
Использование имени тега в качестве атрибута даст вам только первый тег с таким именем:



