- Изучаем pandas. Урок 1. Введение в pandas и его установка
- Что такое pandas?
- Установка pandas
- Installation¶
- Python version support¶
- Installing pandas¶
- Installing with Anaconda¶
- Installing with Miniconda¶
- Installing from PyPI¶
- Installing with ActivePython¶
- Installing using your Linux distribution’s package manager.¶
- Python pandas установка windows
- What if Python already exists? Let’s check
- Downloading and Installing Pandas
- Windows
- Install Pandas using pip
- Install Pandas using Anaconda
- Linux
- Библиотека Pandas в Python
- Установка и начало работы с Pandas
- Структуры данных
- DataFrame
- Импорт данных из CSV
- Проверка данных
- 1. Получение статистической сводки записей
- 2. Сортировка записей
- 3. Нарезка записей
- 4. Фильтрация данных
- 5. Переименование столбца
- 6. Сбор данных
- а. merge()
- b. Группировка
- c. Конкатенация
- Создание DataFrame, переход Dict в Series
- Выбор столбца, добавление и удаление
- Заключение
Изучаем pandas. Урок 1. Введение в pandas и его установка
Это первый урок из цикла, посвященного библиотеке p andas. Данный цикл будет входить в большую группу обучающих материалов, тематику которых можно определить как “Машинное обучение и анализ данных”. pandas – это удобный и быстрый инструмент для работы с данными, обладающий большим функционалом.
Что такое pandas?
Если очень кратко, то pandas – это библиотека, которая предоставляет очень удобные с точки зрения использования инструменты для хранения данных и работе с ними. Если вы занимаетесь анализом данных или машинным обучением и при этом используете язык Python , то вы просто обязаны знать и уметь работать с pandas .
pandasвходи в группу проектов, спонсируемых numfocus . Numfocus – это организация, которая поддерживает различные проекты, связанные с научными вычислениями.
Официальный сайт pandas находится здесь . Стоит отметить, что документация по этому продукту очень хорошая . Если вы знаете английский язык, то для вас не будет большой проблемой разобраться с pandas .
Особенность pandas состоит в том, что эта библиотека очень быстрая, гибкая и выразительная. Это важно, т.к. она используется с языком Python , который не отличается высокой производительностью. pandas прекрасно подходит для работы с одномерными и двумерными таблицами данных, хорошо интегрирован с внешним миром – есть возможность работать с файлами CSV , таблицами Excel , может стыковаться с языком R .
Установка pandas
Для проведения научных расчетов, анализа данных или построения моделей в рамках машинно обучения для языка Python существуют прекрасное решение – Anaconda . Anaconda – это пакет, который содержит в себе большой набор различных библиотек, интерпретатор языка Python и несколько сред для разработки. Подробно об установке пакета Anaconda написано в этой статье .
pandas присутствует в стандартной поставке Anaconda . Если же его там нет, то его можно установить отдельно. Для этого стоит воспользоваться пакетным менеджером, который входит в состав Anaconda , который называется conda . Для его запуска необходимо перейти в каталог [Anaconda install path]\Scripts\ в Windows . В операционной системе Linux , после установки Anaconda менеджер conda должен быть доступен везде.
Введите командной строке:
В случае, если требуется конкретная версия pandas , то ее можно указать при установке.
При необходимости, можно воспользоваться пакетным менеджером pip , входящим в состав дистрибутива Python .
Если вы используете Linux , то ещё одни способ установить pandas – это воспользоваться пакетным менеджером самой операционной системы. Для Ubuntu это выглядит так:
После установки необходимо проверить, что pandas установлен и корректно работает. Для этого запустите интерпретатор Python и введите в нем следующие команды.
В результате в окне терминала должен появиться следующий текст:
Это будет означать, что pandas установлен и его можно использовать.
Installation¶
The easiest way to install pandas is to install it as part of the Anaconda distribution, a cross platform distribution for data analysis and scientific computing. This is the recommended installation method for most users.
Instructions for installing from source, PyPI, ActivePython, various Linux distributions, or a development version are also provided.
Python version support¶
Officially Python 3.7.1 and above, 3.8, and 3.9.
Installing pandas¶
Installing with Anaconda¶
Installing pandas and the rest of the NumPy and SciPy stack can be a little difficult for inexperienced users.
The simplest way to install not only pandas, but Python and the most popular packages that make up the SciPy stack (IPython, NumPy, Matplotlib, …) is with Anaconda, a cross-platform (Linux, macOS, Windows) Python distribution for data analytics and scientific computing.
After running the installer, the user will have access to pandas and the rest of the SciPy stack without needing to install anything else, and without needing to wait for any software to be compiled.
Installation instructions for Anaconda can be found here.
A full list of the packages available as part of the Anaconda distribution can be found here.
Another advantage to installing Anaconda is that you don’t need admin rights to install it. Anaconda can install in the user’s home directory, which makes it trivial to delete Anaconda if you decide (just delete that folder).
Installing with Miniconda¶
The previous section outlined how to get pandas installed as part of the Anaconda distribution. However this approach means you will install well over one hundred packages and involves downloading the installer which is a few hundred megabytes in size.
If you want to have more control on which packages, or have a limited internet bandwidth, then installing pandas with Miniconda may be a better solution.
Conda is the package manager that the Anaconda distribution is built upon. It is a package manager that is both cross-platform and language agnostic (it can play a similar role to a pip and virtualenv combination).
Miniconda allows you to create a minimal self contained Python installation, and then use the Conda command to install additional packages.
First you will need Conda to be installed and downloading and running the Miniconda will do this for you. The installer can be found here
The next step is to create a new conda environment. A conda environment is like a virtualenv that allows you to specify a specific version of Python and set of libraries. Run the following commands from a terminal window:
This will create a minimal environment with only Python installed in it. To put your self inside this environment run:
On Windows the command is:
The final step required is to install pandas. This can be done with the following command:
To install a specific pandas version:
To install other packages, IPython for example:
To install the full Anaconda distribution:
If you need packages that are available to pip but not conda, then install pip, and then use pip to install those packages:
Installing from PyPI¶
pandas can be installed via pip from PyPI.
Installing with ActivePython¶
Installation instructions for ActivePython can be found here. Versions 2.7, 3.5 and 3.6 include pandas.
Installing using your Linux distribution’s package manager.¶
The commands in this table will install pandas for Python 3 from your distribution.
Python pandas установка windows
Pandas in Python is a package that is written for data analysis and manipulation. Pandas offer various operations and data structures to perform numerical data manipulations and time series. Pandas is an open-source library that is built over Numpy libraries. Pandas library is known for its high productivity and high performance. Pandas is popular because it makes importing and analyzing data much easier.
Pandas programs can be written on any plain text editor like notepad, notepad++, or anything of that sort and saved with a .py extension. To begin with, writing Pandas Codes and performing various intriguing and useful operations, one must have Python installed on their System. This can be done by following the step by step instructions provided below:
What if Python already exists? Let’s check
To check if your device is pre-installed with Python or not, just go to the Command line(search for cmd in the Run dialog( + R).
Now run the following command:
If Python is already installed, it will generate a message with the Python version available.
To install Python, please visit: How to Install Python on Windows or Linux?
Downloading and Installing Pandas
Pandas can be installed in multiple ways on Windows and on Linux. Various different ways are listed below:
Windows
Python Pandas can be installed on Windows in two ways:
- Using pip
- Using Anaconda
Install Pandas using pip
PIP is a package management system used to install and manage software packages/libraries written in Python. These files are stored in a large “on-line repository” termed as Python Package Index (PyPI).
Pandas can be installed using PIP by the use of the following command:
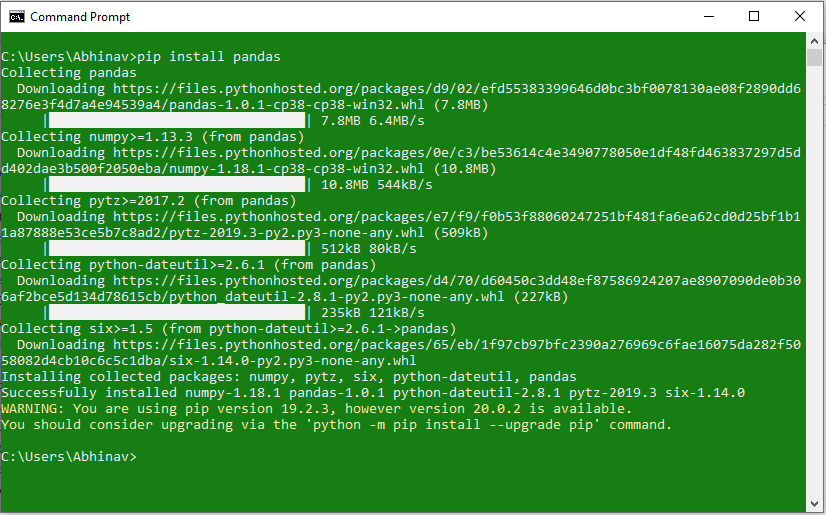
Install Pandas using Anaconda
Anaconda is open-source software that contains Jupyter, spyder, etc that are used for large data processing, data analytics, heavy scientific computing. If your system is not pre-equipped with Anaconda Navigator, you can learn how to install Anaconda Navigator on Windows or Linux?
Steps to Install Pandas using Anaconda Navigator:
Step 1: Search for Anaconda Navigator in Start Menu and open it.
Step 2: Click on the Environment tab and then click on the create button to create a new Pandas Environment.
Step 3: Give a name to your Environment, e.g. Pandas and then choose a python version to run in the environment. Now click on the Create button to create Pandas Environment.
Step 4: Now click on the Pandas Environment created to activate it.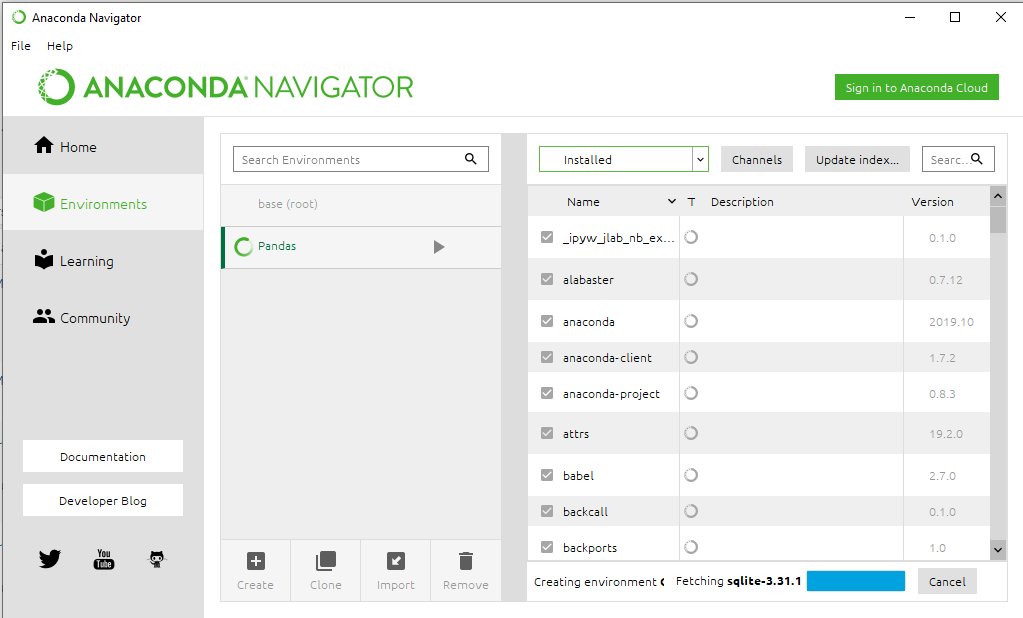
Step 5: In the list above package names, select All to filter all the packages.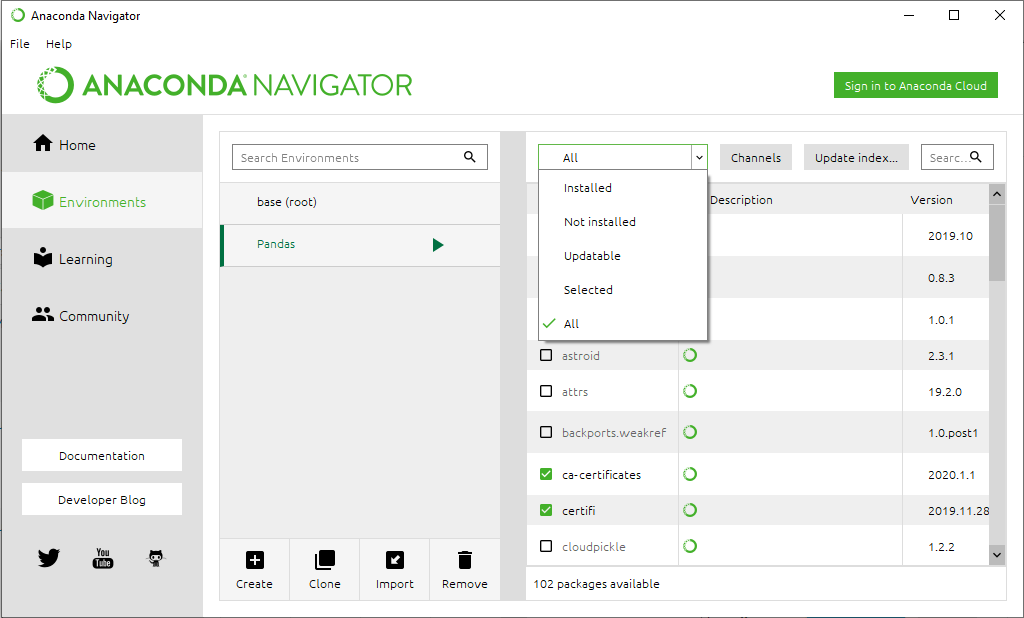
Step 6: Now in the Search Bar, look for ‘Pandas‘. Select the Pandas package for Installation.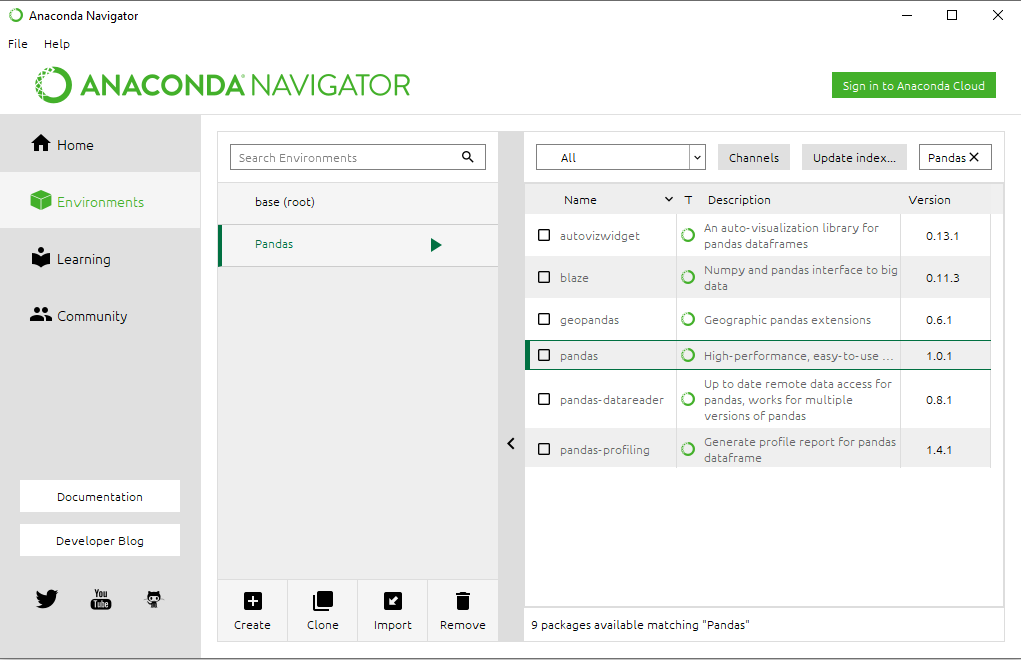
Step 7: Now Right Click on the checkbox given before the name of the package and then go to ‘Mark for specific version installation‘. Now select the version that you want to install.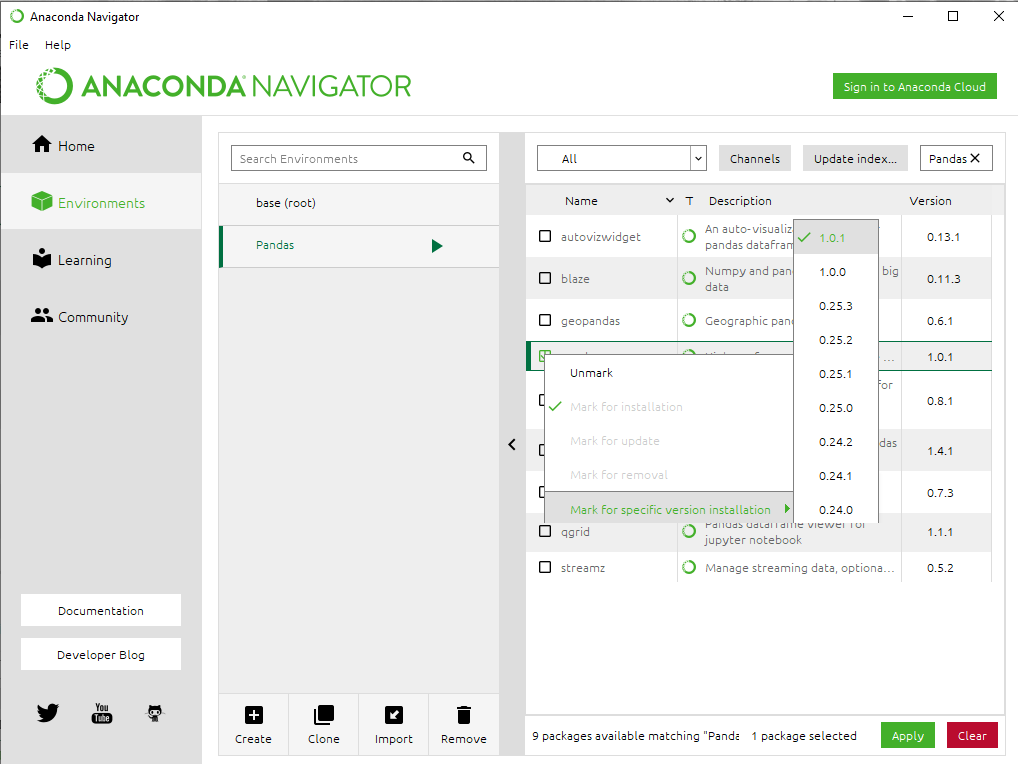
Step 8: Click on the Apply button to install the Pandas Package.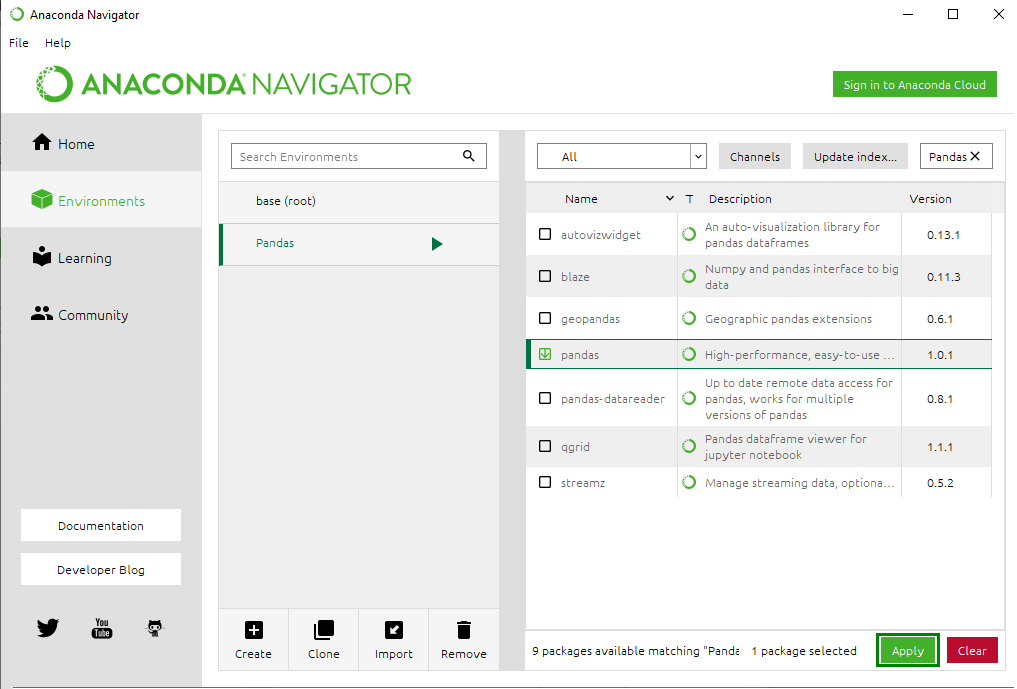
Step 9: Finish the Installation process by clicking on the Apply button.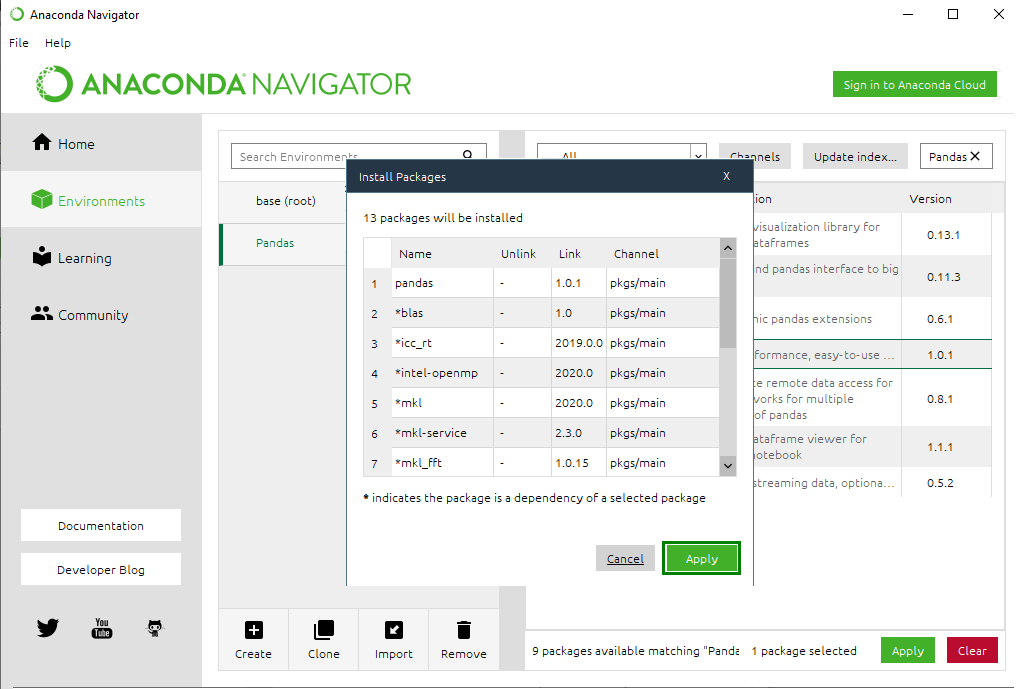
Step 10: Now to open the Pandas Environment, click on the Green Arrow on the right of package name and select the Console with which you want to begin your Pandas programming.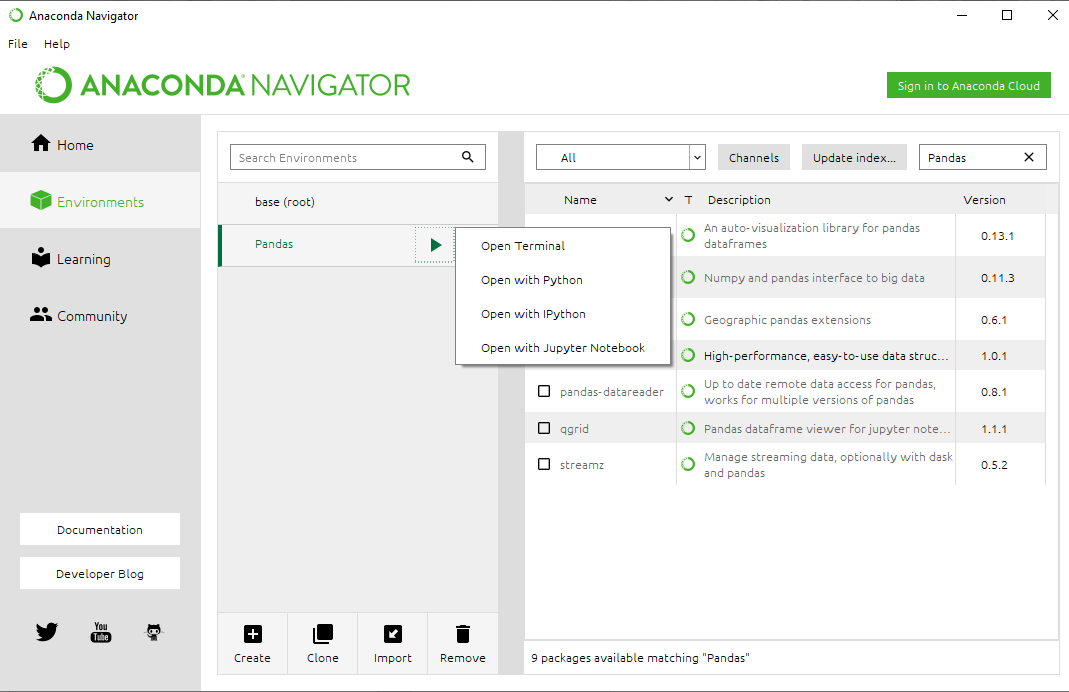
Pandas Terminal Window:
Linux
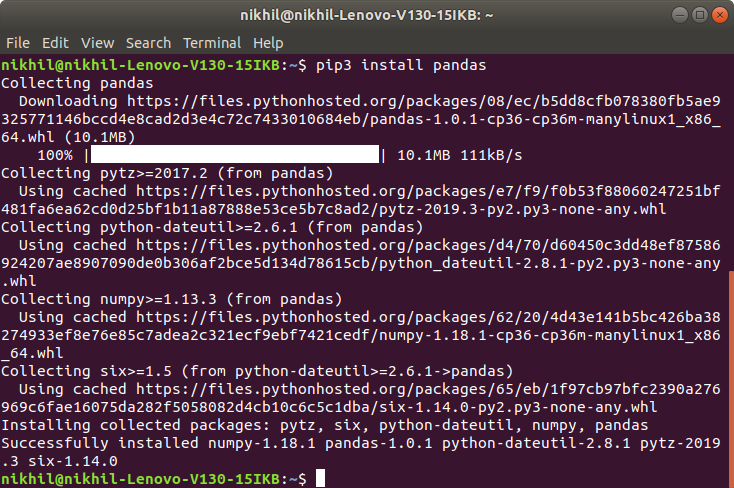
To install Pandas on Linux, just type the following command in the Terminal Window and press Enter. Linux will automatically download and install the packages and files required to run Pandas Environment in Python:
Attention geek! Strengthen your foundations with the Python Programming Foundation Course and learn the basics.
To begin with, your interview preparations Enhance your Data Structures concepts with the Python DS Course.
Библиотека Pandas в Python
Pandas – это библиотека с открытым исходным кодом на Python. Она предоставляет готовые к использованию высокопроизводительные структуры данных и инструменты анализа данных.
- Модуль Pandas работает поверх NumPy и широко используется для обработки и анализа данных.
- NumPy – это низкоуровневая структура данных, которая поддерживает многомерные массивы и широкий спектр математических операций с массивами. Pandas имеет интерфейс более высокого уровня. Он также обеспечивает оптимизированное согласование табличных данных и мощную функциональность временных рядов.
- DataFrame – это ключевая структура данных в Pandas. Это позволяет нам хранить и обрабатывать табличные данные, как двумерную структуру данных.
- Pandas предоставляет богатый набор функций для DataFrame. Например, выравнивание данных, статистика данных, нарезка, группировка, объединение, объединение данных и т.д.
Установка и начало работы с Pandas
Для установки модуля Pandas вам потребуется Python 2.7 и выше.
Если вы используете conda, вы можете установить его, используя команду ниже.
Если вы используете PIP, выполните команду ниже, чтобы установить модуль pandas.

Чтобы импортировать Pandas и NumPy в свой скрипт Python, добавьте следующий фрагмент кода:
Поскольку Pandas зависит от библиотеки NumPy, нам нужно импортировать эту зависимость.
Структуры данных
Модуль Pandas предоставляет 3 структуры данных, а именно:
- Series: это одномерный массив неизменного размера, подобный структуре, имеющей однородные данные.
- DataFrames: это двумерная табличная структура с изменяемым размером и неоднородно типизированными столбцами.
- Panel: это трехмерный массив с изменяемым размером.
DataFrame
DataFrame – самая важная и широко используемая структура данных, а также стандартный способ хранения данных. Она содержит данные, выровненные по строкам и столбцам, как в таблице SQL или в базе данных электронной таблицы.
Мы можем либо жестко закодировать данные в DataFrame, либо импортировать файл CSV, файл tsv, файл Excel, таблицу SQL и т.д.
Мы можем использовать приведенный ниже конструктор для создания объекта DataFrame.
Ниже приводится краткое описание параметров:
- data – создать объект DataFrame из входных данных. Это может быть список, dict, series, Numpy ndarrays или даже любой другой DataFrame;
- index – имеет метки строк;
- columns – используются для создания подписей столбцов;
- dtype – используется для указания типа данных каждого столбца, необязательный параметр;
- copy – используется для копирования данных, если есть.
Есть много способов создать DataFrame. Мы можем создать объект из словарей или списка словарей. Мы также можем создать его из списка кортежей, CSV, файла Excel и т.д.
Давайте запустим простой код для создания DataFrame из списка словарей.

Первый шаг – создать словарь. Второй шаг – передать словарь в качестве аргумента в метод DataFrame(). Последний шаг – распечатать DataFrame.
Как видите, DataFrame можно сравнить с таблицей, имеющей неоднородное значение. Кроме того, можно изменить размер.
Мы предоставили данные в виде карты, и ключи карты рассматриваются Pandas, как метки строк.
Индекс отображается в крайнем левом столбце и имеет метки строк. Заголовок столбца и данные отображаются в виде таблицы.
Также возможно создавать индексированные DataFrames. Это можно сделать, настроив параметр индекса.
Импорт данных из CSV
Мы также можем создать DataFrame, импортировав файл CSV. Файл CSV – это текстовый файл с одной записью данных в каждой строке. Значения в записи разделяются символом «запятая».
Pandas предоставляет полезный метод с именем read_csv() для чтения содержимого файла CSV.
Например, мы можем создать файл с именем «cities.csv», содержащий подробную информацию о городах Индии. Файл CSV хранится в том же каталоге, что и сценарии Python. Этот файл можно импортировать с помощью:
Наша цель – загрузить данные и проанализировать их, чтобы сделать выводы. Итак, мы можем использовать любой удобный способ загрузки данных.
Проверка данных


Точно так же print (df.dtypes) печатает типы данных.

print (df.index) печатает index.

print (df.columns) печатает столбцы DataFrame.

print (df.values) отображает значения таблицы.

1. Получение статистической сводки записей

Функция df.describe() отображает статистическую сводку вместе с типом данных.
2. Сортировка записей

3. Нарезка записей



Интересной особенностью библиотеки Pandas является выбор данных на основе меток строк и столбцов с помощью функции iloc [0].
Часто для анализа может потребоваться всего несколько столбцов. Мы также можем выбрать по индексу, используя loc [‘index_one’]).
Например, чтобы выбрать вторую строку, мы можем использовать df.iloc [1 ,:].
Допустим, нам нужно выбрать второй элемент второго столбца. Это можно сделать с помощью функции df.iloc [1,1]. В этом примере функция df.iloc [1,1] отображает в качестве вывода «Мумбаи».
4. Фильтрация данных
Для фильтрации по условию можно использовать любой оператор сравнения.


5. Переименование столбца
Аргумент inplace = True вносит изменения в DataFrame.

6. Сбор данных
Наука о данных включает в себя обработку данных, чтобы данные могли хорошо работать с алгоритмами данных. Data Wrangling – это процесс обработки данных, такой как слияние, группировка и конкатенация.
Библиотека Pandas предоставляет полезные функции, такие как merge(), groupby() и concat() для поддержки задач Data Wrangling.


а. merge()

Мы видим, что функция merge() возвращает строки из обоих DataFrames, имеющих то же значение столбца, которое использовалось при слиянии.
b. Группировка
Поле «Employee_name» со значением «Meera» сгруппировано по столбцу «Employee_name». Пример вывода приведен ниже:

c. Конкатенация

Создание DataFrame, переход Dict в Series

Мы создали серию. Вы можете видеть, что отображаются 2 столбца. Первый столбец содержит значения индекса, начиная с 0. Второй столбец содержит элементы, переданные как серии.
Можно создать DataFrame, передав словарь Series. Давайте создадим DataFrame, который формируется путем объединения и передачи индексов ряда.

Для первой серии, поскольку мы не указали метку ‘d’, возвращается NaN.
Выбор столбца, добавление и удаление
Приведенный выше код печатает только столбец «Matches played» в DataFrame.



Заключение
В этом руководстве у нас было краткое введение в библиотеку Pandas в Python. Мы также сделали практические примеры, чтобы раскрыть возможности библиотеки, используемой в области науки о данных. Мы также рассмотрели различные структуры данных в библиотеке Python.



