- Распознавание номеров. Практическое пособие. Часть 1
- Кто еще распознает
- Automatic License Plate Recognition
- Recognitor
- Какие инструменты нужны для распознавания номеров
- Nomeroff Net
- Что нам понадобится
- Nomeroff Net «Hello world»
- Онлайн демка
- Что дальше
- Известные проблемы
- Анонс
- Русские Блоги
- Распознавание автомобильных номеров на базе opencv-python
- Запись практических занятий по курсу цифровых изображений
- Базовый процесс реализации:
- Часть GUI
- Распознаем номера автомобилей. Разработка multihead-модели в Catalyst
- Общий подход к решению задачи
- Кодирование
- Результаты эксперимента
- Заключение
Распознавание номеров. Практическое пособие. Часть 1

Все начиналось банально — моя компания уже год платила ежемесячно плату за сервис, который умел находить регион с номерными знаками на фото. Эта функция применяется для автоматической зарисовки номера у некоторых клиентов.
И в один прекрасный день МВД Украины открыло доступ к реестру транспортных средств. Теперь по номерному знаку стало возможным проверять некоторую информацию про автомобиль (марку, модель, год выпуска, цвет и т.д. )! Скучная рутина линейного программирования померкла перед новой свехзадачей — считывать номера по всей базе фото и валидировать эти данные с теми, что указывал пользователь. Сами знаете как это бывает «глаза загорелись» — вызов принят, все остальные задачи на время стали скучны и монотонны… Мы принялись за работу и получили неплохие результаты, чем, собственно и решили поделиться с сообществом.
Для справки: на сайт AUTO.RIA.com, в день добавляется около 100 000 фото.
Кто еще распознает
Год назад я изучил этот рынок и оказалось, что работать с номерами стран exUSSR умеет не так уж много сервисов и ПО. Ниже представлен список компаний с которыми мы работали:
Automatic License Plate Recognition
Recognitor
Этим сервисом мы пользовались около года. Качество хорошее. Зону с номером находит очень хорошо. Сервис не умеет работать с украинскими и европейскими номерами. Стоит отметить хорошую работу с некачественными снимками (в снегу, фото небольшого разрешения, . ). Цена на сервис тоже приемлемая, но за малые объемы берутся неохотно.
Есть множество коммерческих систем с закрытым ПО, но хорошей opensource реализации мы не нашли. На самом деле это очень странно, так как инструменты с открытым кодом, которые лежат в основе решения этой задачи давно уже существуют.
Какие инструменты нужны для распознавания номеров
Нахождение объектов на изображении или в видео-потоке это задача из области компьютерного зрения, которая решается разными подходами, но чаще всего с помощью, так-называемых, сверточных нейронных сетей. Нам нужно найти не просто область на фото в которой встречается искомый объект, но и отделить все его точки от других объектов или фона. Эта разновидность задач называется «Instance Segmentation». На иллюстрации ниже визуализированы разные типы задач компьютерного зрения.
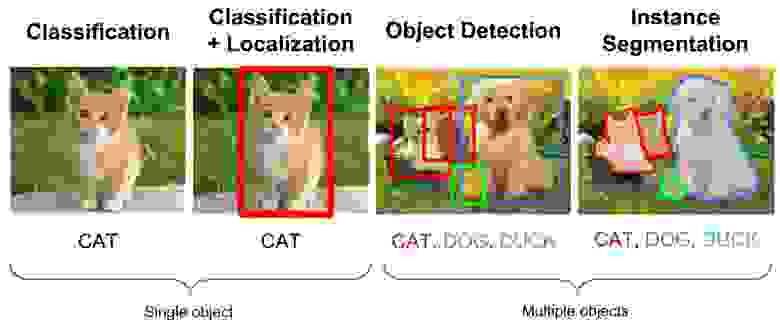
Я не буду сейчас писать много теории о том как работает сверточная сеть, этой информации достаточно в сети и докладов на youtube.
Из современных архитектур сверточных серей для задач сегментации часто используют: U-Net или Mask R-CNN. Мы выбрали Mask R-CNN.
Второй инструмент, который нам понадобится — это библиотека по распознаванию текстов, которая бы могла работать с разными языками и которую можно легко настраивать под специфику текстов, которые мы будем распознавать. Тут выбор не так уж велик, самой продвинутой является tesseract от Google.
Так же есть ряд менее «глобальных» инструментов, с помощью которых нам нужно будет нормализовать область с номерным знаком (привести его в такой вид, при котором распознавание текста будет возможным). Обычно для таких преобразований используют opencv.
Так же, можно будет попробовать определить страну и тип, к которой относится найденный номерной знак, чтоб в постобработке применить уточняющий шаблон, характерный для этой страны и этого типа номера. Например, украинский номерной знак, начиная с 2015 года оформлен в сине-желтом оформлении состоит из шаблона «две буквы черыре цифры две буквы».
Кроме того, имея статистику частоты «встречания» в номерных знаках того или иного сочетания букв или цифр можно улучшить качество постобработки в «спорных» ситуациях. «
Nomeroff Net
Все материалы для нашего проекта: размеченные датасеты и натренированные модели, мы выложили в открытый доступ с разрешения RIA.com под лицензией Creative Commons CC BY 4.0
Что нам понадобится
- Python3
- opencv-python не ниже версии 3.4
- свежие Mask RCNN, tesseract
- через менеджер пакетов pip3 нужно будет установить несколько модулей на python3, они будут перечислены в отдельном файле requirements.txt
У нас с Дмитрием все запущено на Fedora 28, уверен это все можно установить на любой другой дистрибутив Linux. Не хотелось бы этот пост превращать в инструкцию по установке и настройке tensorflow, если захотите попробовать и что-то не получается — спрашивайте в комментах, я обязательно отвечу и подскажу.
Для того, чтобы ускорить установку планируем создать dockerfile — ожидайте в ближайших апдейтах проекта.
Nomeroff Net «Hello world»
Давайте уже что-то попробуем распознать. Клонируем с github-а репозиторий с кодом. Качаем в папку models, натренированные модели для поиска и классификации номеров, немного подправим под себя переменные с расположением папок.
UPD: Этот код является устаревшим, он будет работать только в ветке 0.1.0, свежие примеры смотрите здесь:
Все, можно распознавать:
Онлайн демка
Набросали простенькую демку для тех кому не хочется все это ставить и запускать у себя :). Будьте снисходительны и терпеливы к скорости работы скрипта.
Если нужны примеры украинских номеров (для проверки работы алгоритмов коррекции), возьмите пример из этой папки.
Что дальше
Я понимаю, что тема очень нишевая и вряд ли вызовет большой интерес у широкого круга программистов, кроме того, код и модели еще достаточно «сыроваты» в плане качества распознавания, быстродействия, потребления памяти и пр. Но все же есть надежда, что найдутся энтузиасты, которым будет интересно натренировать модели под свои нужды, свою страну, которые помогут и подскажут, где есть проблемы и вместе с нами сделают проект не хуже, чем коммерческие аналоги.
Известные проблемы
Анонс
Если это будет кому-то интересно, во второй части собираемся рассказать о том как и чем размечать свой датасет и как тренировать свои модели, которые могут работать лучше для вашего контента (вашей страны, вашего размера фото). Также поговорим о том как создать свой классификатор, который, например, поможет определять не зарисован ли номер на фото.
Источник
Русские Блоги
Распознавание автомобильных номеров на базе opencv-python
Запись практических занятий по курсу цифровых изображений
на основе opencv-python Код распознавания автомобильных номеров в основном относится к коду нескольких модераторов на CSDN, и этот код был в определенной степени оптимизирован, что в определенной степени повышает точность распознавания. И переписать интерфейс GUI, добавить функцию экспорта данных.
Базовый процесс реализации:
Прочитать изображение
использовать cv2.imdecode() Функция преобразует файл изображения в данные потока и назначает его в кэш памяти для последующих операций с изображениями. использовать cv2.resize() Функция масштабирует считываемое изображение, чтобы изображение не было слишком большим и время распознавания не было слишком большим.
Подавление шума
использовать cv2.GaussianBlur() Выполните гауссовское шумоподавление. использовать cv2.morphologyEx() Функция для открытия операции, а затем использовать cv2.addWeighted() Функция объединяет результат операции с исходным изображением для удаления отдельных мелких точек, глюков и прочего шума.


3. Бинаризация
использовать cv2.threshold() Функция преобразуется в двоичную форму, а затем используется cv2.Canny() Функция находит край каждой области.

Соединяем края изображения целиком
использовать cv2.morphologyEx() с участием cv2.morphologyEx() Эти две функции выполняют операцию открытия (сначала операция коррозии, затем операция расширения) и операцию закрытия (сначала операция расширения, затем операция коррозии) для удаления меньших участков, заполнения небольших отверстий и закрытия небольших трещин. Выделите положение номерного знака.

Найдите номерной знак (прямоугольная область)
Найдите прямоугольную область, образованную краем изображения в целом, их может быть много, номерной знак находится в одной из прямоугольных областей, а прямоугольные области, которые не являются номерными знаками, исключаются один за другим. Прямоугольная область, образованная номерным знаком, имеет соотношение сторон от 2 до 5,5, поэтому используйте cv2.minAreaRect() Функциональное окно выбирает прямоугольную область для расчета соотношения сторон.Соотношение сторон от 2 до 5,5 может быть номерным знаком, а остальные прямоугольники исключаются. Наконец использовал cv2.drawContours() Функция выбирает область, которая может быть номерным знаком на исходном изображении. (Результатом обработки здесь может быть несколько прямоугольников, которые соответствуют требованиям, но положение номерного знака не может быть получено напрямую, поэтому требуется последующая обработка.)
Графическая коррекция
Прямоугольная область может быть наклонным прямоугольником, и ее необходимо исправить, чтобы использовать цветовое позиционирование для дальнейшего подтверждения того, является ли это номерным знаком. Подобно следующим двум рисункам (указаны только два, их может быть много).


Распознавание цвета
Используйте цветовое позиционирование, чтобы исключить прямоугольники, не являющиеся номерными знаками. В настоящее время только номерные знаки имеют цвета в основном синий, зеленый и желтый. По цвету прямоугольника выбирается прямоугольник, который, скорее всего, является номерным знаком. При этом подбирается тип (цветотип) номерного знака. Используемые параметры: * cv2.COLOR_BGR2HSV * из cv2.cvtColor() Функция преобразует исходное изображение RGB в изображение HSV, чтобы определить цвет.
На основе цветовой модели HSV видно, что диапазон значений оттенка H составляет от 0 ° до 360 °, начиная с красного и считая против часовой стрелки, красный — 0 °, зеленый — 120 °, синий — 240 °. Их дополнительные цвета: желтый — 60 °, голубой — 180 °, пурпурный — 300 °; обратитесь к соответствующей информации, чтобы определить следующую таблицу:
| желтый | зеленый | синий | |
|---|---|---|---|
| H | 14-34 | 34-99 | 99-124 |
Вычислите заполнение каждого цвета в каждом прямоугольнике согласно приведенной выше таблице и сравните заполнение трех цветов каждого прямоугольника, чтобы определить прямоугольник, который, скорее всего, будет цветом номерного знака, и цветом номерного знака.


Частичная бинаризация номерного знака
Параметр использования: * cv2.COLOR_BGR2GRAY * из cv2.cvtColor() Функция преобразует RGB-изображение обнаруженной части номерного знака в серое изображение, а затем использует его. cv2. threshold() Функция преобразует изображение в градациях серого в двоичную форму. Следует отметить, что символы желтого и зеленого номерных знаков темнее фона и являются полной противоположностью синего номерного знака, поэтому желтые и зеленые номерные знаки необходимо использовать до бинаризации. cv2.bitwise_not( ) Функция обратная.
Сегментация персонажей (метод проекции)
В соответствии с установленным порогом и гистограммой изображения найдите гребни и используйте найденные гребни для разделения изображений. Поскольку знак «•» на номерном знаке также создает набор гребней, удалите третий из восьми наборов гребней, чтобы получить гребни каждого символа, а затем разделите изображение номерного знака в соответствии с шириной каждого набора гребней, чтобы получить изображение каждого символа. образ. 

Шаблон соответствия
Сопоставьте каждое сегментированное изображение с обученным шаблоном одно за другим, чтобы получить результат распознавания. 
Часть GUI

- открыть файл
- Дисплей интерфейса
- Обнаружение зависимых файлов
Компьютер снова отключился, поэтому сначала запомните это, а затем заполните остальное .
Источник
Распознаем номера автомобилей. Разработка multihead-модели в Catalyst
Фиксация различных нарушений, контроль доступа, розыск и отслеживание автомобилей – лишь часть задач, для которых требуется по фотографии определить номер автомобиля (государственный регистрационный знак или ГРЗ).
В этой статье мы рассмотрим создание модели для распознавания с помощью Catalyst – одного из самых популярных высокоуровневых фреймворков для Pytorch. Он позволяет избавиться от большого количества повторяющегося из проекта в проект кода – цикла обучения, расчёта метрик, создания чек-поинтов моделей и другого – и сосредоточиться непосредственно на эксперименте.
Сделать модель для распознавания можно с помощью разных подходов, например, путем поиска и определения отдельных символов, или в виде задачи image-to-text. Мы рассмотрим модель с несколькими выходами (multihead-модель). В качестве датасета возьмём датасет с российскими номерами от проекта Nomeroff Net. Примеры изображений из датасета представлены на рис. 1.
Рис. 1. Примеры изображений из датасета
Общий подход к решению задачи
Необходимо разработать модель, которая на входе будет принимать изображение ГРЗ, а на выходе отдавать строку распознанных символов. Модель будет состоять из экстрактора фичей и нескольких классификационных “голов”. В датасете представлены ГРЗ из 8 и 9 символов, поэтому голов будет девять. Каждая голова будет предсказывать один символ из алфавита “1234567890ABEKMHOPCTYX”, плюс специальный символ “-” (дефис) для обозначения отсутствия девятого символа в восьмизначных ГРЗ. Архитектура схематично представлена на рис. 2.
Рис. 2. Архитектура модели
В качестве loss-функции возьмём стандартную кросс-энтропию. Будем применять её к каждой голове в отдельности, а затем просуммируем полученные значения для получения общего лосса модели. Оптимизатор – Adam. Используем также OneCycleLRWithWarmup как планировщик leraning rate. Размер батча – 128. Длительность обучения установим в 10 эпох.
В качестве предобработки входных изображений будем выполнять нормализацию и преобразование к единому размеру.
Кодирование
Далее рассмотрим основные моменты кода. Класс датасета (листинг 1) в общем обычный для CV-задач на Pytorch. Обратить внимание стоит лишь на то, как мы возвращаем список кодов символов в качестве таргета. В параметре label_encoder передаётся служебный класс, который умеет преобразовывать символы алфавита в их коды и обратно.
Листинг 1. Класс датасета
В классе модели (листинг 2) мы используем библиотеку PyTorch Image Models для создания экстрактора фичей. Каждую из классификационных голов модели мы добавляем в ModuleList, чтобы их параметры были доступны оптимизатору. Логиты с выхода каждой из голов возвращаются списком.
Листинг 2. Класс модели
Центральным звеном, связывающим все компоненты и обеспечивающим обучение модели, является Runner. Он представляет абстракцию над циклом обучения-валидации модели и отдельными его компонентами. В случае обучения multihead-модели нас будет интересовать реализация метода handle_batch и набор колбэков.
Метод handle_batch, как следует из названия, отвечает за обработку батча данных. Мы в нём будем только вызывать модель с данными батча, а обработку полученных результатов – расчёт лосса, метрик и т.д. – мы реализуем с помощью колбэков. Код метода представлен в листинге 3.
Листинг 3. Реализация runner’а
Колбэки мы будем использовать следующие:
CriterionCallback – для расчёта лосса. Нам потребуется по отдельному экземпляру для каждой из голов модели.
MetricAggregationCallback – для агрегации лоссов отдельных голов в единый лосс модели.
OptimizerCallback – чтобы запускать оптимизатор и обновлять веса модели.
SchedulerCallback – для запуска LR Scheduler’а.
AccuracyCallback – чтобы иметь представление о точности классификации каждой из голов в ходе обучения модели.
CheckpointCallback – чтобы сохранять лучшие веса модели.
Код, формирующий список колбэков, представлен в листинге 4.
Листинг 4. Код получения колбэков
Остальные части кода являются тривиальными для Pytorch и Catalyst, поэтому мы не станем приводить их здесь. Полный код к статье доступен на GitHub.
Результаты эксперимента
Рис. 3. График лосс-функции модели в процессе обучения. Оранжевая линия – train loss, синяя – valid loss
В списке ниже перечислены некоторые ошибки, которые модель допустила на тест-сете:
Incorrect prediction: T970XT23- instead of T970XO123
Incorrect prediction: X399KT161 instead of X359KT163
Incorrect prediction: E166EP133 instead of E166EP123
Incorrect prediction: X225YY96- instead of X222BY96-
Incorrect prediction: X125KX11- instead of X125KX14-
Incorrect prediction: X365PC17- instead of X365PC178
Здесь присутствуют все возможные типы: некорректно распознанные буквы и цифры основной части ГРЗ, некорректно распознанные цифры кода региона, лишняя цифра в коде региона, а также неверно предсказанное отсутствие последней цифры.
Заключение
В статье мы рассмотрели способ реализации multihead-модели для распознавания ГРЗ автомобилей с помощью фреймворка Catalyst. Основными компонентами явились собственно модель, а также раннер и набор колбэков для него. Модель успешно обучилась и показала высокую точность на тестовой выборке.
Спасибо за внимание! Надеемся, что наш опыт был вам полезен.
Больше наших статей по машинному обучению и обработке изображений:
Источник



