- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Регулярные выражения в Linux
- Первая команда — grep
- egrep (Extended grep)
- Про fgrep
- Рекурсивный rgrep
- Команда sed
- Использование Grep и регулярных выражений для поиска текстовых шаблонов в Linux
- Вступление
- Основы использования
- Общие опции
- Регулярные выражения
- Буквенные совпадения
- Совпадения анкоров
- Совпадение любого символа
- Выражения в скобках
- Шаблон повторения (0 или больше раз)
- Как избежать метасимволов
- Расширенные регулярные выражения
- Группирование
- Чередование
- Кванторы
- Количество повторений совпадений
- Выводы
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Регулярные выражения в Linux
На регулярной основе
Интересным вопросом в Linux системах, является управление регулярными выражениями. Это полезный и необходимый навык не только профессионалам своего дела, системным администраторам, но, а также и обычным пользователям линуксоподобных операционных систем. В данной статье я постараюсь раскрыть, как создавать регулярные выражения и как их применять на практике в каких-либо целях. Основной областью применение регулярных выражений является поиск информации и файлов в линуксоподобных операционных системах.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Для работы в основном используются следующие символы:
- «\text» — слова начинающиеся с text
- «text/» — слова, заканчивающиеся на text
- «^» — начало строки
- «$» — конец строки
- «a-z» — диапазон от a до z
- «[^t]» — не буква t
- «\[« — воспринять символ [ буквально
- «.» — любой символ
- «a|z» — а или z
Регулярные выражения в основном используются со следующими командами:
grep — утилита поиска по выражению
- egrep — расширенный grep
- fgrep — быстрый grep
- rgrep — рекурсивный grep
- sed — потоковый текстовый редактор.
А особенно с утилитой grep. Данная утилита используется для сортировки результатов чего либо, передавая ей результаты по конвейеру. Эта утилита осуществляет поиск и передачу на стандартный вывод результат его. ЕЕ можно запускать с различными ключами, но можно использовать ее другие варианты, которые представлены выше.
И есть еще потоковый текстовый редактор. Это не полноценный текстовый редактор, он просто получает информацию построчно и обрабатывает. После чего выводит на стандартный вывод. Он не изменяет текстовый вывод или текстовый поток, он просто редактирует перед тем как вывести его для нас на экран.
Начнем со следующего. Создадим один пустой файл file1.txt, через команду touch. Создадим в текстовом редакторе в той же директории файл file.txt.
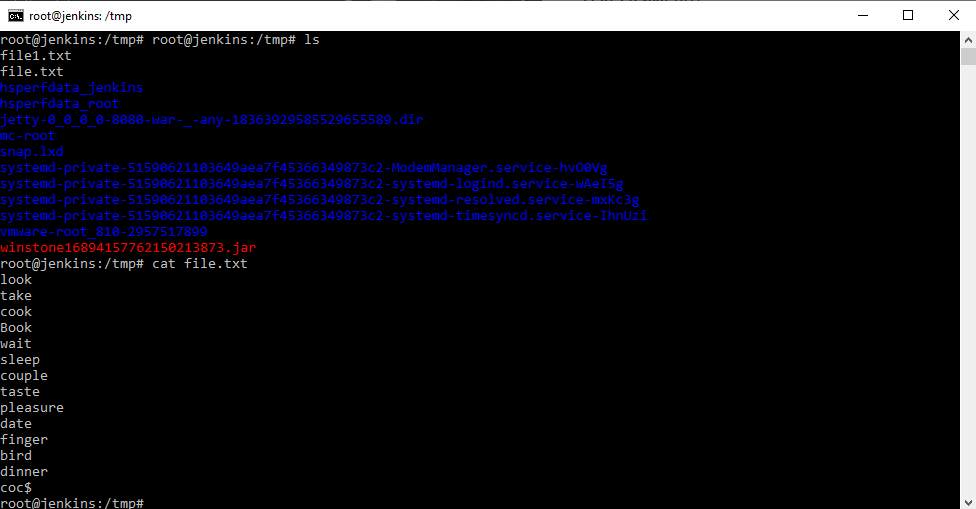
Как мы видим в файле file.txt просто набор слов. Далее мы с помощью данных слов посмотрим, как работают команды.
Первая команда — grep
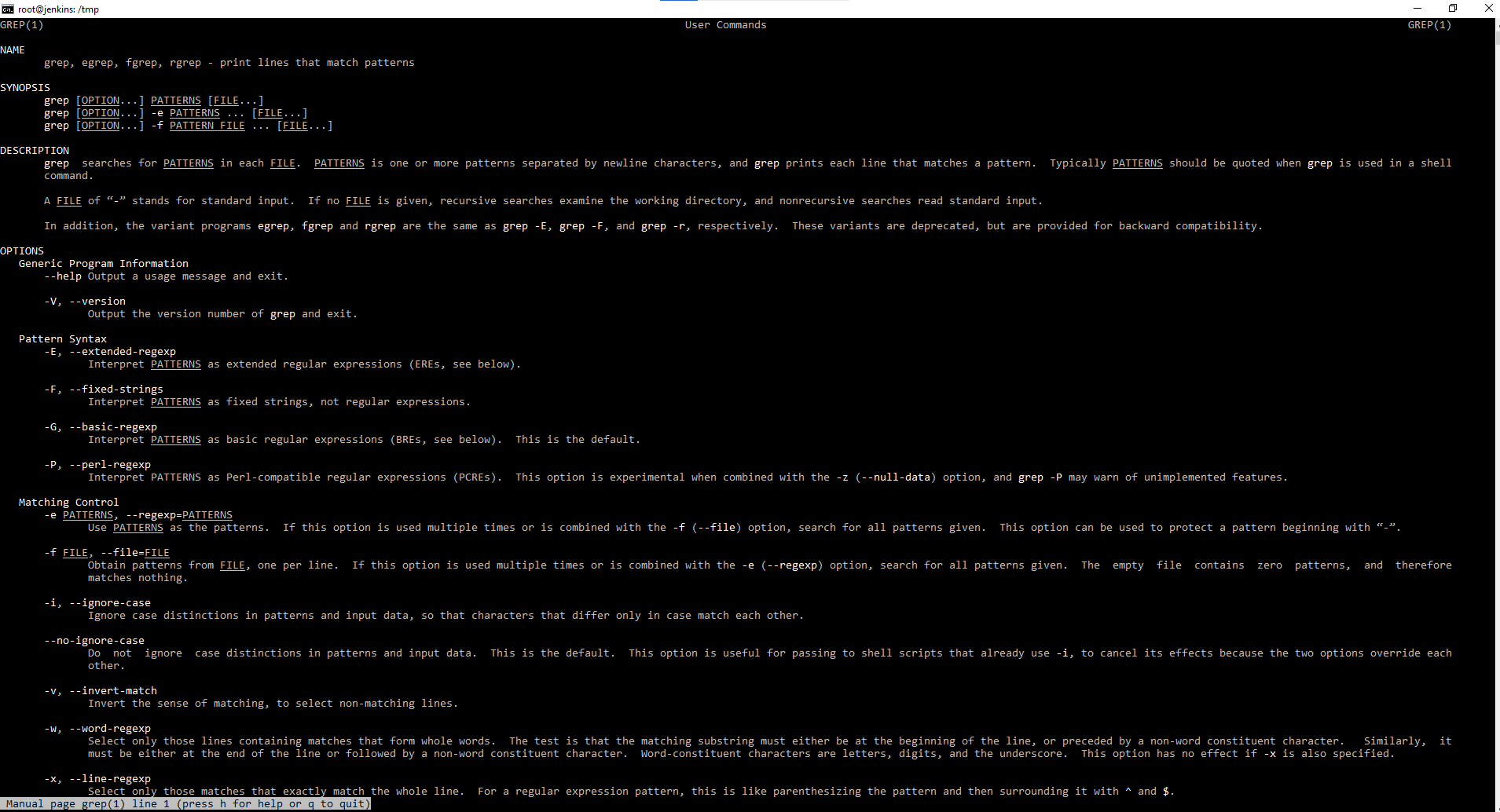
Получаем справку по данной команде. Как можно понять из справки команда grep и ее производные — это печать линий совпадающих шаблонов. Проще говоря, команда grep помогает сортировать те данные, что мы даем команде, через знак конвейера на ввод. Причем в мануале мы можем видеть egrep, fgrep и т.д. данные команды мы можем не использовать. Использовать можно только grep с ключами различными, т.е. ключи просто заменяют эти команды. Можно на примере посмотреть, как работает данная команда. Например, grep oo file.txt
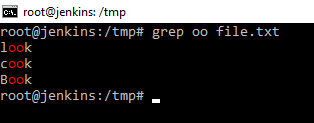
На картинке видно, что команда из указанного файла выбрала по определенному шаблону «oo». Причем даже делает красным цветом подсветку. Можно добавить еще ключик -n, тогда данная команда еще и выведет номер строки в которой находится то, что ищется по шаблону. Это полезно, когда работаем с каким-нибудь кодом или сценарием. Когда необходимо, что-то найти. Сразу видим, где находится объект поиска или что-то ищем по логам.
При использовании шаблона очень важно понимать, что команда grep, чувствительна к регистрам в шаблонах. Это означает, что Boo и boo это разные шаблоны. В одном случае команда найдет слово, а в другом нет. Можно команде сказать, чтобы она не учитывала регистр. Это делается с помощью ключа -i.
Посмотрим содержимое нашего каталога командой ls, а затем отфильтруем только то, что заканчивается на «ile«.

Получается следующее, когда мы даем на ввод команде grep шаблон и где искать, он работает с файлом, а когда мы даем команду ls она выводи содержимое каталога и мы это содержимое передаем по конвейеру на команду grep с заданным шаблоном. Соответственно grep фильтрует переданное содержимое согласно шаблона и выводит на экран. Получается, что команде grep дали, то команда и обработала.
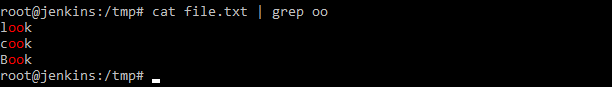
Наглядно можно посмотреть на рисунке выше. Мы просматриваем командой cat содержимое файла и подаем на ввод команде grep с фильтрацией по шаблону.
Давайте найдем файлы в которых содержится сочетание «ple«. grep ple file.txt в данном случае команда нашла оба слова содержащие шаблон. Давайте найдем слово, которое будет начинаться с «ple«. Команда будет выглядеть следующим образом: grep ^ple file.txt . Значок «^» указывает на начало строки. Противоположная задача найти слова, заканчивающиеся на «ple«. Команда будет выглядеть следующим образом grep ple$ file.txt . Т.е. применять к концу строки, говорит значок «$» в шаблоне.

Можно дать команду grep .o file.txt. В данном выражении знак «.» , заменяет любую букву.

Как вы видите вывод шаблона «.ple» вывел только одно слово т.к только слово couple удовлетворяло шаблону , т.к перед «ple» должен был содержаться еще один символ любой.
Попробуем рассмотреть другую команду egrep.
egrep (Extended grep)
man egrep — отошлет к справке по grep.
Данная команда позволяет использовать более расширенный набор шаблонов. Рассмотрим следующий пример команды:
Шаблон заключается в одинарные кавычки, для того чтобы экранировать символы, и команда egrep поняла, что это относится к ней и воспринимала выражение как шаблон. Сам же шаблон означает, что поиск будет искать слова, в начале строки (знак ^) содержащие букву b или d.
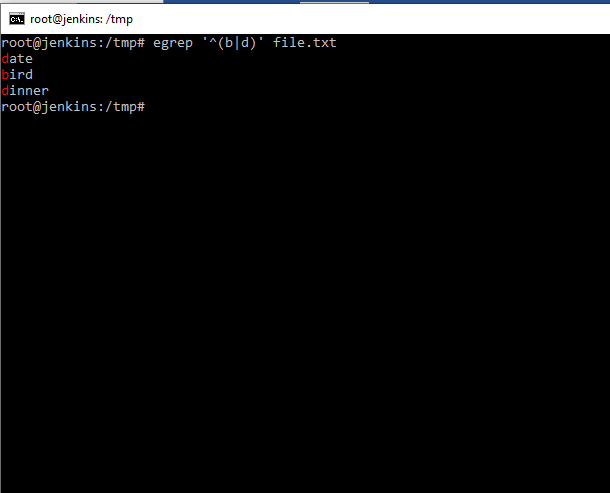
Мы видим, что команда вернула слова, начинающиеся с буквы b или d. Рассмотрим другой вариант использования команды egrep. Например:
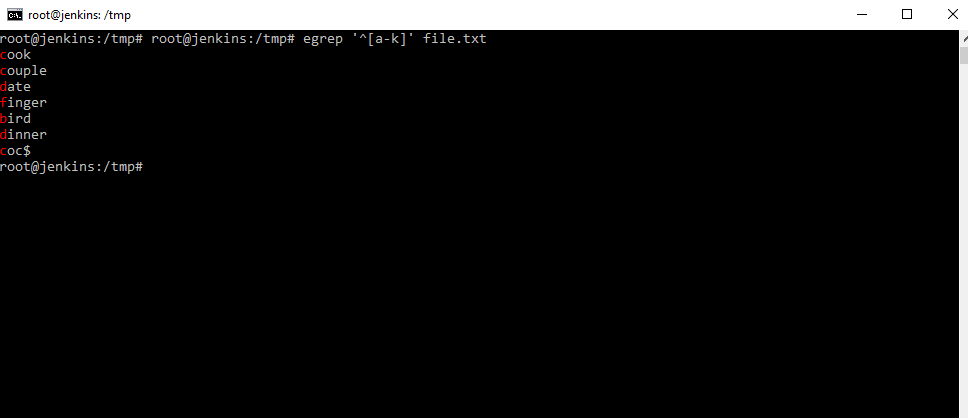
Получим все слова, начинающиеся с «a» по «к». Знак «[]» — диапазона. Как мы видим слова, начинающиеся с большой буквы, не попали. Все эти регулярные выражения очень пригодятся, когда мы что-то ищем в файлах логах.
Усложним еще шаблон. Возьмем следующий:
Усложняя выражение, мы добавили диапазон заглавных букв сказав команде grep искать диапазон маленьких или диапазон больших букв с начала строки.

Вот теперь все хорошо. Слова с Заглавными буквами тоже отобразились.
Как вариант egrep можно запускать просто grep с ключиком -e.
Про fgrep
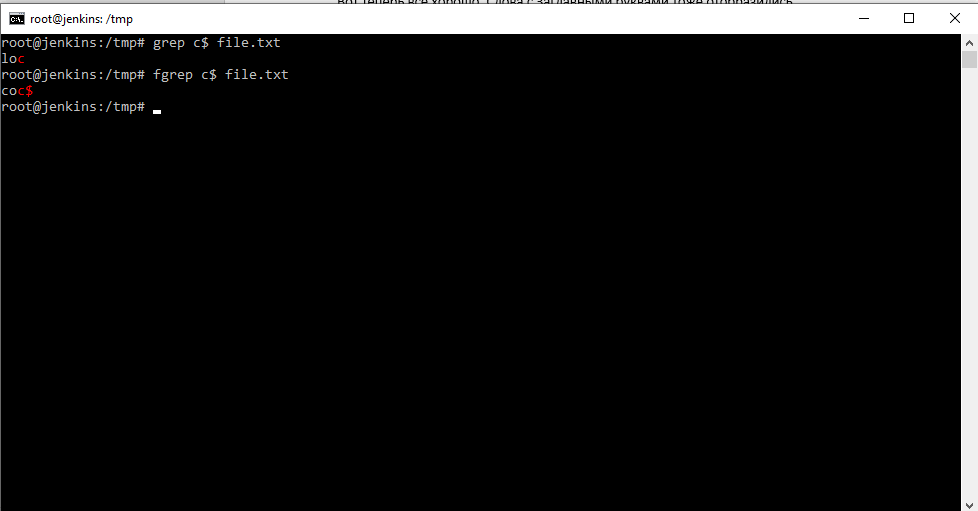
man fgrep — отошлет к справке по grep. Команда fgrep не понимает регулярных выражений вообще.
Получается следующим образом если мы вводим: egrep c$ file.txt . То команда согласно шаблону, ищет в файле букву «c» в конце слова. В случае же с командой fgrep c$ file.txt , команда будет искать именно сочетание «с$». Т.е. команда fgrep воспринимает символы регулярных выражений, как обычные символы, которые ей нужно найти, как аргументы.
Рекурсивный rgrep
Создадим каталог mkdir folder . Создадим файл great.txt в созданной директории folder со словом Hello при помощью команды echo «Hello» folder/great.txt
И если мы скажем grep Hello * , поищи слово Hello в текущей директории. Получится следующая картина.
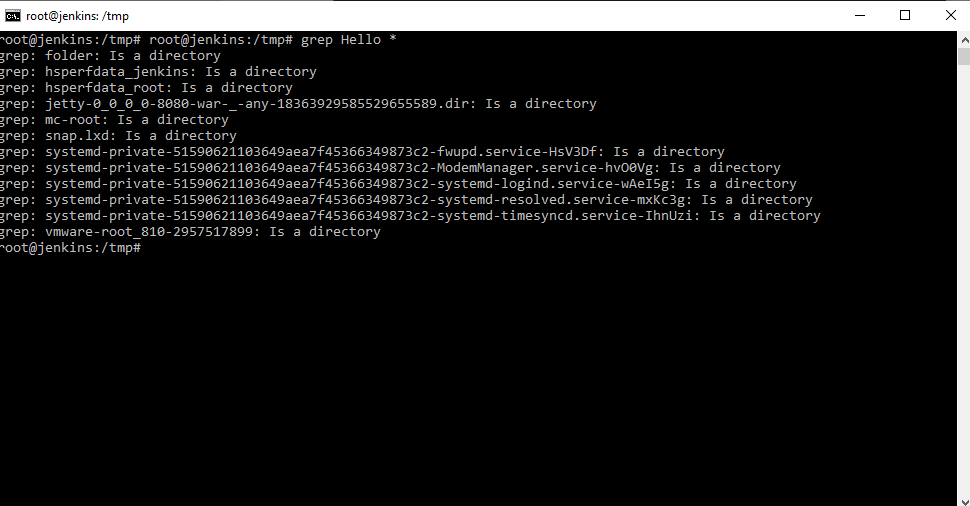
Как мы видим grep не может искать в папках. Для таких случаев и используется утилита rgrep.
Дает следующую картину.
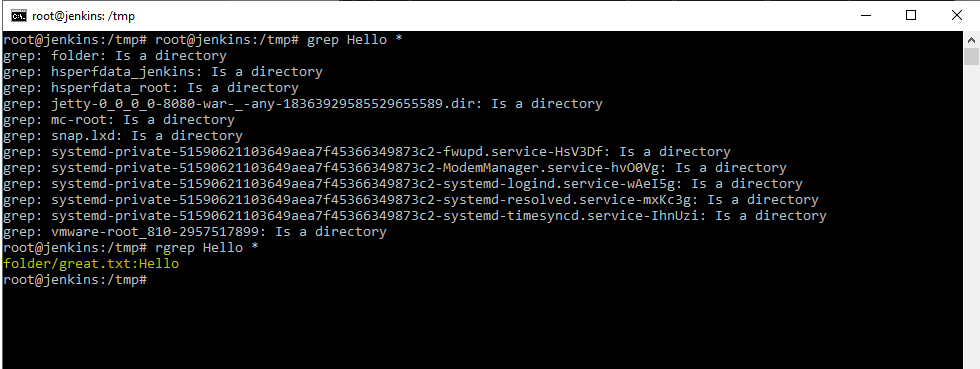
Совершенно спокойно в папке найдено было, то что подходило под шаблон.
Данная утилита пробежалась по всем папкам и файлам в них и нашла подходящее под шаблон слово. Т.е. если нам необходимо провести поиск по всем файлам и папкам, то необходимо использовать утилиту rgrep .
Команда sed
man sed — стрим редактор. Т.е потоковый редактор для фильтрации и редактирования потока данных.
Например, sed -e ‘s/oo/aa’ file.txt — открыть редактор sed и заменить вывод всех oo на aa в файле file.txt. Нужно понимать, что в результате данной команды изменения в файле не произойдут. Просто данные из файла будут взяты и с изменениями выведены на стандартный вывод, т.е. экран. Для сохранения результатов мы можем сказать, чтобы вывел в новый файл указав направление вывода.
В данном редакторе мы можем ему сказать использовать регулярные выражения, для этого необходимо добавить ключ -r. У данного редактора очень большой функционал.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена
Источник
Использование Grep и регулярных выражений для поиска текстовых шаблонов в Linux
Вступление
Одна из наиболее полезных и многофункциональных команд в терминале Linux – команда «grep». Grep – это акроним, который расшифровывается как «global regular expression print» (то есть, «искать везде соответствующие регулярному выражению строки и выводить их»). Это значит, что grep можно использовать для того, чтобы просмотреть, соответствуют ли вводимые данные заданным шаблонам.
Эта на первый взгляд тривиальная программа очень мощна при верном использовании. Ее способность сортировать вводимые данные на основе сложных правил делает ее популярной связкой во многих цепях команд.
Данное руководство рассматривает некоторые возможности команды grep, а затем переходит к использованию регулярных выражений. Все описанные в данном руководстве техники можно применить в управлении виртуальным сервером.
Основы использования
В простейшей форме grep используется для поиска совпадений буквенных шаблонов в текстовом файле. Это значит, что если команда grep получает слово для поиска, она будет выводить каждую содержащую это слово строку файла.
В качестве примера можно использовать grep для поиска строк, содержащих слово «GNU» в версии 3 GNU General Public License на системе Ubuntu.
cd /usr/share/common-licenses
grep «GNU» GPL-3
GNU GENERAL PUBLIC LICENSE
The GNU General Public License is a free, copyleft license for
the GNU General Public License is intended to guarantee your freedom to
GNU General Public License for most of our software; it applies also to
Developers that use the GNU GPL protect your rights with two steps:
«This License» refers to version 3 of the GNU General Public License.
13. Use with the GNU Affero General Public License.
under version 3 of the GNU Affero General Public License into a single
.
.
Первый аргумент, «GNU», является искомым шаблоном, а второй аргумент, «GPL-3», является входным файлом, который нужно найти.
В результате будут выведены все строки, содержащие текстовый шаблон. В некоторых дистрибутивах Linux искомый шаблон будет выделен в выведенных строках.
Общие опции
По умолчанию команда grep просто ищет строго указанные шаблоны во входном файле и выводит найденные строки. Тем не менее, поведение утилиты grep можно изменить, внеся некоторые дополнительные флаги.
При необходимости игнорировать регистр параметра поиска и искать как прописные, так и строчные вариации шаблона, можно использовать утилиты «-i» или «–ignore-case».
Для примера можно использовать grep для поиска в том же файле слова «license», написанного верхним, нижним или смешанным регистром.
grep -i «license» GPL-3
GNU GENERAL PUBLIC LICENSE
of this license document, but changing it is not allowed.
The GNU General Public License is a free, copyleft license for
The licenses for most software and other practical works are designed
the GNU General Public License is intended to guarantee your freedom to
GNU General Public License for most of our software; it applies also to
price. Our General Public Licenses are designed to make sure that you
(1) assert copyright on the software, and (2) offer you this License
«This License» refers to version 3 of the GNU General Public License.
«The Program» refers to any copyrightable work licensed under this
.
.
Как можно видеть, выведенные результаты содержат «LICENSE», «license», and «License». Если бы в файле был экземпляр «LiCeNsE», он также был бы выведен.
При необходимости найти все строки, которые не содержат указанный шаблон, можно использовать флаги «-v» или «–invert-match».
Для примера можно применить следующую команду для поиска в лицензии BSD всех строк, которые не содержат слово «the»:
grep -v «the» BSD
All rights reserved.
Redistribution and use in source and binary forms, with or without
are met:
may be used to endorse or promote products derived from this software
without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS «AS IS» AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
.
.
Как можно видеть, последние две строки были выведены как не содержащие слова «the», поскольку команда «ignore case» не была использована.
Всегда полезно знать номера строк, в которых были обнаружены совпадения. Их можно узнать при помощи флагов «-n» или «–line-number» .
Если применить данный флаг в предыдущем примере, будет выведен следующий результат:
grep -vn «the» BSD
2:All rights reserved.
3:
4:Redistribution and use in source and binary forms, with or without
6:are met:
13: may be used to endorse or promote products derived from this software
14: without specific prior written permission.
15:
16:THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS «AS IS» AND
17:ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
.
.
Теперь можно сослаться на номер строки при необходимости внести изменения в каждой строке, которая не содержит «the».
Регулярные выражения
Как было сказано во вступлении, grep расшифровывается как «global regular expression print». Регулярное выражение – это текстовая строка, которая описывает определенный шаблон поиска.
Разные приложения и языки программирования применяют регулярные выражения немного по-разному. В данном руководстве рассматривается только небольшое подмножество способов описания шаблонов для Grep.
Буквенные совпадения
В приведенных выше примерах поиска слов «GNU» и «the» разыскивались очень простые регулярные выражения, точно соответствующие строке символов «GNU» и «the».
Правильнее представлять их именно как совпадения строк символов, чем как совпадения слов. После ознакомления с более сложными шаблонами это разграничение станет более существенным.
Шаблоны, точно соответствующие заданным символам, называются «буквенными», поскольку они соответствуют шаблону побуквенно, символ в символ.
Все буквенные и числовые символы (а также некоторые другие символы) совпадают буквально, если они не были изменены другими механизмами выражения.
Совпадения анкоров
Анкоры – это специальные символы, которые указывают местонахождение в строке необходимого совпадения.
К примеру, можно указать, что при поиске нужны только строки, содержащие слово «GNU» в самом начале. Для этого нужно использовать анкор «^» перед буквенной строкой.
В этом примере выведены только строки, содержащие в самом начале слово «GNU».
grep «^GNU» GPL-3
GNU General Public License for most of our software; it applies also to
GNU General Public License, you may choose any version ever published
Аналогично, анкор «$» можно использовать после буквенной строки, чтобы указать, что совпадение действительно, только если искомая строка символов находится в конце текстовой строки.
В следующем регулярном выражении выведены только те строки, которые содержат «and» в конце:
grep «and$» GPL-3
that there is no warranty for this free software. For both users’ and
The precise terms and conditions for copying, distribution and
License. Each licensee is addressed as «you». «Licensees» and
receive it, in any medium, provided that you conspicuously and
alternative is allowed only occasionally and noncommercially, and
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
provisionally, unless and until the copyright holder explicitly and
receives a license from the original licensors, to run, modify and
make, use, sell, offer for sale, import and otherwise run, modify and
Совпадение любого символа
Точка (.) используется в регулярных выражениях, чтобы обозначить, что в указанном месте может находиться любой символ.
К примеру, при необходимости найти совпадения, содержащие два символа и затем последовательность «cept», нужно использовать следующий шаблон:
grep «..cept» GPL-3
use, which is precisely where it is most unacceptable. Therefore, we
infringement under applicable copyright law, except executing it on a
tells the user that there is no warranty for the work (except to the
License by making exceptions from one or more of its conditions.
form of a separately written license, or stated as exceptions;
You may not propagate or modify a covered work except as expressly
9. Acceptance Not Required for Having Copies.
.
.
Как можно видеть, в результатах выведены слова «accept» and «except», а также вариации этих слов. Шаблон также совпал бы с последовательностью «z2cept», если бы такая была в тексте.
Выражения в скобках
Поместив группу символов в квадратные скобки («[ ]»), можно указать, что в данной позиции может находиться любой из взятых в скобки символов.
Это значит, что при необходимости найти строки, содержащие «too» или «two», можно кратко указать данные вариации, используя следующий шаблон:
grep «t[wo]o» GPL-3
your programs, too.
freedoms that you received. You must make sure that they, too, receive
Developers that use the GNU GPL protect your rights with two steps:
a computer network, with no transfer of a copy, is not conveying.
System Libraries, or general-purpose tools or generally available free
Corresponding Source from a network server at no charge.
.
.
Как можно видеть, обе вариации были найдены в файле.
Внесение символов в скобки также предоставляет несколько полезных возможностей. Можно указать, что с шаблоном совпадает все, кроме символов в скобках, если начать список символов, внесенных в скобки, с символа «^».
В данном примере используется шаблон «.ode», с которым не должна совпадать последовательность «code».
grep «[^c]ode» GPL-3
1. Source Code.
model, to give anyone who possesses the object code either (1) a
the only significant mode of use of the product.
notice like this when it starts in an interactive mode:
Стоит заметить, что вторая выведенная строка содержит слово «code». Это не ошибка регулярного выражения или команды grep.
Вернее, эта строка была выведена, потому что она также содержит соответствующую шаблону последовательность «mode», найденную в слове «model». То есть, строка была выведена потому, что в ней было обнаружено совпадение с шаблоном.
Еще одна полезная функция скобок – возможность указать диапазон символов вместо того, чтобы отдельно вводить каждый символ.
Это значит, что при необходимости найти каждую строку, которая начинается с заглавной буквы, можно использовать следующий шаблон:
grep «^[A-Z]» GPL-3
GNU General Public License for most of our software; it applies also to
States should not allow patents to restrict development and use of
License. Each licensee is addressed as «you». «Licensees» and
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
System Libraries, or general-purpose tools or generally available free
Source.
User Product is transferred to the recipient in perpetuity or for a
.
.
В связи с некоторыми наследственными проблемами сортировки, для более точного результата лучше использовать классы символов стандарта POSIX вместо диапазона символов, использованного в примере выше.
Существует множество классов символов, не охваченных данным руководством; к примеру, чтобы выполнить ту же процедуру, что и в примере выше, можно использовать класс символов «[:upper:]» в скобках.
grep «^[[:upper:]]» GPL-3
GNU General Public License for most of our software; it applies also to
States should not allow patents to restrict development and use of
License. Each licensee is addressed as «you». «Licensees» and
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
System Libraries, or general-purpose tools or generally available free
Source.
User Product is transferred to the recipient in perpetuity or for a
.
.
Шаблон повторения (0 или больше раз)
Одним из наиболее часто используемых метасимволов является символ «*», что означает «повторить предыдущий символ или выражение 0 или больше раз».
К примеру, при необходимости найти каждую строку с открывающимися или закрывающимися круглыми скобками, что содержат только буквы и одиночные пробелы между ними, можно использовать следующее выражение:
grep «([A-Za-z ]*)» GPL-3
Copyright (C) 2007 Free Software Foundation, Inc.
distribution (with or without modification), making available to the
than the work as a whole, that (a) is included in the normal form of
Component, and (b) serves only to enable use of the work with that
(if any) on which the executable work runs, or a compiler used to
(including a physical distribution medium), accompanied by the
(including a physical distribution medium), accompanied by a
place (gratis or for a charge), and offer equivalent access to the
.
.
Как избежать метасимволов
Иногда может понадобиться искать буквальную точку или буквальную открытую скобку. Поскольку данные символы имеют определенное значение в регулярных выражениях, необходимо «избегать» их, говоря команде grep, что в данном случае использовать их особое значение не нужно.
Этих символов можно избежать, используя обратную косую (\) перед символом, который обычно имеет особое значение.
К примеру, при необходимости найти строку, что начинается с заглавной и заканчивается точкой, можно использовать приведенное ниже выражение. Обратная косая перед последней точкой говорит команде «избегать» ее, так что последняя точка представляет буквальную точку и не имеет значения «любой символ»:
grep «^[A-Z].*\.$» GPL-3
Source.
License by making exceptions from one or more of its conditions.
License would be to refrain entirely from conveying the Program.
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
SUCH DAMAGES.
Also add information on how to contact you by electronic and paper mail.
Расширенные регулярные выражения
Команду Grep можно также использовать с расширенным языком регулярных выражений при помощи флага «-E» или же вызывая команду «egrep» вместо «grep».
Эти команды открывают возможности «расширенных регулярных выражений». Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для выражения более сложных совпадений.
Группирование
Одна из простейших и полезнейших возможностей, которые открывают расширенные регулярные выражения, – это возможность группировать выражения и использовать их как единое целое.
Для группирования выражений используются круглые скобки. При необходимости использовать круглые скобки вне расширенных регулярных выражений, их можно «избежать» при помощи обратной косой
grep «\(grouping\)» file.txt
grep -E «(grouping)» file.txt
egrep «(grouping)» file.txt
Приведенные выше выражения являются эквивалентами.
Чередование
Подобно тому, как квадратные скобки задают различные возможные варианты совпадения одного символа, чередование позволяет указать альтернативные совпадения для строк символов или наборов выражений.
Для обозначения чередования используется символ вертикальной черты «|». Чередование часто применяется в группировании для того, чтобы указать, что один из двух или более возможных вариантов должен рассматриваться как совпадение.
В данном примере нужно найти «GPL» или «General Public License»:
grep -E «(GPL|General Public License)» GPL-3
The GNU General Public License is a free, copyleft license for
the GNU General Public License is intended to guarantee your freedom to
GNU General Public License for most of our software; it applies also to
price. Our General Public Licenses are designed to make sure that you
Developers that use the GNU GPL protect your rights with two steps:
For the developers’ and authors’ protection, the GPL clearly explains
authors’ sake, the GPL requires that modified versions be marked as
have designed this version of the GPL to prohibit the practice for those
.
.
Чередование можно использовать для выбора между двумя и более вариантами; для этого нужно ввести остальные варианты в группу отбора, отделяя каждый при помощи символа вертикальной черты «|».
Кванторы
В расширенных регулярных выражениях существуют метасимволы, указывающие частоту повторения символа, подобно тому, как метасимвол «*» указывает на совпадения предыдущего символа или строки символов 0 или более раз.
Чтобы указать совпадение символа 0 или больше раз, можно использовать символ «?». Он сделает предыдущий символ или ряд символов, по сути, необязательными.
В данном примере при помощи внесения последовательности «copy» в факультативную группу выведены совпадения «copyright» и «right»:
grep -E «(copy)?right» GPL-3
Copyright (C) 2007 Free Software Foundation, Inc.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
«Copyright» also means copyright-like laws that apply to other kinds of
.
.
Символ «+» ищет совпадения выражений 1 или больше раз. Он работает почти как символ «*», но при использовании «+» выражение должно совпасть хотя бы 1 раз.
Приведенное ниже выражение ищет совпадения строки «free» плюс 1 или больше символов, которые не являются пробельными:
grep -E «free[^[:space:]]+» GPL-3
The GNU General Public License is a free, copyleft license for
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
When we speak of free software, we are referring to freedom, not
have the freedom to distribute copies of free software (and charge for
you modify it: responsibilities to respect the freedom of others.
freedoms that you received. You must make sure that they, too, receive
protecting users’ freedom to change the software. The systematic
of the GPL, as needed to protect the freedom of users.
patents cannot be used to render the program non-free.
Количество повторений совпадений
При необходимости указать количество повторения совпадений можно использовать фигурные скобки («< >»). Эти символы используются для указания точного количества, диапазона, а также верхнего и нижнего предела количества совпадений выражения.
При необходимости найти все строки, что содержат сочетание трех гласных, можно использовать следующее выражение:
grep -E «[AEIOUaeiou]<3>» GPL-3
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
receive it, in any medium, provided that you conspicuously and
give under the previous paragraph, plus a right to possession of the
covered work so as to satisfy simultaneously your obligations under this
При необходимости найти все слова, состоящие из 16-20 символов, используйте следующее выражение:
grep -E «[[:alpha:]]<16,20>» GPL-3
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
c) Prohibiting misrepresentation of the origin of that material, or
Выводы
Во многих случаях команда grep бывает полезна для поиска шаблонов внутри файлов или в иерархии файловой системы. Она значительно экономит время, потому стоит ознакомиться с ее параметрами и синтаксисом.
Регулярные выражения еще более многофункциональны и могут быть использованы во многих популярных программах. К примеру, многие текстовые редакторы применяют регулярные выражения для поиска и замены текста.
Более того, передовые языки программирования используют регулярные выражения для выполнения процедур на конкретных фрагментах данных. Умение работать с регулярными выражениями пригодится при решении общих задач, связанных с компьютером.
Источник



