- linux-notes.org
- Установка Kubernetes кластера в Unix/Linux
- Установка Kubernetes кластера в Unix/Linux
- Установка kubernetes-master-1 на CentOS 7
- Установка kubernetes-worker-1 на Debian 8
- Установка kubernetes-worker-2 на Debian 8
- Установка kubernetes-worker-n на CenOS 7/Redhat 7
- Деплой Kubernetes кластера в Unix/Linux
- Ролбэк Kubernetes кластера в Unix/Linux
- Масштабирование Kubernetes кластера в Unix/Linux
- Мониторинг Kubernetes кластера в Unix/Linux
- Удаление Kubernetes кластера в Unix/Linux
- Развертывание кластера Pacemaker для SQL Server на Linux
- Предварительные требования
- Установите надстройку высокого уровня доступности.
- Подготовка узлов для Pacemaker (только в RHEL и Ubuntu)
- Создание кластера Pacemaker
- Установка пакетов высокого уровня доступности и агента SQL Server
- Дальнейшие действия
linux-notes.org
Установка Kubernetes кластера в Unix/Linux
Kubernetes (часто так же используется обозначение «K8s», название образовано от греческого κυβερνήτης, — «кормчий»,»рулевой», по русски — Кубернетес или Кубернетис) — открытое программное обеспечение для автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Оригинальная версия была разработана компанией Google. Впоследствии Kubernetes был передан под управление Cloud Native Computing Foundation. Предназначение Kubernetes — предоставить «платформу для автоматического развёртывания, масштабирования, управления приложениями на кластерах или отдельных хостах». Кубернетис поддерживает различные технологии контейнеризации, включая Docker, VMWare и ряд других.
Kenernetes используется фондом Wikimedia Foundation, инфраструктура которого мигрировала на это приложение с самостоятельно разработанного ПО для организации кластеров.
Установка Kubernetes кластера в Unix/Linux
Я рассказывал об установке kubernetes-а ранее в моей статье, — Установка Kubernetes в Unix/Linux. По этому — я немного опущу установку ПО и расскажу как можно собрать полноценный кластер с «блэкджеком и куртизанками», т.е — собрать все воедино. Добавлять автоматически ноды, мониторить их и так же — выполнять деплой приложений, скейлинг в зависимости от нужд.
- 192.168.13.219 — Нода kubernetes-master-1 на CentOS 7.
- 192.168.13.230 — Нода kubernetes-worker-1 наDebian 8.
- 192.168.13.147 — Нода kubernetes-worker-2 на Debian 8.
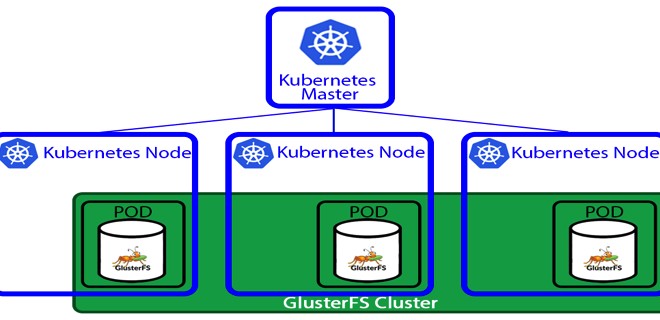
Кластерная диаграмма кубернетес кластера, выглядит следующим образом:

- Мастер отвечает за управление кластером. Master узлы будут координировать всю деятельность, происходящую в вашем кластере, например, приложения для планирования, сохранение желаемого состояния, масштабирование приложений и обновление апликейщенов.
- Узел (node) представляет собой виртуальную машину или физический компьютер, который используется в качестве рабочего компьютера в кластере Kubernetes. Каждый узел из кластера управляется мастером. На типичном узле вы будете иметь инструменты для обработки операций с контейнерами (например, Docker, rkt) и Kubelet, агента для управления узлом. Кластер Kubernetes, который обрабатывает ПРОД, должен иметь минимум три узла в кластере.
Когда мы развертываем приложения на Kubernetes, мы говорим мастеру, чтобы он запускал контейнеры и планировал их запуск на других нодах. Связь между мстером и воркерами(нодами) осуществляется через API — мастером. Тот же API доступен для пользователей, чтобы облегчить взаимодействие с кластером.
Хватит теории, перейдем к установке и настройке самого кластера!
Установка kubernetes-master-1 на CentOS 7
Это не столь важно, но для примера — будет красиво!
Т.к у меня нет DNS-сервера (я строю кластер локально, на виртуальных машинах), то нужно прописать:
Это поможет резолвить ноды между собой.
Не забываем выключить SELinux, а то он может наломать вам дров:
Как вы знаете, в centOS 7 имеется firewalld и по этому — стоит пробрасывать правила (но в моем случае — нету смысла) или просто выключить его:
Добавим репозиторий с kubernetes:
Собственно, выполняем установку докера и кубика:
Добавялем докер-службу в автозагрузку ОС и запускаем сервис:
Some users on RHEL/CentOS 7 have reported issues with traffic being routed incorrectly due to iptables being bypassed. You should ensure net.bridge.bridge-nf-call-iptables is set to 1 in your sysctl config, e.g.
Насчет etcd, я не уверен что нужно сувать его в автозагрузку ОС. Но можно это сделать вот так:
- kubeadm init — Инициализируем кубернетес.
- —ignore-preflight-errors=all — Скипаю все ошибки (но лучше не использовать этот параметр если не уверены).
- —pod-network-cidr=10.244.0.0/16 — Задаем подсеть для будущего кубо-кластера (не обязательная опция).
- —apiserver-advertise-address=192.168.13.231 — Можно задать данный параметр для установки IP адреса самого API сервера (не обязательная опция).
- —kubernetes-version $(kubeadm version -o short) — Чтобы задать версию кубика (не обязательная опция).
- —token=YOUR_TOKEN — Используется чтобы задать токен (не обязательная опция).
Добавялем кубернетес-службу в автозагрузку ОС и запускаем сервис:
Я не буду добавлять пользователя для кубика, буду использовать — root. Вносим изменения небольшие:
Так же, незабываем сохранить команду для добавления нод в мастер, у меня это:
Смотрим что вышло:
PS: Можно получить следующую ошибку:
Как видим, у меня — уже просетапался кубик-мастер нода. Но статус не готов, смотрим что не так:
Такс, нет DNS резолвера, — фиксаем:
Различные сети поддерживаются в k8s и зависят от выбора пользователя. Создание сети, занимает определенное время (пару минут точно), через время — проверяем:
Идем дальше — необходимо установить и добавить воркеры в созданный мастер!
Установка kubernetes-worker-1 на Debian 8
Это не столь важно, но для примера — будет красиво!
Т.к у меня нет DNS-сервера (я строю кластер локально, на виртуальных машинах), то нужно прописать:
Это поможет резолвить ноды между собой.
Ставим нужные зависимости:
Этой командой, добавляем репку, и для установки — выполняем:
Добавляем докер в автозагрузку ОС, запускаем его и смотрим статус:
Сейчас, ставим кубик:
Добавляем kubelet в автозагрузку ОС, запускаем его и смотрим статус:
Все готово, можно добавлять ноду в кластер:
- kubeadm join — Команда для добавления узлов к мастеру.
- —token c4de10.ff1831543e2e223a — Токен для добавления.
- 192.168.13.219:6443 — Хост и порт от мастер-ноды.
- —discovery-token-ca-cert-hash sha256:f75e564824bb87a906a83f11fabc74b31c759a206dae75401448980e64d0953e — Дискавер токен.
- —discovery-token-unsafe-skip-ca-verification — Можно использовать данную опцию для использывания обхода проверки токена обнаружения. Поскольку этот токен генерируется динамически, мы не могли включить его в действия. При создании ПРОД машин, укажите токен, предоставленный kubeadm init.
Фиксим так, для начала — добавляем:
Потом, открываем файл:
Находим строку «GRUB_CMDLINE_LINUX» и приводим к виду:
Немного о cgroups:
И потом, можно запускать (добавляем воркер к мастеру):
На kubernetes-master-1, запускаем:
Идем дальше — необходимо установить и добавить еще один воркер в созданный мастер!
Установка kubernetes-worker-2 на Debian 8
Аналогичные действия, проделываю и для kubernetes-worker-2. Но только с другим хостнеймом.
Установка kubernetes-worker-n на CenOS 7/Redhat 7
Можно добавлять другие воркеры по аналогии как я описывал ранее для kubernetes-master-1, но без инициализации мастера (что логично, не правдали?).
Деплой Kubernetes кластера в Unix/Linux
Приведу наглядный скриншот того, как выглядит развертывание первого приложения на Kubernetes:
Образ контейнера развертывается, а так же — количество реплик определяются во время создания деплоя, но могут быть изменены после.
Когда все ноды будут добавлены в кластер, должно получится что-то типа:
Как видно что 2-й воркер не успел кодключится еще к кластеру. Через время подключится. Нужно пару минут подождать. Ну, пол работы сделано — осталось научится деплоить, мониторить и может чет еще упустил…
-=== СПОСОБ 1 ===-
Смотрим какие деплойменты имеются:
Можно получить дополнительную инфу, выполнив:
Получаем что-то типа:
Делаем контейнер доступным в интернете:
Проверяем работу контейнеров:
На мастере я не запускал воркер, по этому — смысла проверять, — нет.
Можно посмотреть сколько реплик имеется:
Чтобы проверить поды, выполняем:
Ролбэк Kubernetes кластера в Unix/Linux
Можно выполнять ролбэки:
Можно проверить хистори всех ролбеков:
Теперь я выполню откат к предыдущей версии:
- —to-revision=2 — С данной опцией, можно задать до какой ревизии делаем откат.
Масштабирование Kubernetes кластера в Unix/Linux
Можно выводить много полезной инфы вот так:
Все гениальное — просто. Но нужно время чтобы понять.
Мониторинг Kubernetes кластера в Unix/Linux
Дополню когда пойму как можно это сделать автоматически. У меня есть как минимум, 3 способа реализации. Но 1 из них — не очень хорошее решение.
- Можно заюзать zabbix и просетапать все kubernetes ноды, zabbix-агентами. Это реально будет работать, но как по мне — не ТРУЪ!
- Можно использовать consul для этого дела — это лучше решение чем заббикс.
- Так же, можно использовать prometheus
Но об этом немного позже. Я дополню эту часть, обязательно!
Удаление Kubernetes кластера в Unix/Linux
Чтобы удалить ноду с кластера, на мастере, выполните:
Если же нужно удалить вообще все — то обратное действие — установки.
Для удаления деплоймента, используйте:
Теоретически, данный кластер можно поднять минут за 10-15. Но я потратил больше времени, — выплывали всякие косяки. Вывод — данная цтилита, довольно прикольная и юзабельная, но как по мне — нужна доработка. Так же, хотелось отметить, что мой кластер работает, но его нужно оптимизировать/автоматизировать. Нужно больше времени чтобы понять как я могу это сделать.
Вот и все, статья «Установка Kubernetes кластера в Unix/Linux» завершена.
Источник
Развертывание кластера Pacemaker для SQL Server на Linux
Применимо к: SQL Server (все поддерживаемые версии) — Linux
В этом руководстве описываются задачи, необходимые для развертывания кластера Pacemaker Linux для группы доступности Always On SQL Server или экземпляра отказоустойчивого кластера. В отличие от тесно связанного стека Windows Server и SQL Server, создавать кластер Pacemaker, а также настраивать группу доступности в Linux можно как до, так и после установки SQL Server. Интеграция и настройка ресурсов для той части группы доступности или экземпляра отказоустойчивого кластера, которая связана с Pacemaker, выполняется после настройки кластера.
Группа доступности с типом кластера «Нет» не требует наличия кластера Pacemaker и не может управляться с помощью Pacemaker.
- установка надстройки высокого уровня доступности и Pacemaker;
- подготовка узлов для Pacemaker (только в RHEL и Ubuntu);
- создание кластера Pacemaker;
- Установка пакетов высокого уровня доступности и агента SQL Server
Предварительные требования
Установите надстройку высокого уровня доступности.
Используйте приведенный ниже синтаксис, чтобы установить пакеты, составляющие надстройку высокого уровня доступности, для каждого дистрибутива Linux.
Red Hat Enterprise Linux (RHEL)
Зарегистрируйте сервер, используя приведенный ниже синтаксис. Вам будет предложено ввести допустимое имя пользователя и пароль.
Перечислите доступные пулы для регистрации.
Выполните следующую команду, чтобы связать высокий уровень доступности RHEL с подпиской:
Здесь PoolId — это идентификатор пула для подписки высокого уровня доступности из предыдущего шага.
Включите для репозитория возможность использовать надстройку высокого уровня доступности.
Ubuntu
SUSE Linux Enterprise Server (SLES)
Установите шаблон высокого уровня доступности в YaST или сделайте это в рамках основной установки сервера. Установку можно выполнить из ISO, с DVD-диска либо из сети.
В SLES надстройка высокого уровня доступности инициализируется при создании кластера.
Подготовка узлов для Pacemaker (только в RHEL и Ubuntu)
Для Pacemaker используется пользователь hacluster, созданный в дистрибутиве. Он создается при установке надстройки высокого уровня доступности в RHEL и Ubuntu.
На каждом сервере, который будет служить узлом кластера Pacemaker, создайте пароль для пользователя, используемого кластером. В примерах используется имя hacluster, но можно выбрать любое имя. Имя и пароль должны быть одинаковыми во всех узлах, участвующих в кластере Pacemaker.
В каждом узле, который будет входить в кластер Pacemaker, включите и запустите службу pcsd с помощью следующих команд (в RHEL и Ubuntu):
Затем выполните следующую команду:
чтобы убедиться в том, что средство pcsd запущено.
Включите службу Pacemaker в каждом возможном узле кластера Pacemaker.
В Ubuntu произойдет следующая ошибка:
pacemaker Default-Start contains no runlevels, aborting (pacemaker Default-Start не содержит уровни выполнения, прерывание).
Это известная проблема. Несмотря на ошибку, служба Pacemaker включается успешно. Эта ошибка будет исправлена в будущем.
Далее создайте и запустите кластер Pacemaker. На этом этапе между RHEL и Ubuntu есть одно различие. В обоих дистрибутивах при установке pcs настраивается файл конфигурации по умолчанию для кластера Pacemaker, однако в RHEL при выполнении этой команды существующая конфигурация удаляется и создается новый кластер.
Создание кластера Pacemaker
В этом разделе описывается, как создать и настроить кластер для каждого дистрибутива Linux.
RHEL
Здесь NodeX — это имя узла.
Здесь PMClusterName — это имя, присвоенное кластеру Pacemaker, а Nodelist — список имен узлов, разделенных пробелами.
Ubuntu
Ubuntu настраивается так же, как RHEL. Однако есть одно важное отличие: при установке пакетов Pacemaker создается базовая конфигурация кластера, а также включается и запускается pcsd . Если вы попытаетесь настроить кластер Pacemaker, выполнив точно те же инструкции, что и для RHEL, произойдет ошибка. Чтобы решить эту проблему, выполните указанные ниже действия.
Удалите конфигурацию Pacemaker по умолчанию из каждого узла.
Выполните инструкции по созданию кластера Pacemaker для RHEL.
SLES
Процесс создания кластера Pacemaker в SLES совершенно отличается от аналогичного процесса в RHEL и Ubuntu. Ниже описано, как создать кластер для SLES.
Начните процесс настройки кластера, выполнив команду
в одном из узлов. Может появиться предупреждение о том, что протокол NTP не настроен и устройство наблюдения не найдено. Это не помешает настройке. Устройство наблюдения связано с STONITH, если используется встроенное ограждение SLES на основе хранилища. NTP и устройство наблюдения можно настроить позже.
Вам предлагается настроить Corosync. Необходимо указать сетевой адрес для привязки, а также адрес и порт многоадресной рассылки. Сетевой адрес — это используемая подсеть, например 192.191.190.0. Во всех запросах можно принять значения по умолчанию или при необходимости изменить их.
Затем вам будет предложено настроить SBD, то есть ограждение на основе диска. Это при необходимости можно сделать позже. В отличие от RHEL и Ubuntu, если ограждение SBD не настроено, параметр stonith-enabled по умолчанию устанавливается в значение false.
Наконец, вам предлагается настроить IP-адрес для администрирования. Этот IP-адрес является необязательным, но имеет то же значение, что и IP-адрес отказоустойчивого кластера Windows Server (WSFC), то есть создает в кластере IP-адрес для подключения через веб-консоль высокого уровня доступности (HAWK). Эта настройка также является необязательной.
Убедитесь в том, что кластер настроен и запущен, выполнив следующую команду:
Измените пароль пользователя hacluster с помощью следующей команды:
Если вы настроили IP-адрес для администрирования, то можете протестировать его в браузере. При этом также проверяется изменение пароля для пользователя hacluster. 
На другом сервере SLES, который будет узлом кластера, выполните следующую команду:
При появлении запроса введите имя или IP-адрес сервера, который был настроен в качестве первого узла кластера в предыдущих шагах. Сервер добавляется в качестве узла в существующий кластер.
Убедитесь в том, что узел был добавлен, с помощью следующей команды:
- Измените пароль пользователя hacluster с помощью следующей команды:
- Повторите шаги 8–11 для всех остальных серверов, которые необходимо добавить в кластер.
Установка пакетов высокого уровня доступности и агента SQL Server
Используйте приведенные ниже команды, чтобы установить пакет высокого уровня доступности SQL Server и агент SQL Server, если они еще не установлены. Если пакет высокого уровня доступности был установлен после SQL Server, необходимо перезапустить SQL Server, чтобы этот пакет использовался. В этих инструкциях предполагается, что репозитории для пакетов Майкрософт уже настроены, так как SQL Server на этом этапе должен быть установлен.
- Если вы не будете использовать агент SQL Server для доставки журналов или в других целях, устанавливать его не обязательно, поэтому пакет mssql-server-agent можно пропустить.
- Другие необязательные пакеты для SQL Server в Linux — пакет полнотекстового поиска (mssql-server-fts) SQL Server и пакет SQL Server Integration Services (mssql-server-is) — не требуются для обеспечения высокой доступности и экземпляра FCI, и группы доступности.
RHEL
Ubuntu
SLES
Дальнейшие действия
В этом руководстве вы узнали, как развернуть кластер Pacemaker для SQL Server на Linux. Вы ознакомились с выполнением следующих задач:
- установка надстройки высокого уровня доступности и Pacemaker;
- подготовка узлов для Pacemaker (только в RHEL и Ubuntu);
- создание кластера Pacemaker;
- Установка пакетов высокого уровня доступности и агента SQL Server
Чтобы создать и настроить группу доступности для SQL Server на Linux, обратитесь к следующему руководству:
Источник



