- Создаём постоянное хранилище с provisioning в Kubernetes на базе Ceph
- rbd(8) — Linux man page
- Synopsis
- Description
- Options
- Parameters
- Commands
- Image Name
- Striping
- Examples
- Availability
- See Also
- Copyright
- Установка, настройка и эксплуатация Ceph
- Цели статьи
- Что такое Ceph
- Архитектура Ceph
- Аналоги
- CephFS vs GlusterFS
- Опыт использования
- Подготовка настроек
- Установка ceph
- Основные команды
- Использование кластера ceph
- Подключение Cephfs
- Ceph RBD
- Проверка надежности и отказоустойчивости
- Заключение
Создаём постоянное хранилище с provisioning в Kubernetes на базе Ceph

Предисловие переводчика: Когда мы собрались наконец-то подготовить свой материал по разворачиванию Ceph в Kubernetes, нашли уже готовую и, что немаловажно, свежую (от апреля 2017 года) инструкцию от компании Cron (из Боснии и Герцеговины) на английском языке. Убедившись в её простоте и практичности, решили поделиться с другими системными администраторами и DevOps-инженерами в формате «как есть», лишь добавив в листинги один небольшой недостающий фрагмент.
Программно-определяемые хранилища данных набирают популярность последние несколько лет, особенно с масштабным распространением частных облачных инфраструктур. Такие хранилища являются критической частью Docker-контейнеров, а самое популярное из них — Ceph. Если хранилище Ceph уже используется у вас, то благодаря его полной поддержке в Kubernetes легко настроить динамическое создание томов для хранения (volume provisioning) по запросу пользователей. Автоматизация их создания реализуется использованием Kubernetes StorageClasses. В этой инструкции показано, как в кластере Kubernetes реализуется хранилище Ceph. (Создание тестовой инсталляции Kubernetes, управляемой kubeadm, описано в этом материале на английском языке.)
Для начала вам также [помимо инсталляции Kubernetes] понадобится функционирующий кластер Ceph и наличие клиента rbd на всех узлах Kubernetes. Прим. перев.: RBD или RADOS Block Device — драйвер Linux-ядра, позволяющий подключать объекты Ceph как блочные устройства. Автор статьи использует кластер Ceph версии Jewel и Linux-дистрибутив Ubuntu 16.04 на узлах Kubernetes, поэтому установка клиентских библиотек Ceph (включая упомянутый rbd ) выглядит просто:
В официальном образе kube-controller-manager нет установленного клиента rbd , поэтому будем использовать другой образ. Для этого смените имя образа в /etc/kubernetes/manifests/kube-controller-manager.yaml на quay.io/attcomdev/kube-controller-manager:v1.6.1 (на текущий момент уже доступна версия 1.6.3, но конкретно мы тестировали только на 1.5.3 и 1.6.1 — прим. перев.) и дождитесь, пока kube-controller-manager перезапустится с новым образом.
Чтобы kube-controller-manager мог выполнять provisioning для хранилища, ему нужен ключ администратора из Ceph. Получить этот ключ можно так:
Добавьте его в секреты Kubernetes:
Для узлов Kubernetes в кластере Ceph создадим отдельный пул — именно его будем использовать в rbd на узлах:
Также создадим клиентский ключ (в кластере Ceph включена аутентификация cephx):
Для большей изоляции между разными пространствами имён создадим отдельный пул для каждого пространства имён в кластере Kubernetes. Получим ключ client.kube :
И создадим новый секрет в пространстве имён по умолчанию:
Когда оба секрета добавлены, можно определить и создать новый StorageClass:
(Прим. перев.: этот код по какой-то причине отсутствует в оригинальной статье, поэтому мы добавили свой и сообщили автору об обнаруженном упущении.)
Теперь создадим «заявку на постоянный том» (PersistentVolumeClaim) с использованием созданного StorageClass под названием fast_rbd :
Проверим, что всё работает корректно:
Последний шаг — создать тестовый под с использованием созданного PersistentVolumeClaim ( claim1 ):
Всё: новый контейнер использует образ Ceph, который динамически создан по запросу пользователя (PersistentVolumeClaim).
Источник
rbd(8) — Linux man page
rbd — manage rados block device (RBD) images
Synopsis
Description
rbd is a utility for manipulating rados block device (RBD) images, used by the Linux rbd driver and the rbd storage driver for Qemu/KVM. RBD images are simple block devices that are striped over objects and stored in a RADOS object store. The size of the objects the image is striped over must be a power of two.
Options
-c ceph.conf, —conf ceph.conf Use ceph.conf configuration file instead of the default /etc/ceph/ceph.conf to determine monitor addresses during startup. -m monaddress[:port] Connect to specified monitor (instead of looking through ceph.conf). -p pool, —pool pool Interact with the given pool. Required by most commands.
Parameters
—format format Specifies which object layout to use. The default is 1. • format 1 — Use the original format for a new rbd image. This format is understood by all versions of librbd and the kernel rbd module, but does not support newer features like cloning.
• format 2 — Use the second rbd format, which is supported by librbd (but not the kernel rbd module) at this time. This adds support for cloning and is more easily extensible to allow more features in the future. —size size-in-mb Specifies the size (in megabytes) of the new rbd image. —order bits Specifies the object size expressed as a number of bits, such that the object size is 1 —stripe-unit size-in-bytes Specifies the stripe unit size in bytes. See striping section (below) for more details. —stripe-count num Specifies the number of objects to stripe over before looping back to the first object. See striping section (below) for more details. —snap snap Specifies the snapshot name for the specific operation. —id username Specifies the username (without the client. prefix) to use with the map command. —keyfile filename Specifies a file containing the secret to use with the map command. If not specified, client.admin will be used by default. —keyring filename Specifies a keyring file containing a secret for the specified user to use with the map command. If not specified, the default keyring locations will be searched. —shared tag Option for lock add that allows multiple clients to lock the same image if they use the same tag. The tag is an arbitrary string. This is useful for situations where an image must be open from more than one client at once, like during live migration of a virtual machine, or for use underneath a clustered filesystem.
Commands
ls [-l | —long] [pool-name] Will list all rbd images listed in the rbd_directory object. With -l, also show snapshots, and use longer-format output including size, parent (if clone), format, etc. info [image-name] Will dump information (such as size and order) about a specific rbd image. If image is a clone, information about its parent is also displayed. If a snapshot is specified, whether it is protected is shown as well. create [image-name] Will create a new rbd image. You must also specify the size via —size. The —stripe-unit and —stripe-count arguments are optional, but must be used together. clone [parent-snapname] [image-name] Will create a clone (copy-on-write child) of the parent snapshot. Object order will be identical to that of the parent image unless specified. Size will be the same as the parent snapshot.
The parent snapshot must be protected (see rbd snap protect). This requires format 2. flatten [image-name] If image is a clone, copy all shared blocks from the parent snapshot and make the child independent of the parent, severing the link between parent snap and child. The parent snapshot can be unprotected and deleted if it has no further dependent clones.
This requires format 2. children [image-name] List the clones of the image at the given snapshot. This checks every pool, and outputs the resulting poolname/imagename.
This requires format 2. resize [image-name] Resizes rbd image. The size parameter also needs to be specified. rm [image-name] Deletes an rbd image (including all data blocks). If the image has snapshots, this fails and nothing is deleted. export [image-name] [dest-path] Exports image to dest path (use — for stdout). import [path] [dest-image] Creates a new image and imports its data from path (use — for stdin). The import operation will try to create sparse rbd images if possible. For import from stdin, the sparsification unit is the data block size of the destination image (1 cp [src-image] [dest-image] Copies the content of a src-image into the newly created dest-image. dest-image will have the same size, order, and format as src-image. mv [src-image] [dest-image] Renames an image. Note: rename across pools is not supported. snap ls [image-name] Dumps the list of snapshots inside a specific image. snap create [image-name] Creates a new snapshot. Requires the snapshot name parameter specified. snap rollback [image-name] Rollback image content to snapshot. This will iterate through the entire blocks array and update the data head content to the snapshotted version. snap rm [image-name] Removes the specified snapshot. snap purge [image-name] Removes all snapshots from an image. snap protect [image-name] Protect a snapshot from deletion, so that clones can be made of it (see rbd clone). Snapshots must be protected before clones are made; protection implies that there exist dependent cloned children that refer to this snapshot. rbd clone will fail on a nonprotected snapshot.
This requires format 2. snap unprotect [image-name] Unprotect a snapshot from deletion (undo snap protect). If cloned children remain, snap unprotect fails. (Note that clones may exist in different pools than the parent snapshot.)
This requires format 2. map [image-name] Maps the specified image to a block device via the rbd kernel module. unmap [device-path] Unmaps the block device that was mapped via the rbd kernel module. showmapped Show the rbd images that are mapped via the rbd kernel module. lock list [image-name] Show locks held on the image. The first column is the locker to use with the lock remove command. lock add [image-name] [lock-id] Lock an image. The lock-id is an arbitrary name for the user’s convenience. By default, this is an exclusive lock, meaning it will fail if the image is already locked. The —shared option changes this behavior. Note that locking does not affect any operation other than adding a lock. It does not protect an image from being deleted. lock remove [image-name] [lock-id] [locker] Release a lock on an image. The lock id and locker are as output by lock ls. bench-write [image-name] —io-size [io-size-in-bytes] —io-threads [num-ios-in-flight] —io-total [total-bytes-to-write] Generate a series of sequential writes to the image and measure the write throughput and latency. Defaults are: —io-size 4096, —io-threads 16, —io-total 1GB
Image Name
In addition to using the —pool and the —snap options, the image name can include both the pool name and the snapshot name. The image name format is as follows: Thus an image name that contains a slash character (‘/’) requires specifying the pool name explicitly.
Striping
RBD images are striped over many objects, which are then stored by the Ceph distributed object store (RADOS). As a result, read and write requests for the image are distributed across many nodes in the cluster, generally preventing any single node from becoming a bottleneck when individual images get large or busy.
The striping is controlled by three parameters: order The size of objects we stripe over is a power of two, specifially 2^[*order*] bytes. The default is 22, or 4 MB. stripe_unit Each [*stripe_unit*] contiguous bytes are stored adjacently in the same object, before we move on to the next object. stripe_count After we write [*stripe_unit*] bytes to [*stripe_count*] objects, we loop back to the initial object and write another stripe, until the object reaches its maximum size (as specified by [*order*]. At that point, we move on to the next [*stripe_count*] objects. By default, [stripe_unit] is the same as the object size and [stripe_count] is 1. Specifying a different [stripe_unit] requires that the STRIPINGV2 feature be supported (added in Ceph v0.53) and format 2 images be used.
Examples
To create a new rbd image that is 100 GB: or alternatively: To use a non-default object size (8 MB): To delete an rbd image (be careful!): To create a new snapshot: To create a copy-on-write clone of a protected snapshot: To see which clones of a snapshot exist: To delete a snapshot: To map an image via the kernel with cephx enabled: To unmap an image: To create an image and a clone from it: To create an image with a smaller stripe_unit (to better distribute small writes in some workloads): To change an image from one format to another, export it and then import it as the desired format: To lock an image for exclusive use: To release a lock:
Availability
rbd is part of the Ceph distributed file system. Please refer to the Ceph documentation at http://ceph.com/docs for more information.
See Also
Copyright
2010-2012, Inktank Storage, Inc. and contributors. Licensed under Creative Commons BY-SA
Источник
Установка, настройка и эксплуатация Ceph
Продолжаю цикл статей про кластерные решения, который был начат с установки kubernetes. Я расскажу как установить и настроить кластер ceph, так же покажу, как им потом пользоваться. Статья с практическими примерами от и до — поднятие кластера и подключение дисков к конечным серверам.
Цели статьи
- Рассказать своими словами о том, что такое Ceph, для чего нужен и какие есть аналоги.
- Развернуть тестовый кластер ceph с помощью ansible-playbook.
- Показать работу с кластером — подключение rbd дисков, запись данных в cephfs.
- Проверить поведение кластера при отказе одного из узлов.
Что такое Ceph
Ceph — программная объектная отказоустойчивая сеть хранения данных. Для чего нужна Ceph? Она реализует возможность файлового и блочного доступа к данным. Оба этих варианта я рассмотрю в своей статье. Это бесплатное программное обеспечение, которое устанавливается на linux системы и может состоять из огромного количества узлов.
Для того, чтобы потестировать ceph, достаточно трех практически любых компьютеров или виртуальных машин. Моя тестовая лаборатория, на которой я буду писать статью, состоит из 4-х виртуальных машин с операционной системой Centos 7 со следующими характеристиками.
| CPU | 2 |
| RAM | 4G |
| DISK | /dev/sda 50G, /dev/sdb 50G |
Это минимальная конфигурация для ceph, с которой стоит начинать тестирование. Из трех машин будет собран кластер ceph, а к четвертой я буду монтировать диски для проверки работоспособности.
Архитектура Ceph
Кластерная система хранения данных ceph состоит из нескольких демонов, каждый из которых обладает своей уникальной функциональностью. Расскажу о них кратко своими словами.
- MON, Ceph monitor — монитор кластера, который отслеживает его состояние. Все узлы кластера сообщают мониторам информацию о своем состоянии. Когда вы монтируете хранилища кластера к целевым серверам, вы указываете адреса мониторов. Сами мониторы не хранят непосредственно данные.
- OSD, Object Storage Device — элемент хранилища, который хранит сами данные и обрабатывает запросы клиентов. OSD являются основными демонами кластера, на которые ложится большая часть нагрузки. Данные в OSD хранятся в виде блоков.
- MDS, Metadata Server Daemon — сервер метаданных. Он нужен для работы файловой системы CephFS. Если вы ее не используете, то MDS вам не нужен. К примеру, если кластер ceph предоставляет доступ к данным через блочное устройство RBD, сервер метаданных разворачивать нет необходимости. Разделение метаданных от данных значительно увеличивает производительность кластера. К примеру, для листинга директории нет необходимости дергать OSD. Данные берутся из MDS.
- MGR, Manager Daemon — сервис мониторинга. До релиза Luminous был не обязательным компонентом, теперь — неотъемлемая часть кластера. Демон обеспечивает различный мониторинг кластера — от собственного дашборда до выгрузки метрик через json. Очень удобно. Мониторинг кластера не представляет особых сложностей.
Кластер ceph состоит из пулов для хранения данных. Каждый pool может обладать своими настройками. Пулы состоят из Placement Groups (PG), в которых хранятся объекты с данными, к которым обращаются клиенты.
В каждом кластере ceph имеется понятие фактора репликации — это уровень избыточности данных, или по простому — сколько копий данных будет храниться на разных дисках. Фактор репликации можно задавать разным для каждого пула и менять на лету.
Аналоги
Вообще говоря, Ceph достаточно уникальное кластерное решение, прямых аналогов которого нет. Но есть некоторые системы, схожие по решаемым проблемам. Основным аналогом Ceph является GlusterFS, которую я рассмотрю ниже отдельно. Так же к аналогам можно отнести следующие кластерные системы хранения данных:
- Файловая система ocfs2.
- OpenStack Swift.
- Sheepdog.
- HDFS (Hadoop Distributed File System)
- LeoFS
Список не полный. Это только то, что вспомнил я из того, что слышал. Сразу оговорюсь, что перечисленные системы мне практически не знакомы. Список привожу только для того, что, чтобы вам было проще потом самим найти о них информацию и сравнить. Они не являются полными аналогами ceph, но в каких-то вариантах могут подойти больше, нежели он. К примеру, Sheepdog намного проще система и потребности только в хранилище для виртуальных машин может закрывать лучше, чем ceph.
Теперь рассмотрим отдельно GlusterFS.
CephFS vs GlusterFS
Я не буду строить из себя эксперта и пытаться что-то объяснить в том, в чем не разбираюсь. На хабре есть очень подробная статья о сравнении Cephfs с GlusterFS от человека, который использовал обе системы. Если вам интересна тема подобного сравнения, то внимательно прочитайте. Я приведу краткие выводы, которые вынес сам из этой статьи.
- Glusterfs менее стабильная и у нее больше критических багов, которые приводят к повреждению данных.
- Ceph более гибкая и функциональная система.
- В ceph можно добавлять диски любого размера и каждый будет иметь зависимый от размера вес. Данные будут размещаться по дискам почти равномерно. В glusterfs диски добавляются парами или тройками в зависимости от фактора репликации. В итоге в glusterfs не получится просто вытащить старые диски меньшего объема и поставить новые больше. Вам нужно будет менять диски сразу у всей группы, выводя ее из работы. В ceph такой проблемы нет, можно спокойно заменять старые диски на новые большего объема.
- Архитектурно ceph быстрее и надежнее обрабатывает отказы дисков или серверов.
- GlusterFS лучше масштабируется. Есть примеры огромных инсталляций.
- В случае фактора репликации 2 у GlusterFS есть отличное решение с внешним арбитром.
Подводя итог статьи автор отмечает, что CephFS более сложное но и более функциональное решение. Я так понял, он отдает предпочтение ему.
Опыт использования
Своего опыта использования Ceph в production у меня нет. Я его хорошо протестировал и понял, что готов к тому, чтобы внедрять и использовать. Так что как и в предыдущем разделе поделюсь сторонними материалами на эту тему, которые изучал сам и они мне показались полезными.
Во-первых, очень интересная и популярная статья — Ceph. Анатомия катастрофы. Автор очень подробно рассматривает, как развивается ситуация в случае деградации кластера и дает советы по проектированию, чтобы восстановление прошло с наименьшими потерями. К слову, я тестировал на своем кластере отказ одной из трех нод и наблюдал примерно ту же картину, что описывает автор. Кластер начинает очень-очень сильно тормозить и привести его в чувство не так просто. После ввода в работу упавшей ноды, кластер вставал колом. Без подготовки и тренировки вся заявленная отказоустойчивость кластера ceph может вылететь в трубу и вы получите остановленный сервис. Там же в статье автор дает совет не отключать swap. А, к примеру, при установке Kubernetes, его наоборот нужно обязательно отключить.
Еще одна статья, которой хотел бы с вами поделиться на эту тему — А вот вы говорите Ceph… а так ли он хорош? Автор обращает внимание на огромное количество настроек ceph, большая часть из которых не понятно, что означает и за что отвечает 🙂 Так же он делится своим опытом эксплуатации большого и нагруженного кластера. Некоторые вещи удивляют, и становится не понятно, как это ставить в production. Тем не менее люди ставят и это вроде как даже нормально работает. Но однозначно это путь смелых! В комментариях автор явно не ответил, но стало понятно, что его кластер не имеет бэкапа! Как вам такое? Сложнейшая распределенная система, которая может превратиться в тыкву и нет бэкапов. Админам таких систем нужно доплачивать за риск. Я бы не стал работать в такой должности. Мне спокойная жизнь дороже даже повышенной оплаты за обслуживание таких систем.
Как я понял из этих статей, нагруженный ceph требует очень внимательного мониторинга и обслуживания. Требуется постоянно дежурный инженер и готовые инструкции на наиболее популярные инциденты — замена дисков, отказ сервера, переполнение osd и т.д. Все это нужно заранее тестировать и документировать.
Подготовка настроек
Ну что же, с теоретической частью закончили, начинаем практику. Мы будем устанавливать ceph с помощью официального playbook для ansible. Клонируем к себе репозиторий.
Переключаемся на последнюю стабильную ветку 3.2.
Проверяем зависимости в файле requirements.txt:
=2.6, Вычисление Placement Groups (PG)
Самая большая трудность в вычислении PG это необходимость соблюсти баланс между количеством групп на OSD и их размером. Чем больше PG на одной OSD, тем больше вам надо памяти для хранения информации об их расположении. А чем больше размер самой PG, тем больше данных будет перемещаться при балансировке.
Получается, что если у вас мало PG, они у вас большого размера, надо меньше памяти, но больше трафика уходит на репликацию. А если больше, то все наоборот. Теоретически считается, что для хранения 1 Тб данных в кластере надо 1 Гб оперативной памяти.
Как я уже кратко сказал выше, примерная формула расчета PG такая — Total PGs = (Number OSD * 100) / max_replication_count. Конкретно в моей установке по этой формуле получается цифра 100, которая округляется до 128. Но если задать такое количество pg, то роль ansible отработает с ошибкой:
Суть ошибки в том, что максимальное количество pg становится больше, чем возможно, исходя из параметра mon_max_pg_per_osd 250. То есть не более 250 на один OSD. Я не стал менять этот дефолтный параметр, а просто установил количество pg_num 64. Более подробная формула есть на официальном сайте — https://ceph.com/pgcalc/.
Существует проблема выделения pg и состоит она в том, что у нас в кластере обычно несколько пулов. Как распределить pg между ними? В общем случае поровну, но это не всегда эффективно, потому что в каждом пуле может храниться разное количество и типов данных. Поэтому для распределения pg по пулам стараются учитывать их размеры. Для этого тоже есть примерная формула — pg_num_pool = Total PGs * % of SizeofPool/TotalSize.
Количество PG можно изменять динамически. К примеру, если вы добавили новые OSD, то вы можете увеличить и количество PG в кластере. В последней версии ceph, которая еще не lts, появилась возможность уменьшения Placement Groups.
Установка ceph
Запускаем установку Ceph с помощью playbook ansible.
Если вы используете авторизацию по паролю, то скорее всего получите ошибку подключения к ssh. Я с этим столкнулся. Когда вывел расширенный лог ошибок плейбука, увидел, что ansible подключается по ssh с использованием публичного ключа, который я не задаю. Изменить это можно в конфиге ansible.cfg, который лежит в корне репозитория. Находим там строку:
и удаляем параметр для publickey, чтобы получилось вот так:
После этого заново запускайте развертывание ceph. Оно должно пойти без ошибок. В конце увидите примерно такое сообщение.
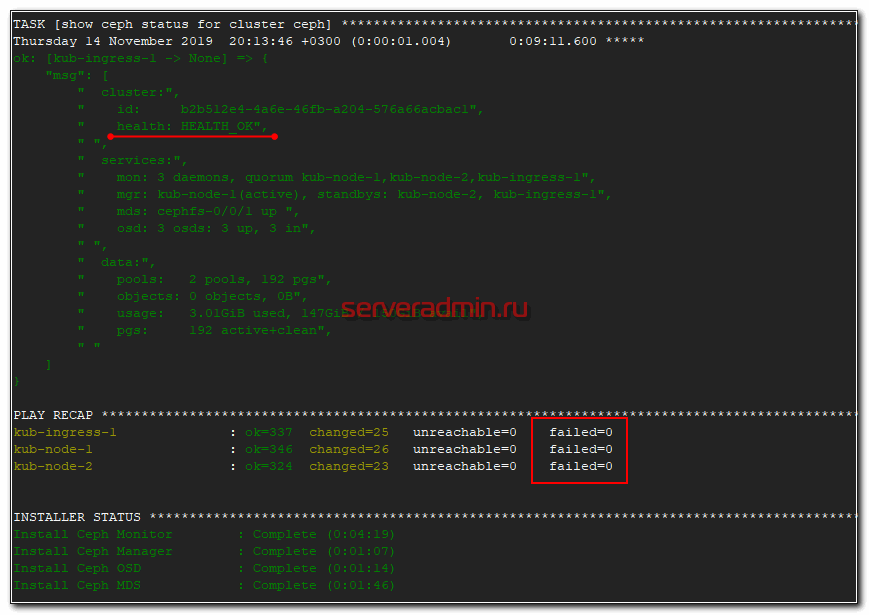
Если будут какие-то ошибки и счетчик failed не будет равен нулю, то разбирайте ошибки, исправляйте их и запускайте роль заново, пока она не закончится без ошибок.
После установки Ceph, можно проверить статус кластера командой, которую нужно выполнить на одной из нод кластера.
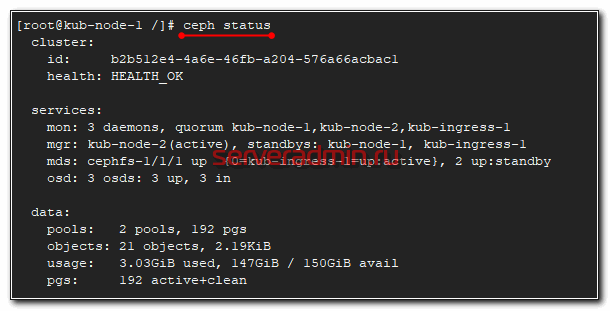
Вы должны увидеть примерно то же самое, что на скриншоте выше. 3 монитора работают в кворуме, друг друга видят, все хорошо.
Менеджеры работают в режиме активный и ждущие — 1 активен, остальные ожидают.
3 Гб данный ceph занял под свои нужды. Так же нужно учитывать, что доступное пространство в 150 Гб это общее пространство кластера, которое будет расходоваться в зависимости от заданной репликации. Записать 150 Гб данных туда не получится. Если мы запишем 1 Гб данных, они реплицируются на все ноды и будут реально занимать 3 Гб в кластере.
Кластер ceph установлен. Дальше разберем, как с ним работать.
Основные команды
Пройдемся по основным командам ceph, которые вам пригодятся при эксплуатации кластера. Основная — обзор состояния кластера:
Традиционный ключ -w к команде для отслеживания изменений в реальном времени:
Посмотреть список пулов в кластере:
Статистика использования кластера:
Список всех ключей учетных записей кластера:
Просмотр дерева OSD:
Создание или удаление OSD:
Создание или удаление пула:
Тестирование производительности OSD:
Использование кластера ceph
Для начала давайте посмотрим, какие пулы у нас уже есть в кластере ceph.
Это дефолтные пулы для работы cephfs, которые были созданы в момент установки кластера. Сейчас подробнее на этом остановимся. Ceph представляет для клиента различные варианты доступа к данным:
- файловая система cephfs;
- блочное устройство rbd;
- объектное хранилище с доступом через s3 совместимое api.
Я рассмотрю два принципиально разных варианта работы с хранилищем — в виде cephfs и rbd. Основное отличие в том, что cephfs позволяет монтировать один и тот же каталог с данными на чтение и запись множеству клиентов. RBD же подразумевает монопольный доступ к выделенному хранилищу. Начнем с cephfs. Для этого у нас уже все готово.
Подключение Cephfs
Как я уже сказал ранее, для работы cephfs у нас уже есть pool, который можно использовать для хранения данных. Я сейчас подключу его к одной из нод кластера, где у меня есть административный доступ к нему и создам в пуле отдельную директорию, которую мы потом смонтируем на другой сервер.
В данном случае 10.1.4.32 адрес одного из мониторов. Их надо указывать все три, но сейчас я временно подключаю пул просто чтобы создать в нем каталог. Достаточно и одного монитора. Я использую команду:
для того, чтобы получить ключ пользователя admin. С помощью такой конструкции он нигде не засвечивается, а сразу передается команде mount. Проверим, что у нас получилось.
Смонтировали pool. Его размер получился 47 Гб. Напоминаю, что у нас в кластере 3 диска по 50 Гб, фактор репликации 3 и 3 гб заняты под служебные нужды. По факту у нас есть 47 Гб свободного места для использования в кластере ceph. Это место делится поровну между всеми пулами. К примеру, когда у нас появятся rbd диски, они будут делить этот размер вместе с cephfs.
Создаем в cephfs директорию data1, которую будем монтировать к другому серверу.
Теперь нам нужно создать пользователя для доступа к этой директории.
На выходе получите ключ от пользователя. Что я сделал в этой команде:
- Создал клиента data1;
- Выставил ему права к разным сущностям кластера (mon, mds, osd);
- Дал права на запись в директорию data1 в cephfs.
Если забудете ключ доступа, посмотреть его можно с помощью команды:
Теперь идем на любой другой сервер в сети, который поддерживает работу с cephfs. Это практически все современные дистрибутивы linux. У них поддержка ceph в ядре. Монтируем каталог кластера ceph, указывая все 3 монитора.
Проверяем, что получилось.
Каталог data1 на файловой системе cephfs подключен. Можете попробовать на него что-то записать. Этот же файл вы должны увидеть с любого другого клиента, к которому подключен этот же каталог.
Теперь настроим автомонтирование диска cephfs при старте системы. Для этого надо создать конфиг файл /etc/ceph/data1.secret следующего содержания.
Это просто ключ пользователя data1. Добавляем в /etc/fstab подключение диска при загрузке.
Не забудьте в конце файла fstab сделать переход на новую строку, иначе сервер у вас не загрузится. Теперь проверим, все ли мы сделали правильно. Если у вас уже смонтирован диск, отмонтируйте его и попробуйте автоматически смонтировать на основе записи в fstab.
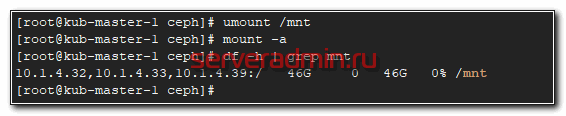
На этом по поводу cephfs все. Можно пользоваться. Переходим к блочным устройствам rbd.
Ceph RBD
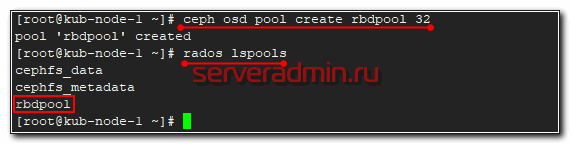
Теперь давайте создадим rbd диск в кластере ceph и подключим его к целевому серверу. Для этого идем в консоль на любую ноду кластера. Создаем pool для rbd дисков.
| rbdpool | название пула, может быть любым |
| 32 | 32 — кол-во pg (placement groups) в пуле |
Проверим список пулов кластера.
Создаем в этом пуле rbd диск на 10G.
Добавим пользователя с разрешениями на использование этого пула. Делается точно так же, как в случае с cephfs, что мы проделали ранее.
В консоли увидите ключ пользователя rbduser для подключения пула rbdpool.
Перемещаемся на целевой сервер, куда мы будем подключать rbd диск кластера ceph. Для подключения blockdevice нам необходимо поставить программное обеспечение из репозитория ceph-luminous на сервер, где будет использоваться rbd.
Так же запишем на целевой сервер ключ клиента, который имеет доступ к пулу с дисками. Создаем файл /etc/ceph/ceph.client.rbduser.keyring следующего содержания.
Там же создаем конфигурационный файл /etc/ceph/ceph.conf, где нам необходимо указать ip адреса мониторов ceph.
Пробуем подключить блочное устройство.
Скорее всего получите такую же или подобную ошибку. Суть ее в том, что текущее ядро поддерживает не все возможности образа RBD, поэтому их нужно отключить. Как это сделать показано в подсказке. Для отключения нужен администраторский доступ в кластер. Так что идем на любую ноду пула и выполняем там предложенную команду.
Не должно быть никаких ошибок, как и любого вывода после работы команды. Возвращаемся на целевой сервер и пробуем подключить rbd диск еще раз.
Все в порядке. В системе появился новый диск — /dev/rbd0. Создадим на нем файловую систему и подмонтируем к серверу.
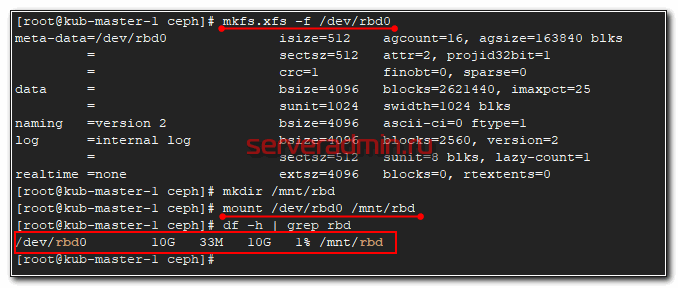
Можно попробовать туда что-то записать и посмотреть на скорость.
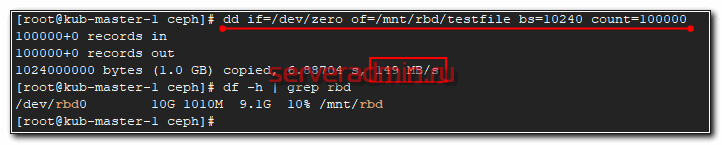
Не знаю, что я измерил 🙂 На самом деле это скорость одиночного sata диска, на котором установлена система сервера, которому я подключил диск. Так понимаю, запись вся ушла в буфер, а потом началась синхронизация по кластеру.
Настроим теперь автоматическое подключение rbd диска при старте системы. Для начала надо настроить mapping диска. Для этого создаем конфиг файл /etc/ceph/rbdmap следующего содержания.
Запускаем скрипт rbdmap и добавляем в автозапуск.
Осталось добавить монтирование блочного устройства rbd в /etc/fstab.
И не забудьте в конце сделать переход на новую строку. После этого перезагрузите сервер и проверьте, что rbd диск кластера ceph нормально подключается.
Проверка надежности и отказоустойчивости
Расскажу, какие проверки отказоустойчивости ceph делал я. Напомню, что у меня кластер состоит всего из трех нод, да еще на sata дисках на двух разных гипервизорах. Многого тут не натестируешь 🙂 Диски собраны в raid1, никакой нагрузки помимо ceph на серверах не было. Я просто выключал одну ноду. При этом в работе кластера не было никаких заметных изменений. С ним можно было нормально работать, писать и читать данные. Самое интересное начиналось, когда я запускал обратно выключенную ноду.
В этот момент запускался ребалансинг кластера и он начинал жутко тормозить. Настолько жутко, что в эти моменты я даже не мог зайти на ноды по ssh или напрямую с консоли, чтобы посмотреть, что именно там тормозит. Виртуальные машины вставали колом. Я пытался их отключать и включать по очереди, но ничего не помогало. В итоге я выключил все 3 ноды и стал включать их по одной. Очевидно, что и нагрузки никакой я не давал, так как кластер был не в состоянии обслуживать внешние запросы.
Включил сначала одну ноду, убедился, что она загрузилась и показывает свой статус. Запустил вторую. Дождался, когда полностью синхронизируются две ноды, потом включил третью. Только после этого все вернулось в нормальное состояние. При этом никаких действий с кластером я не производил. Только следил за статусом. Он сам вернулся в рабочее состояние. Данные все оказались на месте. Меня это приятно удивило, с учетом того, что я жестко выключал зависшие виртуалки несколько раз.
Как я понял, если у вас есть возможность снять с кластера нагрузку, то в момент деградации особых проблем у вас не будет. Это актуально для кластеров с холодными данными, например, под бэкапы или другое долгосрочное хранение. Там можно тормознуть задачи и дождаться ребаланса. Особых проблем с эксплуатацией ceph быть не должно. А вот если у вас идет постоянная работа с кластером, то вам нужно все внимательно проектировать, изучать, планировать, тестировать и т.д. Точно должен быть еще один тестовый кластер и доскональное понимание того, что вы делаете.
Заключение
Надеюсь, моя статья про описание, установку и эксплуатацию ceph была полезна. Постарался объяснять все простым языком для тех, кто как и я, только начинает знакомство с ceph. Мне система очень понравилась именно тем, что ее можно так легко разворачивать и масштабировать. Берешь обычные серверы, раскатываешь ceph, ставишь фактор репликации 3 и не переживаешь за свои данные. Думаю, использовать его под бэкапы, docker registry или некритичное видеонаблюдение.
Переживать начинаешь, когда в кластер идет непрерывная высокая нагрузка. Но тут, как и в любых highload проектах, нет простых решений. Надо во все вникать, во всем разбираться и быть всегда на связи. Меня не привлекают такие перспективы 🙂
Источник



