- Linux/UNIX: Bash Read a File Line By Line
- Syntax: Read file line by line on a Bash Unix & Linux shell:
- How to Read a File Line By Line in Bash
- How to use command/process substitution to read a file line by line
- Using a here strings
- How to file descriptor with read command
- Examples that shows how to read file line by line
- Bash Scripting: Read text file line-by-line to create pdf files
- Read from bash shell variable
- Conclusion
- 5 Commands to View the Content of a File in Linux Command Line
- 5 commands to view files in Linux
- 1. Cat
- 3. Less
- 4. Head
- 5. Tail
- Bonus: Strings command
Linux/UNIX: Bash Read a File Line By Line
Syntax: Read file line by line on a Bash Unix & Linux shell:
| Tutorial details | |
|---|---|
| Difficulty level | Easy |
| Root privileges | No |
| Requirements | Bash/ksh/zsh/tcsh |
| Est. reading time | 10m |
- The syntax is as follows for bash, ksh, zsh, and all other shells to read a file line by line
- while read -r line; do COMMAND; done
- The -r option passed to read command prevents backslash escapes from being interpreted.
- Add IFS= option before read command to prevent leading/trailing whitespace from being trimmed —
- while IFS= read -r line; do COMMAND_on $line; done
How to Read a File Line By Line in Bash
Here is more human readable syntax for you:
The input file ( $input ) is the name of the file you need use by the read command. The read command reads the file line by line, assigning each line to the $line bash shell variable. Once all lines are read from the file the bash while loop will stop. The internal field separator (IFS) is set to the empty string to preserve whitespace issues. This is a fail-safe feature.
- No ads and tracking
- In-depth guides for developers and sysadmins at Opensourceflare✨
- Join my Patreon to support independent content creators and start reading latest guides:
- How to set up Redis sentinel cluster on Ubuntu or Debian Linux
- How To Set Up SSH Keys With YubiKey as two-factor authentication (U2F/FIDO2)
- How to set up Mariadb Galera cluster on Ubuntu or Debian Linux
- A podman tutorial for beginners – part I (run Linux containers without Docker and in daemonless mode)
- How to protect Linux against rogue USB devices using USBGuard
Join Patreon ➔
How to use command/process substitution to read a file line by line
Process or command substitution means nothing more but to run a shell command and store its output to a variable or pass it to another command. The syntax is:
Using a here strings
How to file descriptor with read command
The syntax is simple:
Here is a sample script:
Examples that shows how to read file line by line
Here are some examples:
The same example using bash shell:
You can also read field wise:
Fig.01: Bash shell scripting- read file line by line demo outputs
Bash Scripting: Read text file line-by-line to create pdf files
My input file is as follows (faq.txt):
Read from bash shell variable
Let us say you want a list of all installed php packages on a Debian or Ubuntu Linux, enter:
You can now read from $list and install the package:
Conclusion
This page explained how to read file line by line in bash shell script.
🐧 Get the latest tutorials on Linux, Open Source & DevOps via
| Category | List of Unix and Linux commands |
|---|---|
| Documentation | help • mandb • man • pinfo |
| Disk space analyzers | df • duf • ncdu • pydf |
| File Management | cat • cp • less • mkdir • more • tree |
| Firewall | Alpine Awall • CentOS 8 • OpenSUSE • RHEL 8 • Ubuntu 16.04 • Ubuntu 18.04 • Ubuntu 20.04 |
| Linux Desktop Apps | Skype • Spotify • VLC 3 |
| Modern utilities | bat • exa |
| Network Utilities | NetHogs • dig • host • ip • nmap |
| OpenVPN | CentOS 7 • CentOS 8 • Debian 10 • Debian 8/9 • Ubuntu 18.04 • Ubuntu 20.04 |
| Package Manager | apk • apt |
| Processes Management | bg • chroot • cron • disown • fg • glances • gtop • jobs • killall • kill • pidof • pstree • pwdx • time • vtop |
| Searching | ag • grep • whereis • which |
| Shell builtins | compgen • echo • printf |
| Text processing | cut • rev |
| User Information | groups • id • lastcomm • last • lid/libuser-lid • logname • members • users • whoami • who • w |
| WireGuard VPN | Alpine • CentOS 8 • Debian 10 • Firewall • Ubuntu 20.04 |
Comments on this entry are closed.
The bash example is correct for all shells. The ksh example is not correct; it will strip leading and trailing whitespace.
To demonstrate, use:
on a file with leading and/or trailing whitespace on one or more .
The BASH password file parsing example does not work for my centos 7 box: all the colons are stripped from each line and the whole line without colons is stored in f1
my output reads:
Username: root/root/bin/bash, Home directory: , Shell:
Reading a file line by line with a single loop is fine in 90% of the cases.
But if things get more complicated then you may be better off opening the file as a file descriptor.
Situations such as:
* the read of the file is only a minor aspect and not the main task, but you want to avoid opening an closing the file multiple times. For example preserving where you have read up to or avoiding file closure (network, named pipes, co-processing)
* the file being read requires different methods of parsing, that is better done in simpler but different loops. Reading emails (header and body) is an example of this, but so is reading files with separate operational and data blocks.
* you are reading from multiple files at the same time, and switching between different files, in a pseudo-random way. That is you never quite know whch file you will need to read from next.
I have a scenario like this. I have a file which has servername, port and ipaddress
svr1
port1
ip1
svr2
port2
ip2
…
…
I tried couple of ways reading these records and assigning them a field and print the output to a file like below but nothing is helpful
servername port ipaddress
svr1 port1 ip1
scr2 port2 ip2
and so on
can someone please help me.
I figured it out. May be not professional but it is working for me.
if the file is 100% predictable in each host,ip,port coming in groups of 3 you can use “paste”
cat list.txt | paste – – –
HOW DO YOU SPLIT INPUT INTO FIELDS FOR PROCESSING?
I have a question concerning how you’d actually process individual fields of input.
For example, let’s say you’re doing the usual
while read LINE; do
process the statements
done firstbyteinq and looking at firstbyteinq with a read, but 1). the cut doesn’t seem to be doing it just to the record being read, it does it to ALL the records all at one time; 2). the read of the firstbyteinq then advances the other file one record.
It seems to me there ought to be some way to “declare” the positions from a to b as fields and THEN use the while read, but I’m not sure how to do that.
I’ll try anything. Thanks VERY much in advance.
princess anu, there’s no need to use arithmetic; just read the file in groups of three lines:
A correction; you need to check that the read succeeded; checking the first should be enough:
I have scenario :
One file which contain values like:
ABS
SVS
SGS
SGS
another file is template which has to use values from 1st file (One value at a time, line by line )
ARGS=ABS >> save in one file
New file:
ARGS=SVS >> save in another file
Can you please help me to achive this
u can use paste command if the fields are same …..and then output the records to the other file and print another.
rm 3 4 5
first=1
seco=2
cat 1 | while read l
do
echo “$l =” >> 3
done
paste 3 2 | while read line
do
echo “$line” >> 4
done
awk ‘
now u can move the records line by line to another file
echo “$line” # Chris F.A. Johnson Jul 3, 2013 @ 11:40
Some shells shells will output -n; that is what POSIX requires.
My while/read is having an issue with the data not being printed for the last line read.
The info is read and summed but is not being printed to the report.
The script is reading a file with tab delimited fields, sorting on a field then reading each line while assigning the fields to var names.
If statements determine whether the numbers are summed or if a new category is found with the previous categories data being written to the report. All categories except the last are complete in the report. The last category is left out.
I added trouble shooting echo statements to check the workflow and they showed that the last category is being read and summed but it doesnt get printed.
It’s as if the read gets to the last line, does the work and then doesnt know what to do with the output.
The sorted data looks something like:
Code with troubleshooting echos and most comments deleted:
The read name is different than the last line (new category)
cat | sort -k3 | while read -r Count IP Name
sort -k3 | while read -r Count IP Name
It is also possible to store the elements in a bash array using the -a option
The following example reads some comma separated values and print them in reverse order:
input.txt
Hi guys. I’m just getting started with scripting and I am needing some help reading a file into the script. This shell script below works and does what it needs to do but I have to manually input the file name for “read list”. How do I modify this script to automatically read the file. Inside the file is just a list of aix server names.
#!/usr/bin/sh
echo ” Please input the master list you know to use”
read list
for i in `cat $list`
do
ssh $i hostname
ssh $i df
done
Hi all,
I need to write a script to look for user in /etc/passwd file. The program takes user input from command line and check to see if the user that the person entered exists. If user doesn’t exist, the script sends error message. I use grep to print the user which exist. But not sure what command to use and look and if the user doesn’t exist, send error message?
Thanks,
Hi stone,
me trying to get the list of server have /mysqlshare file system in it but i am unable to get it..
for now trying get only 2 server details from txt file ie(text.txt) which have
server1_name
server2_name
when i try this script its only reading 1st server details and getting exit from script
Can someone help me out..
can anyone help me to include the line number while read line by line ,
Источник
5 Commands to View the Content of a File in Linux Command Line
If you are new to Linux and you are confined to a terminal, you might wonder how to view a file in the command line.
Reading a file in Linux terminal is not the same as opening file in Notepad. Since you are in the command line mode, you should use commands to read file in Linux.
Don’t worry. It’s not at all complicated to display a file in Linux. It’s easy as well essential that you learn how to read files in the line.
Here are five commands that let you view the content of a file in Linux terminal.
5 commands to view files in Linux
Before you how to view a file in Unix like systems, let me clarify that when I am referring to text files here. There are different tools and commands if you want to read binary files.
1. Cat
This is the simplest and perhaps the most popular command to view a file in Linux.
Cat simply prints the content of the file to standard display i.e. your screen. It cannot be simpler than this, can it?
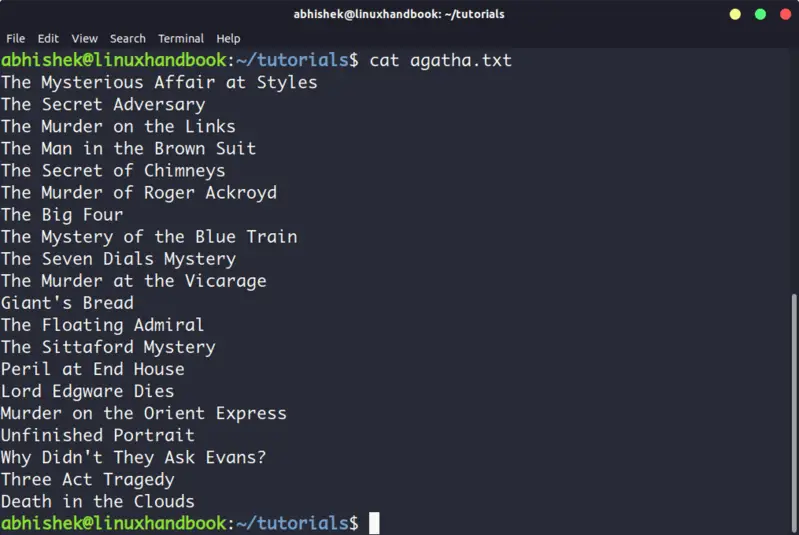 cat displays the content of the file on the screen
cat displays the content of the file on the screen
Cat becomes a powerful command when used with its options. I recommend reading this detailed tutorial on using cat command.
The problem with cat command is that it displays the text on the screen. Imagine if you use cat command with a file that has 2000 lines. Your entire screen will be flooded with the 200 lines and that’s not the ideal situation.
So, what do you do in such a case? Use less command in Linux (explained later).
The nl command is almost like the cat command. The only difference is that it prepends line numbers while displaying the text in the terminal.
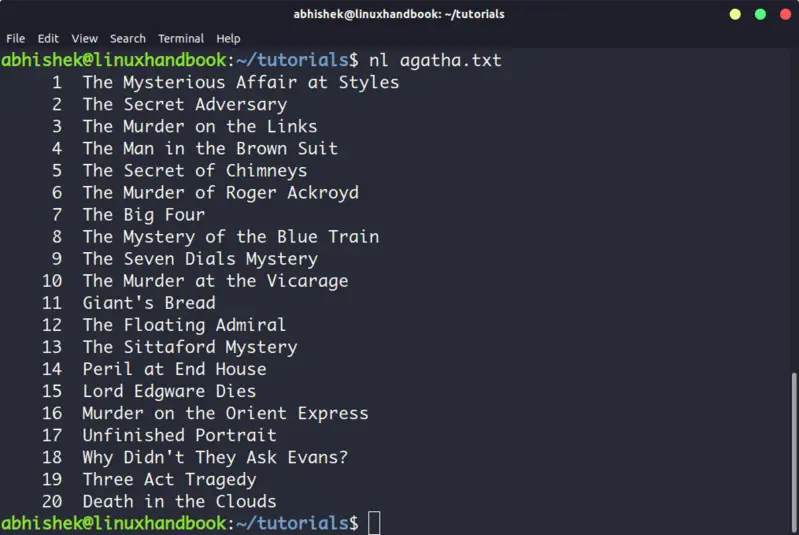 nl command displays text with line numbers
nl command displays text with line numbers
There are a few options with nl command that allows you to control the numbering. You can check its man page for more details.
3. Less
Less command views the file one page at a time. The best thing is that you exit less (by pressing q), there are no lines displayed on the screen. Your terminal remains clean and pristine.
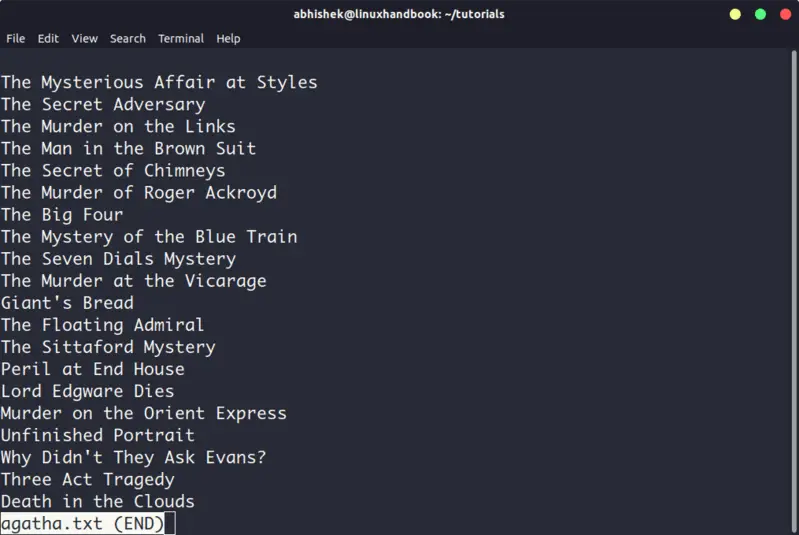
I strongly recommend learning a few options of the Less command so that you can use it more effectively.
There is also more command which was used in olden days but less command has more friendly features. This is why you might come across the humorous term ‘less is more’.
4. Head
Head command is another way of viewing text file but with a slight difference. The head command displays the first 10 lines of a text file by default.
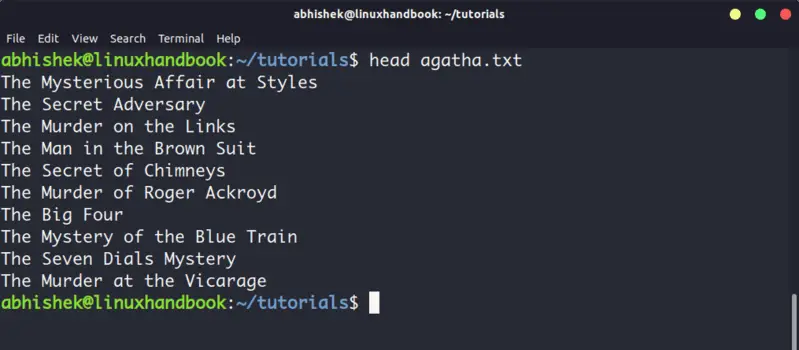
You can change this behavior by using options with head command but the fundamental principle remains the same: head command starts operating from the head (beginning) of the file.
5. Tail
Tail command in Linux is similar and yet opposite to the head command. While head command displays file from the beginning, the tail command displays file from the end.
By default, tail command displays the last 10 lines of a file.
Head and Tail commands can be combined to display selected lines from a file. You can also use tail command to see the changes made to a file in real time.
Bonus: Strings command
Okay! I promised to show only the commands for viewing text file. And this one deals with both text and binary files.
Strings command displays the readable text from a binary file.
No, it doesn’t convert binary files into text files. If the binary file consists of actual readable text, strings command displays those text on your screen. You can use the file command to find the type of a file in Linux.
Conclusion
Some Linux users use Vim to view the text file but I think that’s overkill. My favorite command to open a file in Linux is the less command. It leaves the screen clear and has several options that makes viewing text file a lot easier.
Since you now know ways to view files, maybe you would be interested in knowing how to edit text files in Linux. Cut and Paste are two such commands that you can use for editing text in Linux terminal. You may also read about creating files in Linux command line.
Источник



