- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Курс по сетям
- Разбираемся с Jenkins. Что это?
- Настройка и использование Docker Compose
- Разбираемся с Docker: установка и использование
- Caddy: установка и настройка веб сервера
- 8 лучших панелей управления веб-хостингом
- ELK (ElasticSearch, LogStash, Kibana): базовая настройка
- Настройка и использование Docker Compose
- Redis – что это и для чего?
- Redis как база данных
- Примеры использования
- Redis
- Быстрое хранилище данных в памяти с открытым исходным кодом для использования в качестве базы данных, кэша, брокера сообщений или очереди.
- Что такое Redis?
- Как работает Redis?
- Сравнение Redis и MemCached
- Новые возможности в Redis 5.0
- Преимущества Redis
- Хранилище данных в памяти
- Гибкие структуры данных
- Простота и удобство
- Репликация и постоянное хранение
- Высокая доступность и масштабируемость
- Возможность расширения
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Популярное и похожее
Курс по сетям

Разбираемся с Jenkins. Что это?
Настройка и использование Docker Compose
Разбираемся с Docker: установка и использование
Caddy: установка и настройка веб сервера
8 лучших панелей управления веб-хостингом
ELK (ElasticSearch, LogStash, Kibana): базовая настройка
Настройка и использование Docker Compose
Еженедельный дайджест
Redis – что это и для чего?
Еще немного про open source
Друг, начнем с цитаты:
Обучайся в Merion Academy
Пройди курс по сетевым технологиям
Начать
Redis – это высокопроизводительная БД с открытым исходным кодом (лицензия BSD), которая хранит данные в памяти, доступ к которым осуществляется по ключу доступа. Так же Редис это кэш и брокер сообщений.
Надо признаться, определение не дает точного понимания, что же такое Redis. Если это так круто, то зачем вообще нужны другие БД? На самом деле, Redis правильнее всего использовать в определенных кейсах, само собой, зная про подводные камни – именно об этом и поговорим.
Про установку Redis в CentOS 8 мы рассказываем в этой статье.
Redis как база данных
Говорим про случай, когда Redis выступает в роли базы данных:
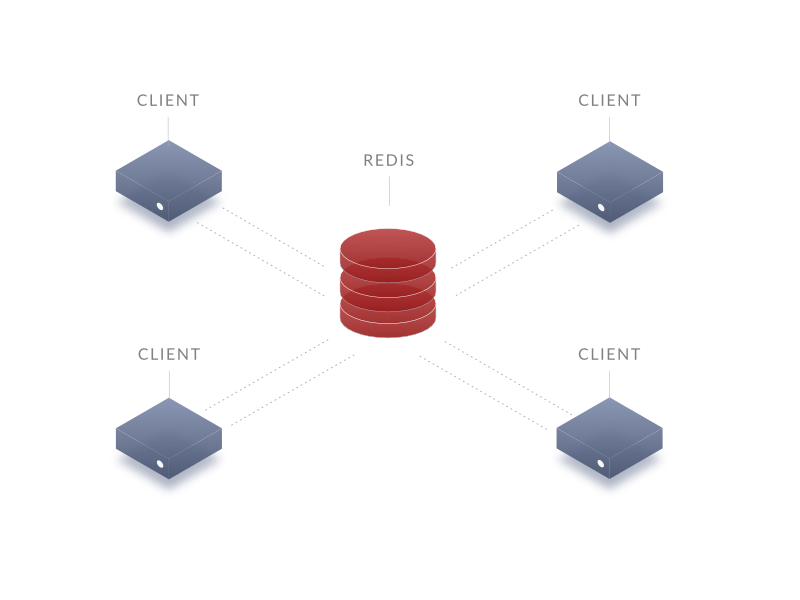
Пару слов про ограничения такой модели:
- Размер БД ограничен доступной памятью
- Шардинг (техника масштабирования) ведет к увеличению задержки
- Это NoSQL — никакого языка SQL
- LUA скриптинг в качестве альтернативы
- Это нереляционная СУБД!
- Нет сегментации на пользователей или группы пользователей. Отсутствует контроль доступа
- Доступ по общему паролю. Что скажут ваши безопасники?
Теперь про преимущества модели:
- Скорость
- Хранение данных в памяти делает быстрее работу с ними
- Скрипты на LUA
- Выполнение прямо в памяти, опять же, ускоряет работу
- Удобные форматы запросов/данных
- Geospatial – геоданные (высота, ширина, долгота и так далее)
- Hyperloglog – статистическе алгоритмы
- Hash – если коротко, то хэш в Redis делают между строковыми полями и их значениями
- Алгоритмы устаревания данных
Примеры использования
Представь, у нас есть приложение, где пользователям необходимо авторизоваться, чтобы выполнять какие – либо действия внутри приложения. Каждый раз, когда мы обновляем авторизационные данные клиента, мы хотим их получать для последующего контроля.
Мы могли бы отправлять лист авторизационных параметров (с некими номерами авторизаций, сроком действия с соответствующими подписями), чтобы каждое действие внутри приложения, сопровождалось авторизацонной транзакцией из листа, который мы прислали клиенту. С точки зрения безопасности, в этом подходе нет ничего плохого, если мы храним на своей стороне данные в безопасности и используем Javascript Object Signing and Encryption (JOSE), например. Но проблема появится в том случае, когда наш пользователь имеет более одной авторизации внутри приложения – такие схемы плохо поддаются масштабированию.
А что если вместо отправки листа авторизационных параметров, мы сохраним его у себя, а пользователю отправим некий токен, который они должны отправлять для авторизации? Далее, по этому токену, мы легко сможем найти авторизации юзера. Это делает систему гораздо масштабируемой. Redis, такой Redis.
Итого, для указанной выше схемы, мы хотим:
- Скорость
- Мы не хотим, чтобы пользователь долго ожидал авторизации
- Масштабирумость системы
- Сопоставление ключа (токена) с авторизациями юзера
А вот, что на эти вызовы может ответить Redis:
- Redis хранит данные в памяти – он быстрый.
- Redis можно кластеризовать через компонент Sentinel. Масштабируемость? Пожалуйста.
- В Redis куча вариантов хранения списков. Самый простой будет являться набором данных.
В качестве бонуса от Redis, вы получите механизм экспайринга токенов (устаревания). Все будет работать.
Redis как кэш!
Redis почти заменил memcached в современных приложениях. Его фичи делают супер – удобным кэширование данных.
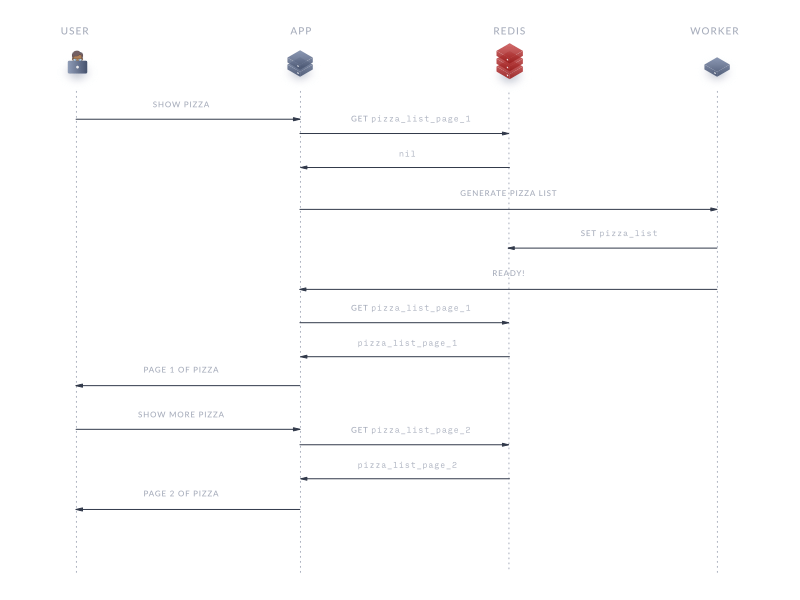
- Значения не могут превышать 512 МБ
- Отсутствует искусственный интеллект, который будет очищать ваше хранилище данных
- Совместное использование кэша разными сервисами по сети
- Удобные фичи, такие как LUA скриптинг, который упрощает работы с кэшом
- Временные ограничения для данных
Еще один кейс
Предположим, перед нами такая задача: приложение, отображает пользователям данные с определенными значениями, которые можно сортировать по множеству признаков. Все наши данные хранятся в БД (например, MySQL) и показывать отсортированные данные нужно часто. Дергать БД каждый раз весьма тяжело и ресурсозатратно, а значит, нам нужно кэшировать данные в отсортированном порядке.
Окей, кейс понятен. Рэдис, что скажешь на такие требования?
- Кэш должен хранить сортированные наборы данных
- Нам нужно вытаскивать наборы данных внутри наборов данных (для пагинации, например, то есть для переключения между страницами)
- Это должно быть быстрее, чем пересчет данных с нуля
Что скажет Redis:
- Хранить наборы данных — легко
- Может вытаскивать сабсеты из наборов — легко
- Конечно быстрее. Ведь данные хранятся в памяти
Redis как брокер сообщений
Редис может выступать в качестве брокера сообщений. Схема обычная и весьма базовая — publish–subscribe (pub/sub), или как можно перевести на русский язык «Издатель — подписчик».
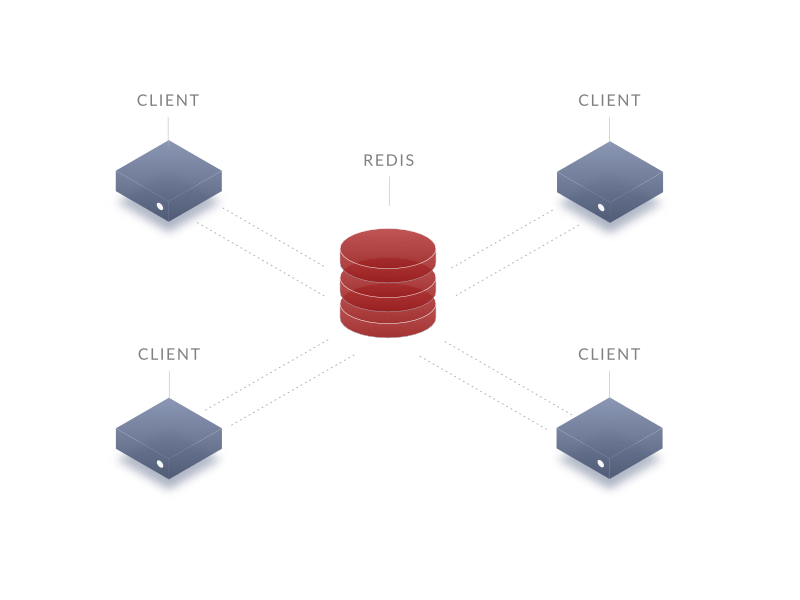
Как и раньше, давайте обсудим плюсы и минусы, хотя их тут и не так много. Минусы:
- Только тривиальная модель pub/sub
- Отсутствие очередей сообщений
Ну а плюсы, как обычно для Редиса – скорость и стабильность.
Кейс напоследок
Простой пример – коллаборация сотрудников одной компании. Предположим, у них есть приложение, где они работают над общими задачами. Каждый пользователь делает свой набор действий, о котором другие пользователи должны знать. А так же, юзеры могут иметь разные экземпляры приложений – десктоп, мобильный или что то еще.
Требования по этой задаче:
- Низкая задержка
- Мы не хотим иметь трудности в процессе совместной работы сотрудников
- Стабильная работа и непрерывность
- Масштабирование
- Кампания растет и развивается
Редис, твой выход!
- Низкая задержка – да, говорили об этом ранее
- Стабильность – минимальное количество точек отказа в Redis
- Стабильная работа и непрерывность
- Масштабирование – сделаем кластер, нет проблем.
Выводы
Redis — крутая штука, которая позволяет объединять сервисы и следовать 12 принципам приложений. Для приложений, в которых нагрузка ориентирована на быстрое изменение наборов данных и высокая безопасность данных не имеет завышенных требований – Redis прекрасный выбор.
Если данные нуждаются в усиленной защите, Редис подойдет в меньшей степени, лучше посмотрите в сторону MongoDB или Elasticsearch.
Redis
Быстрое хранилище данных в памяти с открытым исходным кодом для использования в качестве базы данных, кэша, брокера сообщений или очереди.
Что такое Redis?
Redis (расшифровывается как Remote Dictionary Server) – это быстрое хранилище данных типа «ключ‑значение» в памяти с открытым исходным кодом для использования в качестве базы данных, кэша, брокера сообщений или очереди. Проект возник, когда Сальваторе Санфилиппо, первоначальный разработчик Redis, пытался улучшить масштабируемость стартапа в Италии. Redis обеспечивает время отклика на уровне долей миллисекунды и позволяет приложениям, работающим в режиме реального времени, выполнять миллионы запросов в секунду. Такие приложения востребованы в сфере игр, рекламных технологий, финансовых сервисов, здравоохранения и IoT. Redis широко применяется для кэширования, управления сеансами, разработки игр, создания таблиц лидеров, аналитики в режиме реального времени, работы с геопространственными данными, поддержки служб такси, чатов и сервисов обмена сообщениями, потоковой передачи мультимедиа и приложений с отправкой сообщений по модели «издатель – подписчик» (Pub/Sub).

*Новая публикация в блоге*: Redis Cluster 101
Как работает Redis?
Все данные в Redis хранятся в памяти, а не на дисках или твердотельных накопителях, как в других базах данных. Поскольку Redis, как и другие хранилища данных в памяти, не нуждается в доступе к диску, это исключает задержки, связанные с поиском, и обеспечивает доступ к данным за микросекунды. В число возможностей Redis входит поддержка разнообразных структур данных, обеспечение высокой доступности, работа с геопространственными данными, создание скриптов Lua, проведение транзакций, постоянное хранение данных на диске и поддержка кластеров. Все это упрощает создание приложений, работающих в режиме реального времени в масштабе всего Интернета.
Сравнение Redis и MemCached
Как Redis, так и MemCached представляют собой хранилища данных в памяти с открытым исходным кодом. Высокопроизводительный сервис кэширования с распределенной памятью Memcached отличает простота, а Redis обладает широкими функциональными возможностями, которые позволяют эффективно использовать хранилище для разнообразных целей. Подробное сравнение функций, которое поможет вам принять решение, см. по ссылке Сравнение Redis и Memcached. Они используются с реляционными базами данных или базами данных на основе пар «ключ – значение», такими как MySQL, Postgres, Aurora, Oracle, SQL Server, DynamoDB и многими другими, для повышения производительности.
Новые возможности в Redis 5.0
Redis 5, а теперь уже Redis 5.0.3, – это последняя общедоступная версия Redis с открытым исходным кодом. С момента первого выпуска в 2009 г. система Redis с открытым исходным кодом превратилась из технологии кэширования в простое в использовании и быстрое хранилище данных в памяти с универсальными структурами данных и временем отклика на уровне долей миллисекунды. Главной вехой для Redis стал выпуск версии 5.0, в которую вошел целый ряд улучшений и усовершенствований. Основным нововведением стало внедрение функции Streams – первой совершенно новой структуры данных в Redis после HyperLogLog. В этом выпуске также добавлены команды для структур данных Sorted Set и новые возможности для API модуля.

Полностью управляемый сервис Redis с возможностью шифрования, изменения размера работающего кластера, обеспечения высокой доступности и соответствия требованиям.
Преимущества Redis
Хранилище данных в памяти
Все данные Redis находятся в основной памяти сервера, в отличие от таких баз данных, как PostgreSQL, Cassandra, MongoDB и других, которые большую часть данных хранят на магнитных дисках или SSD‑накопителях. По сравнению с традиционными дисковыми базами данных, требующими циклического обращения к диску для большинства операций, хранилища данных в памяти, такие как Redis, свободны от этого ограничения. Благодаря этому многократно увеличивается количество выполняемых операций и сокращается время отклика. В результате обеспечивается чрезвычайно высокая производительность. Операции чтения или записи в среднем занимают менее миллисекунды, скорость работы достигает миллионов операций в секунду.
Гибкие структуры данных
В отличие от упрощенных хранилищ на основе пар «ключ – значение», которые поддерживают ограниченный набор структур данных, Redis поддерживает огромное разнообразие структур данных, позволяющее удовлетворить потребности разнообразных приложений. Типы данных Redis включают:
- строки – текстовые или двоичные данные размером до 512 МБ;
- списки – коллекции строк, упорядоченные в порядке добавления;
- множества – неупорядоченные коллекции строк с возможностью пересечения, объединения и сравнения с другими типами множеств;
- сортированные множества – множества, упорядоченные по значению;
- хэш‑таблицы – структуры данных для хранения списков полей и значений;
- битовые массивы – тип данных, который дает возможность выполнять операции на уровне битов;
- структуры HyperLogLog – вероятностные структуры данных, служащие для оценки количества уникальных элементов в наборе данных.
Простота и удобство
Redis упрощает код, позволяя писать меньше строк для хранения, использования данных и организации доступа к данным в приложениях. К примеру, если приложение содержит данные, хранящиеся в хэш‑таблице, и требуется сохранить эти данные в хранилище, можно просто использовать структуру данных хэш‑таблицы Redis. Решение подобной задачи с использованием хранилища данных, не поддерживающего структуры хэш‑таблиц, потребует написания серьезного объема кода для преобразования данных из одного формата в другой. Redis уже оснащен встроенными структурами данных и предоставляет множество возможностей их комбинирования и взаимодействия с данными клиента. Разработчикам под Redis доступны более ста клиентов с открытым исходным кодом. Поддерживаемые языки программирования включают Java, Python, PHP, C, C++, C#, JavaScript, Node.js, Ruby, R, Go и многие другие.
Репликация и постоянное хранение
В Redis применяется архитектура узлов «ведущий‑подчиненный» и поддерживается асинхронная репликация, при которой данные могут копироваться на несколько подчиненных серверов. Это обеспечивает как улучшенные характеристики чтения (так как запросы могут быть распределены между серверами), так и ускоренное восстановление в случае сбоя основного сервера. Для обеспечения постоянного хранения Redis поддерживает снимки состояния на момент времени (копирование наборов данных Redis на диск).
Высокая доступность и масштабируемость
Redis предлагает архитектуру «ведущий‑подчиненный» с одним ведущим узлом или с кластерной топологией. Это позволяет создавать высокодоступные решения, обеспечивающие стабильную производительность и надежность. Если требуется настроить размер кластера, доступны различные варианты вертикального и горизонтального масштабирования. В результате можно наращивать кластер в соответствии с потребностями.
Возможность расширения
Redis – проект с открытым исходным кодом, поддерживаемый активным сообществом. Поскольку Redis базируется на открытых стандартах, поддерживает открытые форматы данных и имеет множество клиентов, отсутствует вероятность блокировки поставщиком или технологического тупика.



