- Шпаргалка по регулярным выражениям
- Квантификаторы
- Модификаторы
- Спецсимволы
- Спецсимволы внутри символьного класса
- Позиция внутри строки
- Якоря
- Символьные классы
- POSIX
- Утверждения
- Кванторы
- Экранирование в регулярных выражениях
- Спецсимволы экранирования в регулярных выражениях
- Подстановка строк
- Группы и диапазоны
- Модификаторы шаблонов
- Мета-символы
- Регулярные выражения
- /Быть или не быть/ugi ¶
- «Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
- Как правильно писать регулярные выражения ¶
- Практическое применение регулярных выражений ¶
- Ссылки ¶
Шпаргалка по регулярным выражениям
Квантификаторы
| Аналог | Пример | Описание | |
|---|---|---|---|
| ? | a? | одно или ноль вхождений «а» | |
| + | a+ | одно или более вхождений «а» | |
| * | a* | ноль или более вхождений «а» |
Модификаторы
Символ «минус» (-) меред модификатором (за исключением U) создаёт его отрицание.
| Описание | |
|---|---|
| g | глобальный поиск (обрабатываются все совпадения с шаблоном поиска) |
| i | игнорировать регистр |
| m | многострочный поиск. Поясню: по умолчанию текст это одна строка, с модификатором есть отдельные строки, а значит ^ — начало строки в тексте, $ — конец строки в тексте. |
| s | текст воспринимается как одна строка, спец символ «точка» (.) будет вкючать и перевод строки |
| u | используется кодировка UTF-8 |
| U | инвертировать жадность |
| x | игнорировать все неэкранированные пробельные и перечисленные в классе символы |
Спецсимволы
| Аналог | Описание | |
|---|---|---|
| () | подмаска, вложенное выражение | |
| [] | групповой символ | |
| количество вхождений от «a» до «b» | ||
| | | логическое «или», в случае с односимвольными альтернативами используйте [] | |
| \ | экранирование спец символа | |
| . | любой сивол, кроме перевода строки | |
| \d | 7 | десятичная цифра |
| \D | [^\d] | любой символ, кроме десятичной цифры |
| \f | конец (разрыв) страницы | |
| \n | перевод строки | |
| \pL | буква в кодировке UTF-8 при использовании модификатора u | |
| \r | возврат каретки | |
| \s | [ \t\v\r\n\f] | пробельный символ |
| \S | [^\s] | любой символ, кроме промельного |
| \t | табуляция | |
| \w | [0-9a-z_] | любая цифра, буква или знак подчеркивания |
| \W | [^\w] | любой символ, кроме цифры, буквы или знака подчеркивания |
| \v | вертикальная табуляция |
Спецсимволы внутри символьного класса
| Пример | Описание | |
|---|---|---|
| ^ | [^da] | отрицание, любой символ кроме «d» или «a» |
| — | [a-z] | интервал, любой симво от «a» до «z» |
Позиция внутри строки
| Пример | Соответствие | Описание | |
|---|---|---|---|
| ^ | ^a | aaa aaa | начало строки |
| $ | a$ | aaa aaa | конец строки |
| \A | \Aa | aaa aaa aaa aaa | начало текста |
| \z | a\z | aaa aaa aaa aaa | конец текста |
| \b | a\b \ba | aaa aaa aaa aaa | граница слова, утверждение: предыдущий символ словесный, а следующий — нет, либо наоборот |
| \B | \Ba\B | aaa aaa | отсутствие границы слова |
| \G | \Ga | aaa aaa | Предыдущий успешный поиск, поиск остановился на 4-й позиции — там, где не нашлось a |
Скачать в PDF, PNG.
Якоря
Якоря в регулярных выражениях указывают на начало или конец чего-либо. Например, строки или слова. Они представлены определенными символами. К примеру, шаблон, соответствующий строке, начинающейся с цифры, должен иметь следующий вид:
Здесь символ ^ обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, \d соответствует любой цифре от 0 до 9 включительно, \w соответствует буквам и цифрам, а \W — всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит так:
POSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе каждое слово, включающее букву “q”, за которой не следует “werty”».
Приведенный выше код начинается с поиска любых символов, кроме пробела ( [^\s]* ), за которыми следует q . Затем парсер достигает «смотрящего вперед» утверждения. Это автоматически делает предшествующий элемент (символ, группу или символьный класс) условным — он будет соответствовать шаблону, только если утверждение верно. В нашем случае, утверждение является отрицательным ( ?! ), т. е. оно будет верным, если то, что в нем ищется, не будет найдено.
Итак, парсер проверяет несколько следующих символов по предложенному шаблону ( werty ). Если они найдены, то утверждение ложно, а значит символ q будет «проигнорирован», т. е. не будет соответствовать шаблону. Если же werty не найдено, то утверждение верно, и с q все в порядке. Затем продолжается поиск любых символов, кроме пробела ( [^\s]* ).
Кванторы
Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон:
По умолчанию кванторы — «жадные». Поэтому квантор + , означающий «один или больше раз», будет соответствовать максимально возможному значению. Иногда это вызывает проблемы, и тогда вы можете сказать квантору перестать быть жадным (стать «ленивым»), используя специальный модификатор. Посмотрите на этот код:
Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
Приведенный выше шаблон найдет в этой строке вот такую подстроку:
Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание на модификатор ? ) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных кавычках по отдельности:
Экранирование в регулярных выражениях
Регулярные выражения используют некоторые символы для обозначения различных частей шаблона. Однако, возникает проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто использовать « . » в качестве шаблона — это приведет к нахождению практически всего. Итак, вам необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с помощью знака экранирования.
Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»).
Шаблон для нахождения точки таков:
Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Спецсимволы экранирования в регулярных выражениях
| Выражение | Соответствие |
|---|---|
| \ | не соответствует ничему, только экранирует следующий за ним символ. Это нужно, если вы хотите ввести метасимволы !$()*+.<>?[\]^ <|>в качестве их буквальных значений. |
| \Q | не соответствует ничему, только экранирует все символы вплоть до \E |
| \E | не соответствует ничему, только прекращает экранирование, начатое \Q |
Подстановка строк
Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке.
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона из другой его части; а также при подстановке строк.
Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»:
Если в регулярном выражении необходимо сослаться на какую-то из предшествующих групп, следует использовать \n , где вместо n подставить номер нужной группы. Вам может понадобиться шаблон, соответствующий буквам «aaa» или «bbb», за которыми следует число, а затем те же три буквы. Такой шаблон реализуется с помощью групп:
Первая часть шаблона ищет «aaa» или «bbb», объединяя найденные буквы в группу. За этим следует поиск одной или более цифр ( 1+ ), и наконец \1 . Последняя часть шаблона ссылается на первую группу и ищет то же самое. Она ищет совпадение с текстом, уже найденным первой частью шаблона, а не соответствующее ему. Таким образом, «aaa123bbb» не будет удовлетворять вышеприведенному шаблону, так как \1 будет искать «aaa» после числа.
Одним из наиболее полезных инструментов в регулярных выражениях является подстановка строк. При замене текста можно сослаться на найденную группу, используя $n . Скажем, вы хотите выделить в тексте все слова «wish» жирным начертанием. Для этого вам следует использовать функцию замены по регулярному выражению, которая может выглядеть так:
Первым параметром будет примерно такой шаблон (возможно вам понадобятся несколько дополнительных символов для этой конкретной функции):
Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой:
Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква и не цифра), отмечая его $1 . Без этого мы бы просто удалили этот символ из текста. То же касается конца подстановки ( $3 ). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы можете использовать CSS или ), выделив им вторую группу, найденную по шаблону ( $2 ).
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.
Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще используется «/»), и выглядит все таким образом:
Модификаторы добавляются в конец этой строки, вот так:
Мета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
Шпаргалка представляет собой общее руководство по шаблонам регулярных выражений без учета специфики какого-либо языка. Она представлена в виде таблицы, помещающейся на одном печатном листе формата A4. Создана под лицензией Creative Commons на базе шпаргалки, автором которой является Dave Child. Скачать в PDF, PNG.
Регулярные выражения
Регулярные выражения (regular expressions) — это текстовый шаблон, который соответствует какому-то тексту. И всё? Да, это всё, для чего они нужны.
Что можно делать с помощью регулярных выражений:
- Проверять то, что вводит пользователь, чтобы быть уверенным в правильности данных (например, правильно ли пользователь ввёл email или ip-адрес).
- Разбирать большой текст на меленькие кусочки (например, выбирать данные из большого лога).
- Делать замены по шаблону (например, убирать непечатаемые символы из XML).
- Показывать невероятную крутость тем, кто не знает регулярных выражений.
Большинство современных языков программирования и текстовых редакторов (по моему личному мнению) поддерживают регулярные выражения. Поддержим их и мы.
/Быть или не быть/ugi ¶
Синтаксис регулярных выражений прост и логичен. Он разделяется на символ-разделитель (он идёт в начале и конце выражения, обычно это /), шаблон поиска и необязательные модификаторы.
Формальный синтаксис такой:
Разделителем может быть любой символ, но обычно это / или
. Важно лишь то, чтобы шаблон начинался и заканчивался одним и тем же разделителем. В самом конце регулярных выражений идут модификаторы, которые нужны, чтобы менять логику работы шаблонов (например делать регистронезависимый поиск).
Давайте разберём выражение /Быть или не быть/ugi :
Данное регулярное выражение будет искать текст Быть или не быть не зависимо от регистра по всему тексту неограниченное количество раз. Модификатор u нужен для того, чтобы явно указать, что текст у нас в юникоде, то есть содержит символы, отличные от латиницы. Модификатор i включает регистронезависимый поиск. Модификатор g указывает поисковику идти до победного конца, иначе он остановится после первого удачного совпадения.
«Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст «Петя любит Катю» . Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \ | Символ экранирования или начала мета-символа | /путь\/к\/папке/ | Надёт текст путь/к/папке |
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на Дом |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на родной |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как Петя любит Машу , так и Петя губит Машу |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт Вжх и Вжух |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт Вжх , Вжух , Вжуух , Вжууух и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт Вжух , Вжуух , Вжууух и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например _Вася333_ |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например @Петя@ |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например 123 |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например Петя |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова дом , но проигнорирует рядом |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на дом |
| \R | Любой перевод строки (Unix, Mac, Windows) | /.*\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор u . К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (. ) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (. ) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P . ) | Задаёт имя под-шаблона | /(?P Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и ‘воздыхатель’ |
| [abc] | Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы \w, \d, \s и т.д.) | /^[123]+$/ | Соответствует любому выражению 323323123 , но не 54321 |
| [a-я0-9] | Если внутри квадратных скобок указать минус, то это считается диапазоном | /[A-Za-zА-Яа-яЁё0-9_]+/ | Аналог /\w/ui для JavaScript |
| [abc-] | Если минус является первым или последним символом диапазона, то это просто минус | /[0-9+-]+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) |
| [^. ] | Квадратные скобки с «крышечекой» означают любой символ НЕ входящий в диапазон | /[^a-zа-я0-9 ]/i | Найдёт любой символ, который не является буквой, числом или пробелом |
| [[:class:]] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /[^[:print:]]+/ | Найдёт последовательность непечатаемых символов |
| Фигурные скобки с одним числом задают точное количество символов | /\w+н<2>\w+/u | Найдёт слово, в котором две буквы н | |
| Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н<1,2>\w+/u | Найдёт слово, в котором есть одна или две буквы н | |
| Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н<3,>\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Как правильно писать регулярные выражения ¶
Прежде, чем садиться и писать регулярно выраженного кракена, подумайте, что именно вы хотите сделать. Регулярное выражение должно начинаться с мысли «Я хочу найти/заменить/удалить то-то и то-то». Затем вам нужен исходный текст, который содержит как ПРАВИЛЬНЫЕ, так и НЕправильные данные. Затем вы открываете https://regex101.com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
Для примера возьмём валидацию ip-адреса. Первая мысль должна быть: «Я хочу валидировать ip-адрес. А что такое ip-адрес? Из чего он состоит?». Затем нужен список валидных и невалидных адресов:
Валидный адрес должен содержать четыре числа (байта) от 0 до 255. Если он содержит число больше 255, это уже ошибка. Если бы мы делали валидацию на каком-либо языке программирования, то можно было бы разбить выражение на четыре части и проверить каждое число отдельно. Но регулярные выражения не поддерживают проверки больше или меньше, поэтому придётся делать по-другому.
Для начала упростим задачу: будем валидировать не весь ip-адрес, а только один байт. А байт это всегда есть либо одно-, либо дву-, либо трёхзначное число. Для одно- и двузначного числа шаблон очень простой — любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
Теперь, зная все диапазоны байта, можно объединить их в одно выражение через вертикальную палочку | (ИЛИ):
Обратите внимание, что я использовал границу слова \b, чтобы искать полные байты. Пробуем регулярку в деле:
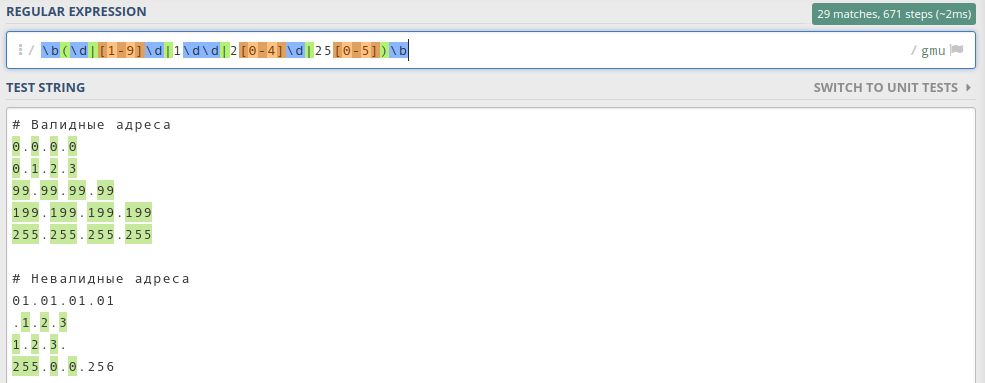
Как видим, все байты стали зелёненькими. Это значит, что мы на верном пути.
Осталось дело за малым: сделать так, чтобы искать четыре байта, а не один. Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
Результат выглядит так:
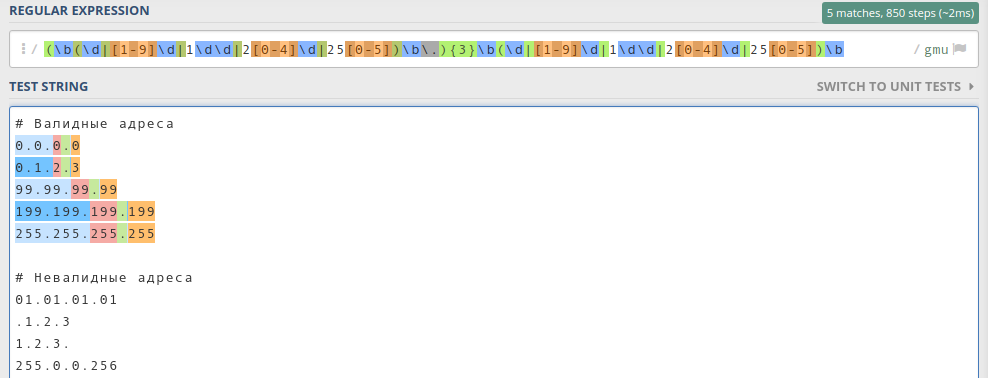
Подсветились только валидные ip-адреса, значит регулярное выражение работает корректно.
Если бы я сразу начал писать валидацию всего адреса, а не отдельного байта, то с большой долей вероятности допустил бы ошибку. Скопления скобочек, палочек и точечек трудно воспринимаются на глаз, поэтому задачу надо обязательно упрощать.
Практическое применение регулярных выражений ¶
Регулярными выражениями можно пользоваться не только для валидации, но и для обработки данных, например, в блокноте. Вот практический пример такой обработки: скопировать номера регионов и перевести в формат PHP-массива.
Your browser does not support HTML5 video.
Ссылки ¶
- https://regex101.com/ — сайт для тестирования регулярных выражений.
- https://linux.die.net/man/1/perlre — руководство по регулярным выражениям Perl.
- https://www.php.net/manual/ru/reference.pcre.pattern.syntax.php — регулярные выражения в PHP.
- https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/RegExp — регулярные выражения JavaScript.
© 2021 Антон Прибора. При копировании материалов с сайта, пожалуйста, указывайте ссылку на источник.



