- Фундаментальные основы Linux. Часть IV. Программные каналы и команды
- Глава 19. Регулярные выражения
- Версии синтаксисов регулярных выражений
- Утилита grep
- Утилита rename
- Утилита sed
- История командной оболочки bash
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Регулярные выражения в Linux
- Первая команда — grep
- egrep (Extended grep)
- Про fgrep
- Рекурсивный rgrep
- Команда sed
Фундаментальные основы Linux. Часть IV. Программные каналы и команды
Глава 19. Регулярные выражения
Механизм регулярных выражений являются очень мощным инструментом системы Linux. Регулярные выражения могут использоваться при работе с множеством программ, таких, как bash, vi, rename, grep, sed и других.
В данной главе представлены базовые сведения о регулярных выражениях .
Версии синтаксисов регулярных выражений
В зависимости от используемого инструмента может использоваться один или несколько упомянутых синтаксисов.
К примеру, инструмент grep поддерживает параметр -E , позволяющий принудительно использовать расширенный синтаксис регулярных выражений (ERE) при разборе регулярного выражения, в то в время, как параметр -G позволяет принудительно использовать базовый синтаксис регулярных выражений (BRE), а параметр -P — синтаксис регулярных выражений языка программирования Perl (PCRE).
Учтите и то, что инструмент grep также поддерживает параметр -F , позволяющий прочитать регулярное выражение без обработки.
Инструмент sed также поддерживает параметры, позволяющие выбирать синтаксис регулярных выражений.
Всегда читайте страницы руководств используемых инструментов!
Утилита grep
Вывод строк, совпадающих с шаблоном
Утилита grep является популярным инструментом систем Linux, предназначенным для поиска строк, которые совпадают с определенным шаблоном. Ниже приведены примеры простейших регулярных выражений , которые могут использоваться при работе с ним.
Сравнение с шаблоном, использованным в данном примере, осуществляется очевидным образом; в том случае, если заданный символ встречается в строке, утилита grep выведет эту строку.
Для поиска сочетаний символов в строках символы регулярного выражения должны объединяться аналогичным образом.
Один или другой символ
Обратите внимание на то, что мы используем параметр -E утилиты grep для принудительной интерпретации нашего регулярного выражения как выражения, использующего расширенный синтаксис регулярных выражений (ERE).
Одно или большее количество совпадений
Совпадение в конце строки
Совпадение в начале строки
Символ вставки (^) позволяет осуществлять поиск совпадения в начале (или с первых символов) строки.
Символы доллара и вставки, используемые в регулярных выражениях, называются якорями (anchors).
Параметры утилиты grep
Предотвращение раскрытия регулярного выражения командной оболочкой
Утилита rename
Реализации утилиты rename
В дистрибутивах, основанных на дистрибутиве Red Hat, не создается аналогичной символьной ссылки для указания на описанный сценарий (конечно же, за исключением тех случаев, когда создается символьная ссылка на сценарий, установленный вручную), поэтому в данном разделе не будет описываться реализация утилиты rename из дистрибутива Red Hat.
В дискуссиях об утилите rename в сети Интернет обычно происходит путаница из-за того, что решения, которые отлично работают в дистрибутиве Debian (а также Ubuntu, xubuntu, Mint, . ), не могут использоваться в дистрибутиве Red Hat (а также CentOS, Fedora, . ).
Хорошо известный синтаксис
Чаще всего утилита rename используется для поиска файлов с именами, соответствующими определенному шаблону в форме строки , и замены данной строки на другую строку .
Эти два примера являются работоспособными по той причине, что используемые нами строки встречаются исключительно в расширениях файлов. Не забывайте о том, что расширения файлов не имеют значения при работе с командной оболочкой bash.
При исполнении рассматриваемой команды осуществляется замена исключительно первого вхождения разыскиваемой строки.
Синтаксис, использованный в предыдущем примере, может быть описан следующим образом: s/регулярное выражение/строка для замены/ . Это описание является простым и очевидным, так как вам придется всего лишь разместить регулярное выражение между двумя первыми слэшами и строку для замены между двумя последними слэшами.
Теперь используемый нами синтаксис может быть описан как s/регулярное выражение/строка для замены/g , где модификатор s обозначает операцию замены (switch), а модификатор g — сообщает о необходимости осуществления глобальной замены (global).
Обратите внимание на то, что в данном примере был использован параметр -n для вывода информации о выполняемой операции (вместо выполнения самой операции, заключающейся в непосредственном переименовании файла).
Замена без учета регистра
Интерфейс командной строки Linux не имеет представления о расширениях файлов, аналогичных применяемым в операционной системе MS-DOS, но многие пользователи и приложения с графическим интерфейсом используют их.
Обратите внимание на то, что символ доллара в рамках регулярного выражения обозначает окончание строки . Без символа доллара исполнение данной команды должно завершиться неудачей в момент обработки имени файла really.txt.txt.
Утилита sed
Редактор потока данных
Редактор потока данных (stream editor) или, для краткости, утилита sed , использует регулярные выражения для модификации потока данных.
Простые обратные ссылки
Символ амперсанда может использоваться для ссылки на искомую (и найденную) строку.
Круглые скобки используются для группировки частей регулярного выражения, на которые впоследствии могут быть установлены ссылки.
Точка для обозначения любого символа
Множественные обратные ссылки
Данная возможность называется группировкой (grouping).
Последовательность символов \s может использоваться для ссылки на такой символ, как символ пробела или табуляции.
Символ знака вопроса указывает на то, что предыдущий символ является необязательным .
Ровно n повторений
Вы можете указать точное количество повторений предыдущего символа.
От n до m повторений
История командной оболочки bash
Командная оболочка bash также может интерпретировать некоторые регулярные выражения.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Регулярные выражения в Linux
На регулярной основе
Интересным вопросом в Linux системах, является управление регулярными выражениями. Это полезный и необходимый навык не только профессионалам своего дела, системным администраторам, но, а также и обычным пользователям линуксоподобных операционных систем. В данной статье я постараюсь раскрыть, как создавать регулярные выражения и как их применять на практике в каких-либо целях. Основной областью применение регулярных выражений является поиск информации и файлов в линуксоподобных операционных системах.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Для работы в основном используются следующие символы:
- «\text» — слова начинающиеся с text
- «text/» — слова, заканчивающиеся на text
- «^» — начало строки
- «$» — конец строки
- «a-z» — диапазон от a до z
- «[^t]» — не буква t
- «\[« — воспринять символ [ буквально
- «.» — любой символ
- «a|z» — а или z
Регулярные выражения в основном используются со следующими командами:
grep — утилита поиска по выражению
- egrep — расширенный grep
- fgrep — быстрый grep
- rgrep — рекурсивный grep
- sed — потоковый текстовый редактор.
А особенно с утилитой grep. Данная утилита используется для сортировки результатов чего либо, передавая ей результаты по конвейеру. Эта утилита осуществляет поиск и передачу на стандартный вывод результат его. ЕЕ можно запускать с различными ключами, но можно использовать ее другие варианты, которые представлены выше.
И есть еще потоковый текстовый редактор. Это не полноценный текстовый редактор, он просто получает информацию построчно и обрабатывает. После чего выводит на стандартный вывод. Он не изменяет текстовый вывод или текстовый поток, он просто редактирует перед тем как вывести его для нас на экран.
Начнем со следующего. Создадим один пустой файл file1.txt, через команду touch. Создадим в текстовом редакторе в той же директории файл file.txt.
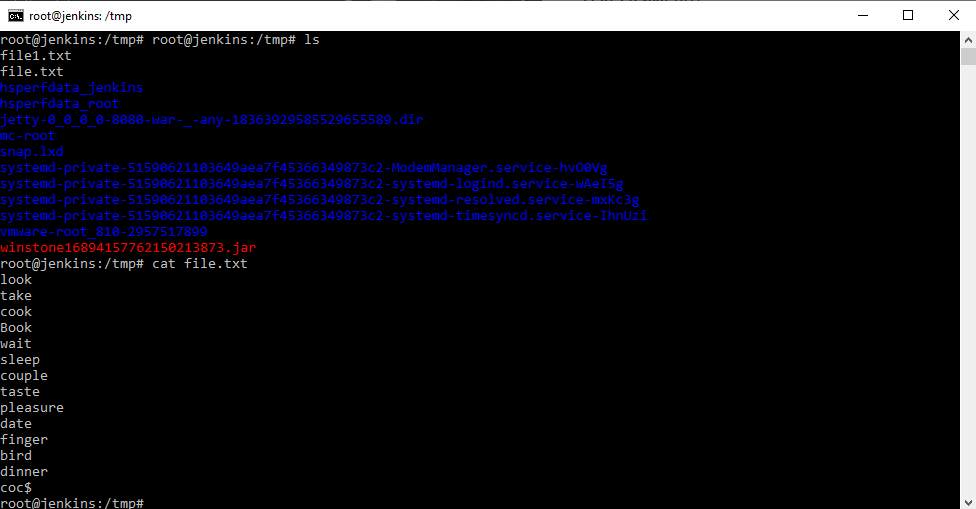
Как мы видим в файле file.txt просто набор слов. Далее мы с помощью данных слов посмотрим, как работают команды.
Первая команда — grep
Получаем справку по данной команде. Как можно понять из справки команда grep и ее производные — это печать линий совпадающих шаблонов. Проще говоря, команда grep помогает сортировать те данные, что мы даем команде, через знак конвейера на ввод. Причем в мануале мы можем видеть egrep, fgrep и т.д. данные команды мы можем не использовать. Использовать можно только grep с ключами различными, т.е. ключи просто заменяют эти команды. Можно на примере посмотреть, как работает данная команда. Например, grep oo file.txt
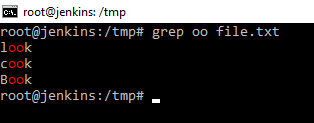
На картинке видно, что команда из указанного файла выбрала по определенному шаблону «oo». Причем даже делает красным цветом подсветку. Можно добавить еще ключик -n, тогда данная команда еще и выведет номер строки в которой находится то, что ищется по шаблону. Это полезно, когда работаем с каким-нибудь кодом или сценарием. Когда необходимо, что-то найти. Сразу видим, где находится объект поиска или что-то ищем по логам.
При использовании шаблона очень важно понимать, что команда grep, чувствительна к регистрам в шаблонах. Это означает, что Boo и boo это разные шаблоны. В одном случае команда найдет слово, а в другом нет. Можно команде сказать, чтобы она не учитывала регистр. Это делается с помощью ключа -i.
Посмотрим содержимое нашего каталога командой ls, а затем отфильтруем только то, что заканчивается на «ile«.

Получается следующее, когда мы даем на ввод команде grep шаблон и где искать, он работает с файлом, а когда мы даем команду ls она выводи содержимое каталога и мы это содержимое передаем по конвейеру на команду grep с заданным шаблоном. Соответственно grep фильтрует переданное содержимое согласно шаблона и выводит на экран. Получается, что команде grep дали, то команда и обработала.
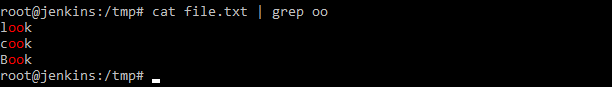
Наглядно можно посмотреть на рисунке выше. Мы просматриваем командой cat содержимое файла и подаем на ввод команде grep с фильтрацией по шаблону.
Давайте найдем файлы в которых содержится сочетание «ple«. grep ple file.txt в данном случае команда нашла оба слова содержащие шаблон. Давайте найдем слово, которое будет начинаться с «ple«. Команда будет выглядеть следующим образом: grep ^ple file.txt . Значок «^» указывает на начало строки. Противоположная задача найти слова, заканчивающиеся на «ple«. Команда будет выглядеть следующим образом grep ple$ file.txt . Т.е. применять к концу строки, говорит значок «$» в шаблоне.

Можно дать команду grep .o file.txt. В данном выражении знак «.» , заменяет любую букву.

Как вы видите вывод шаблона «.ple» вывел только одно слово т.к только слово couple удовлетворяло шаблону , т.к перед «ple» должен был содержаться еще один символ любой.
Попробуем рассмотреть другую команду egrep.
egrep (Extended grep)
man egrep — отошлет к справке по grep.
Данная команда позволяет использовать более расширенный набор шаблонов. Рассмотрим следующий пример команды:
Шаблон заключается в одинарные кавычки, для того чтобы экранировать символы, и команда egrep поняла, что это относится к ней и воспринимала выражение как шаблон. Сам же шаблон означает, что поиск будет искать слова, в начале строки (знак ^) содержащие букву b или d.
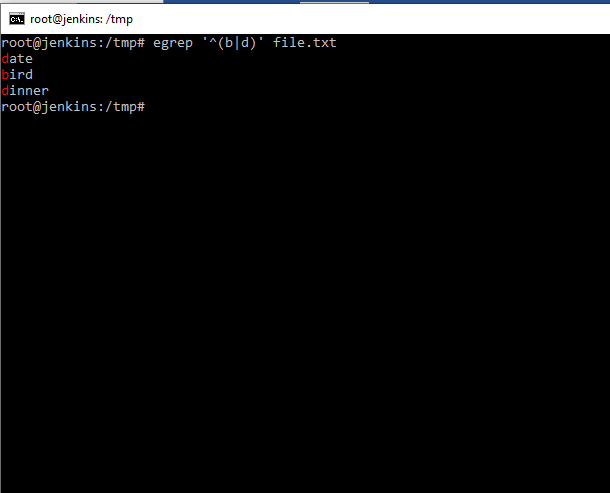
Мы видим, что команда вернула слова, начинающиеся с буквы b или d. Рассмотрим другой вариант использования команды egrep. Например:
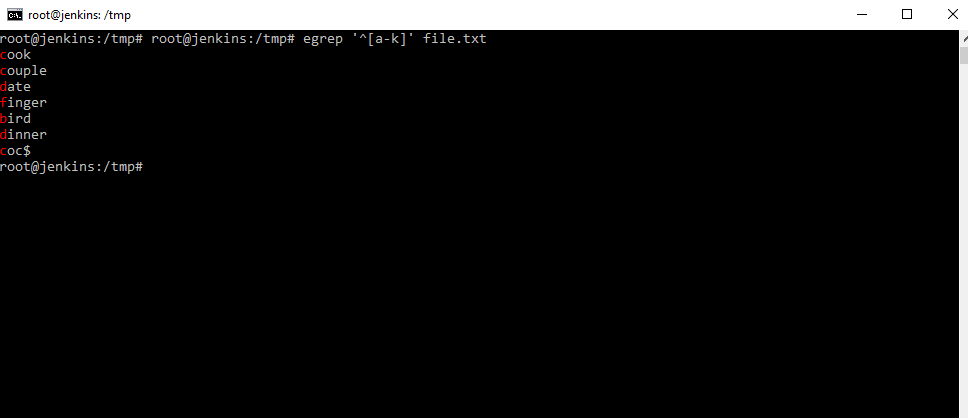
Получим все слова, начинающиеся с «a» по «к». Знак «[]» — диапазона. Как мы видим слова, начинающиеся с большой буквы, не попали. Все эти регулярные выражения очень пригодятся, когда мы что-то ищем в файлах логах.
Усложним еще шаблон. Возьмем следующий:
Усложняя выражение, мы добавили диапазон заглавных букв сказав команде grep искать диапазон маленьких или диапазон больших букв с начала строки.

Вот теперь все хорошо. Слова с Заглавными буквами тоже отобразились.
Как вариант egrep можно запускать просто grep с ключиком -e.
Про fgrep
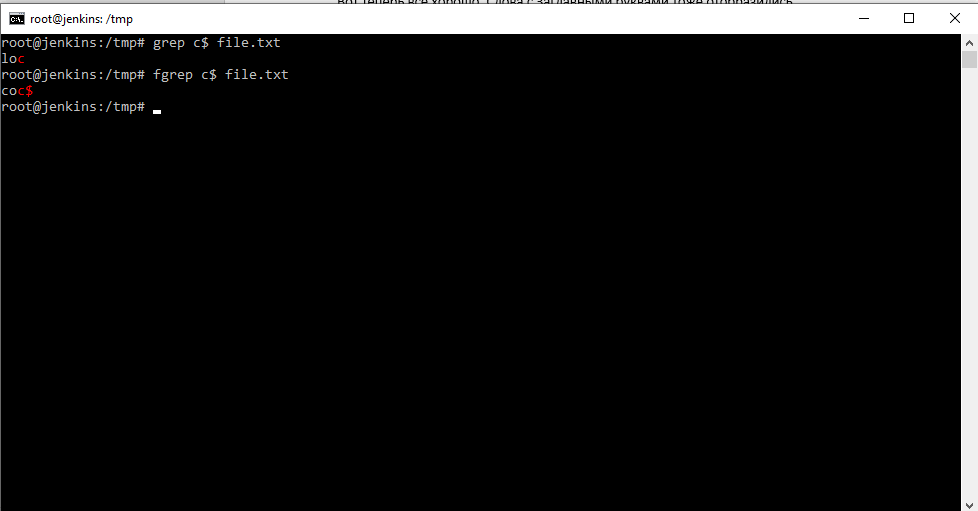
man fgrep — отошлет к справке по grep. Команда fgrep не понимает регулярных выражений вообще.
Получается следующим образом если мы вводим: egrep c$ file.txt . То команда согласно шаблону, ищет в файле букву «c» в конце слова. В случае же с командой fgrep c$ file.txt , команда будет искать именно сочетание «с$». Т.е. команда fgrep воспринимает символы регулярных выражений, как обычные символы, которые ей нужно найти, как аргументы.
Рекурсивный rgrep
Создадим каталог mkdir folder . Создадим файл great.txt в созданной директории folder со словом Hello при помощью команды echo «Hello» folder/great.txt
И если мы скажем grep Hello * , поищи слово Hello в текущей директории. Получится следующая картина.
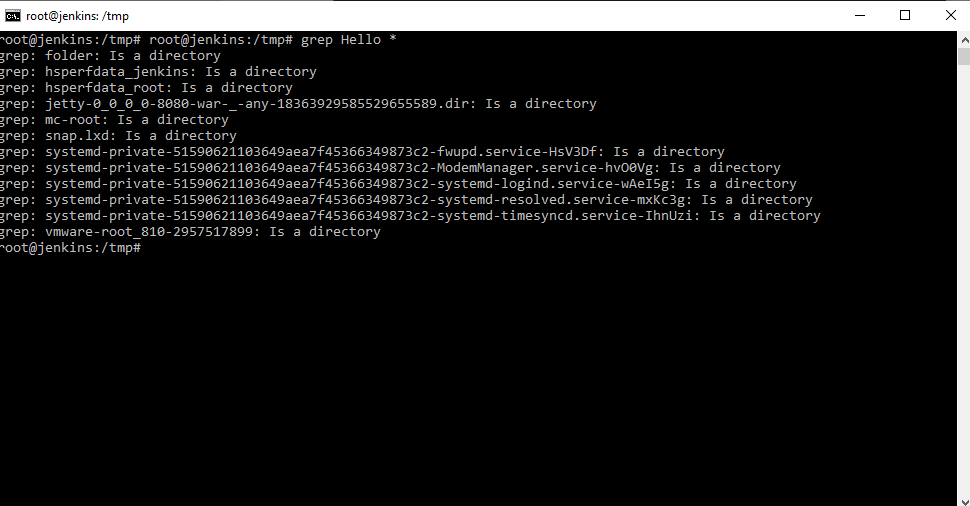
Как мы видим grep не может искать в папках. Для таких случаев и используется утилита rgrep.
Дает следующую картину.
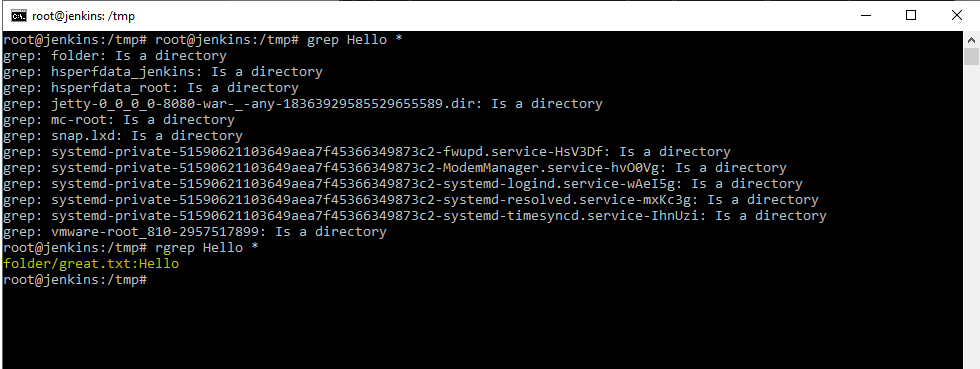
Совершенно спокойно в папке найдено было, то что подходило под шаблон.
Данная утилита пробежалась по всем папкам и файлам в них и нашла подходящее под шаблон слово. Т.е. если нам необходимо провести поиск по всем файлам и папкам, то необходимо использовать утилиту rgrep .
Команда sed
man sed — стрим редактор. Т.е потоковый редактор для фильтрации и редактирования потока данных.
Например, sed -e ‘s/oo/aa’ file.txt — открыть редактор sed и заменить вывод всех oo на aa в файле file.txt. Нужно понимать, что в результате данной команды изменения в файле не произойдут. Просто данные из файла будут взяты и с изменениями выведены на стандартный вывод, т.е. экран. Для сохранения результатов мы можем сказать, чтобы вывел в новый файл указав направление вывода.
В данном редакторе мы можем ему сказать использовать регулярные выражения, для этого необходимо добавить ключ -r. У данного редактора очень большой функционал.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник



