- Шпаргалка по регулярным выражениям
- Квантификаторы
- Модификаторы
- Спецсимволы
- Спецсимволы внутри символьного класса
- Позиция внутри строки
- Якоря
- Символьные классы
- POSIX
- Утверждения
- Кванторы
- Экранирование в регулярных выражениях
- Спецсимволы экранирования в регулярных выражениях
- Подстановка строк
- Группы и диапазоны
- Модификаторы шаблонов
- Мета-символы
- Регулярные выражения Linux
- Регулярные выражения Linux
- Примеры использования регулярных выражений
- Выводы
Шпаргалка по регулярным выражениям
Квантификаторы
| Аналог | Пример | Описание | |
|---|---|---|---|
| ? | a? | одно или ноль вхождений «а» | |
| + | a+ | одно или более вхождений «а» | |
| * | a* | ноль или более вхождений «а» |
Модификаторы
Символ «минус» (-) меред модификатором (за исключением U) создаёт его отрицание.
| Описание | |
|---|---|
| g | глобальный поиск (обрабатываются все совпадения с шаблоном поиска) |
| i | игнорировать регистр |
| m | многострочный поиск. Поясню: по умолчанию текст это одна строка, с модификатором есть отдельные строки, а значит ^ — начало строки в тексте, $ — конец строки в тексте. |
| s | текст воспринимается как одна строка, спец символ «точка» (.) будет вкючать и перевод строки |
| u | используется кодировка UTF-8 |
| U | инвертировать жадность |
| x | игнорировать все неэкранированные пробельные и перечисленные в классе символы |
Спецсимволы
| Аналог | Описание | |
|---|---|---|
| () | подмаска, вложенное выражение | |
| [] | групповой символ | |
| количество вхождений от «a» до «b» | ||
| | | логическое «или», в случае с односимвольными альтернативами используйте [] | |
| \ | экранирование спец символа | |
| . | любой сивол, кроме перевода строки | |
| \d | 1 | десятичная цифра |
| \D | [^\d] | любой символ, кроме десятичной цифры |
| \f | конец (разрыв) страницы | |
| \n | перевод строки | |
| \pL | буква в кодировке UTF-8 при использовании модификатора u | |
| \r | возврат каретки | |
| \s | [ \t\v\r\n\f] | пробельный символ |
| \S | [^\s] | любой символ, кроме промельного |
| \t | табуляция | |
| \w | [0-9a-z_] | любая цифра, буква или знак подчеркивания |
| \W | [^\w] | любой символ, кроме цифры, буквы или знака подчеркивания |
| \v | вертикальная табуляция |
Спецсимволы внутри символьного класса
| Пример | Описание | |
|---|---|---|
| ^ | [^da] | отрицание, любой символ кроме «d» или «a» |
| — | [a-z] | интервал, любой симво от «a» до «z» |
Позиция внутри строки
| Пример | Соответствие | Описание | |
|---|---|---|---|
| ^ | ^a | aaa aaa | начало строки |
| $ | a$ | aaa aaa | конец строки |
| \A | \Aa | aaa aaa aaa aaa | начало текста |
| \z | a\z | aaa aaa aaa aaa | конец текста |
| \b | a\b \ba | aaa aaa aaa aaa | граница слова, утверждение: предыдущий символ словесный, а следующий — нет, либо наоборот |
| \B | \Ba\B | aaa aaa | отсутствие границы слова |
| \G | \Ga | aaa aaa | Предыдущий успешный поиск, поиск остановился на 4-й позиции — там, где не нашлось a |
Скачать в PDF, PNG.
Якоря
Якоря в регулярных выражениях указывают на начало или конец чего-либо. Например, строки или слова. Они представлены определенными символами. К примеру, шаблон, соответствующий строке, начинающейся с цифры, должен иметь следующий вид:
Здесь символ ^ обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, \d соответствует любой цифре от 0 до 9 включительно, \w соответствует буквам и цифрам, а \W — всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит так:
POSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе каждое слово, включающее букву “q”, за которой не следует “werty”».
Приведенный выше код начинается с поиска любых символов, кроме пробела ( [^\s]* ), за которыми следует q . Затем парсер достигает «смотрящего вперед» утверждения. Это автоматически делает предшествующий элемент (символ, группу или символьный класс) условным — он будет соответствовать шаблону, только если утверждение верно. В нашем случае, утверждение является отрицательным ( ?! ), т. е. оно будет верным, если то, что в нем ищется, не будет найдено.
Итак, парсер проверяет несколько следующих символов по предложенному шаблону ( werty ). Если они найдены, то утверждение ложно, а значит символ q будет «проигнорирован», т. е. не будет соответствовать шаблону. Если же werty не найдено, то утверждение верно, и с q все в порядке. Затем продолжается поиск любых символов, кроме пробела ( [^\s]* ).
Кванторы
Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон:
По умолчанию кванторы — «жадные». Поэтому квантор + , означающий «один или больше раз», будет соответствовать максимально возможному значению. Иногда это вызывает проблемы, и тогда вы можете сказать квантору перестать быть жадным (стать «ленивым»), используя специальный модификатор. Посмотрите на этот код:
Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
Приведенный выше шаблон найдет в этой строке вот такую подстроку:
Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание на модификатор ? ) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных кавычках по отдельности:
Экранирование в регулярных выражениях
Регулярные выражения используют некоторые символы для обозначения различных частей шаблона. Однако, возникает проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто использовать « . » в качестве шаблона — это приведет к нахождению практически всего. Итак, вам необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с помощью знака экранирования.
Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»).
Шаблон для нахождения точки таков:
Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Спецсимволы экранирования в регулярных выражениях
| Выражение | Соответствие |
|---|---|
| \ | не соответствует ничему, только экранирует следующий за ним символ. Это нужно, если вы хотите ввести метасимволы !$()*+.<>?[\]^ <|>в качестве их буквальных значений. |
| \Q | не соответствует ничему, только экранирует все символы вплоть до \E |
| \E | не соответствует ничему, только прекращает экранирование, начатое \Q |
Подстановка строк
Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке.
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона из другой его части; а также при подстановке строк.
Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»:
Если в регулярном выражении необходимо сослаться на какую-то из предшествующих групп, следует использовать \n , где вместо n подставить номер нужной группы. Вам может понадобиться шаблон, соответствующий буквам «aaa» или «bbb», за которыми следует число, а затем те же три буквы. Такой шаблон реализуется с помощью групп:
Первая часть шаблона ищет «aaa» или «bbb», объединяя найденные буквы в группу. За этим следует поиск одной или более цифр ( 4+ ), и наконец \1 . Последняя часть шаблона ссылается на первую группу и ищет то же самое. Она ищет совпадение с текстом, уже найденным первой частью шаблона, а не соответствующее ему. Таким образом, «aaa123bbb» не будет удовлетворять вышеприведенному шаблону, так как \1 будет искать «aaa» после числа.
Одним из наиболее полезных инструментов в регулярных выражениях является подстановка строк. При замене текста можно сослаться на найденную группу, используя $n . Скажем, вы хотите выделить в тексте все слова «wish» жирным начертанием. Для этого вам следует использовать функцию замены по регулярному выражению, которая может выглядеть так:
Первым параметром будет примерно такой шаблон (возможно вам понадобятся несколько дополнительных символов для этой конкретной функции):
Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой:
Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква и не цифра), отмечая его $1 . Без этого мы бы просто удалили этот символ из текста. То же касается конца подстановки ( $3 ). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы можете использовать CSS или ), выделив им вторую группу, найденную по шаблону ( $2 ).
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.
Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще используется «/»), и выглядит все таким образом:
Модификаторы добавляются в конец этой строки, вот так:
Мета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
Шпаргалка представляет собой общее руководство по шаблонам регулярных выражений без учета специфики какого-либо языка. Она представлена в виде таблицы, помещающейся на одном печатном листе формата A4. Создана под лицензией Creative Commons на базе шпаргалки, автором которой является Dave Child. Скачать в PDF, PNG.
Источник
Регулярные выражения Linux
Регулярные выражения — это очень мощный инструмент для поиска текста по шаблону, обработки и изменения строк, который можно применять для решения множества задач. Вот основные из них:
- Проверка ввода текста;
- Поиск и замена текста в файле;
- Пакетное переименование файлов;
- Взаимодействие с сервисами, таким как Apache;
- Проверка строки на соответствие шаблону.
Это далеко не полный список, регулярные выражения позволяют делать намного больше. Но для новых пользователей они могут показаться слишком сложными, поскольку для их формирования используется специальный язык. Но учитывая предоставляемые возможности, регулярные выражения Linux должен знать и уметь использовать каждый системный администратор.
В этой статье мы рассмотрим регулярные выражения bash для начинающих, чтобы вы смогли разобраться со всеми возможностями этого инструмента.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- — указывает сколько раз (n) нужно повторить предыдущий символ;
- — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- [az] — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- [^az] — любой символ, кроме тех, что указаны в скобках;
- [a-z] — любой символ из указанного диапазона;
- [^a-z] — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту.
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать команду egrep:
egrep «^s» /etc/passwd
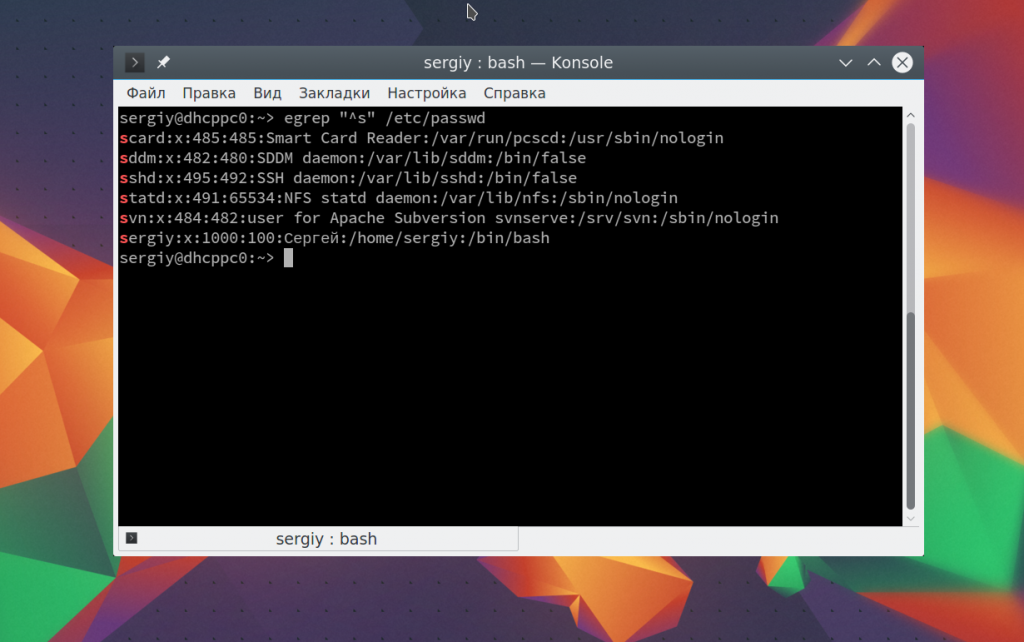
Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:
egrep «false$» /etc/passwd
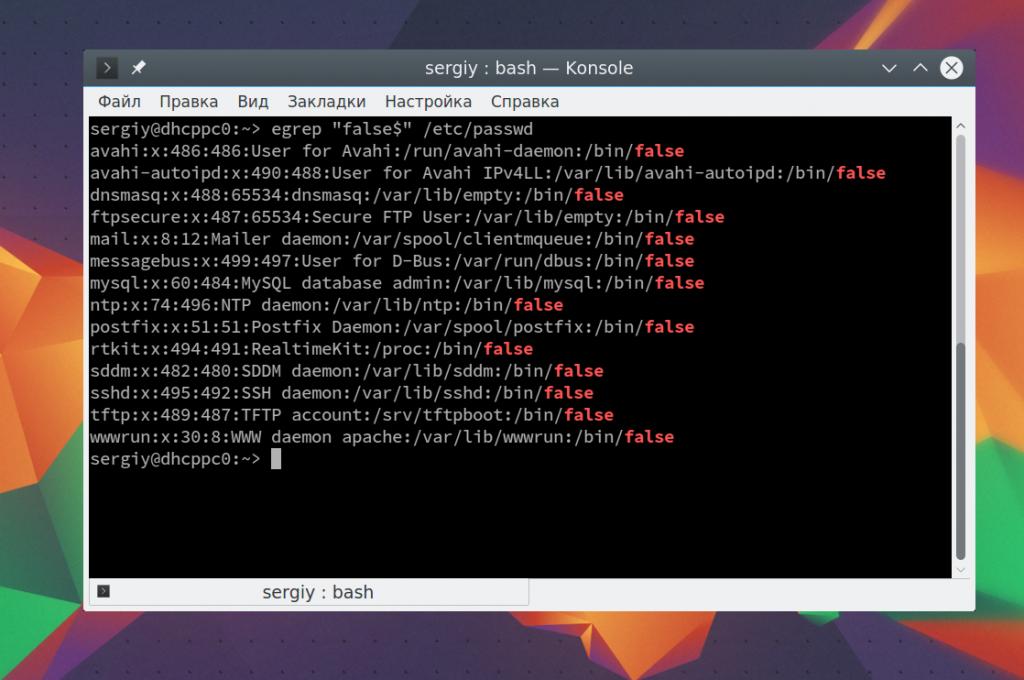
Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
egrep «^[sd]» /etc/passwd
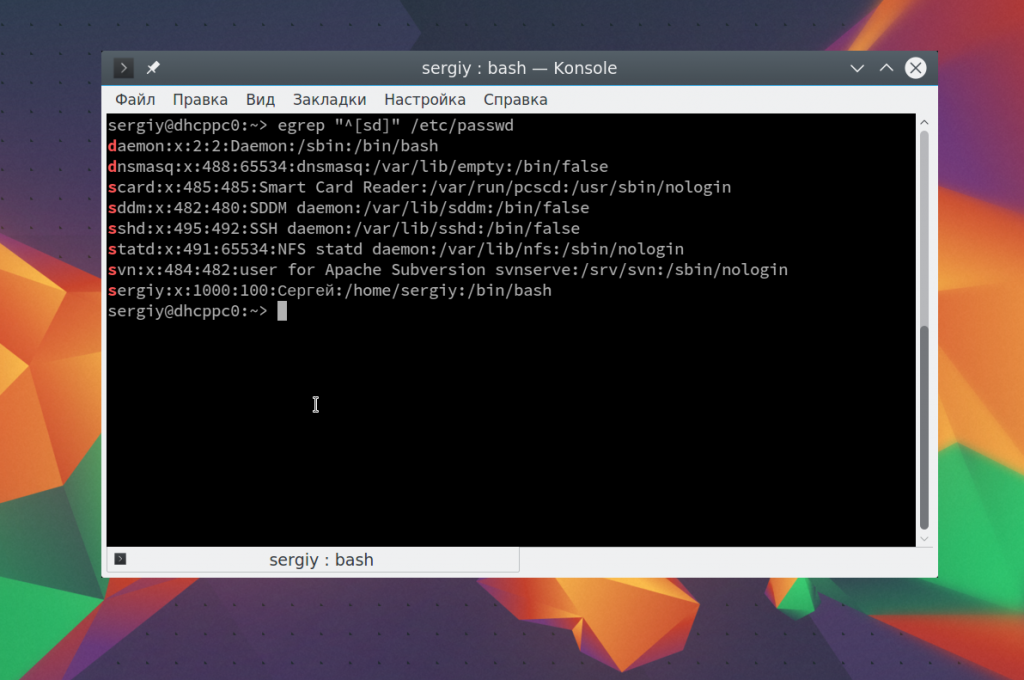 Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
egrep «^[s|d]» /etc/passwd
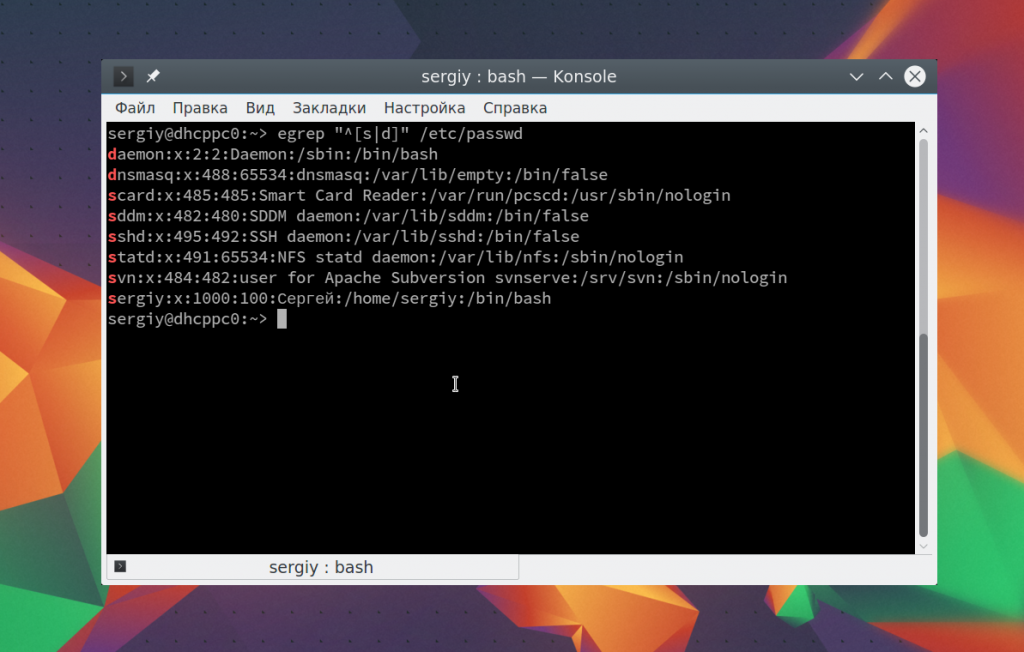
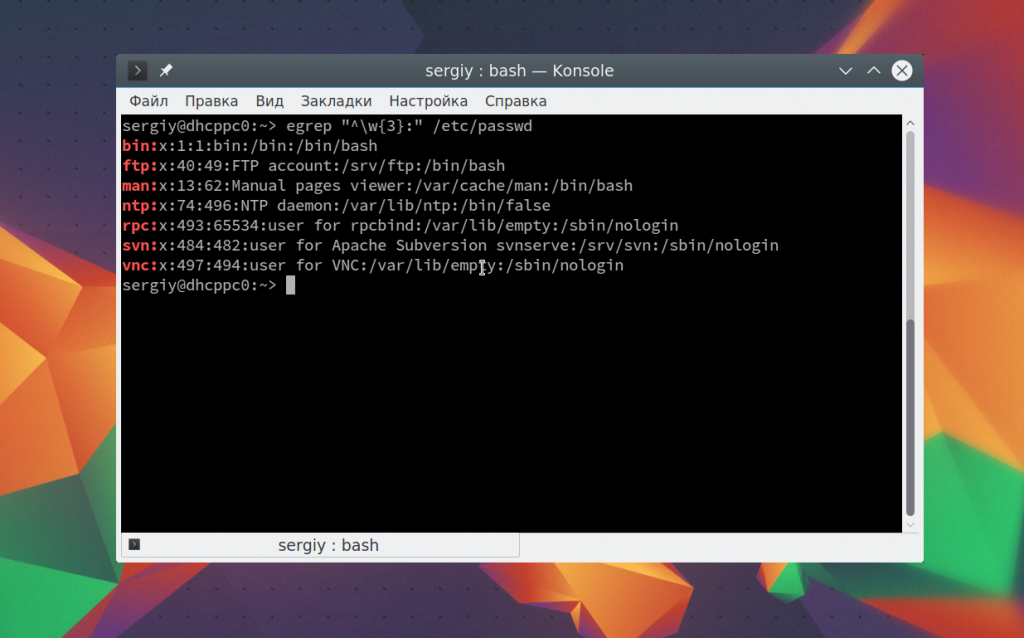
Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием:
egrep «^\w<3>:» /etc/passwd
Выводы
В этой статье мы рассмотрели регулярные выражения Linux, но это были только самые основы. Если копнуть чуть глубже, вы найдете что с помощью этого инструмента можно делать намного больше интересных вещей. Время, потраченное на освоение регулярных выражений, однозначно будет стоить того.
На завершение лекция от Яндекса про регулярные выражения:
Источник



