ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Регулярные выражения в Linux
На регулярной основе
Интересным вопросом в Linux системах, является управление регулярными выражениями. Это полезный и необходимый навык не только профессионалам своего дела, системным администраторам, но, а также и обычным пользователям линуксоподобных операционных систем. В данной статье я постараюсь раскрыть, как создавать регулярные выражения и как их применять на практике в каких-либо целях. Основной областью применение регулярных выражений является поиск информации и файлов в линуксоподобных операционных системах.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Для работы в основном используются следующие символы:
- «\text» — слова начинающиеся с text
- «text/» — слова, заканчивающиеся на text
- «^» — начало строки
- «$» — конец строки
- «a-z» — диапазон от a до z
- «[^t]» — не буква t
- «\[« — воспринять символ [ буквально
- «.» — любой символ
- «a|z» — а или z
Регулярные выражения в основном используются со следующими командами:
grep — утилита поиска по выражению
- egrep — расширенный grep
- fgrep — быстрый grep
- rgrep — рекурсивный grep
- sed — потоковый текстовый редактор.
А особенно с утилитой grep. Данная утилита используется для сортировки результатов чего либо, передавая ей результаты по конвейеру. Эта утилита осуществляет поиск и передачу на стандартный вывод результат его. ЕЕ можно запускать с различными ключами, но можно использовать ее другие варианты, которые представлены выше.
И есть еще потоковый текстовый редактор. Это не полноценный текстовый редактор, он просто получает информацию построчно и обрабатывает. После чего выводит на стандартный вывод. Он не изменяет текстовый вывод или текстовый поток, он просто редактирует перед тем как вывести его для нас на экран.
Начнем со следующего. Создадим один пустой файл file1.txt, через команду touch. Создадим в текстовом редакторе в той же директории файл file.txt.
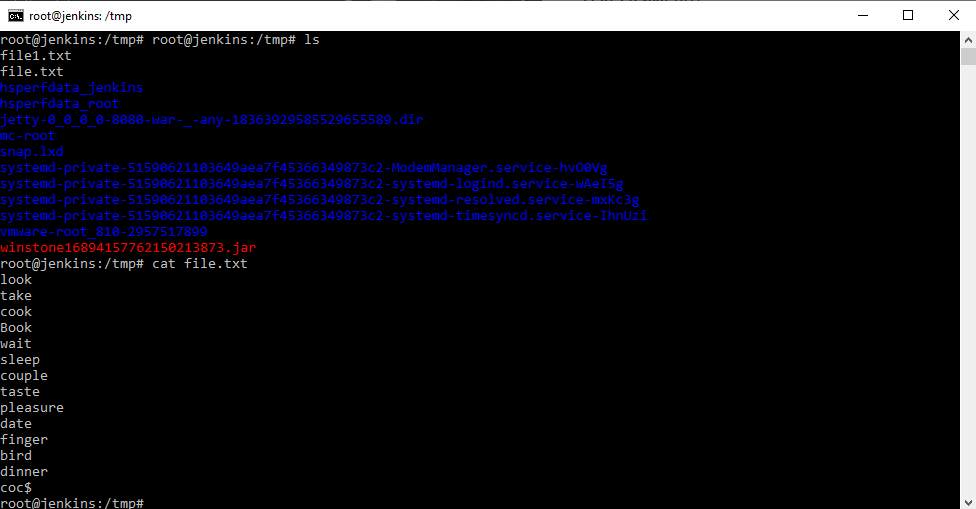
Как мы видим в файле file.txt просто набор слов. Далее мы с помощью данных слов посмотрим, как работают команды.
Первая команда — grep
Получаем справку по данной команде. Как можно понять из справки команда grep и ее производные — это печать линий совпадающих шаблонов. Проще говоря, команда grep помогает сортировать те данные, что мы даем команде, через знак конвейера на ввод. Причем в мануале мы можем видеть egrep, fgrep и т.д. данные команды мы можем не использовать. Использовать можно только grep с ключами различными, т.е. ключи просто заменяют эти команды. Можно на примере посмотреть, как работает данная команда. Например, grep oo file.txt
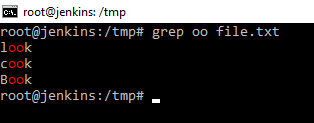
На картинке видно, что команда из указанного файла выбрала по определенному шаблону «oo». Причем даже делает красным цветом подсветку. Можно добавить еще ключик -n, тогда данная команда еще и выведет номер строки в которой находится то, что ищется по шаблону. Это полезно, когда работаем с каким-нибудь кодом или сценарием. Когда необходимо, что-то найти. Сразу видим, где находится объект поиска или что-то ищем по логам.
При использовании шаблона очень важно понимать, что команда grep, чувствительна к регистрам в шаблонах. Это означает, что Boo и boo это разные шаблоны. В одном случае команда найдет слово, а в другом нет. Можно команде сказать, чтобы она не учитывала регистр. Это делается с помощью ключа -i.
Посмотрим содержимое нашего каталога командой ls, а затем отфильтруем только то, что заканчивается на «ile«.

Получается следующее, когда мы даем на ввод команде grep шаблон и где искать, он работает с файлом, а когда мы даем команду ls она выводи содержимое каталога и мы это содержимое передаем по конвейеру на команду grep с заданным шаблоном. Соответственно grep фильтрует переданное содержимое согласно шаблона и выводит на экран. Получается, что команде grep дали, то команда и обработала.
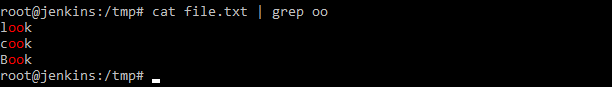
Наглядно можно посмотреть на рисунке выше. Мы просматриваем командой cat содержимое файла и подаем на ввод команде grep с фильтрацией по шаблону.
Давайте найдем файлы в которых содержится сочетание «ple«. grep ple file.txt в данном случае команда нашла оба слова содержащие шаблон. Давайте найдем слово, которое будет начинаться с «ple«. Команда будет выглядеть следующим образом: grep ^ple file.txt . Значок «^» указывает на начало строки. Противоположная задача найти слова, заканчивающиеся на «ple«. Команда будет выглядеть следующим образом grep ple$ file.txt . Т.е. применять к концу строки, говорит значок «$» в шаблоне.

Можно дать команду grep .o file.txt. В данном выражении знак «.» , заменяет любую букву.

Как вы видите вывод шаблона «.ple» вывел только одно слово т.к только слово couple удовлетворяло шаблону , т.к перед «ple» должен был содержаться еще один символ любой.
Попробуем рассмотреть другую команду egrep.
egrep (Extended grep)
man egrep — отошлет к справке по grep.
Данная команда позволяет использовать более расширенный набор шаблонов. Рассмотрим следующий пример команды:
Шаблон заключается в одинарные кавычки, для того чтобы экранировать символы, и команда egrep поняла, что это относится к ней и воспринимала выражение как шаблон. Сам же шаблон означает, что поиск будет искать слова, в начале строки (знак ^) содержащие букву b или d.
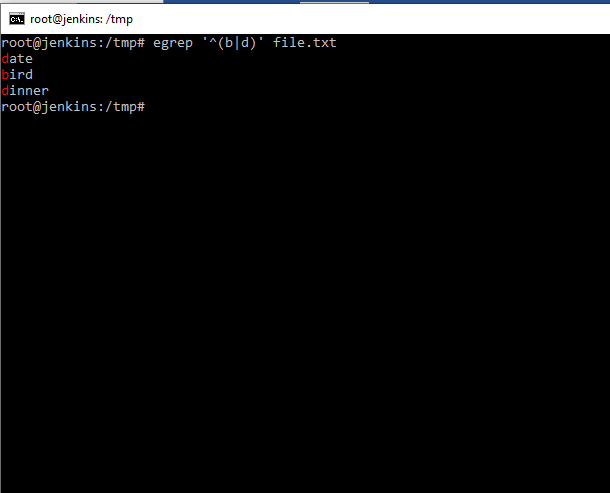
Мы видим, что команда вернула слова, начинающиеся с буквы b или d. Рассмотрим другой вариант использования команды egrep. Например:
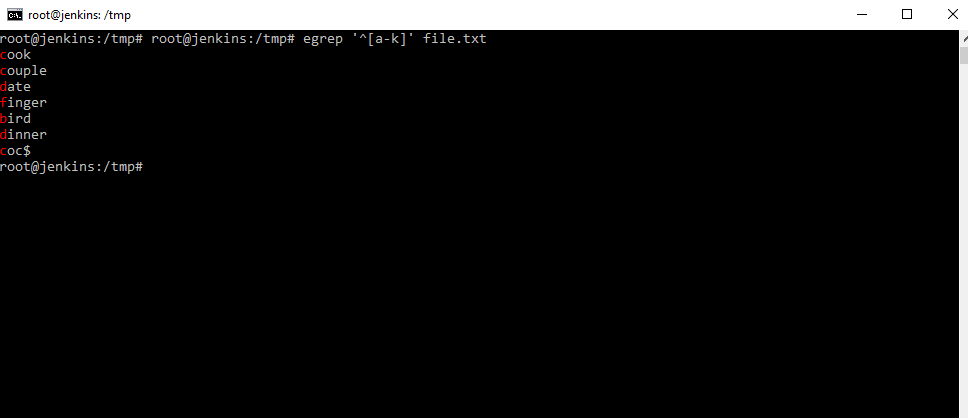
Получим все слова, начинающиеся с «a» по «к». Знак «[]» — диапазона. Как мы видим слова, начинающиеся с большой буквы, не попали. Все эти регулярные выражения очень пригодятся, когда мы что-то ищем в файлах логах.
Усложним еще шаблон. Возьмем следующий:
Усложняя выражение, мы добавили диапазон заглавных букв сказав команде grep искать диапазон маленьких или диапазон больших букв с начала строки.

Вот теперь все хорошо. Слова с Заглавными буквами тоже отобразились.
Как вариант egrep можно запускать просто grep с ключиком -e.
Про fgrep
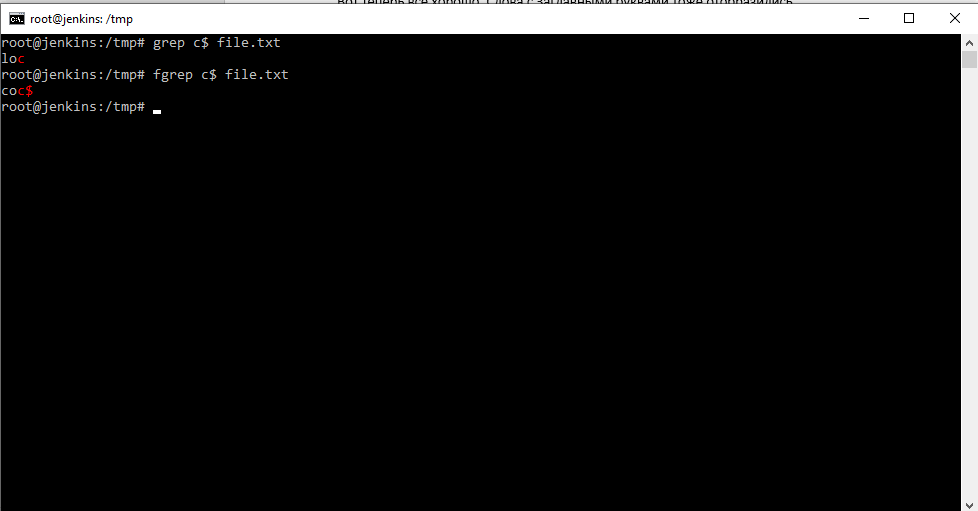
man fgrep — отошлет к справке по grep. Команда fgrep не понимает регулярных выражений вообще.
Получается следующим образом если мы вводим: egrep c$ file.txt . То команда согласно шаблону, ищет в файле букву «c» в конце слова. В случае же с командой fgrep c$ file.txt , команда будет искать именно сочетание «с$». Т.е. команда fgrep воспринимает символы регулярных выражений, как обычные символы, которые ей нужно найти, как аргументы.
Рекурсивный rgrep
Создадим каталог mkdir folder . Создадим файл great.txt в созданной директории folder со словом Hello при помощью команды echo «Hello» folder/great.txt
И если мы скажем grep Hello * , поищи слово Hello в текущей директории. Получится следующая картина.
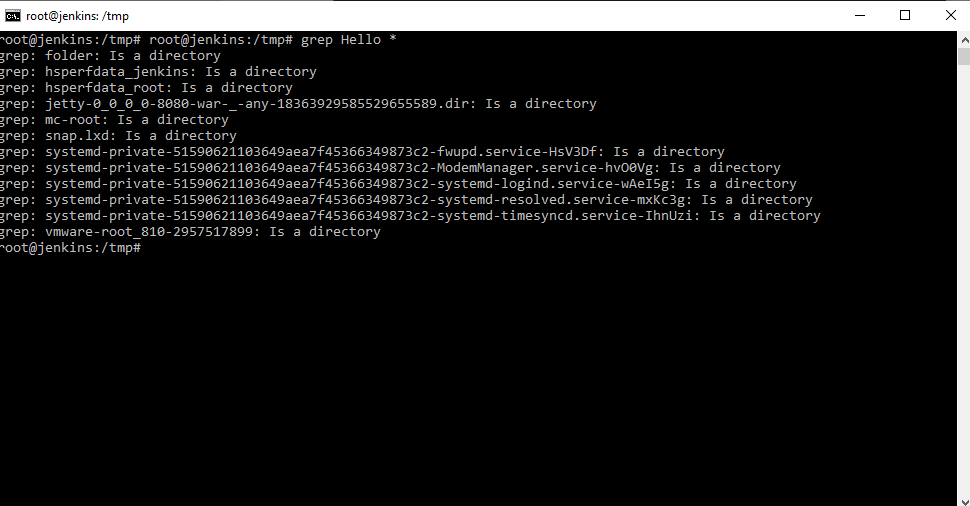
Как мы видим grep не может искать в папках. Для таких случаев и используется утилита rgrep.
Дает следующую картину.
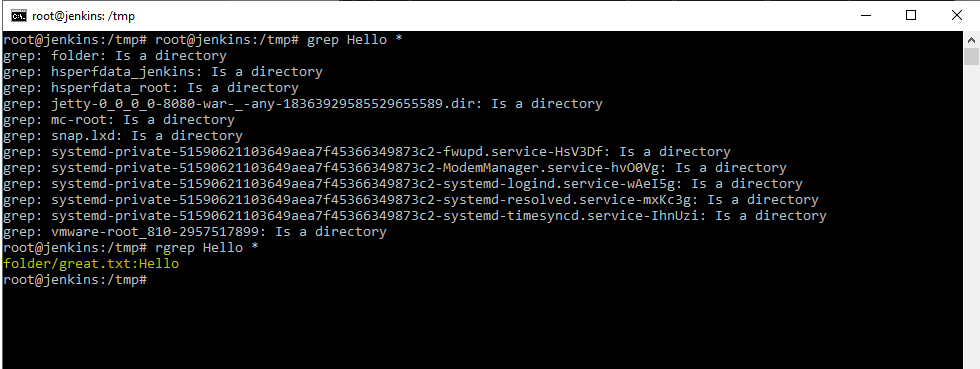
Совершенно спокойно в папке найдено было, то что подходило под шаблон.
Данная утилита пробежалась по всем папкам и файлам в них и нашла подходящее под шаблон слово. Т.е. если нам необходимо провести поиск по всем файлам и папкам, то необходимо использовать утилиту rgrep .
Команда sed
man sed — стрим редактор. Т.е потоковый редактор для фильтрации и редактирования потока данных.
Например, sed -e ‘s/oo/aa’ file.txt — открыть редактор sed и заменить вывод всех oo на aa в файле file.txt. Нужно понимать, что в результате данной команды изменения в файле не произойдут. Просто данные из файла будут взяты и с изменениями выведены на стандартный вывод, т.е. экран. Для сохранения результатов мы можем сказать, чтобы вывел в новый файл указав направление вывода.
В данном редакторе мы можем ему сказать использовать регулярные выражения, для этого необходимо добавить ключ -r. У данного редактора очень большой функционал.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
Урок 1. Файловая система и типы файлов в Linux
Файловая система организует доступ и хранение файлов на жестком диске и съемных устройствах.
Файловая система в Linux образует иерархическую древовидную структуру, которая описывается стандартом FHS (Filesystem Hierarchy System). Согласно этому стандарту любая система Linux содержит определенные каталоги и файлы, в которых хранятся только определенные файлы
Например, установленные программы хранятся в одном каталоге, а настройки системы в другом каталоге и так далее. Таким образом, пользователи и само ядро знают где и какие файлы хранятся в системе.
Согласно FHS в системе существует только один родительский корневой каталог, от которого отходят ветви — подкаталоги. Даже если в системе присутствует несколько жестких дисков и съемных устройств, то все равно корневой каталог только один.
Так выглядит файловая структура всех систем Linux

Рассмотрим какие файлы и каталоги присутствуют в системе и опишем для чего они нужны.
/bin — (сокращенно от “binary” — исполняемый), содержит необходимые программы/утилиты (исполняемые файлы) для функционирования и восстановления системы.
/boot — (сокращенно от “boot” — загрузка), содержит загрузчик системы, образ ядра.
/dev — (сокращенно от “devices” — устройства), содержит файлы для “общения” с внешними устройствами (USB, CD/DVD).
/etc — содержит конфигурационные файлы системы, различные настройки.
/home — домашний каталог всех зарегистрированных пользователей системы (кроме root). Содержит пользовательские данные, которые не будут утеряны при сбое системы.
/lib — (сокращенно от “library” — библиотека), содержит библиотечные файлы установленных программ.
/mnt — (сокращенно от “mount” — монтировать), содержит временные ссылки файлов и каталогов смонтированных файловых систем (от съемных носителей). Например, если подключить USB флэшку к компу, то содержимое флэшку можно будет просмотреть через данный каталог.
/sbin — (сокращенно от “system binary” — системные исполняемые файлы), содержит системные исполняемые файлы, которые доступны только администратору.
/opt — содержит библиотеки и исполняемые файлы дополнительного ПО.
/usr — (сокращенно от “user” — пользовательский), содержит конфигурационные и исполняемые файлы всей системы, в том числе и различные пользовательские прикладные программы.
/tmp — (сокращенно от “temporary” — временный), содержит временные файлы, которые можно удалить после завершения работы программ. После перезагрузки системы файлы удаляются.
/root — домашний каталог суперпользователя root.
Почему данный каталог не может быть в каталоге /home вместе с остальными каталогами пользователей?
Потому что каталог /home может находится и на съемных носителях, в то время как каталог /root всегда должен присутствовать в системе.
/var — (сокращенно от “variables” — переменные), содержит различные логи, журнал событий в системе и так далее. После перезагрузки системы файлы не удаляются.
/proc — (сокращенно от “process” — процессы), содержит подкаталоги, которые хранят информацию о запущенных процессах в системе. Каждый процесс и каталог характеризуются идентификатором процессов PID.
В Linux принято, что абсолютно все объекты являются файлами. Не все файлы хранят данные, поэтому выделяют следующие типы файлов:
Обычные ( регулярные ) файлы — любые текстовые, исполняемые, библиотечные, графические файлы.
Каталоги — хранят именованные ссылки (только ссылки, но не сами файлы) на другие файлы. Существуют специальные каталоги . — текущий каталог, .. — родительский каталог.
Символьные ссылки — файл с текстовой строкой, которая представляет собой путь к самому файлу. У одного файла может быть несколько символьных ссылок.
Жесткие ссылки — представляет собой второе имя файла. Данная ссылка указывает на индексный дескриптор файла.
Сокеты — файлы, которые используются для взаимодействия между различными процессами.
Именованные каналы FIFO — подобны сокетам, но работают в одном направлении.
Файлы блочных и символьных устройств — используются для взаимодействия с внешними устройствами и представляют собой своего рода шлюз между системой и внешним устройством. Данные файлы характеризуются 2 числами: старшим и младшим. Старший означает какой драйвер использовать с данным устройством, а младший — конкретное физическое устройство либо раздел на диске.
Источник



