- linux-notes.org
- Установка Lsyncd в Unix/Linux
- Установка Lsyncd в Debian/Ubuntu
- Установка Lsyncd в CentOS/RedHat/Fedora
- Установка Lsyncd в Mac OS X
- Настройка и использование Lsyncd в Unix/Linux
- Настройка и использование Lsyncd на Mac OS X
- Настройка и использование Lsyncd на CentOS
- One thought on “ Установка Lsyncd в Unix/Linux ”
- Добавить комментарий Отменить ответ
- Настраиваем DRBD для репликации хранилища на два CentOS 7 сервера
- Тестовая среда
- Шаг 1: Установка пакетов DRBD
- Шаг 2. Подготовка низкоуровневого хранилища
- Шаг 3. Настройка DRBD
- Шаг 4. Добавление ресурса
- Шаг 5. Инициализация и запуск ресурса
- Шаг 6: Установка основного ресурса/источника начальной синхронизации устройств
- Шаг 7: Тестирование DRBD сетапа
- Резюме
- Высокая доступность веб-сайта: георепликация файлов сайта с lsyncd
- Lsyncd
- Установка и настройка георепликации файлов веб-сервера
- Проверяем доступность сайта
- Заключение
linux-notes.org

Lsyncd (Live Syncing Daemon) — утилита для синхронизации файлов между сервером(ами). Файлы на локальном компьютере отслеживаются каждые несколько секунд, и если какие-либо изменения отмечены, они затем реплицируются и синхронизируются с удаленными серверами. По умолчанию, Lsync использует Rsync для репликации файлов с локальной машины и передает только файлы, которые были изменены. Тонкоструктурную настройку можно выполнить через файл конфигурации. Пользовательские конфигурации действий могут даже быть написаны с нуля в каскадных слоях, начиная от shell до кода, написанного на языке Lua.
Основные Lsyncd функции:
- Проверяет, нужно ли синхронизировать данные с локальной машиной на удаленный сервер(ы).
- Выполняет проверку наоборот.
- Синхронизация с вашей локальной машины на удаленный (ые).
- Синхронизирует наоборот.
- Может редактировать файл «rsync includes»
Установка Lsyncd в Unix/Linux
Процесс установки очень прост и не требует очень больших усилий. Я приведу несколько примеров по установки данной утилиты на различные Unix/Linux ОС.
Установка Lsyncd в Debian/Ubuntu
После установки, переходим к настройке.
Установка Lsyncd в CentOS/RedHat/Fedora
И, установим дополнительные пакеты:
После установки, переходим к настройке.
Установка Lsyncd в Mac OS X
Ставим себе на машину homebrew:
И выполняем установку:
После установки, переходим к настройке.
Настройка и использование Lsyncd в Unix/Linux
Чтобы все хорошо работало, нужно сгенерировать RSA ключ и положить его на удаленный сервер. Я пропущу данный шаг, т.к я это уже сделал, а если не знаете как это сделать вот статья:
Настройка и использование Lsyncd на Mac OS X
И так, я у себя на mac OS X хотел бы настроить lsyncd таким образом, чтобы он синхронизировал все изменения.
И так, я установил данную утилиту и следующим действием, я создам папку где будет хранится лог-файлы:
И создаю нужные файлы:
PS: В ОС Linux они могут лежать в /var/log/lsyncd. Если не имеется такой папки, то создаем.
Далее, я создаю каталог lsyncd в /etc/ для настройки конфига:
После создания данной папки, я создаю конфигурационный файл:
Иногда нужно исключать некоторые каталоги. Вы можете создать файлe и добавить исключения в строке как в этом примере:
файл имеет следующее содержание:
Теперь мы можем запустить службу lsyncd, выполнив следующую команду:
Настройка и использование Lsyncd на CentOS
Вот еще пример (проверялось на CentOS 7):
ИЛИ, если использовать RSYNC:
Добавляем в автозагрузку ОС:
Если используете CentOS 7:
Подключаемся к серверу и проверяем папки. Так же, можно посмотреть логи.
Репликация в 2 стороны
Чтобы работала репликация и в обратную сторону — на сервере в другом регионе проведите такие же настройки, но в файле конфигурации lsyncd укажите адрес первого сервера. Проверьте, что данные реплицируются и в обратном направлении. В конфигурации lsyncd уже указана временная директория temp_dir, использование которой необходимо для двусторонней синхронизации.
Репликация на несколько серверов
Вот пример конфиругации:
На этом, у меня все, статья «Установка Lsyncd в Unix/Linux» завершена.
One thought on “ Установка Lsyncd в Unix/Linux ”
отличная статья. Только не хватает инфы по соединению конфига с lsyncd))
Добавить комментарий Отменить ответ
Этот сайт использует Akismet для борьбы со спамом. Узнайте, как обрабатываются ваши данные комментариев.
Источник
Настраиваем DRBD для репликации хранилища на два CentOS 7 сервера

DRBD (Distributed Replicated Block Device — распределённое реплицируемое блочное устройство) представляет собой распределенное, гибкое и универсально реплицируемое решение хранения данных для Linux. Оно отражает содержимое блочных устройств, таких как жесткие диски, разделы, логические тома и т.д. между серверами. Оно создает копии данных на двух устройствах хранения для того, чтобы в случае сбоя одного из них можно было использовать данные на втором.
Можно сказать, что это нечто вроде сетевой конфигурации RAID 1 с дисками, отражаемыми на разные сервера. Однако оно работает совсем не так, как RAID (даже сетевой).
Первоначально DRBD использовалось главным образом в компьютерных кластерах высокой доступности (HA — high availability), однако, начиная с девятой версии, оно может использоваться для развертывания решений облачного хранилища.
В этой статье мы расскажем, как установить DRBD в CentOS, и кратко продемонстрируем, как использовать его для репликации хранилища (раздела) на двух серверах. Это идеальная статья для начала работы с DRBD в Linux.
Тестовая среда
Мы будем использовать кластер из двух узлов для этого сетапа.
- Узел 1: 192.168.56.101 – tecmint.tecmint.lan
- Узел 2: 192.168.56.102 – server1.tecmint.lan
Шаг 1: Установка пакетов DRBD
DRBD реализован как модуль ядра Linux. Он представляет из себя драйвер для виртуального блочного устройства, поэтому он располагается в самом низу стека ввода-вывода системы.
DRBD может быть установлен из ELRepo или EPEL. Начнем с импорта ключа подписи пакета ELRepo и подключения репозитория на обоих узлах, как показано ниже.
Затем на нужно установить модуль ядра DRBD и утилиты на обоих узлах с помощью:
Если у вас подключен SELinux, вам нужно настроить политики так, чтобы освободить процессы DRBD от контроля SELinux.
Кроме того, если в вашей системе работает файрвол (firewalld), вам необходимо добавить порт DRBD 7789, чтобы разрешить синхронизацию данных между двумя узлами.
Запустите эти команды для первого узла:
Затем запустите эти команды для второго узла:
Шаг 2. Подготовка низкоуровневого хранилища
Теперь, когда у нас установлено DRBD на обоих узлах кластера, мы должны подготовить на них области хранения примерно одного и того же размера. Это может быть раздел жесткого диска (или целый физический жесткий диск), программное устройство RAID, логический том LVM или любой другой тип блочного устройства, находящийся в вашей системе.
Для этой статьи мы создадим тестовое блочное устройство размером 2 ГБ с помощью команды dd.
Предположим, что это неиспользуемый раздел (/dev/sdb1) на втором блочном устройстве (/dev/sdb), подключенном к обоим узлам.
Шаг 3. Настройка DRBD
Основной файл конфигурации DRBD — /etc/drbd.conf , а дополнительные файлы конфигурации можно найти в каталоге /etc/drbd.d .
Чтобы реплицировать хранилище, нам нужно добавить необходимые для этого конфигурации в файл /etc/drbd.d/global_common.conf , который содержит глобальные и общие разделы конфигурации DRBD, а определять ресурсы нам нужно в .res файлах.
Сделаем резервную копию исходного файла на обоих узлах, а затем откроем новый файл для редактирования (используйте текстовый редактор по своему вкусу).
Добавьте в оба файла следующие строки:
Сохраните файл, а затем закройте редактор.
Давайте ненадолго остановимся на строке protocol C. DRBD поддерживает три различных режима репликации (т.е. три степени синхронности репликации), а именно:
- protocol A: протокол асинхронной репликации; чаще всего используется в сценариях репликации на больших расстояниях.
- protocol B: протокол полусинхронной репликации или протокол синхронной памяти.
- protocol C: обычно используется для узлов в сетях с небольшими расстояниями; это безусловно, наиболее часто используемый протокол репликации в настройках DRBD.
Важно: выбор протокола репликации влияет на два фактора развертывания: защиту и задержку. А пропускная способность, напротив, не зависит в значительной степени от выбранного протокола репликации.
Шаг 4. Добавление ресурса
Ресурс (Resource) — это собирательный термин, который относится ко всем аспектам конкретного реплицируемого набора данных. Мы определим наш ресурс в файле /etc/drbd.d/test.res .
Добавьте следующее в файл на обоих узлах (не забудьте заменить переменные фактическими значениями для вашей среды).
Обратите внимание на имена хостов, нам нужно указать сетевое имя хоста, которое можно получить с помощью команды uname -n .
- on hostname: раздел on, к которому относится вложенный оператор конфигурации.
- test: это имя нового ресурса.
- device /dev/drbd0: указывает новое виртуальное блочное устройство, управляемое DRBD.
- disk /dev/sdb1: это раздел блочного устройства, который является резервным устройством для устройства DRBD.
- meta-disk: определяет, где DRBD хранит свои метаданные. Internal означает, что DRBD хранит свои метаданные на том же физическом низкоуровневом устройстве, что и фактические данные на продакшене.
- address: указывает IP-адрес и номер порта соответствующего узла.
Также обратите внимание, что если на обоих хостах параметры имеют одинаковые значения, вы можете указать их непосредственно в разделе ресурсов.
Например, приведенная выше конфигурация может быть реструктурирована в:
Шаг 5. Инициализация и запуск ресурса
Для взаимодействия с DRBD мы будем использовать следующие инструменты администрирования (которые взаимодействуют с модулем ядра для настройки и администрирования ресурсов DRBD):
- drbdadm: инструмент администрирования высокого уровня DRBD.
- drbdsetup: инструмент администрирования более низкого уровня для подключения устройств DRBD к их устройствам резервного копирования, настройки пар устройств DRBD для отражения их устройств резервного копирования и для проверки конфигурации работающих устройств DRBD.
- Drbdmeta: инструмент управления метаданными.
После добавления всех начальных конфигураций ресурса мы должны вызвать ресурс на обоих узлах.
Инициализация хранилища метаданных
Далее мы должны запустить его, что подключит ресурс к его устройству резервного копирования, затем установит параметры репликации и подключит ресурс к своему пиру:
Теперь, если вы запустите команду lsblk, вы заметите, что устройство/том DRBD drbd0 связан с резервным устройством /dev/sdb1 :
Список блочных устройств
Чтобы отключить ресурс, запустите:
Чтобы проверить состояние ресурса, выполните запустите следующую команду (обратите внимание, что на этом этапе ожидается состояние дисков Inconsistent/Inconsistent):
Проверка состояния ресурса на у
злах
Шаг 6: Установка основного ресурса/источника начальной синхронизации устройств
На данном этапе DRBD уже готов к работе. Теперь нам нужно указать, какой узел следует использовать в качестве источника начальной синхронизации устройств.
Запустите следующую команду только на одном узле, чтобы начать первоначальную полную синхронизацию:
Установка основного узла в качестве начального устройства
После завершения синхронизации состояние обоих дисков должно быть UpToDate.
Шаг 7: Тестирование DRBD сетапа
Наконец, нам нужно проверить, будет ли DRBD устройство работать так как нужно для хранения реплицированных данных. Помните, что мы использовали пустой том диска, поэтому мы должны создать файловую систему на устройстве и смонтировать ее, чтобы проверить, можем ли мы использовать ее для хранения реплицированных данных.
Нам нужно создать файловую систему на устройстве с помощью следующей команды на узле, с которого мы начали первоначальную полную синхронизацию (на котором есть ресурс с основной ролью):
Создаем файловую систему на томе Drbd
Затем смонтировать ее как показано (вы можете дать точке монтирования подходящее имя):
Теперь скопируйте или создайте какие-нибудь файлы в указанной выше точке монтирования и сделайте длинный список с помощью команды ls:
Вывести список содержимого основного тома Drbd
Далее размонтируйте устройство (убедитесь, что монтирование не открыто, измените каталог после размонтирования, чтобы избежать ошибок) и измените роль узла с первичного на вторичный:
Другой узел (на котором есть ресурс с вторичной ролью) сделайте первичным, затем подключите к нему устройство и выполните длинный список точек монтирования. Если сетап работает нормально, все файлы, хранящиеся на томе, должны быть там:
Проверка сетапа DRBD, работающего на вторичном узле.
Для получения дополнительной информации обращайтесь к справочным страницам инструментов администрирования:
Резюме
DRBD чрезвычайно гибок и универсален, что делает его решением для репликации хранилища, подходящим для добавления HA практически в любое приложение. В этой статье мы показали, как установить DRBD в CentOS 7, и кратко продемонстрировали, как использовать его для репликации хранилища. Не стесняйтесь делиться своими мыслями с нами с помощью формы обратной связи ниже.
Источник
Высокая доступность веб-сайта: георепликация файлов сайта с lsyncd
Высокая доступность веб-сайта — совместная работа хостинг-провайдера и разработчика сайта. Основная цель обеспечения высокой доступности — минимизация запланированных и незапланированных простоев.
Высокая доступность — это больше, чем просто размещение вашего проекта в надежном облаке. По-настоящему высокодоступный сайт должен работать в нескольких регионах облака и его пользователи не должны замечать каких-то изменений даже если один из регионов облака станет недоступным. Разработчик веб-сайта должен обеспечить работоспособность сайта даже в случае чрезвычайной ситуации. Системы высокой доступности дублируются: при сбое у провайдера сайт будет доступен. При сбое репликации пользователя сайт также должен быть доступен. Если необходимо провести работы на сервере разработчику или перезагрузить его — пользователи не должны замечать этого.

В этом цикле статей мы рассмотрим способы организации высокой доступности различных подсистем вашего сайта. Многие задачи имеют различные решения. Автор не утверждает, что здесь представлено лучшее решение, но оно вполне работоспособно и проверено на практике. Однако поле для экспериментов по увеличению доступности огромно.
Сегодня мы рассмотрим синхронизацию статического сайта между регионами облака: изменения в файлах на одном из серверов должны появляться и на другом. Также мы рассмотрим простейший способ перенаправить пользователей вашего сайта на альтернативный сервер с помощью нескольких А-записей DNS, применимый для этого случая.
Lsyncd
Lsyncd (Live Syncing Daemon) – приложение для своевременного интерактивного зеркалирования данных серверов для использования в кластерах высокой доступности. Особенно хорошо lsyncd подходит для систем с небольшим трафиком синхронизации. Приложение собирает информацию об изменениях данных через подсистему ядра Linux inotify в течение определенного в конфигурации периода и запускает процессы зеркалирования изменений (через rsync по умолчанию, но есть и другие варианты). По-умолчанию lsyncd запускается как демон в фоне и протоколирует свои действия с помощью syslog. Для целей тестирования можно запустить приложение без демонизации, чтобы видеть происходящие действия в терминале для отладки.
Lsyncd не использует отдельную файловую систему или блочное устройство и не влияет сильно на производительность локальной файловой системы.
Использование опции Rsync + SSH позволяет передавать файлы сразу в целевую директорию вместо передачи места размещения на удаленный сервер.
Установка и настройка георепликации файлов веб-сервера
Получение доступа к разным регионам InfoboxCloud
Закажите 2 подписки на InfoboxCloud в Москве и Амстердаме для создания геораспределенного решения.
Для того, чтобы подписки были привязаны к единому аккаунту пользователя действовать нужно так:
1. Зайдите на http://infoboxcloud.ru и закажите облачную инфраструктуру в любом регионе (например в Амстердаме). Далее войдите в панель управления и закажите облако в другом регионе (например в Москве), как показано ниже.
После заказа выйдите из панели управления и войдите вновь. Теперь вы можете выбирать регион, в котором происходит работа, в правом верхнем углу панели управления:

Создайте 2 сервера: один в Москве, другой в Амстердаме.

В качестве операционной системы выберите CentOS 7. В статье рассматривается именно она, но можно использовать и другую операционную систему Linux при необходимости. При этом настройки могут отличаться. Вы можете использовать любой тип виртуализации на выбор. Разница для конкретного сценария в том, что если вы не поставите галочку «разрешить управление ядром ОС» — сможете использовать автомасштабирование по памяти для серверов, что позволит использовать ресурсы эффективнее. А если поставите — сможете настроить подсистему ядра inotify, что будет полезно при высоких нагрузках (пример настройки), но не имеет смысла для обычного небольшого сайта. Обязательно при создании каждого из серверов добавьте по одному публичному ip–адресу, чтобы к серверам был доступ из внешней сети:

После создания серверов данные для доступа придут к вам на email.
Настройка DNS
Для основного домена, сайт на котором должен быть высокодоступен, создайте две А-записи DNS, указывающие на сервер в Москве и сервер в Амстердаме. В нашем случае сайт будет failover.trukhin.com.
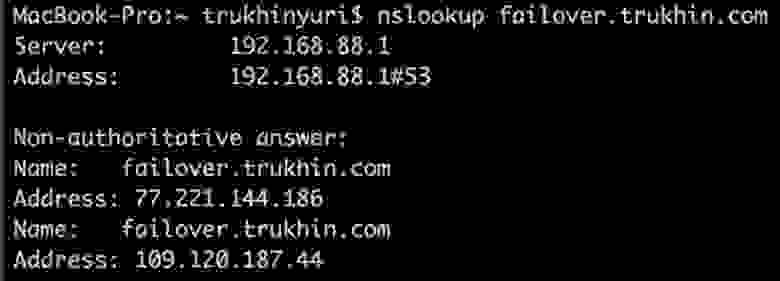
Создайте служебные поддомены, A–запись которых должна указывать на свой сервер. Например failovermsk.trukhin.com указывает на сервер в Москве, а failoverams.trukhin.com указывает на сервер в Амстердаме. Отдельные поддомены для каждого из серверов нужны, чтобы, в случае если сервер выйдет из строя, с резервного сервера развернуть еще реплику и перенаправить поддомен на нее.
Настройка серверов
Указанные ниже действия нужно провести на обоих серверах.
Подключитесь по SSH к обоим серверам. Установите Apache на каждом из серверов, запустите его и добавьте в автозагрузку:
Создайте файл index.html в директории /var/www/html каждого из серверов и убедитесь, что страница корректно открывается в браузере с каждого из серверов.
Для работы lsyncd нужно, чтобы был предоставлен доступ к каждому из серверов по ключу друг для друга.
Сгенерируйте ключ SSH (на вопросы можно просто нажать Enter):
С сервера в Москве добавьте ключ на сервер в Амстердаме:
С сервера в Амстердаме добавьте ключ на сервер в Москве:
Теперь подключитесь с сервера в Москве (root@failovermsk.trukhin.com) к серверу в Амстердаме (root@failoverams.trukhin.com) и наоборот. Пароль запрашиваться не должен. На вопросы при подключении ответьте yes.
Устанавливаем и настраиваем lsyncd
Указанные ниже действия нужно провести на обоих серверах.
Для установки lsyncd в CentOS 7 добавьте репозиторий EPEL командой:
Теперь установите lsyncd:
Создайте директорию для хранения логов и временных файлов lsyncd:
Создайте файл конфигурации lsyncd по адресу: /etc/lsyncd.conf
Значение host: failovermsk.trukhin.com замените на поддомен, направленный только на сервер в другом регионе. В source указывается папка на текущем сервере. В targetdir указывается папка на удаленном сервере. Параметр delay – период, через который будет выполняться синхронизация изменений на сервере. Данное значение подобрано экспериментальным путем, значение по умолчанию — 10. Полностью все параметры lsyncd можно найти в официальной документации.
Для отладки установите параметр nodaemon=true и сохраните изменения. Создайте файл на одном из серверов:
Запустите lsyncd вручную для проверки, что все корректно синхронизируется.

Если все прошло хорошо — на сервере в другом регионе в папке /var/www/html вы увидите созданный тестовый файл.

Теперь верните значение nodaemon=false в /etc/lsyncd.conf. Добавьте lsyncd в автозагрузку и запустите сервис:
Убедитесь, что данные реплицируются и после перезагрузки.
Репликация в 2 стороны
Чтобы работала репликация и в обратную сторону — на сервере в другом регионе проведите такие же настройки, но в файле конфигурации lsyncd укажите адрес первого сервера. Проверьте, что данные реплицируются и в обратном направлении. В конфигурации lsyncd уже указана временная директория temp_dir, использование которой необходимо для двусторонней синхронизации.
Реплицировать в 2 стороны необходимо не всегда, так как в mysql не рекомендуется использовать master-master репликацию и в случае выхода первого сервера из строя при использовании такой базы данных придется настроить репликацию из второго рабочего сервера на третий. Это делается просто, если мы заранее подготовим шаблон резервного сервера для облака, о чем будет рассказано в последующих статьях. Сегодня мы работаем только с файлами и для статического сайта двусторонняя репликация вполне применима.
Проверяем доступность сайта
Давайте зайдем на наш сайт:

Оба сервера доступны.
Далее выключим сервер в Москве.

Наш сайт доступен:
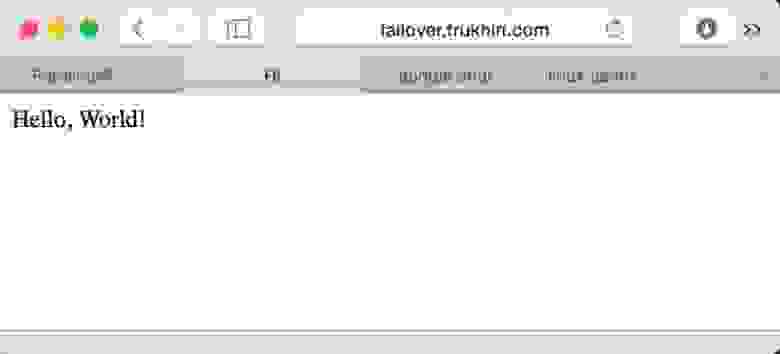
Включим сервер в Москве и выключим в Амстердаме:

Наш сайт доступен:

Почему это работает?
Современные браузеры при наличии нескольких А-записей сначала пытаются зайти на один ip–адрес, а если он не доступен — на другой. Таким образом если хотя бы один сервер доступен — сайт будет работать.
Данный подход в более сложном виде давно используется большими сайтами и резервных серверов для них сделано много. Например у Google их 11:

Заключение
В данной статье мы рассмотрели как настроить георепликацию для статического сайта без базы данных. В последующих статьях мы рассмотрим, как реплицировать базу данных и обеспечивать высокую доступность для более сложных сайтов.
Если вы обнаружили ошибку в статье, автор ее с удовольствием исправит. Пожалуйста напишите в ЛС или на почту о ней. Если вы не можете оставлять комментарии на Хабре — напишите их в Сообществе InfoboxCloud.
Источник



