- Резервное копирование и восстановление
- Восстановление после сбоя
- Логическое резервирование (SQL)
- Пример
- Скрипт для резервирования БД
- Дополнительная информация по изучению PostgreSQL
- Крупнейшая в Европе школа английского языка
- Онлайн школа английского языка
- Школа английского языка по Skype
- Backup and restore in Azure Database for PostgreSQL — Single Server
- Backups
- Backup frequency
- Servers with up to 4-TB storage
- Servers with up to 16-TB storage
- Backup retention
- Backup redundancy options
- Backup storage cost
- Restore
- Point-in-time restore
- Geo-restore
- Perform post-restore tasks
- Бэкап и восстановление базы 1С в бд postgresql, обслуживание базы
- Введение
- Бэкап и восстановление базы 1C в бд postgresql
- Использование программы PostgreSQL Backup
- Обновление статистики и реиндексация в postgresql
- Заключение
Резервное копирование и восстановление
Резервное копирование и восстановление в PostgreSQL. Существуют три принципиально различных подхода к резервному копированию данных PostgreSQL:
Восстановление после сбоя
Если работа сервера аварийно завершается, в логе сервера появляется сообщение с уровнем важности PANIC.
Восстановление после сбоя. Все изменения данных записываются на диск только после их гарантированного журналирования в WAL. Следует заметить, что изменения в базе данных не пишутся на диск в момент фиксации транзакции. Они записываются позже в фоновом процессе.
В логе WAL есть контрольный точки (checkpoints).

Логическое резервирование (SQL)
Ключи pg_dump:
Логическое резервирование заключается в создании текстового файла с командами SQL. Такой файл можно передать обратно на сервер и воссоздать базу данных в том же состоянии, в котором она была во время бэкапа. У PostgreSQL для этого есть специальная утилита — pg_dump. При выполнении pg_dump, таблицы блокируются минимально, только запрет на изменение структуры таблицы.
базу данных «dbname» потребуется создать перед восстановлением и пользователя (которому принадлежит восстанавливаемая база данных)
Пример
Пример: Полное логическое (SQL) резервирование и восстановление БД mbillcz5054. Алгоритм:
Если вы хотите исключить какие-либо таблицы из дампа, не забудьте сделать схему этой таблицы, чтобы в будущем Вы ее могли восстановить на новом сервере, например исключим таблицу cdr из дампа и создадим ее схему:
Скрипт для резервирования БД
Запускаем еженедельно при помощи Anacron (если установлено) или Использование планировщика cron в Linux, для этого создаем символическую ссылку в директорию /etc/cron.weekly
Дополнительная информация по изучению PostgreSQL
Обучение PostgreSQL. Полный курс по работе с базой данных PostgreSQL!
Курс включает в себя все инструменты: управление доступом, резервное копирование, репликация, журналирование, работа со статистикой, способы масштабирование, а также работа PostgreSQL в облаках AWS, GCP, Azure и в Kubernetes. Проверь свои знания — пройди тестирование
Крупнейшая в Европе школа английского языка
Промокоды, акции и подарки, чтобы Ваше обучение было не только интересным, но и выгодным. Закажите пробный урок уже сейчас!
Онлайн школа английского языка
Английский по скайпу от 680р за урок, без заучивания правил. Эффективно! Удобно! Выгодно! Начните обучение прямо сейчас.
Школа английского языка по Skype
Персональные занятия по разумным ценам. Бесплатные ресурсы для студентов: разговорные клубы, блог, вебинары, книги, тест на определение уровня английского. Пробный урок бесплатно!
Backup and restore in Azure Database for PostgreSQL — Single Server
Azure Database for PostgreSQL automatically creates server backups and stores them in user configured locally redundant or geo-redundant storage. Backups can be used to restore your server to a point-in-time. Backup and restore are an essential part of any business continuity strategy because they protect your data from accidental corruption or deletion.
Backups
Azure Database for PostgreSQL takes backups of the data files and the transaction log. Depending on the supported maximum storage size, we either take full and differential backups (4-TB max storage servers) or snapshot backups (up to 16-TB max storage servers). These backups allow you to restore a server to any point-in-time within your configured backup retention period. The default backup retention period is seven days. You can optionally configure it up to 35 days. All backups are encrypted using AES 256-bit encryption.
These backup files cannot be exported. The backups can only be used for restore operations in Azure Database for PostgreSQL. You can use pg_dump to copy a database.
Backup frequency
Servers with up to 4-TB storage
For servers which support up to 4-TB maximum storage, full backups occur once every week. Differential backups occur twice a day. Transaction log backups occur every five minutes.
Servers with up to 16-TB storage
In a subset of Azure regions, all newly provisioned servers can support up to 16-TB storage. Backups on these large storage servers are snapshot-based. The first full snapshot backup is scheduled immediately after a server is created. That first full snapshot backup is retained as the server’s base backup. Subsequent snapshot backups are differential backups only. Differential snapshot backups do not occur on a fixed schedule. In a day, three differential snapshot backups are performed. Transaction log backups occur every five minutes.
Backup retention
Backups are retained based on the backup retention period setting on the server. You can select a retention period of 7 to 35 days. The default retention period is 7 days. You can set the retention period during server creation or later by updating the backup configuration using Azure portal or Azure CLI.
The backup retention period governs how far back in time a point-in-time restore can be retrieved, since it’s based on backups available. The backup retention period can also be treated as a recovery window from a restore perspective. All backups required to perform a point-in-time restore within the backup retention period are retained in backup storage. For example — if the backup retention period is set to 7 days, the recovery window is considered last 7 days. In this scenario, all the backups required to restore the server in last 7 days are retained. With a backup retention window of seven days:
- Servers with up to 4-TB storage will retain up to 2 full database backups, all the differential backups, and transaction log backups performed since the earliest full database backup.
- Servers with up to 16-TB storage will retain the full database snapshot, all the differential snapshots and transaction log backups in last 8 days.
Backup redundancy options
Azure Database for PostgreSQL provides the flexibility to choose between locally redundant or geo-redundant backup storage in the General Purpose and Memory Optimized tiers. When the backups are stored in geo-redundant backup storage, they are not only stored within the region in which your server is hosted, but are also replicated to a paired data center. This provides better protection and ability to restore your server in a different region in the event of a disaster. The Basic tier only offers locally redundant backup storage.
Configuring locally redundant or geo-redundant storage for backup is only allowed during server create. Once the server is provisioned, you cannot change the backup storage redundancy option.
Backup storage cost
Azure Database for PostgreSQL provides up to 100% of your provisioned server storage as backup storage at no additional cost. Any additional backup storage used is charged in GB per month. For example, if you have provisioned a server with 250 GB of storage, you have 250 GB of additional storage available for server backups at no additional charge. Storage consumed for backups more than 250 GB is charged as per the pricing model.
You can use the Backup Storage used metric in Azure Monitor available in the Azure portal to monitor the backup storage consumed by a server. The Backup Storage used metric represents the sum of storage consumed by all the full database backups, differential backups, and log backups retained based on the backup retention period set for the server. The frequency of the backups is service managed and explained earlier. Heavy transactional activity on the server can cause backup storage usage to increase irrespective of the total database size. For geo-redundant storage, backup storage usage is twice that of the locally redundant storage.
The primary means of controlling the backup storage cost is by setting the appropriate backup retention period and choosing the right backup redundancy options to meet your desired recovery goals. You can select a retention period from a range of 7 to 35 days. General Purpose and Memory Optimized servers can choose to have geo-redundant storage for backups.
Restore
In Azure Database for PostgreSQL, performing a restore creates a new server from the original server’s backups.
There are two types of restore available:
- Point-in-time restore is available with either backup redundancy option and creates a new server in the same region as your original server.
- Geo-restore is available only if you configured your server for geo-redundant storage and it allows you to restore your server to a different region.
The estimated time of recovery depends on several factors including the database sizes, the transaction log size, the network bandwidth, and the total number of databases recovering in the same region at the same time. The recovery time varies depending on the the last data backup and the amount of recovery needs to be performed. It is usually less than 12 hours.
If your source PostgreSQL server is encrypted with customer-managed keys, please see the documentation for additional considerations.
If you want to restore a deleted PostgreSQL server, follow the procedure documented here.
Point-in-time restore
Independent of your backup redundancy option, you can perform a restore to any point in time within your backup retention period. A new server is created in the same Azure region as the original server. It is created with the original server’s configuration for the pricing tier, compute generation, number of vCores, storage size, backup retention period, and backup redundancy option.
Point-in-time restore is useful in multiple scenarios. For example, when a user accidentally deletes data, drops an important table or database, or if an application accidentally overwrites good data with bad data due to an application defect.
You may need to wait for the next transaction log backup to be taken before you can restore to a point in time within the last five minutes.
If you want to restore a dropped table,
- Restore source server using Point-in-time method.
- Dump the table using pg_dump from restored server.
- Rename source table on original server.
- Import table using psql command line on original server.
- You can optionally delete the restored server.
It is recommended not to create multiple restores for the same server at the same time.
Geo-restore
You can restore a server to another Azure region where the service is available if you have configured your server for geo-redundant backups. Servers that support up to 4 TB of storage can be restored to the geo-paired region, or to any region that supports up to 16 TB of storage. For servers that support up to 16 TB of storage, geo-backups can be restored in any region that support 16 TB servers as well. Review Azure Database for PostgreSQL pricing tiers for the list of supported regions.
Geo-restore is the default recovery option when your server is unavailable because of an incident in the region where the server is hosted. If a large-scale incident in a region results in unavailability of your database application, you can restore a server from the geo-redundant backups to a server in any other region. There is a delay between when a backup is taken and when it is replicated to different region. This delay can be up to an hour, so, if a disaster occurs, there can be up to one hour data loss.
During geo-restore, the server configurations that can be changed include compute generation, vCore, backup retention period, and backup redundancy options. Changing pricing tier (Basic, General Purpose, or Memory Optimized) or storage size is not supported.
If your source server uses infrastructure double encryption, for restoring the server, there are limitations including available regions. Please see the infrastructure double encryption for more details.
Perform post-restore tasks
After a restore from either recovery mechanism, you should perform the following tasks to get your users and applications back up and running:
- If the new server is meant to replace the original server, redirect clients and client applications to the new server. Also change the user name also to username@new-restored-server-name .
- Ensure appropriate server-level firewall and VNet rules are in place for users to connect. These rules are not copied over from the original server.
- Ensure appropriate logins and database level permissions are in place
- Configure alerts, as appropriate
Бэкап и восстановление базы 1С в бд postgresql, обслуживание базы

Во время работы с базой данных postgresql в 1С необходимо периодически выполнять задачи по бэкапу базы данных и ее восстановлению. Для увеличения производительности рекомендуется регулярно проводить очистку, анализ и переиндексацию базы 1С. Для автоматизации процессов по архивации и обслуживанию я написал небольшие скрипты с пояснениями. Ими и хочу поделиться с вами.
Данная статья является частью единого цикла статьей про сервер Debian.
Введение
Ранее я рассказывал о том, как установить и настроить postgresql для работы с 1С, а затем как провести анализ производительности базы 1С и по возможности увеличить быстродействие. После успешного выполнения первых двух задач, мы можем приступать к эксплуатации системы. Когда рабочая база 1С уже на сервере, обязательно нужно настроить ее регулярный бэкап. Желательно так же периодически проводить очистку и переиндексацию sql базы. Это увеличит ее быстродействие. Выполнять эти операции лучше всего автоматически, в нерабочее время. Именно этим мы и займемся в этой статье.
Бэкап и восстановление базы 1C в бд postgresql
Способов бэкапа базы данных postgresql много. Я буду использовать самый простой — выгрузка базы данных в обычный текстовый sql скрипт с помощью pg_dump. Подробно о работе этой утилиты и ее настройках можно прочитать вот тут — https://postgrespro.ru/docs/postgrespro/9.6/app-pgdump. В сети много примеров и готовых скриптов для решения вопроса архивации баз postgresql. Например, есть вот такой скрипт. Когда я его увидел, мне просто стало лень с ним разбираться. Написать простенький свой мне гораздо проще.
Прежде чем делать непосредственно архив 1С базы, нам нужно разрешить подключаться локально к серверу бд без авторизации. Я единственный пользователь сервера, доступа к нему никто больше не имеет, в интернет он не опубликован, поэтому я сознательно иду на этот шаг, чтобы упростить себе работу. Если для вас этот вариант не подходит, то все дальнейшие скрипты вам нужно будет самим изменить, добавив в них авторизацию. Это не сложно, в описании команд все есть. Я буду все команды выполнять локально от пользователя root.
Редактируем в файле /etc/postgresql/9.6/main/pg_hba.conf строку, приведя ее к такому виду:
После этого надо перезапустить постгрес, чтобы изменения вступили в силу.
Бэкап базы данных выполняется простой командой:
| postgres | имя пользователя базы данных |
| base1c | название бд с 1С |
| pigz | архиватор |
| base1c.sql.gz | файл, куда будет сохранена резервная копия |
Обращаю внимание на архиватор pigz. Я его использую, потому что он умеет жать данные, нагружая все ядра процессора, в отличие от gzip. Прирост производительности 2-3 раза. Рекомендую. На debian он ставится из стандартного репозитория:
В centos из epel:
Попробуйте вручную в консоли выполнить команду и посмотреть на результат. Вы должны получить заархивированный файл с текстовыми sql командами в открытом виде. Теперь попробуем восстановить базу данных 1С из архива. Тут будут нюансы. Первым делом разархивируем файл:
Файл будет распакован, а архив удален. Чтобы сохранить архив, можно использовать такую команду:
Создадим на сервере новую базу данных, в которую будем восстанавливать резервную копию. Перед этим посмотрим список баз данных на сервере:
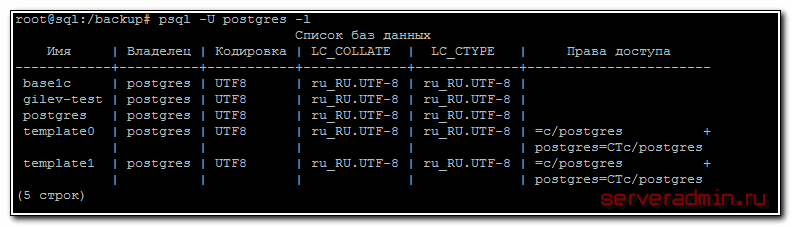
Создаем новую базу данных:
Смотрим, что получилось:
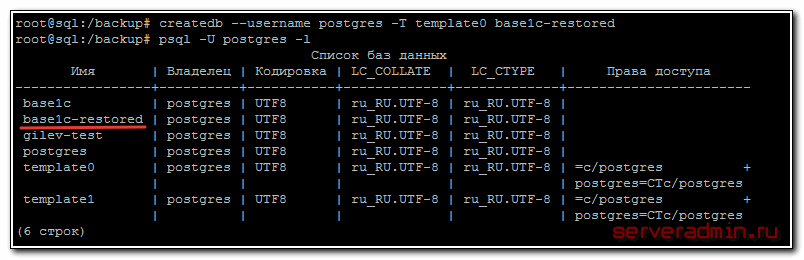
Базу данных создали. Теперь загружаем в нее наш бэкап 1с:
Ждем приличное время. Оно будет зависеть от размера базы. После того, как восстановление завершено, можно идти в консоль кластера 1С и добавлять новую базу, указывая в качестве базы postgresql только что созданную базу с загруженным архивом.
Я сначала пошел по другому пути. Создал в консоли пустую базу, загрузил в нее бэкап через консоль postgresql. Архив вроде бы загрузился, но в базу я не мог войти, не проходила авторизация. То есть возникли какие-то проблемы. Когда сделал, как описал выше, без проблем все заработало сразу. Проверил базу, все было в порядке.
После того, как вы убедитесь, что все в порядке, можно написать небольшой скрипт, который мы добавим в cron для регулярного бэкапа нашей базы 1С. Я его сделал совсем простым, ничего лишнего, только 1 база. Я считаю, что если баз не много и вручную не представляет труда написать несколько строчек скрипта, то лучше все сделать без циклов и лишних переменных. Если у вас больше одной базы, то просто скопируйте строки и замените названия баз. Вот сам скрипт:
Я указал в названии файла с бэкапом 1с базы использовать текущую дату с точностью до минуты. В лог я пишу информацию с точностью до секунды, чтобы было точно видно, сколько длился бэкап. Просто для справки информация, можно обойтись и без лога совсем. В конце удаляю из папки все архивы старше 3-х дней. Я обычно сервером с бэкапами забираю информацию с целевых хостов. То есть я буду подключаться к sql серверу и забирать с него архивы и уже на сервере бэкапов буду их хранить и ротировать в зависимости от желаемой глубины архива. А здесь я удаляю почти сразу архивы, не храню их, чтобы не занимать место. Если вы будете хранить их долгосрочно на этом же сервере, то просто измените цифру 3 на нужное вам число дней, за которые вы хотите иметь архивную копию своей базы 1С.
Использование программы PostgreSQL Backup
Для бэкапа базы данных постгрес есть удобная и бесплатная для двух баз программа под windows — PostgreSQL Backup. Я ее установил, проверил, сделал бэкап, потом восстановил из бэкапа. Все отлично работает. Из полезных функций:
- встроенный планировщик
- автоматическое сжатие бэкапа
- отправка оповещений на email
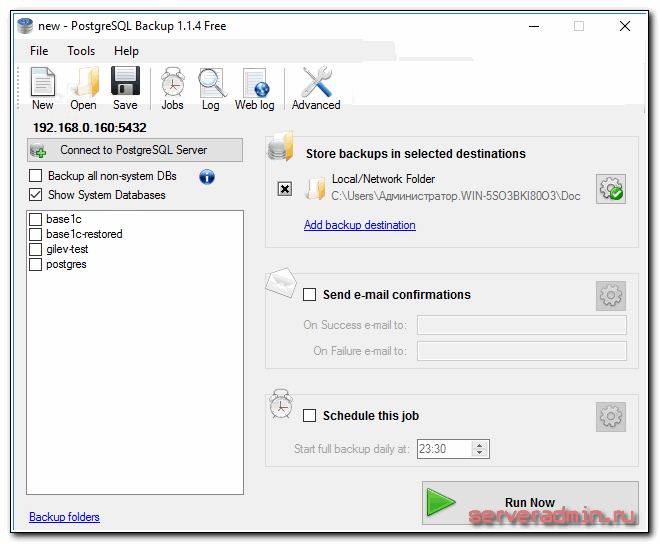
Программа, простая, понятная и приятная на вид. Попробуйте, возможно вам будет достаточно такого варианта. К сожалению, она не умеет восстанавливать из бэкапа. Для этого архив придется перенести на сервер, распаковать и загрузить в базу через консоль, как я показывал выше.
Обновление статистики и реиндексация в postgresql
С бэкапами разобрались, теперь настроим регламентные операции на уровне субд, чтобы поддерживать быстродействие базы данных. Тут особых комментариев не будет, в интернете очень много информации на тему регламентных заданий для баз 1С. Я просто приведу пример того, как это выглядит в postgresql.
Выполняем очистку и анализ базы данных 1С:
Реиндексация таблиц базы данных:
Завернем все это в скрипт с логированием времени выполнения команд:
Сохраняем скрипт и добавляем в планировщик. Хотя я для удобства сделал еще один скрипт, который объединяет бэкап и обслуживание и уже его добавил в cron:
Добавялем в /etc/crontab:
Проверяем лог файл и наличие бэкапа. Не забывайте делать проверочное регулярное восстановление бд из архива.
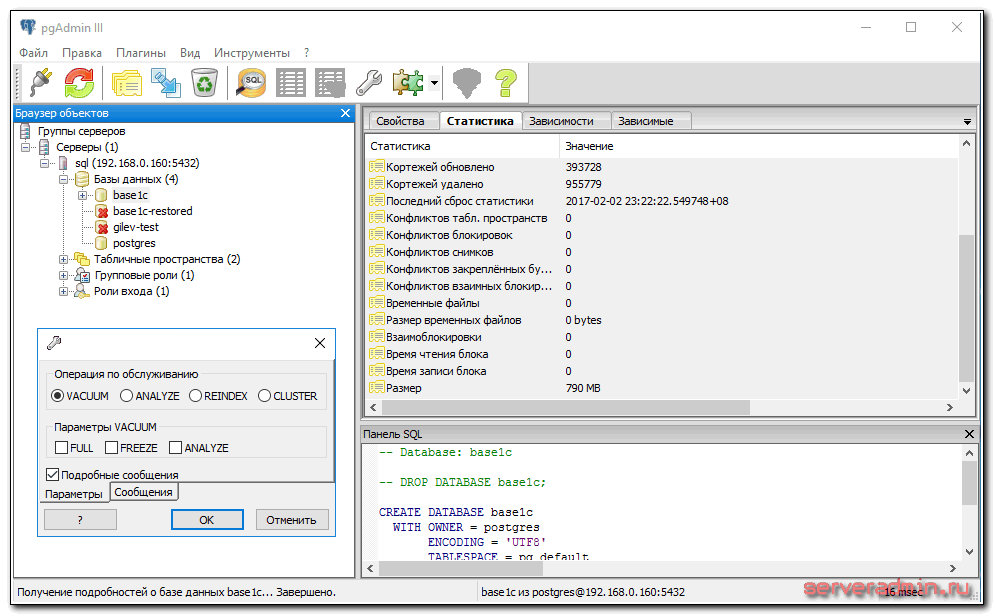
Описанные выше операции очистки и переиндексации можно делать в ручном режиме в программе под windows — pgAdmin. Рекомендую ее установить на всякий случай. Достаточно удобно и быстро можно посмотреть информацию или выполнить какие-то операции с базой данных посгрес.
Заключение
Вот и все, что я хотел рассказать по поводу бэкапа и обслуживания баз postgresql в связке с 1С. Если у кого есть еще полезная информация, прошу поделиться в комментариях. Возможно с бэкапом есть какие-то нюансы, особенно на больших базах. Но мне негде тестировать, больших рабочих баз более 10 гб у меня нет под рукой, а с теми что были, все отлично работает.
Напоминаю, что данная статья является частью единого цикла статьей про сервер Debian.



