Рихтер Дж., Назар К. — Windows via C C++. Программирование на языке Visual C++ — 2009
14 Часть I Материалы для обязательного чтения
Табл. 2-1. Наборы символов Unicode для различных алфавитов
Символьные и строковые типы данных для ANSI и Unicode
Уверен, вы знаете, что тип данных char в языке С представляет 8-битные ANSIсимволы. По умолчанию при объявлении в коде строки-литерала компилятор С преобразует составляющие строку символы в массив 8-битных значений типа char.
// 8-битный символ char с = „A‟;
// массив 99 8-битных символов с нулем в конце (также 8-битным) char szBuffer[100] = “А String”;
Созданный Майкрософт компилятор С/С++ поддерживает встроенный тип данных wchar_t , представляющий 16-битные символы Unicode (в кодировке UTF16). Прежние версии компилятора Майкрософт не поддерживали этот тип данных как встроенный и работали с ним только при указании параметра компилятора /Zc:wchar_t. Этот параметр компилятора установлен по умолчанию при создании С++-проекта в Microsoft Visual Studio. Рекомендуется всегда устанавливать этот параметр, поскольку с Unicode-символами лучше работать с использованием встроенных примитивных типов, понятных компилятору без «посредников».
Примечание . Пока компилятор не поддерживал встроенный тип данных wchar_t, этот тип определялся в заголовочном файле С следующим образом:
typedef unsigned short wchar_t;
Объявить Unicode-символ как строку можно следующим образом:
// 16-битный символ wchar_t с = „A‟;
Глава 2. Работа с символами и строками .docx 15
// Массив 99 16-битных символов о нулем в конце (16-битным) wchar_t szBuffer[100] = L»A String»;
Заглавная буква L перед литералом сообщает компилятору, что указанный литерал следует компилировать как Unicode-строку. В этом простом примере при размещении данной строки в секции данных программы компилятор кодирует ее в UTF-16, вставляя нулевые байты между ASCII-символами.
Разработчики Windows хотят определить собственный тип данных, чтобы в некоторой степени изолировать себя от языка С. Поэтому в заголовочном файле Windows, WinNT.h, определены следующие типы данных:
Кроме того, в заголовочном файле WinNT.h определен ряд общих типов данных для работы с указателями на символы и строки:
// указатель на 8-битные символы и строки typedef CHAR *PCHAR;
typedef CHAR *PSTR; typedef CONST CHAR *PCSTR
// указатель на 16-битные символы и строки typedef WCHAR *PWCHAR;
typedef WCHAR *PWSTR; typedef CONST WCHAR ♦PCWSTR;
Примечание . В файле WinNT.h есть следующее определение:
typedef __nullterminated WCHAR *NWPSTR, *LPWSTR, *PWSTR;
Префикс __nullterminated представляет собой заголовочную аннотацию (header annotation) , описывающую применение типов в качестве параметров и возвращаемых значений функций. В редакции Enterprise среды Visual Studio можно включить параметр Code Analysis в свойствах проекта. В результате в командную строку компилятора будет добавлен параметр /analyze. Он заставит компилятор проверять, не вызываются ли функции с нарушением семантики, предписанной аннотациями. Заметьте: только в версии Enterprise поддерживает параметр /analyze. Для простоты в этой книге заголовочные аннотации убраны из примеров кода. Подробнее о заголовочных аннотаци-
ях см. в статье MSDN «Header Annotations» ( http://msd2.microsoft.com/EnUS/library/aa383701.aspx ).
Независимо от того, какие именно типы данных вы используете в своем коде, рекомендую следить за их согласованностью ради удобства сопровождения вашего кода. Поскольку я программирую для Windows, я всегда использую типы данных Windows — они соответствуют документации MSDN, что существенно облегчает другим чтение моего кода.
16 Часть I Материалы для обязательного чтения
Можно написать код так, чтобы он компилировался с ANSI- и Unicodeсимволами. В заголовочном файле WinNT.h определены следующие типы данных и макросы:
typedef WCHAR TCHAR, *PTCHAR, PTSTR;
typedef CONST WCHAR *PCTSTR;
#define __TEXT(quote) quote
#define __TEXT(quote) L##quote
typedef CHAR TCHAR, *PTCHAR, PTSTR;
typedef CONST CHAR •PCTSTR;
#define __TEXT(quote) quote
#define TEXT(quote) __JEXT(quote)
Эти типы и макросы (и некоторые другие, менее востребованные и потому здесь не показанные) используются для создания код, который может компилироваться как с ANSI-, так и Unicode-символами, например:
// 16-битный символ, если определен UNICODE,
// или 8-битный символ в противном случае
TCHAR с = ТЕХТ („А‟);
// массив 16-битных символов, если определен UNICODE,
// либо 8-битных символов в противном случае
TCHAR szBuffer[100] = TEXT(«A String»);
Unicode- и ANSI-функции в Windows
Начиная с Windows NT, все версии Windows создаются на основе, включающей Unicode. Иными словами, все ключевые функции для создания окон, вывода текста, манипулирования строками и т.д. требуют Unicode-строки. Если любой Windows-функции передать при вызове ANSI-строку (строку 1-байтовых символов), эта функция сначала преобразует ANSI-строку в Unicode, и только после этого передаст ее операционной системе. Если некоторая функция должна возвращать ANSI-строку, операционная система преобразует Unicode-строку в ANSI и возвращает результат вашему приложению. Все эти преобразования выполняются незаметно для программиста и, естественно, вызывают дополнительный расход памяти и времени.
Глава 2. Работа с символами и строками .docx 17
Я уже говорил, что существует две функции CreateWindowEx : одна принимает строки в Unicode, другая — в ANSI. Все так, но в действительности прототипы этих функций чуть-чуть отличаются:
HWND WINAPI CreateWindowExW (DWORD dwExStyle,
HWND WINAPI CreateWindowExA (DWORD dwExStyle,
int nHeight, HWND hWndParent, HHENU hMenu,
HINSTANCE hInstance, PVOID pParam);
CreateWindowExW — это Unicode-версия. Буква W конце имени функции — аббревиатура слова wide (широкий). Символы Unicode занимают по 16 битов каждый, поэтому их иногда называют широкими символами (wide characters). Буква А в конце имени CreateWindowExA указывает, что данная версия функции принимает ANSI-строки.
Но обычно CreateWindowExW или CreateWindowExA напрямую не вызывают, а обращаются к CreateWindowEx — макросу, определенному в файле WinUser.h:
#define CreateWindowEx CreateWindowExW #else
#define CreateWindowEx CreateWindowExA #endif
18 Часть I Материалы для обязательного чтения
Какая именно версия CreateWindowEx будет вызвана, зависит от того, определен ли UNICODE в период компиляции. Перенося 16-разрядное Windowsприложение на платформу Win32, вы, вероятно, не станете определять UNICODE. Тогда все вызовы CreateWindowEx будут преобразованы в вызовы CreateWindowExA — ANSI-версии функции. И перенос приложения упростится, ведь 16разрядная Windows работает только с ANSI-версией CreateWindowEx .
В Windows Vista функция CreateWindowExA — просто шлюз (транслятор), который выделяет память для преобразования строк из ANSI в Unicode и вызывает CreateWindowExW , передавая ей преобразованные строки. Когда CreateWindowExW вернет управление, CreateWindowExA освободит буферы и передаст вам описатель окна.
Таким образом, при вызове функций, заполняющих буферы строками система должна преобразовать Unicode-строки в их эквиваленты, прежде чем ваше приложение сможет обработать строки. Из-за необходимости этих преобразований ваши приложения требуют больше памяти и медленнее работают. Чтобы повысить быстродействие приложений, следует с самого начала писать их в расчете на работу с Unicode-строками. Кроме того, в функциях, преобразующих строки, найдены ошибки, так что отказ от их использования уменьшает число потенциальных сбоев в приложениях.
Разрабатывая DLL, которую будут использовать и другие программисты, предусматривайте в ней по две версии каждой функции — для ANSI и для Unicode. В ANSI-версии просто выделяйте память, преобразуйте строки и вызывайте Unicode-версию той же функции. (Этот процесс я продемонстрирую позже.)
Некоторые функции Windows API (например, WinExec или OpenFile ) существуют только для совместимости с 16-разрядными программами, и их надо избегать. Лучше заменить все вызовы WinExec и OpenFile вызовами CreateProcess и CreateFile соответственно. Тем более что старые функции просто обращаются к новым. Самая серьезная проблема с ними в том, что они не принимают строки в Unicode, — при их вызове вы должны передавать строки в ANSI. С другой стороны, в Windows 2000 у всех новых или пока не устаревших функций обязательно есть как ANSI-, так и Unicode-версия.
Некоторые функции Windows API, такие как WinExec и OpenFile , существуют исключительно для преемственной совместимости с 16-разрядными Windowsприложениями, поддерживающими исключительно ANSI-строки. Использовать их в современных программах не следует. Вызовы WinExec и OpenFile следует заменять вызовами CreateProcess и CreateFile , устаревшие функции все равно вызывают новые функции. Основная проблема с устаревшими функциями в том, что они не принимают Unicode-строки и предоставляют меньше возможностей, при вызове им необходимо передавать ANSI-строки. В Windows Vista для большинства функций, не успевших устареть, существуют как Unicode-, так и ANSI-версии. Однако Майкрософт проявляет тенденцию к созданию функций, поддерживаю-
щих только Unicode, примерами могут быть ReadDirectoryChangesW и CreateProcessWithLogonW .
Глава 2. Работа с символами и строками .docx 19
При переносе СОМ из 16-разрядных версий Windows на Win32 руководство Майкрософт решило сделать так, чтобы все методы интерфейсов СОМ, требующие строки, принимали только Unicode-строки. Это было правильное решение, поскольку СОМ обычно применяют для организации «общения» различных компонентов, а Unicode обеспечивает максимум возможностей для передачи строковых данных. Таким образом, использование Unicode в приложении облегчает и взаимодействие с СОМ.
В итоге компилятор ресурсов обрабатывает все ваши ресурсы, записывая их в выходной файл в двоичном формате. Строковые ресурсы (таблицы, шаблоны диалоговых окон, меню и пр.) всегда записываются в файлы ресурсов в виде Unicodeстрок. Если в приложении не определен макрос UNICODE, в Windows Vista соответствующие преобразования выполняет система. Например, если при компиляции модуля не определен UNICODE, в результате вызова LoadString в действительности будет вызвана функция LoadStringA . LoadStringA прочитает Unicodeстроку из ресурса и преобразует ее в ANSI, а LoadString вернет приложению ANSI-представление строки.
Unicode- и ANSI-функции в библиотеке С
Подобно Windows, библиотека языка С поддерживает два набора функций: один для манипулирования ANSI-строками и символами, а другой — для работы с Un- icode-строками и символами. Однако, в отличие от Windows, здесь ANSI-функции выполняют свою работу. Они не преобразуют внутренне полученные строки в Unicode и не вызывают затем Unicode-версии тех же функций. Ну, и, конечно, Un- icode-версии сами делают то, что им положено, а не вызывают ANSI-версии.
Рихтер Дж., Назар К. — Windows via C C++. Программирование на языке Visual C++ — 2009
34 Часть I Материалы для обязательного чтения
// продвигаеися на 1 символ вправо. pWideCharStr++;
// продвигаемся на 1 символ влево.
// символы в строке переставлены, возвращаем управление. return(TRUE);
ANSI-версию этой функции можно написать так, чтобы она вообще ничем не занималась, а просто преобразовывала ANSI-строку в Unicode, передавала ее в функцию StringReverseW и конвертировала обращенную строку снова в ANSI. Тогда функция должна выглядеть примерно так:
BOOL StringReverseA(PSTR pMultiByteStr, DWORD cchLength) < PV(STR pWideCharStr;
int nLenOfWideCharStr; BOOL fOk = FALSE;
// вычисляем количество символов, необходимых
// для хранения широкосимвольной версии строки. nLenOfWideCharStr = MultiByteToWideChar(CP_ACP, 0,
pMultiByteStr, cchLength, NULL, 0);
// Выделяем память из стандартной кучи процесса,
// достаточную для хранения широкосимвольной строки.
// Не эабудьте, что MultiByteToWideChar возвращает
// количество символов, а не байтов, поэтому мы должны
// умножить это число на размер широкого символа. pWideCharStr = (PWSTR)HeapAlloc(GetProcessHeap(), 0,
if (pWideCharStr == NULL) return(fOk);
// преобразуем мультибайтовую строку в широкосимвольную
MultiByteToWideChar(CP_ACP, 0, pMultiByteStr, cchLength, pWideCharStr, nLenOfWideCharStr);
// вызываем широкосимвольную версию этой функции
// для выполнения настоящей работы
fOk = 8tringReverseW(pWideCharStr, cChLength);
// преобразуем широкосимвольную строку
// обратно в мультибайтовую.
Глава 2. Работа с символами и строками .docx 35
WideCharToMultiByte(CP_ACP, 0, pWideCharStr, cchLength, pMultiByteStr, (int)strlen(pMultiByteStr), NULL, NULL);
// освобождаем память, выделенную под широкобайтовую строку.
HeapFree(GetProcessHeap(), 0, pWideCharStr);
И, наконец, в заголовочном файле, поставляемом вместе с DLL, прототипы этих функций были бы такими:
B00L StringReverseW(PWSTR pWideCharStr, DWORD cchLength);
BOOL StringReverseA(PSTR pMultiByteStr, DWORD cchLength);
#define StringReverse StringReverseW #else
#define StringReverse StringReverseA #endif // !UNICODE
Определяем формат текста (ANSI или Unicode)
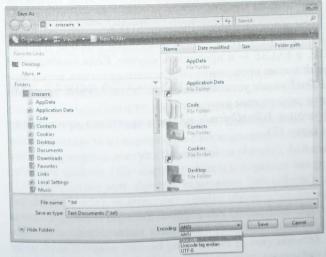
Блокнот Windows позволяет открывать и создавать как Unicode-, так и ANSIфайлы (см. диалог сохранения файла на рис. 2-5).
Рис. 2-5. Диалог сохранения файла в Блокноте Windows Vista
36 Часть I Материалы для обязательного чтения
Для многих обрабатывающих текстовые файлы приложений, к числу которых относятся и компиляторы, была бы полезной возможность определения формата открытого текстового файла (ANSI или Unicode). В этом поможет функция IsTextUnicode , поддерживаемая AdvApi32.dll и объявленная в WmBase.h:
BOOL IsTextUnicode(CONST PVOID pvBuffer, int cb, PINT pResult);
Проблема с текстовыми файлами в том, что их содержимое весьма разнообразно и нет четких правил, регламентирующих его. Поэтому чрезвычайно сложно определить, содержит ли файл ANSIили Unicode-символы. IsTextUnicode определяет тип содержимого буфера, используя ряд статистических и аналитических методов. Как сказано выше, точных критериев для этого не существует, следовательно, IsTextUnicode может ошибаться.
Первый параметр этой функции, pvBuffer , задает адрес анализируемого буфера. Используется void-указатель, поскольку при вызове функции не известно, находятся ли в массиве ANSIили Unicode-символы.
Второй параметр, cb , задает число байтов буфера, на который указывает pvBuffer . И в этом случае тип содержимого буфера заранее не известно, поэтому значение cb выражается в байтах, а не символах. Заметьте, что указывать размер целого буфера не обязательно. Естественно, чем больше байтов проверит IsTextUnicode , тем точнее будет ее результат.
Третий параметр, pResult , представляет адрес целого числа, который необходимо инициализировать перед вызовом IsTextUnicode , чтобы указать этой функции, какую проверку она должна выполнить. В этом параметре можно передавать NULL, и тогда IsTextUnicode выполнит все доступные тесты (подробнее об этом см. в документации Platform SDK).
Если IsTextUnicode определила, что в буфере находится Unicode-текст, то она возвращает TRUE, и FALSE — в противном случае. Если целочисленным параметром pRezult задано проведение определенных тестов, перед возвратом управления IsTextUnicode устанавливает в целочисленном значении биты, соответствующие результатам выполненных тестов.
Использование функции IsTextUnicode иллюстрируется в приложении примере FileRev (см. главу 17).
Г Л А В А 3 Объекты ядра.
Что такое объект ядра .
Учет пользователей объектов ядра .
Таблица описателей объектов ядра .
Создание объекта ядра .
Закрытие объекта ядра .
Совместное использование объектов ядра несколькими процессами .
Наследование описателя объекта .
Дублирование описателей объектов .
Изучение Windows API мы начнем с объектов ядра и их описателей (handles). Эта глава посвящена сравнительно абстрактным концепциям, т. е. мы, не углубляясь в специфику тех или иных объектов ядра, рассмотрим их общие свойства.
Я бы предпочел начать с чего-то более конкретного, но без четкого понимания объектов ядра вам не стать настоящим профессионалом в области разработки Windows-программ. Эти объекты используются системой и нашими приложениями для управления множеством самых разных ресурсов: процессами, потоками, файлами и т. д. Концепции, представленные здесь, будут встречаться на протяжении всей книги. Однако я прекрасно понимаю, что часть материалов не уляжется у вас в голове до тех пор, пока вы не приступите к работе с объектами ядра, используя реальные функции. И при чтении последующих глав книги вы, наверное, будете время от времени возвращаться к этой главе.
Глава 3. Объекты ядра .docx
Что такое объект ядра
Создание, открытие и прочие операции с объектами ядра станут для вас, как разработчика Windows-приложений, повседневной рутиной. Система позволяет создавать и оперировать с несколькими типами таких объектов, в том числе: маркерами доступа (access token objects), файлами (file objects), проекциями файлов
(file-mapping objects), портами завершения ввода-вывода (I/O completion port objects), заданиями (job objects), почтовыми ящиками (mailslot objects), мьютексами
(mutex objects), каналами (pipe objects), процессами (process objects), семафорами (semaphore objects), потоками (thread objects) и ожидаемыми таймерами (waitable timer objects), а также фабриками пула потоков (thread pool worker factory objects).
Бесплатная утилита WinObj от Sysinternals (ее можно скачать по ссылке http://www.microsoft . com/technet/sysintemak/utilities/winobj.mspx ) позволяет про-
сматривать списки типов объектов ядра (см. пример на следующей странице). Эту утилиту следует запускать из проводника из-под администраторской учетной записи.

12 Часть I Материалы для обязательного чтения
Эти объекты создаются Windows-функциями. Например, CreateFileMapping заставляет систему сформировать объект «проекция файла», связанный с соответствующим объектом «секция» (это можно увидеть с помощью WinObj). Каждый объект ядра — на самом деле просто блок памяти, выделенный ядром и доступный только ему. Этот блок представляет собой структуру данных, в элементах которой содержится информация об объекте. Некоторые элементы (дескриптор защиты, счетчик числа пользователей и др .) присутствуют во всех объектах , но бо ́ льшая их часть специфична для объектов конкретного типа. Например, у объекта «процесс» есть идентификатор, базовый приоритет и код завершения, а у объекта «файл» — смещение в байтах, режим разделения и режим открытия.
Поскольку структуры объектов ядра доступны только ядру, приложение не может самостоятельно найти эти структуры в памяти и напрямую модифицировать их содержимое. Такое ограничение Майкрософт ввела намеренно, чтобы ни одна программа не нарушила целостность структур объектов ядра. Это же ограничение позволяет Майкрософт вводить, убирать или изменять элементы структур, не нарушая работы каких-либо приложений.
Но вот вопрос: если мы не можем напрямую модифицировать эти структуры, то как же наши приложения оперируют объектами ядра? Ответ в том, что в Windows предусмотрен набор функций, обрабатывающих структуры
Глава 3. Объекты ядра .docx
объектов ядра по строго определенным правилам. Мы получаем доступ к объектам ядра только через эти функции. Когда вы вызываете функцию, создающую объект ядра, она возвращает описатель, идентифицирующий созданный объект. Описатель следует рассматривать как «непрозрачное» значение, которое может быть использовано любым потоком вашего процесса. Описатель представляет собой 32- (в 32-разрядных Windows-процессах) или 64-разрядное (в 64-разрядных Windows-процессах) значение. Этот описатель вы передаете Windows-функциям, сообщая системе, какой объект ядра вас интересует. Но об описателях мы поговорим позже (в этой главе).
Для большей надежности, операционной системы Майкрософт сделала так, чтобы значения описателей зависели от конкретного процесса. Поэтому, если вы передадите такое значение (с помощью какого-либо механизма межпроцессной связи) потоку другого процесса, любой вызов из того процесса со значением описателя, полученного в вашем процессе, даст ошибку. Но не волнуйтесь, в конце главы мы рассмотрим три механизма корректного использования несколькими процессами одного объекта ядра.
Учет пользователей объектов ядра
Объекты ядра принадлежат ядру, а не процессу. Иначе говоря, если ваш процесс вызывает функцию, создающую объект ядра, а затем завершается, объект ядра может быть не разрушен. В большинстве случаев такой объект все же разрушается; но если созданный вами объект ядра используется другим процессом, ядро запретит разрушение объекта до тех пор, пока от него не откажется и тот процесс.
Ядру известно, сколько процессов использует конкретный объект ядра, поскольку в каждом объекте есть счетчик числа его пользователей. Этот счетчик — один из элементов данных, общих для всех типов объектов ядра. В момент создания объекта счетчику присваивается 1. Когда к существующему объекту ядра обращается другой процесс, счетчик увеличивается на 1. А когда какой-то процесс завершается, счетчики всех используемых им объектов ядра автоматически уменьшаются на 1. Как только счетчик какого-либо объекта обнуляется, ядро уничтожает этот объект.
Объекты ядра можно защитить дескриптором защиты (security descriptor), который описывает, кто создал объект и кто имеет права на доступ к нему. Дескрипторы защиты обычно используют при написании серверных приложений. Однако в Windows Vista это свойство объектов ядра доступно и клиентским приложениям, обладающим собственными пространствами имен (подробнее см. ниже в этой, главе).
Почти все функции, создающие объекты ядра, принимают указатель на структуру SECURITY_ATTRIBUTES как аргумент, например:
14 Часть I Материалы для обязательного чтения
Большинство приложений вместо этого аргумента передает NULL и создает объект с защитой по умолчанию. Такая защита подразумевает, что создатель объекта и любой член группы администраторов получают к нему полный доступ, а все прочие к объекту не допускаются. Однако вы можете создать и инициализировать структуру SECURITY_ATTRIBUTES, а затем передать ее адрес. Она выглядит так:
typedef struct _SECURITY_ATTRIBUTES < DWORD nLength;
LPVOID lpSecurityDescriptor; BOOL bInheritHandle;
Хотя структура называется SECURITY_ATTRIBUTES, лишь один ее элемент имеет отношение к защите — lpSecurityDescriptor . Если надо ограничить доступ к созданному вами объекту ядра, создайте дескриптор защиты и инициализируйте структуру SECURITY_ATTRIBUTES следующим образом:
// используется для выяснения версий
// адрес инициализированной SD
HANDLE hFileMapping = CreateFileMapping(INVALID_HANDLE_VALUE, &sa, PA6E_READWRITE, 0, 1024, TEXT(«MyFileMapping»));
Рассмотрение элемента bInheritHandle я отложу до раздела о наследовании, так как этот элемент не имеет ничего общего с защитой.
Желая получить доступ к существующему объекту ядра (вместо того чтобы создавать новый), укажите, какие операции вы намерены проводить над объектом. Например, если бы я захотел считывать данные из существующей проекции файла, то вызвал бы функцию OpenFileMapping таким образом:
HANDLE hFileMapping = OpenFileMapping(FILE_MAP_READ, FALSE,
Передавая FILE_MAP_READ первым параметром в функцию OpenFileMapping , я сообщаю, что, как только мне предоставят доступ к проекции файла, я буду считывать из нее данные. Функция OpenFileMapping , прежде чем вернуть действительный описатель, проверяем тип защиты объекта: Если меня, как зарегистрировавшегося пользователя, допускают к существую-
Глава 3. Объекты ядра .docx
щему объекту ядра «проекция файла», OpenFileMapping возвращает действительный описатель. Но если мне отказывают в доступе, OpenFileMapping возвращает
NULL, а вызов GetLastError дает код ошибки 5 (или ERROR_ ACCESS_DENIED).
Но опять же, в основной массе приложений защиту не используют, и поэтому я больше не буду задерживаться на этой теме.
Хотя в большинстве приложений нет нужды беспокоиться о защите, многие функции Windows требуют, чтобы вы передавали им информацию о нужном уровне защиты. Некоторые приложения, написанные для прежних версий Windows, в Windows Vista толком не работают из-за того, что при их реализации не было уделено должного внимания защите.
Представьте, что при запуске приложение считывает данные из какого-то раздела реестра. Чтобы делать это корректно, оно должно вызывать функцию RegOpenKeyEx , передавая значение KEY_QUERY_VALUE, которое разрешает операцию чтения в указанном разделе.
Однако многие приложения для версий Windows, предшествующих Windows 2000, создавались без учета вопросов, связанных с защитой. Поскольку эти версии Windows не защищают свой реестр, разработчики часто вызывали RegOpenKeyEx со значением KEY_ALL__ACCESS. Так проще и не надо ломать голову над тем, какой уровень доступа требуется па самом деле. Но проблема в том, что раздел реестра может быть доступен для чтения, и блокирован для записи. В Windows Vista вызов RegOpenKeyEx со значением KEY_ALL_ACCESS заканчивается неудачно, и без соответствующего контроля ошибок приложение может повести себя совершенно непредсказуемо.
Если бы разработчик хоть немного подумал о защите и поменял значение
KEY_ALL_ACCESS на KEY_QUERY_VALUE (только-то и всего!), его продукт мог бы работать в обеих операционных системах.
Пренебрежение флагами, определяющими уровень доступа, — одна из самых крупных ошибок, совершаемых разработчиками. Правильное их использование позволило бы легко переносить многие приложения в новые версии Windows. Необходимо также учитывать, что в каждой новой версии Windows появляются ограничения, отсутствовавшие в прежней версии. Так, в Windows Vista добавлена функция контроля пользовательских учетных записей (User Account Control, UAC). По соображениям безопасности UAC заставляет систему исполнять приложения в ограниченном контексте защиты, даже если текущий пользователь обладает администраторскими правами. Подробнее о UAC — в главе 4.
Кроме объектов ядра ваша программа может использовать объекты других типов — меню, окна, указатели мыши, кисти и шрифты. Они относятся к объектам User или GDI. Новичок в программировании для Windows может запутаться, пытаясь отличить объекты User или GDI от объектов ядра. Как узнать, например, чьим объектом — User или ядра — является данный значок? Выяснить, не принадлежит ли объект ядру, проще всего так: проанализировать функцию, создающую объект. Практически у всех функций, создающих
16 Часть I Материалы для обязательного чтения
объекты ядра, есть параметр, позволяющий указать атрибуты защиты, — как у
В то же время у функций, создающих объекты User или GDI, нет параметра типа PSECURITY_ATTRIBUTES, и пример тому — функция CreateIcon :
HICON CreateIcon( HINSTANCE hinst, int nWidth,
int nHeight, BYTE cPlanes, BYTE cBitsPixel,
CONST BYTE *pbANDbits, CONST BYTE *pbXORbits);
Подробнее об объектах GDI и User, а также об их мониторинге см. в статье
MSDN, доступной по ссылке http://msdn.microsoft.com/msdnmag/issues/03/01/ GDILeaks .
Таблица описателей объектов ядра
При инициализации процесса система создает в нем таблицу описателей, используемую только для объектов ядра. Сведения о структуре этой таблицы и управлении ею незадокументированы. Вообще-то я воздерживаюсь от рассмотрения недокументированных частей операционных систем. Но в данном случае стоит сделать исключение — квалифицированный Windows-программист, на мой взгляд, должен понимать, как устроена таблица описателей в процессе. Поскольку информация о таблице описателей незадокументирована, я не ручаюсь за ее стопроцентную достоверность, к тому же эта таблица по-разному реализуется в разных версиях Windows. Таким образом, следующие разделы помогут понять, что представляет собой таблица описателей, но вот что система действительно делает с ней — этот вопрос я оставляю открытым.
В таблице 3-1 показано, как выглядит таблица описателей, принадлежащая процессу. Как видите, это просто массив структур данных. Каждая структура содержит указатель на какой-нибудь объект ядра, маску доступа и некоторые флаги.
Табл. 3-1. Структура таблицы описателей, принадлежащей процессу



