- RMS для macOS и Linux
- Что реализовано:
- Что будет добавлено к релизу:
- Символы Unicode: о чём должен знать каждый разработчик
- Введение в кодировку
- Краткая история кодировки
- Проблемы с ASCII
- Что такое кодовые страницы ASCII?
- Безумие какое-то.
- Так появился Unicode
- Unicode Transform Protocol (UTF)
- Что такое UTF-8 и как она работает?
- Напоследок про UTF
- Это всё?
- Заключение
- POER Smart и MQTT
RMS для macOS и Linux
Мы выпустили RMS-Клиент для macOS и Linux. Приглашаем принять участие в бета-тестировании первой версии долгожданного кроссплатформенного продукта.
Это абсолютно новое приложение, написанное полностью с нуля. На начальном этапе было принято непростое стратегическое решение — перейти на новую, более совершенную, платформу — Qt (C++). Это негативно сказалось на времени разработки, т.к. не позволило использовать накопленную, более чем за десять лет, кодовую базу, однако, сделало продукт надежнее и намного перспективнее в плане использования новых технологий, а также UI.
Финальный релиз запланирован к весне 2020 года. Также на 2020 год запланирован выпуск Хоста.
Что реализовано:
- Нативное приложение для macOS и Linux, написанное полностью с нуля на новой платформе.
- Соединение в режиме управления удаленным рабочим столом.
- Адресная книга в формате, совместимом с Windows-версией.
- Возможность подключать несколько адресных книг.
- Соединение через Internet-ID.
Что будет добавлено к релизу:
- Файловый менеджер.
- Поддержка синхронизации адресных книг и авторизации через Сервер.
- Модуль управления питанием удаленных машин.
- Режим просмотра списка соединений в виде эскизов удаленных рабочих столов.
- Перетаскивание и копирование соединений, в том числе, через буфер обмена.
- Отображение формы указателя мыши удаленного компьютера.
- Полноэкранный просмотр в режиме управления удаленным рабочим столом.
- Соединение через прокси-сервер.
- Журнал соединений и ошибок.
Ссылки на загрузку и обсуждение продукта на нашем корпоративном форуме.
Источник
Символы Unicode: о чём должен знать каждый разработчик

Если вы пишете международное приложение, использующее несколько языков, то вам нужно кое-что знать о кодировке. Она отвечает за то, как текст отображается на экране. Я вкратце расскажу об истории кодировки и о её стандартизации, а затем мы поговорим о её использовании. Затронем немного и теорию информатики.
Введение в кодировку
Компьютеры понимают лишь двоичные числа — нули и единицы, это их язык. Больше ничего. Одно число называется байтом, каждый байт состоит из восьми битов. То есть восемь нулей и единиц составляют один байт. Внутри компьютеров всё сводится к двоичности — языки программирования, движений мыши, нажатия клавиш и все слова на экране. Но если статья, которую вы читаете, раньше была набором нулей и единиц, то как двоичные числа превратились в текст? Давайте разберёмся.
Краткая история кодировки
На заре своего развития интернет был исключительно англоязычным. Его авторам и пользователям не нужно было заботиться о символах других языков, и все нужды полностью покрывала кодировка American Standard Code for Information Interchange (ASCII).
ASCII — это таблица сопоставления бинарных обозначений знакам алфавита. Когда компьютер получает такую запись:
то с помощью ASCII он преобразует её во фразу «Hello world».
Один байт (восемь бит) был достаточно велик, чтобы вместить в себя любую англоязычную букву, как и управляющие символы, часть из которых использовалась телепринтерами, так что в те годы они были полезны (сегодня уже не особо). К управляющим символам относился, например 7 (0111 в двоичном представлении), который заставлял компьютер издавать сигнал; 8 (1000 в двоичном представлении) — выводил последний напечатанный символ; или 12 (1100 в двоичном представлении) — стирал весь написанный на видеотерминале текст.
В те времена компьютеры считали 8 бит за один байт (так было не всегда), так что проблем не возникало. Мы могли хранить все управляющие символы, все числа и англоязычные буквы, и даже ещё оставалось место, поскольку один байт может кодировать 255 символов, а для ASCII нужно только 127. То есть неиспользованными оставалось ещё 128 позиций в кодировке.
Вот как выглядит таблица ASCII. Двоичными числами кодируются все строчные и прописные буквы от A до Z и числа от 0 до 9. Первые 32 позиции отведены для непечатаемых управляющих символов.

Проблемы с ASCII
Позиции со 128 по 255 были пустыми. Общественность задумалась, чем их заполнить. Но у всех были разные идеи. Американский национальный институт стандартов (American National Standards Institute, ANSI) формулирует стандарты для разных отраслей. Там утвердили позиции ASCII с 0 по 127. Их никто не оспаривал. Проблема была с остальными позициями.
Вот чем были заполнены позиции 128-255 в первых компьютерах IBM:
Какие-то загогулины, фоновые иконки, математические операторы и символы с диакретическим знаком вроде é. Но разработчики других компьютерных архитектур не поддержали инициативу. Всем хотелось внедрить свою собственную кодировку во второй половине ASCII.
Все эти различные концовки назвали кодовыми страницами.
Что такое кодовые страницы ASCII?
Здесь собрана коллекция из более чем 465 разных кодовых страниц! Существовали разные страницы даже в рамках какого-то одного языка, например, для греческого и китайского. Как можно было стандартизировать этот бардак? Или хотя бы заставить его работать между разными языками? Или между разными кодовыми страницами для одного языка? В языках, отличающихся от английского? У китайцев больше 100 000 иероглифов. ASCII даже не может всех их вместить, даже если бы решили отдать все пустые позиции под китайские символы.
Эта проблема даже получила название Mojibake (бнопня, кракозябры). Так говорят про искажённый текст, который получается при использовании некорректной кодировки. В переводе с японского mojibake означает «преобразование символов».
Пример бнопни (кракозябров).
Безумие какое-то.
Именно! Не было ни единого шанса надёжно преобразовывать данные. Интернет — это лишь монструозное соединение компьютеров по всему миру. Представьте, что все страны решили использовать собственные стандарты. Например, греческие компьютеры принимают только греческий язык, а английские отправляют только английский. Это как кричать в пустой пещере, тебя никто не услышит.
ASCII уже не удовлетворял жизненным требованиям. Для всемирного интернета нужно было создать что-то другое, либо пришлось бы иметь дело с сотнями кодовых страниц.
��� Если только ������ вы не хотели ��� бы ��� читать подобные параграфы. �֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
Так появился Unicode
Unicode расшифровывают как Universal Coded Character Set (UCS), и у него есть официальное обозначение ISO/IEC 10646. Но обычно все используют название Unicode.
Этот стандарт помог решить проблемы, возникавшие из-за кодировки и кодовых страниц. Он содержит множество кодовых пунктов (кодовых точек), присвоенных символам из языков и культур со всего мира. То есть Unicode — это набор символов. С его помощью можно сопоставить некую абстракцию с буквой, на которую мы хотим ссылаться. И так сделано для каждого символа, даже египетских иероглифов.
Кто-то проделал огромную работу, сопоставляя каждый символ во всех языках с уникальными кодами. Вот как это выглядит:
Префикс U+ говорит о том, что это стандарт Unicode, а число — это результат преобразования двоичных чисел. Стандарт использует шестнадцатеричную нотацию, которая является упрощённым представлением двоичных чисел. Здесь вы можете ввести в поле что угодно и посмотреть, как это будет преобразовано в Unicode. А здесь можно полюбоваться на все 143 859 кодовых пунктов.
Уточню на всякий случай: речь идёт о большом словаре кодовых пунктов, присвоенных всевозможным символам. Это очень большой набор символов, не более того.
Осталось добавить последний ингредиент.
Unicode Transform Protocol (UTF)
UTF — протокол кодирования кодовых пунктов в Unicode. Он прописан в стандарте и позволяет кодировать любой кодовый пункт. Однако существуют разные типы UTF. Они различаются количеством байтов, используемых для кодировки одного пункта. В UTF-8 используется один байт на пункт, в UTF-16 — два байта, в UTF-32 — четыре байта.
Но если у нас есть три разные кодировки, то как узнать, какая из них применяется в конкретном файле? Для этого используют маркер последовательности байтов (Byte Order Mark, BOM), который ещё называют сигнатурой кодировки (Encoding Signature). BOM — это двухбайтный маркер в начале файл, который говорит о том, какая именно кодировка тут применена.
В интернете чаще всего используют UTF-8, она также прописана как предпочтительная в стандарте HTML5, так что уделю ей больше всего внимания.
Этот график построен в 2012-м, UTF-8 становилась доминирующей кодировкой. И всё ещё ею является.
Что такое UTF-8 и как она работает?
UTF-8 кодирует с помощью одного байта каждый кодовый пункт Unicode с 0 по 127 (как в ASCII). То есть если вы писали программу с использованием ASCII, а ваши пользователи применяют UTF-8, они не заметят ничего необычного. Всё будет работать как задумано. Обратите внимание, как это важно. Нам нужно было сохранить обратную совместимость с ASCII в ходе массового внедрения UTF-8. И эта кодировка ничего не ломает.
Как следует из названия, кодовый пункт состоит из 8 битов (один байт). В Unicode есть символы, которые занимают несколько байтов (вплоть до 6). Это называют переменной длиной. В разных языках удельное количество байтов разное. В английском — 1, европейские языки (с латинским алфавитом), иврит и арабский представлены с помощью двух байтов на кодовый пункт. Для китайского, японского, корейского и других азиатских языков используют по три байта.
Если нужно, чтобы символ занимал больше одного байта, то применяется битовая комбинация, обозначающая переход — он говорит о том, что символ продолжается в нескольких следующих байтах.
И теперь мы, как по волшебству, пришли к соглашению, как закодировать шумерскую клинопись (Хабр её не отображает), а также значки emoji!
Подытожив сказанное: сначала читаем BOM, чтобы определить версию кодировки, затем преобразуем файл в кодовые пункты Unicode, а потом выводим на экран символы из набора Unicode.
Напоследок про UTF
Коды являются ключами. Если я отправлю ошибочную кодировку, вы не сможете ничего прочесть. Не забывайте об этом при отправке и получении данных. В наших повседневных инструментах это часто абстрагировано, но нам, программистам, важно понимать, что происходит под капотом.
Как нам задавать кодировку? Поскольку HTML пишется на английском, и почти все кодировки прекрасно работают с английским, мы можем указать кодировку в начале раздела .
Важно сделать это в самом начале , поскольку парсинг HTML может начаться заново, если в данный момент используется неправильная кодировка. Также узнать версию кодировки можно из заголовка Content-Type HTTP-запроса/ответа.
Если HTML-документ не содержит упоминания кодировки, спецификация HTML5 предлагает такое интересное решение, как BOM-сниффинг. С его помощью мы по маркеру порядка байтов (BOM) можем определить используемую кодировку.
Это всё?
Unicode ещё не завершён. Как и в случае с любым стандартом, мы что-то добавляем, убираем, предлагаем новое. Никакие спецификации нельзя назвать «завершёнными». Обычно в год бывает 1-2 релиза, найти их описание можно здесь.
Если вы дочитали до конца, то вы молодцы. Предлагаю сделать домашнюю работу. Посмотрите, как могут ломаться сайты при использовании неправильной кодировки. Я воспользовался этим расширением для Google Chrome, поменял кодировку и попытался открывать разные страницы. Информация была совершенно нечитаемой. Попробуйте сами, как выглядит бнопня. Это поможет понять, насколько важна кодировка.
Заключение
При написании этой статьи я узнал о Майкле Эверсоне. С 1993 года он предложил больше 200 изменений в Unicode, добавил в стандарт тысячи символов. По состоянию на 2003 год он считался самым продуктивным участником. Он один очень сильно повлиял на облик Unicode. Майкл — один из тех, кто сделал интернет таким, каким мы его сегодня знаем. Очень впечатляет.
Надеюсь, мне удалось показать вам, для чего нужны кодировки, какие проблемы они решают, и что происходит при их сбоях.
Источник
POER Smart и MQTT



Сразу предупреждаю: готовых решений здесь не ждите (хотя, кто знает, — может, они тут когда-то появятся).
Итак, имеется некое подобие экосистемы от широко известного в узких кругах производителя POER. «Подобие» — потому что эта экосистема довольно ограничена по списку поддерживаемых устройств (и как все понимают, все представители этого списка являются устройствами производства самой компании POER).
Общий принцип работы этой экосистемы таков: все устройства (термостаты, блоки управления) общаются между собой на радиочастоте 433 или 868 МГц (например, термостат посылает блоку управления команду замкнуть реле (чтобы, например, включить котел отопления) и получает в ответ информацию о состоянии реле). Плюс к этому все устройства общаются на той же радиочастоте со шлюзом (единственная на сегодня модель шлюза называется PTG10), а шлюз, в свою очередь, по WiFi через вашу точку доступа имеет выход в ИНтернет и общается со своей «фирменной» облачной службой. Приложение на вашем смартфоне тоже общается с этим облаком — поэтому у вас есть возможность настройки и мониторинга термостатов для управления вашей системой отопления. Более подробно об этом можно почитать здесь.
В принципе, сама по себе эта экосистема POER довольно-таки неплохая — начиная от дизайна устройств и заканчивая удобством управления через родное приложение. Но самый существенный недостаток — это замкнутость экосистемы на саму себя. Другими словами, управлять и контролировать устройства POER можно только через родное фирменное приложение. Сведений об удачном включении устройств POER в какие-либо системы «умного дома» обнаружить не удалось. Единственное небольшое исключение из этого правила — это крайне примитивная интеграция с Google Home, которая позволяет всего лишь переключить режим термостата в один из трех вариантов, заранее настроенных в «родном» приложении или на самом термостате.
Автор упомянутой статьи тоже задавался вопросом интеграции POER в умный дом. При этом он в качестве «печки» (той, от которой пляшут) выбрал приложение для смартфона — пытался выяснить, по каким сетевым адресам уходит из приложения информация, что приходит в ответ, и какие именно данные передаются. Процесс, судя по всему, так и не был доведен до конца.
Ну а я решил пойти другим путем — начал «плясать» от WiFi-шлюза PTG10. Для начала просто открыл «админку» своего роутера, чтобы посмотреть, с кем общается шлюз. И вот, что выдал мне роутер:
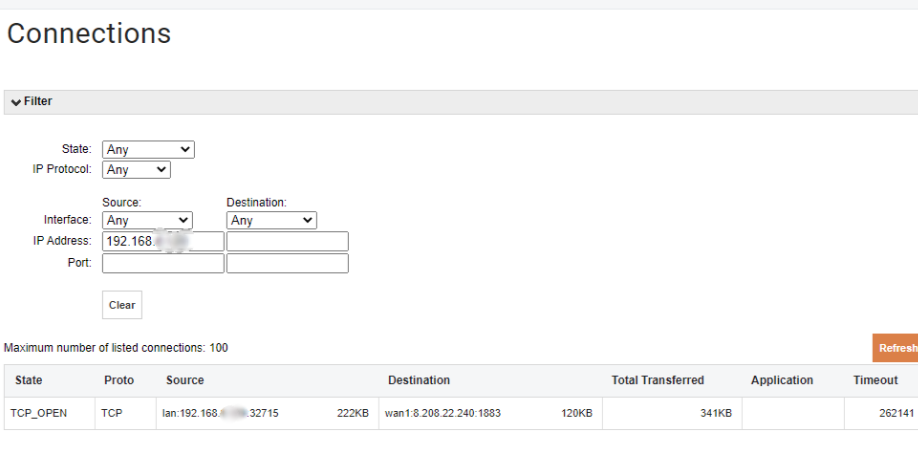
Ха! (сказал я себе). А ведь 1883-й порт — это же стандартный порт MQTT-брокера. Надо бы проверить. Запустил на компе MQTT-клиента, вбил адрес и. совершенно без проблем подключился — не было запрошено ни логина, ни пароля.
Этот самый брокер (судя по адресу, он находится в Сингапуре) выдал мне вот такую картинку:
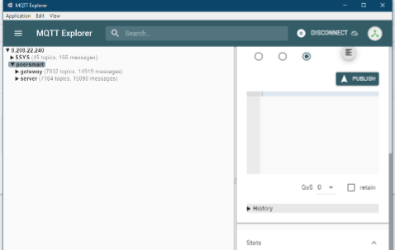
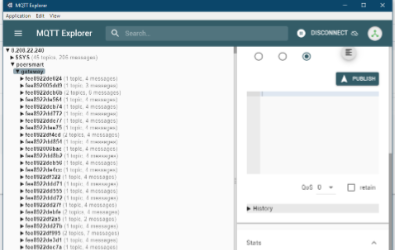
Разумно предположить, что топики (на правой картинке) названы по MAC-адресам шлюзов. Так и оказалось, но за одним нюансом — первый сегмент MAC-адреса шлюза — FC. А в имени топика первые два символа — FE. То есть, узнаете MAC-адрес шлюза, меняете первый сегмент с FC на FE, и. получаете доступ к данным, которые ваш шлюз отсылает брокеру.
Казалось бы, дело осталось за малым — читаем пэйлоуды и получаем данные. Но нет — оказывается там не текст, а набор двоичных данных.
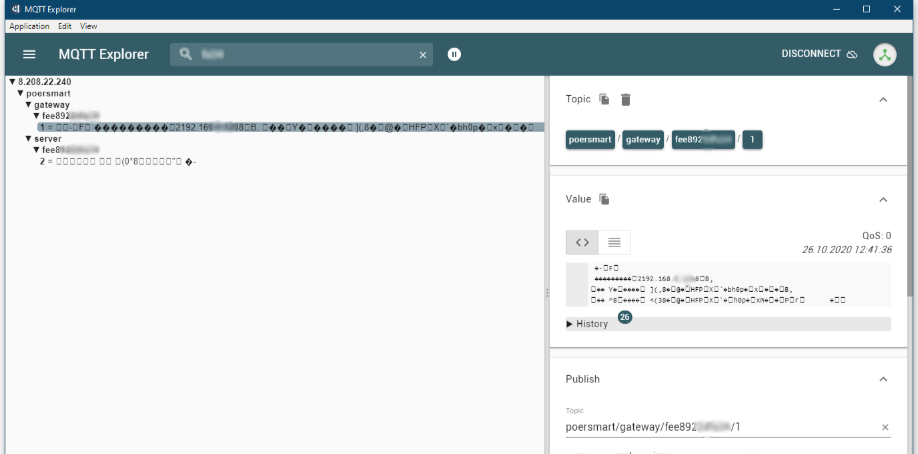
Как видим, данные совершенно нечитабельные, их даже нельзя куда-нибудь скопипастить, поскольку при копировании у части символов обрезаются биты и т.д., и т.п.
Но есть выход. Под Линуксом запускаем.
mosquitto_sub -h 8.208.22.240 -p 1883 -t poersmart/gateway/fee892 � � � � ��/# (замените на MAC-адрес своего шлюза)
. и получаем что-то вроде этого:
Источник



