- 8 облачных анализаторов логов для оценки рабочей среды
- Список анализаторов логов:
- Loggly
- SumoLogic
- Splunk
- Papertrail
- Logz.io
- Timber
- Logentries
- Logsene
- Централизованный сбор Windows Event Logs с помощью ELK (Elasticsearch — Logstash — Kibana)
- Что такое ELK?
- Установка Ubuntu 14.04
- Установка JAVA 7
- Установка Elasticsearch
- Установка Kibana
- Установка Logstash
- Установка nxlog
- Использование
8 облачных анализаторов логов для оценки рабочей среды
Увеличение количества устройств, повышение квалификационных требований, оптимизация процесса сбора данных необходимы для любого вида бизнеса. Анализ логов может дать вам реальное представление о том, что происходит в вашей информационной среде. Вот некоторые примеры, функционирующие в реальном времени:
- планирование производительности
- раннее обнаружение проблемы
- актуальная отчетность
- управление доступностью
Если у вас несколько мегабайт лог-файлов, тогда их можно просмотреть вручную, но когда вы работаете в среднем и корпоративном бизнесе, где объем логов исчисляется гигабайтами, тогда ручной анализ превращается в кошмар.

Если вы ищете решение для мониторинга и анализа логов ваших веб-приложений, включая инфраструктуру, вы можете рассмотреть следующие средства для работы с логами. Большинство из них имеют слегка урезанную бесплатную версию, в которой вы можете попробовать поработать.
Список анализаторов логов:
Loggly
Loggly одно из самых популярных решений для управления логами, подходит для анализа данных практически из любого источника, включая следующие:
- веб-приложения — Apache, Nginx, PHP, Node.js, .NET, Java, JavaScript
- операционные системы – Linux, Windows
С помощью Loggly вы можете собирать данные (логи) для анализа и создавать содержательные информационные панели для мониторинга необходимых показателей. Разумеется, вы можете осуществлять поиск в логах из интерфейса Loggly.
Loggly обладает мощной поисковой системой, в которой вы можете настраивать и устанавливать фильтры для всего текста, одного поля и булевских значений. Вы можете также привязать электронную почту, PageDuty, Slack, HipChat и т.д., чтобы получать оповещения.
SumoLogic
Получите информационную аналитику в режиме реального времени с помощью SumoLogic для мониторинга, анализа, устранения проблем и защиты бизнес приложений и инфраструктуры.
У SumoLogic есть агент-сборщик/облачный сборщик, который необходимо установить на ваш сервер для передачи логов в SumoLogic. Вы можете преобразовывать любые типы логов составляя наглядную картину происходящего, обновляющуюся в реальном времени, для мониторинга и оповещения о достижении заданных границ.

SumoLogic имеет несколько заранее настроенных приложений, основанных на наиболее распространенных способах применения для ускорения работающих задач и изучения проблем.
Примеры приложений для:
- mongoDB – отслеживание общего состояния, оптимизация запросов, мониторинг безопасности;
- AWS Lambda – проактивный мониторинг, обзор затрат, углубленное изучение;
- AWS – определение проблем производительности, активный контроль безопасности, расширенная аналитика;
- Salesforce – улучшение адаптации для пользователей, аудиторские проверки, сравнение данных;
- Trend Micro – анализ уязвимости, история событий, улучшение визуализации атак;
- Github – визуализация командной производительности, создание базовых показателей использования;
- Docker — расширенная аналитика, устранение проблем;
- Linux — устранение неполадок и оптимизация ОС, оповещения о доступе/проверке и событиях безопасности, отслеживание показателей производительности;
- Nginx — обзор, локация посетителей, время отклика, выявление узких мест в производительности;
- Apache – взаимодействие с посетителями, оптимизация производительности, визуализация посетителей;
- IIS — комплексная информация, статистика трафика, поиск медленных страниц;
- MySQL — общее состояние, ключевые ошибки, мониторинг производительности запросов.
В бесплатной версии вы получите 500 мегабайт в день с 7-дневным хранением данных с любым исходным типом собираемых данных.
Splunk
Splunk Cloud доступен в 10 регионах AWS по всему миру для сбора и индексирования любого типа информации. Splunk — это быстрый и простой способ анализа и визуализации данных, создаваемых на физических, облачных или виртуальных устройствах.
С помощью Splunk вы можете отслеживать и визуализировать данные и настраивать пороговые показатели для оповещений. Я не видел бесплатной версии, но у них есть пробная версия, позволяющая анализировать и визуализировать данные объемом 5 ГБ в течение 15 дней.
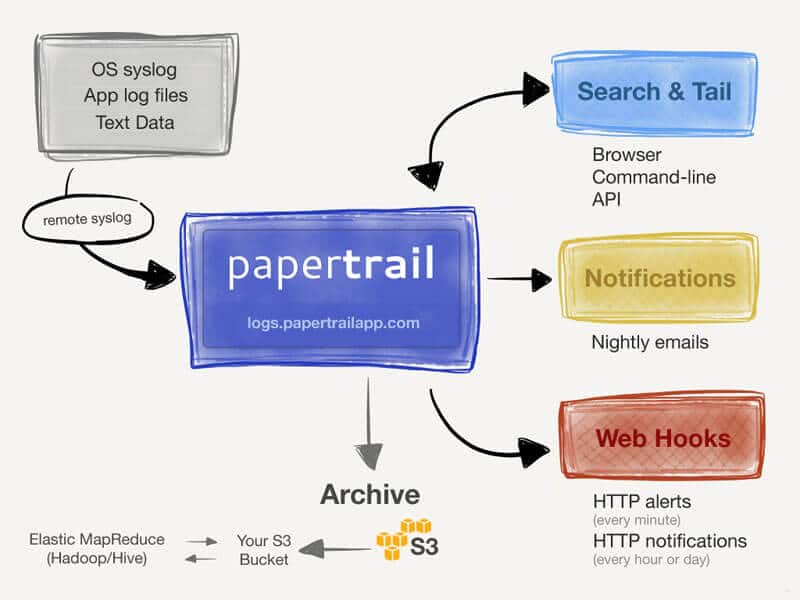
Papertrail
Papertrail может собирать данные из syslog, text, Apache, MySQL, приложений Heroku, журнала событий Windows, маршрутизаторов, брандмауэров, RubyOnRails и многого другого.
Вы можете выполнять поиск в режиме реального времени с помощью браузера, командной строки или API и получать оповещения по электронной почте или Slack.
Logz.io
Logz.io предоставляет размещение ELK как услугу. ELK (Elastic Search, Logstash, Kibana) — одна из самых популярных платформ для анализа с открытым исходным кодом. Если вы ищете гибкую платформу для обработки логов, то Logz.io будет вам полезен.
Logz.io может индексировать данные почти всех современных технологий и предоставлять вам подробный анализ с визуализацией данных и оповещениями.

Некоторые поддерживаемые технологии:
- Apache HTTP/Tomcat
- Nginx
- Hadoop
- Heroku
- Node.js
- mongoDB
- postgreSQL
- Windows
- Linux
- AWS
Бесплатная версия предлагает три дня хранения с 3 ГБ данных в день.
Timber
Отслеживание в режиме реального времени, современная система фильтрации, быстрый поиск, а также возможность интеграции Timber с вашим приложением или платформой.

Библиотеки доступны для Node, Ruby и Elixir и поддерживают многие платформы, включая следующие:
- Logstash
- Zeit (Now)
- AWS Lambda
- Docker
- Linux
- Heroku
- Kubernetes
Вы можете начать с бесплатной версии и опробовать эту платформу.
Logentries
Отправьте любые данные в Logentries для немедленного поиска и визуализации данных. Вы можете следить за логами в пользовательском интерфейсе Logentries и немедленно получать оповещения о необходимых значениях.
Оповещения могут быть переданы в Slack, Hipchat, Pagerduty или при помощи вебхуков. Logentries предоставляет REST API для запроса ваших логов для визуализации.

В бесплатной версии вы можете отправить данные объемом до 5 ГБ, а срок хранения составляет семь дней.
Logsene
Logsene от Sematext — это ваш облачный управляемый ELK Stack для управления и анализа логов. Вы можете отправлять логи через зашифрованные каналы из любого источника, включая Syslog.
Он работает на AWS и поддерживает SOC, SSAE, FISMA, DIACAP, HIPPA и др.

Попробуйте демо-версию, чтобы понять принцип работы.
Я надеюсь, что эти облачные анализаторы журналов помогут вам искать, анализировать и визуализировать свои данные и облегчат ИТ-аналитику.
Централизованный сбор Windows Event Logs с помощью ELK (Elasticsearch — Logstash — Kibana)
 Передо мной встала задача организовать сбор Windows Event Logs в некое единое хранилище с удобным поиском/фильтрацией/возможно даже визуализацией. После некоторого поиска в интернете я натолкнулся на чудесный стек технологий от Elasticsearch.org — связка ELK (Elasticsearch — Logstash — Kibana). Все продукты являются freeware и распространяются как в виде архива с программой, так и в виде пакетов deb и rpm.
Передо мной встала задача организовать сбор Windows Event Logs в некое единое хранилище с удобным поиском/фильтрацией/возможно даже визуализацией. После некоторого поиска в интернете я натолкнулся на чудесный стек технологий от Elasticsearch.org — связка ELK (Elasticsearch — Logstash — Kibana). Все продукты являются freeware и распространяются как в виде архива с программой, так и в виде пакетов deb и rpm.
Что такое ELK?
Elasticsearch
Elasticsearch — это поисковый сервер и хранилище документов основанное на Lucene, использующее RESTful интерфейс и JSON-схему для документов.
Logstash
Logstash – это утилита для управления событиями и логами. Имеет богатый функционал для их получения, парсинга и перенаправления\хранения.
Kibana
Kibana – это веб-приложение для визуализации и поиска логов и прочих данных имеющих отметку времени.
В данной статье я постараюсь описать некий HOW TO для установки одного сервера на базе Ubuntu Server 14.04, настройки на нем стека ELK, а так же настройки клиента nxlog для трансляции логов на сервер. Хочу однако отметить что данный стек технологий можно использовать гораздо шире. Какие логи вы будете пересылать, парсить, хранить и в последствии пользоваться поиском\визуализацией по ним зависит только от вашей фантазии. По использованию данных технологий есть множество вебинаров на сайте http://www.elasticsearch.org/videos/ .
Установка Ubuntu 14.04
Дабы не повторяться с установкой дистрибутива Ubuntu 14.04 приведу ссылку на статью моего коллеги по блогу, Алексея Максимова — Настройка прокси сервера Squid 3.3 на Ubuntu Server 14.04 LTS. Часть 1. Установка ОС на ВМ Hyper-V Gen2 . Все действия по настройке можно проделать аналогичные, за исключением установки минимального UI и настройки второго сетевого интерфейса – его можно исключить на стадии создания виртуальной машины, ведь сервер будет находиться внутри периметра вашей сети.
Установка JAVA 7
Так как два из трех используемых продуктов написаны на JAVA нам придется его установить. Устанавливать будем Oracle Java 7, так как Elasticsearch рекомендует устанавливать именно его.
Добавляем Oracle Java PPA в apt:
И устанавливаем последнюю стабильную версию Oracle Java 7:
Проверить версию Java можно набрав команду
Установка Elasticsearch
Хотя документация по Logstash рекомендует использовать Elasticsearch версии 1.1.1, он прекрасно работает и с последней стабильной версией 1.3.1. Именно ее мы и установим.
Добавляем публичный GPG ключ в apt:
Создаем source list apt:
И устанавливаем Elasticsearch 1.3.1:
Базовая конфигурация Elasticsearch очень простая, нам нужно указать в файле конфигурации всего два параметра – имя кластера и имя ноды.
Открываем elasticsearch.yml:
И раcкомментируем строки “cluster.name: elasticsearch” и “node.name: «Franz Kafka»”. Вместо значений по умолчанию можно указать свои.
Создаем скрипты автозапуска elasticsearch:
Перед стартом сервера я рекомендую установить еще два плагина к elasticsearch – head и paramedic. Первый позволяет управлять сервером поиска и индексами документов, второй следит за “здоровьем” пациента, выводя графики с различной полезной информацией.
Плагины к elasticsearch устанавливаются с помощью команды plugin прямо из github:
Доступ к результатам работы плагинов можно получить через url вида http://elasticsearch.server.name:9200/_plugin/head/ или http://elasticsearch.server.name:9200/_plugin/paramedic/
После чего можно запускать сам сервер:
Установка Kibana
Так как Kibana это веб-приложение, перед его установкой нужно установить веб-сервер. Я воспользовался простейшим nginx.
Создаем папку www для будущего приложения:
Даем nginx права на папку:
Скачиваем последний архив с файлами Kibana (на настоящий момент это kibana-3.1.0.tar.gz):
И копируем его содержимое в папку /var/www:
Скачиваем файл конфигурации для работы Kibana под nginx:
Открываем его в редакторе nano и указываем в какой папке лежат файлы Kibana:
Заменяем строку
root /usr/share/kibana3;
на строку
root /var/www;
Копируем данный файл как файл по умолчанию для nginx:
И перезапускаем nginx:
Теперь если перейти по адресу http://elasticsearch.server.name/ мы увидим стартовый дашборд Kibana. Если вы не планируете создавать других дашбордов, то можно сразу поставить по умолчанию дашборд Logstash.
Для этого нужно заменить файл дашборда по умолчанию на файл дашборда Logstash:
Основные настройки Kibana находятся в файле config.js по адресу /var/www/config.js, однако “из коробки” все работает замечательно.
Установка Logstash
Добавляем source list Logstash в apt:
И устанавливаем Logstash:
Logstash установлен, однако конфигурации у него нет. Конфигурационный файл Logstash состоит из 3х частей – input, filter и output. В первой определяется источник событий или логов, во второй с ними производятся необходимые манипуляции, и в третей части описывается куда обработанные данные нужно подавать. Подробно все части описаны в документации http://logstash.net/docs/1.4.2/ и есть некоторые примеры.
Для текущей задачи, мною была написана следующая простая конфигурация:
Создадим файл в папке конфигураций Logstash
И поместим туда следующую конфигурацию
Разберем по порядку:
В разделе input
tcp <> — открывает tcp порт и слушает его
type => “eventlog” говорит Logstash что на входе будут данные типа eventlog (известный формат полей для Logstash)
port => 3515 – номер потра
format => ‘json’ – говорит Logstash о том, что данные придут “обернутые” в JSON
Никаких манипуляций с логами я не совершаю, потому раздел filter у меня пустой. Хотя если Вам будет необходимо, к примеру, привести дату к нужному формату, или убрать из лога одно или несколько полей, то в данном разделе можно эти манипуляции описать.
В разделе output
elasticsearch <> – оправляет данные в elasticsearch
cluster => “elasticsearch” – указывает на имя кластера, что мы указывали при конфигурировании Elasticsearch
node_name => “Franz Kafka” – указывает на имя ноды.
Сохраняем файл и запускаем Logstash
Можно проверить что порт tcp 3515 слушается командой:
Установка nxlog
Идем на сайт nxlog ( http://nxlog.org/download) и скачиваем саму свежую версию для Windows.
Устанавливаем на нужной Windows машине данный клиент. Настройки он хранит в файле nxlog.conf по адресу по умолчанию “c:\Program Files (x86)\nxlog\conf\” (для 32-битной версии “c:\Program Files\nxlog\conf\”).
Для решения данной задачи я написал конфигурационный файл следующего содержания:
У nxlog конфигурационный файл так же состоит из нескольких частей – это Extension, Input, Output и Route. Об устройстве конфигурационного файла nxlog можно почитать в документации к nxlog ( http://nxlog.org/nxlog-docs/en/nxlog-reference-manual.html) .
Могу отметить следующие детали – в разделе Input используется модуль im_msvistalog (для операционных систем Vista/2008 +) для более старых ОС нужно раскомментировать строку с указанием на модуль im_mseventlog. Модуль im_msvistalog позволяет фильтровать логи через XPath запрос (подробнее тут — http://msdn.microsoft.com/en-us/library/aa385231.aspx) . В приведенном конфигурационном файле выбираются логи из трех источников – это журналы Application, Security и System, причем из Application и System выбираются только Critical, Error и Warning логи, для Security выбираются все логи, так как они там другого типа – Info. Команда Exec to_json; “оборачивает” данные в JSON формат.
В разделе Output указывается модуль om_tcp для отправки данных по протоколу tcp, указывается хост и порт подключения.
Раздел Route служит для указания порядка выполнения действий, так как клиент nxlog умеет читать из множества источников и отсылать во множество приемников. Все это можно подчерпнуть из документации к продукту.
Настроив конфигурационный файл не забудьте его сохранить и можно запускать клиент через оснастку Службы (Services) или через командную строку:
Использование
Открыв в браузере Kibana (и перейдя на дашборд Logstash, если он у Вас не по умолчанию) мы увидим после всего проделанного следующую картину.
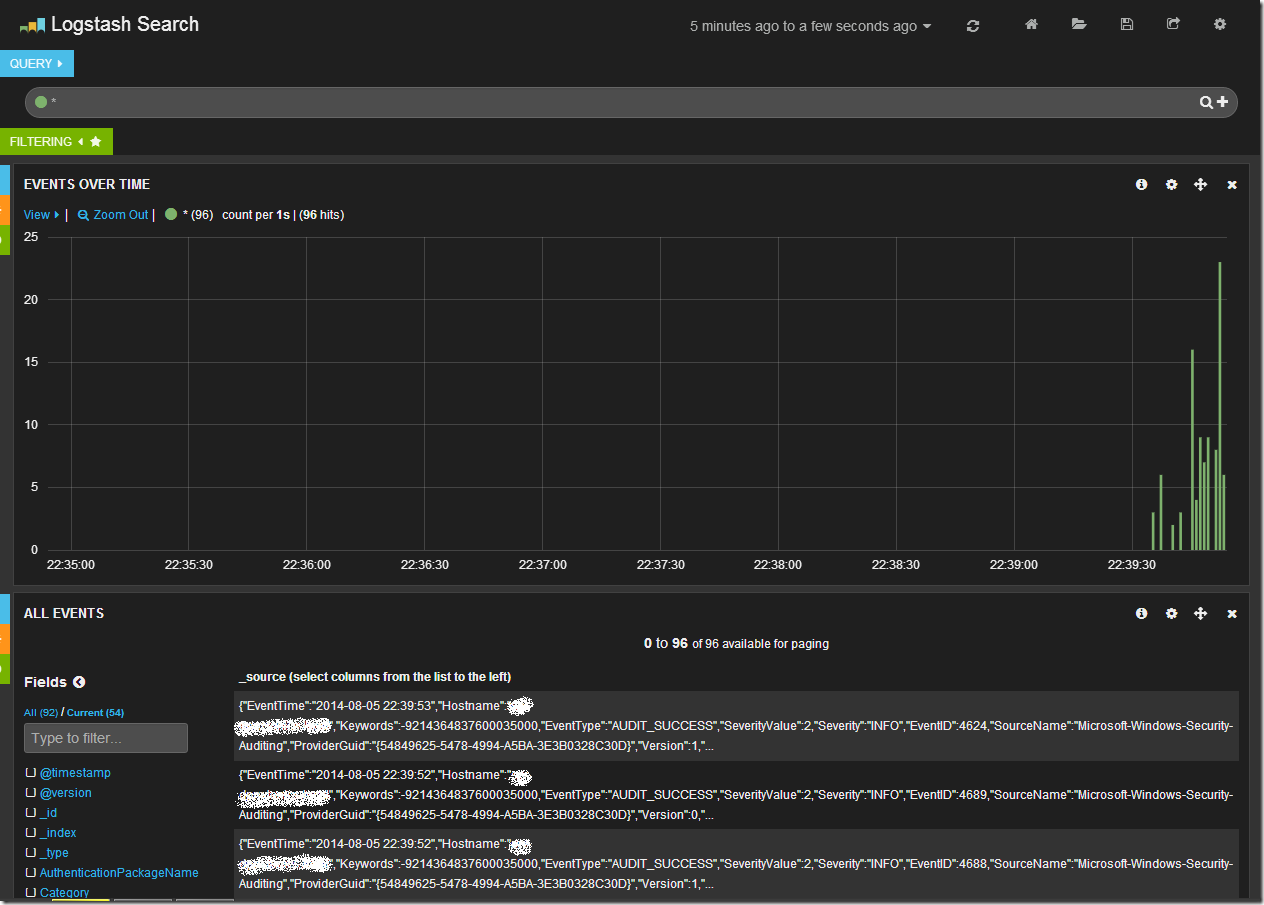
Центральный график на дашборде отражает количество записей в единицу времени. Сверху находится строка запроса и панель управления дашбордом. В нижней части таблица с данными.
Обратив свое внимание на таблицу данных мы увидим что данные показаны в “сыром” виде, однако слева от таблицы есть список полей. Щелкнув последовательно по чекбоксам с полями EventID, EventTime, EventType, Hostname, Sevirity, Message, Channel, мы получим уже более читабельный вид таблицы:
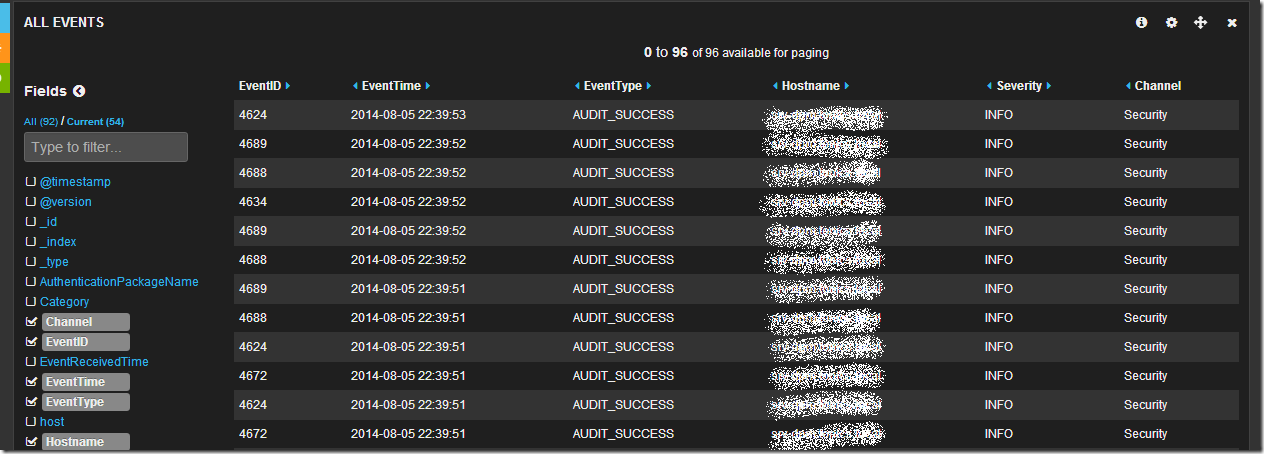
Просмотрев логи я вижу что в основном это логи из раздела Security, хочется понять какие приложения создают данные записи. Изучив список полей я нахожу поле ProcessName, если по нему кликнуть мышкой, то откроется интересное меню микроанализа по полю в котором будет перечислен TOP10 по количеству записей от процесса с их именами.
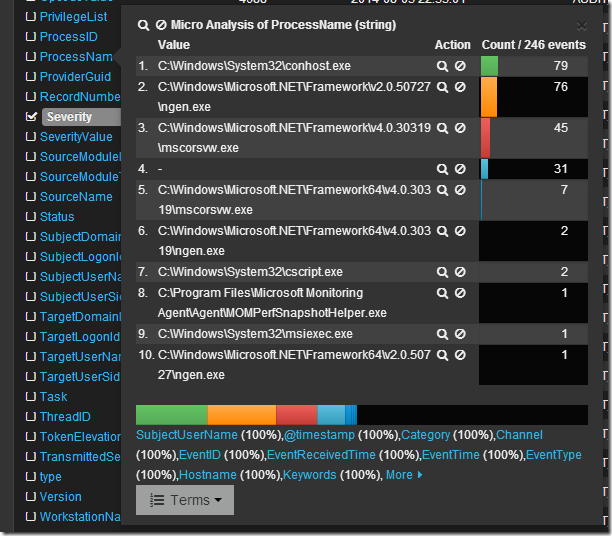
Если кликнуть по символу лупы рядом с именем процесса, то создастся фильтр по этому имени.
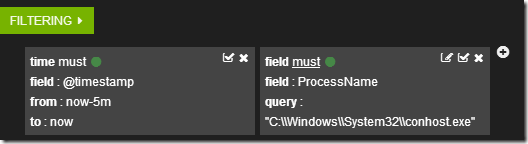
А данные в таблице отобразятся в соответствии с фильтрами.
Кликнув в таблице по любой записи можно развернуть ее в детальный вид, где будет видно все поля записи. Например так:
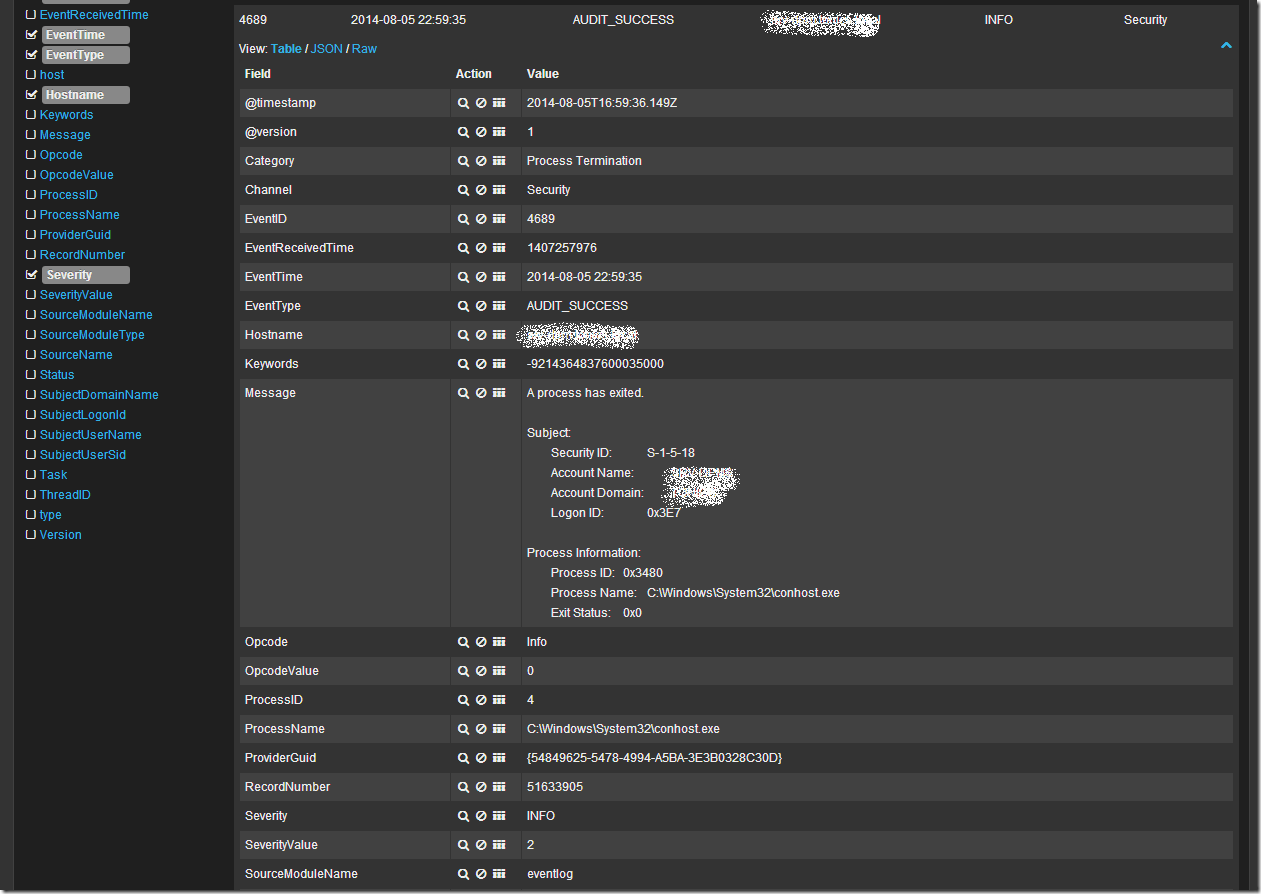
Ну и наконец если я просто хочу поискать по всем полям словосочетание “System Center” в поле запроса я пишу “System Center”. В случае поиска по конкретному полю можно воспользоваться конструкцией FieldName:”SearchQuery”, например ProcessName:»System Center». Что бы исключить из выборки данные найденные с помощью конструкции можно воспользоваться оператором “-“, например -ProcessName:»System Center» или -“System Center”. Так же работают операторы OR и AND.
Более подробно о возможностях Kibana + Logstash + Elasticsearch можно узнать из документации и вебинаров на сайте elasticsearch.org. Здесь я показал лишь малую толику того что может эта замечательная связка инструментов.
При подготовке статьи я пользовался следующими источниками:



