- Принцип работы планировщика задач в Linux
- Типы процессов в Linux
- Планирование в реальном времени
- SCHED_FIFO
- SCHED_RR
- Обобщение по планированию в реальном времени
- Условное планирование
- Виртуальное время выполнения
- CFS —Абсолютно справедливый планировщик
- Почему?
- How to Schedule a Task in Linux?
- Schedule tasks in Linux
- Настройка планировщика Cron в Linux
Принцип работы планировщика задач в Linux

Планирование – это процесс распределения ресурсов системы для выполнения задач. В статье мы рассмотрим его вариант, в котором ресурсом является одно или несколько ядер процессора, а задачи представлены потоками или процессами, которые нужно выполнить.
Само планирование осуществляется планировщиком, который нацелен:
- Максимизировать пропускную способность, то есть количество задач, выполняемых за единицу времени.
- Минимизировать время ожидания, то есть время, прошедшее с момента готовности процесса до начала его выполнения.
- Минимизировать время ответа, то есть время, прошедшее с момента готовности процесса до завершения его выполнения.
- Максимизировать равнодоступность, то есть справедливое распределение ресурсов между задачами.
Если с этими метриками вы не знакомы, то предлагаю просмотреть несколько примеров в другой моей статье (англ.), посвященной алгоритмам планировщика.
Типы процессов в Linux
В Linux процессы делятся на два типа:
- Процессы реального времени.
- Условные процессы.
Процессы реального времени должны вписываться в границы времени ответа, независимо от загрузки системы. Иначе говоря, такие процессы являются срочными и ни при каких условиях не откладываются.
В качестве примера можно привести процесс переноса, отвечающий за распределение рабочей нагрузки между ядрами ЦПУ.
Условные же процессы не ограничиваются строгими рамками времени ответа и в случае занятости системы могут подвергаться задержкам.
В пример можно привести процесс браузера, который позволяет вам читать эту статью.
У каждого типа процессов есть свой алгоритм планирования. При этом пока есть готовые к выполнению процессы реального времени, выполняться будут они, оставляя условные процессы в ожидании.
Планирование в реальном времени
В случае с планированием в реальном времени используются две политики, SCHED_RR и SCHED_FIFO .
Политика определяет количество выделяемого процессу времени, а также принцип организации очереди на выполнение.
Суть в том, что готовые к выполнению процессы хранятся в очереди, откуда выбираются планировщиком на основе той или иной политики.
SCHED_FIFO
В данной политике планировщик выбирает процесс, ориентируясь на время его поступления (FIFO = первым вошел, первым вышел).
Процесс с политикой планирования SCHED_FIFO может «освободить» ЦПУ в нескольких случаях:
- Процесс ожидает, к примеру, операции ввода/вывода, после чего по возвращению в состояние «готов» помещается в конец очереди.
- Процесс уступил ЦПУ через системный вызов sched_yield , после чего он тут же возвращается в конец очереди.
SCHED_RR
SCHED_RR подразумевает циклическое планирование.
В этой политике каждый процесс в очереди получает интервал времени (квант) и выполняется в свою очередь (исходя из приоритета) по циклическому принципу.
Для лучшего понимания рассмотрим пример, где в очереди находятся три процесса, A B C , все из которых работают по политике SCHED_RR .
Как показано ниже, каждый процесс получает квант времени и выполняется в свою очередь. После однократного выполнения всех процессов они повторяются в той же последовательности.
Обобщение по планированию в реальном времени
Процесс реального времени может планироваться по двум разным политикам, SCHED_FIFO и SCHED_RR .
Политика влияет на принцип работы очереди и определяет, сколько времени нужно выделить тому или иному процессу.
Условное планирование
Здесь мы знакомимся с Completely Fair Scheduler (CFS, абсолютно справедливый планировщик), представляющим алгоритм планирования условных процессов, появившийся в версии Linux 2.6.23.
Помните метрики планирования, которые мы затронули в начале статьи? Так вот CFS фокусируется на одной из них – он стремится к максимальной равноправности процессов, то есть обеспечивает выделение всем процессам равных квантов времени ЦПУ.
Обратите внимание, что процессы с повышенным приоритетом все равно могут получать на обработку больше времени.
Для лучшего понимания принципа работы CFS нужно познакомиться с новым термином – виртуальное время выполнения ( vruntime ).
Виртуальное время выполнения
Виртуальное время выполнения процесса – это количество времени, потраченного именно на выполнение, без учета любых ожиданий.
Как было сказано, CFS стремится быть максимально справедливым, в связи с чем по очереди планирует готовый к выполнению процесс с минимальным виртуальным временем.
CFS задействует переменные, содержащие максимальное и минимальное виртуальное время выполнения, и чуть позже станет ясно зачем.
CFS —Абсолютно справедливый планировщик
Прежде чем перейти к принципу работы этого алгоритма, нужно понять, какие структуры данных он использует.
CFS задействует красно-черное дерево, представляющее бинарное дерево поиска – то есть добавление, удаление и поиск выполняются за O(logN) , где N выражает количество процессов.
Ключом в этом дереве выступает виртуальное время выполнения процесса. Новые процессы или процесс, возвращающиеся из ожидания в состояние готовности, добавляются в дерево с ключом vruntime = min_vruntime . Это очень важный момент, который позволяет избежать дефицита внимания ЦПУ для старых процессов.
Вернемся к самому алгоритму. В первую очередь он устанавливает себе лимит времени – sched_latency .
В течение этого времени алгоритм стремится выполнить все готовые процессы – N . Это означает, что каждый процесс получит интервал времени равный временному лимиту, поделенному на количество процессов: Qi = sched_latency/N .
Когда процесс исчерпывает свой интервал ( Qi ), алгоритм выбирает в дереве следующий процесс с наименьшим виртуальным временем.
Рассмотрим ситуацию, которая может стать проблематичной для такой схемы работы алгоритма.
Предположим, что алгоритм выбрал лимит времени 48мс при наличии 6 процессов – в этом случае каждый процесс получит на выполнение по 8мс.
Но что произойдет, если система окажется перегружена процессами? Предположим, что лимит времени остается равен 48мс, но теперь у нас 32 процесса. В результате каждый получит уже всего по 1.5мс на выполнение, что приведет к замедлению работы всей системы.
Почему?
Все дело в переключении контекста, которое подразумевает сохранение состояния процесса или потока с последующим его восстановлением и продолжением выполнения.
Каждый раз, когда процесс исчерпывает свое время на выполнение, и планируется очередной процесс, активируется переключение контекста, которое также занимает некоторое время.
Предположим, что на него уходит 1мс. В первом примере, где каждому процессу у нас отводилось по 8мс, это вполне допустимо. Так мы тратим 1мс на переключение контекста и 7мс на фактическое выполнение процесса.
А вот во втором примере на выполнение каждого процесса останется уже всего по 0.5мс – то есть большая часть времени уходит на переключение контекста, отсюда и проблема с выполнением.
Для того, чтобы исправить ситуацию, мы вводим новую переменную, которая определит минимальную протяженность кванта времени выполнения – min_granularity .
Представим, что min_granularity = 6мс , и вернемся к нашему примеру, где лимит времени равен 48мс при наличии 32 процессов.
С помощью той же формулы, что и прежде, мы получаем по 1.5мс на каждый процесс, но теперь такой вариант не допускается, так как min_granularity задает минимальный квант времени, который должен получить каждый процесс.
В данном случае, где Qi , мы берем Qi равным min_granularity , то есть 6мс, и соответствующим образом изменяем временной лимит. В результате он составит Qi x N = 6мс x 32 = 192мс .
На данный момент отличия между CFS и RR могут оказаться недостаточно наглядны, поскольку они оба определяют временные интервалы и организуют порядок выполнения процессов. Для лучшего обобщения и понимания различий между этими алгоритмами я приведу краткую таблицу:
| RR – циклический список | CFS – абсолютно справедливый планировщик |
|
|
|
|
Надеюсь, что статься помогла вам лучше понять реализацию планирования задач в ядре Linux.
Прошу обратить внимание, что автор оригинальной статьи Eliran поблагодарил читателей за интерес и отдельно пригласил желающих со знанием английского языка в свой блог Coding Kaiser для ознакомления с множеством материалов по смежным и другим интересным темам, а также обмена идеями.
Источник
How to Schedule a Task in Linux?
In the case of Linux, it comes with two basic but powerful tools: Cron daemon (default task scheduler) and at (more suitable for one-time task scheduling).
In this guide, check out how to schedule a task in Linux.
Schedule tasks in Linux
Cron
The cron daemon is responsible for running a lot of jobs at specific times. These tasks are generally run in the background at scheduled times. It offers great flexibility irrespective of the task, irrespective of the interval (hour, week, month, year, or whatever).
Cron keeps track of its actions using the crontab file. The crontab file is a script that contains all the necessary information to run all the cron jobs.
Let’s have a quick look at some of the basic usage of cron. In the case of any of the following commands, it’ll be configured for the root user if it’s run with sudo privilege. For the demonstration, I’ve grabbed a sample crontab file from here.
To list all the scheduled cron jobs for the current user, run the following command. It’ll print all the contents of the crontab file.
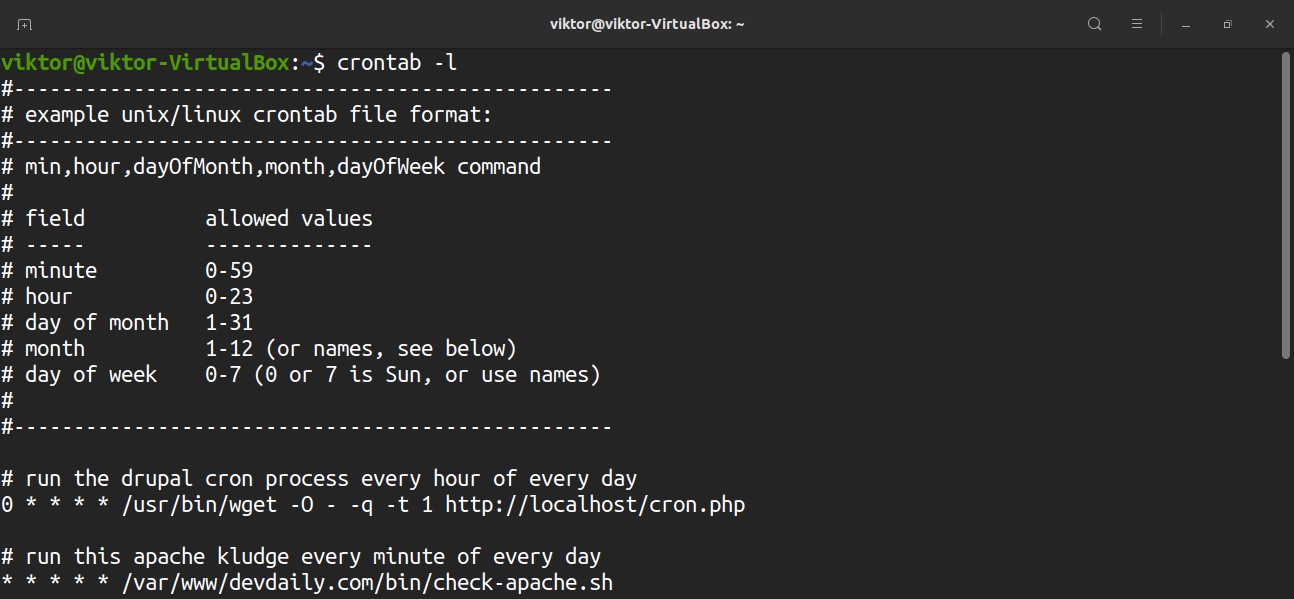
Want the cron job list for a different user? Run this command instead.
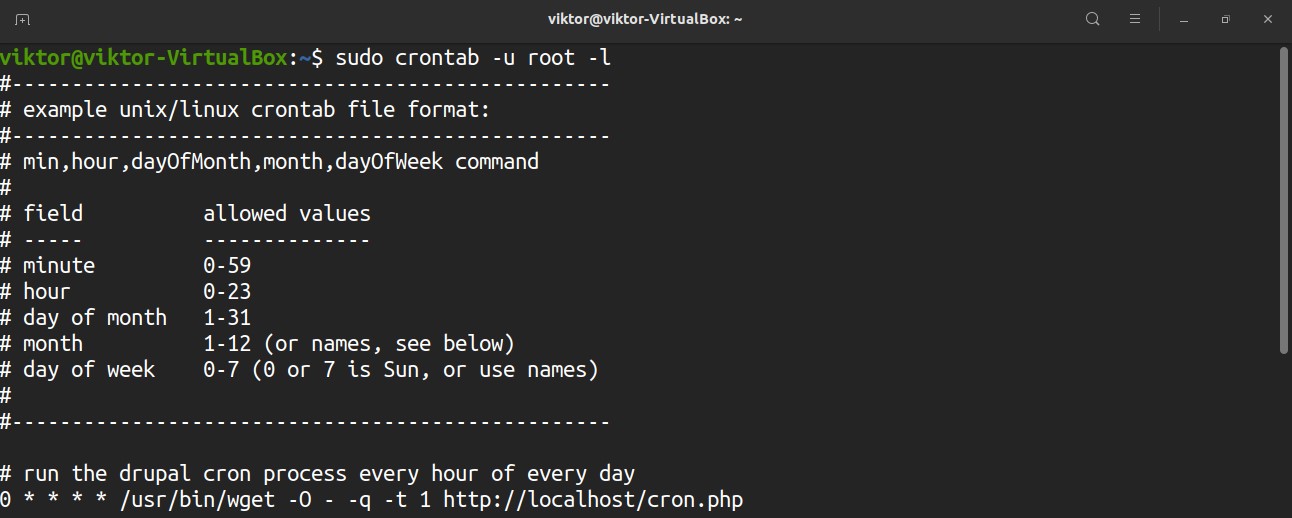
To edit the crontab script, run the command. To edit the crontab file for root, run the following command with sudo privilege.
Each line in the crontab script defines a task. Here’s a quick breakdown of the crontab entries.
Here’s a list of all the possible values for all these fields. If used an asterisk (*) instead of a numeric value, every possible value of the field will be used.
- minute: 0 to 59
- hours: 0 to 23
- day of the month: 1 to 31
- month: 1 to 12
- day of the week: 0 (Sunday) to 6 (Saturday)
For an in-depth guide on how to use crontab to automate tasks, check out how to setup cron jobs in Linux. Here’s another quick example of a cron job running every minute.
at
While cron is the primary way of task scheduling, at offers the ability to run a command/script at a specific time or at a fixed interval, note that at will run the target job once whereas cron would re-run the job at the interval. The at tool is less popular compared to cron, but it’s relatively easier to use. You can use certain keywords like midnight or teatime (4 P.M.).
This tool doesn’t come pre-installed in most of the Linux distros. To install at, run the appropriate command according to your distro.
For Debian/Ubuntu and derivatives.

For CentOS/RHEL and derivatives.
Источник
Настройка планировщика Cron в Linux
Планировщик заданий является по праву одним из важных компонентов системы. По умолчанию, в дистрибутивах Linux, а также FreeBSD, используется планировщик заданий Cron. Рассмотрим как его настроить.
Настроить cron можно несколькими способами. Самый простой и быстрый — указать задание руками в файл /etc/crontab. Проблема в том, что это может сделать только пользователь root.
Структура файла /etc/crontab представляет собой последовательность установок даты и времени, имени пользователя от которого выполняется задача и явное указание исполняемого файла.
# m h dom mon dow user command
# — строка закомментирована, т.е. не выполняется планировщиком
m — минуты. Диапазон значений 0-59
h — часы. Диапазон значений 0-23.
dom — day of month — день месяца (число). Диапазон значений 1-31
mon — месяц. Диапазон значений 1-12
dow — day of week — день недели. указывается числом, где 0 — воскресенье, 6 — суббота.
user — пользователь от которого выполняется задача.
command — выполняемая задача.
Важно! Значения минут, часов, дней месяца, дней недели, а также месяца могут быть * (звездочкой) принимая все доступные значения. Также можно использовать список параметров разделенных запятой.
Примеры разберем подробнее немного позже.
Простым пользователям доступна системная утилита crontab. Для гибкости использования используются параметры:
Используется для редактирования или создания файла расписания для текущего пользователя
Вывод существующих задач в расписании пользователя
Удаление файла расписания текущего пользователя
crontab -u username
Работа с расписаниями указанных пользователей. Выполняется только от пользователя root
Для этого в консоли пишем команду:
Запустится редактор файла используемый по умолчанию (Ubuntu — nano/vi, FreeBSD — ee), в нашем случае mcedit из пакета Midnight Commander.

Синтаксис команд идентичен как и для файла /etc/crontab, за исключением отсутствия параметра имени пользователя. Это значит, что после сохранения файла, все задачи будут выполняться от текущего пользователя.
Сохраняем файл, выходим из редактора и проверяем список заданий crontab -l.

Проверим как работает удаление файла заданий — crontab -r.

Важно! Программа не спрашивает уверены ли вы в удалении файла заданий. Если нужно удалить конкретное задание, следует использовать crontab -e.
Для администратора важно, чтобы не все пользователи могли пользоваться планировщиком. Для этих целей можно использовать файлы /etc/cron.allow и /etc/cron.deny (в некоторых дистрибутивах эти файлы должны размещаться в /etc/cton.d). По умолчанию, использование cron разрешено всем пользователям.
Примеры использования в файле /etc/crontab.
Выполнение задачи каждые 5 минут от пользователя root:
*/5 * * * * root /root/scripts/script1.sh
В полдень и полночь:
0 */12 * * * root /root/scripts/backup.sh
Перезагрузка сервера в 0:00 в первый день месяца (исключительно как пример):
0 0 1 * * root reboot
Выполнение скрипта с понедельника по пятницу в полночь:
0 0 * * 1-5 root /root/script/backup_db.sh
* 0 * * 1-5 root /root/script/backup_db.sh
Ошибка в том, что скрипт будет запускаться с понедельника по пятницу каждую минуту с 0:00 по 0:59
В заданиях назначаемых через crontab -e (т.е. от текущего пользователя) не указывается параметр имени пользователя, в случае примеров — root.
На что еще следует обратить внимание:
Все пути до исполняемых файлов следует писать абсолютными.
Скрипты исполняются из корневой директории, а следовательно, при написании скрипта следует указывать рабочий каталог, либо абсолютные пути до целевых файлов (если в ходе работы скрипта генерируются файлы-отчета и им подобные)
Источник



