/4te.me

Из-за очередного приступа параноии, я решил сменить Google Drive на собственное решение и хранить свои файлики поближе к телу. Выбор был между: поднимать в каком-нибудь DigitalOcean виртуалку и хранить там, или собрать дома свое хардварное решение. Подсчитав сколько будет стоить виртуалка с нужным объемом диска, выбор был сделан в пользу домашнего NAS-сервера.
Выбор
У меня было примерно 100 ГБ данных на момент съезда из Google Drive. Виртуалка в DigitalOcean на 160ГБ стоит 40$ в месяц, то есть в год будет выходить
500$. Дорого. За эти деньги можно дома собрать NAS на терабайт с SSD дисками. Есть ещё вариант брать маленькую виртуалку, и к нему подключить S3 хранилище, но софт, который я планировал использовать, не умеет работать с S3.
Итак, вариант с виртуалкой в облаке я отмёл и пошел смотреть, что нынче есть на рынке домашних NAS серверов. Так как я живу в маленькой квартире, NAS я планировал ставить в жилой комнате, и, если он будет шуметь вентиляторами и вибрировать HDD-дисками, то житья в комнате не будет. Поэтому я хотел найти NAS с пассивным охлаждением и вставить туда SSD диски. Не самое дешевое решение, но за тишину приходится платить.
Как выяснилось, на рынке практически нет NAS с пассивным охлаждением. Почему так я не понимаю, по опыту использования — максимальная температура дисков за год использования у меня была 47.0 C (наверно когда я переносил все данные), в покое — 36.0 C, крышка NAS-а чуть теплая. 90% времени диски простаивают и зачем им вентилятор я не понимаю.
Вот модели с пассивным охлаждением которые я смог найти — QNAP HS-210 , QNAP HS-251 , QNAP HS-251+ (он же QNAP S2 ), QNAP HS-453 . У всех моделей обычный x64-процессор, не ARM. Получается маленькая такая desktop-тачка с местом для двух HDD.
- HS-210 — 512 МБ ОЗУ мало.
- HS-251 — 1ГБ ОЗУ мало
- HS-251+ — 2ГБ ОЗУ норм
- HS-453 — 4 или 8 ГБ ОЗУ. Ultimate решение, но не продается в России и стоит космос.
У Synology бесшумных решений я не нашел. Собирать системник тоже не хотелось — он не получится таким же маленьким и бесшумным как QNAP. В общем выбрал золотую середину — QNAP HS-251+ (QNAP S2).
Из дисков я выбрал WD BLUE 3D NAND SATA SSD 1 TB (WDS100T2B0A). Взял две штуки. Они без проблем заходят в NAS. Итого вышло:
Не самое дешевое решение для NAS, но самое дешевое из подходящих под требования. Кроме этого, чтобы создать свое облако потребуется статический “белый” IP-адрес дома. Чтобы подключаться из интернета к домашнему серверу. Обычно такая услуга есть у любого провайдера.
Программная часть
После покупки и установки самого NAS-а, решил попробовать использовать софт от самого QNAP. Стоит сказать, что он очень разнообразный — полностью заменяет публичные облака и даже умеет запускать виртуальные машины. Из себя он представляет некую ОС (на основе Debian, кажется), с веб-интерфейсом а-ля iPad и проприетарными приложениями.
К сожалению все работает довольно медленно, да и менять один проприетарный продукт на другой, внутренний параноик мне не позволил, поэтому я установил на NAS обыкновенный чистый Linux.
Так как это обычный x86_64 ПК, я записал на флешку свежий дистрибутив, зашел в BIOS и загрузился с нее:
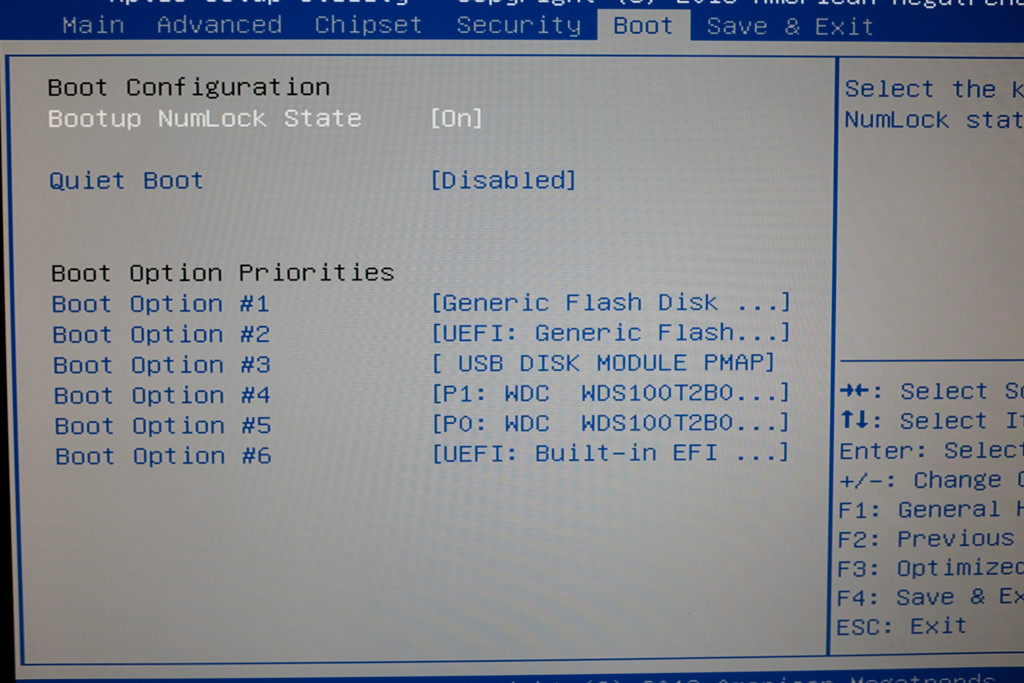
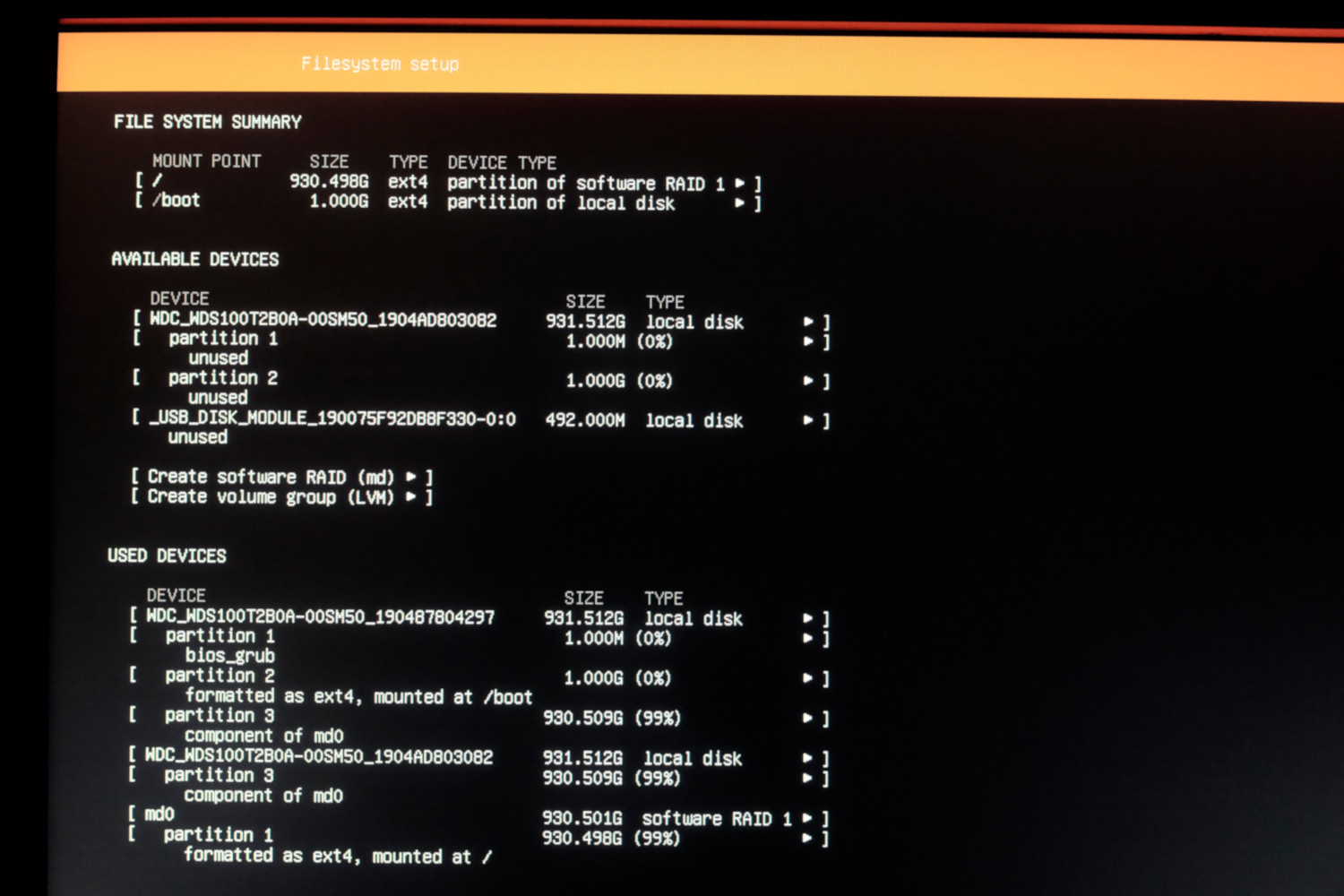
В этом NAS-е есть постоянная память размером 512 МБ куда установлена дефолтная прошивка. Ее я не перезаписывал (при желании можно будет вернуться на нее), и поставил Ubuntu 18.04 на software RAID, собранный из двух установленных дисков. На каждом диске создается по партиции одинакового размера, и они объединяются в RAID1. На одном диске также раздел для загузчика и /boot:
Домашнее облако
Для замены Google Drive (Яндекс.Диск, Dropbox и тд.) я выбрал Seafile — https://www.seafile.com/en/home/
Выбор был между ним и Nextcloud/ownCloud, но после тестовых установок выбрал Seafile. До 3-х пользователей можно использовать Enterprise версию — её и взял. В ней есть поиск по файлам и еще несколько полезных функций, вот здесь есть сравнение бесплатной и enterprise версий. Разворачивал с помощью Docker — очень просто и быстро, на сайте есть подробный мануал
У Seafile есть веб-интерфейс, desktop-приложение для всех ОС и мобильный клиент.
Nextcloud/ownCloud гораздо богаче по функционалу и хранят файлы в открытом виде, то есть их можно интегрировать в другие серверные приложения, но жуткие тормоза при аплоаде файлов и на веб-интерфейсе делают их неработопригодными.
Seafile тоже не идеален, всё что он умеет — просто хранить файлы. Особенности использования:
- хранит данные в бинарных файлах. То есть их нельзя просматривать на диске. Получаем высокую скорость при доступе к данным, но теряем в гибкости. Вот так выглядят данные на ФС:
есть приложение для Android/iOS. Довольно скромное, но заливать фотки с телефона и просматривать файлы умеет.
Домашний NAS и медиа-плеер
Так как в NAS-е есть HDMI выход, я его подключил к телевизору и сделал из него медиа-плеер. В комплекте также есть пульт ДУ:

С помощью очень классной программы Kodi (https://kodi.tv/) можно полностью заменить smartTV, онлайн-кинотеатр и приставку для проигрывания IPTV. Он устанавливается на linux и на экран выводит свой интерфейс. Навигация пультом ДУ или приложением Kore. С пультом были проблемы, не заводился из коробки, пришлось немного потанцевать с бубном.
Вот так выглядит интерфейс Kodi на телевизоре:
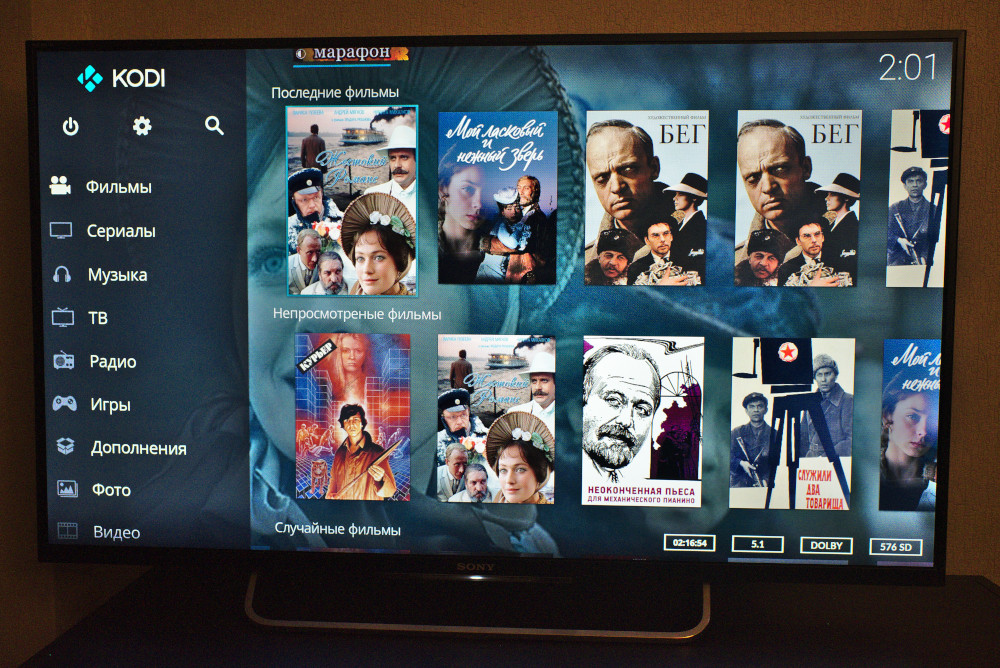
Как я использую Kodi:
- плеер фильмов, которые лежат на NAS-диске
- плеер IPTV вместо MAG-250. Умеет показывать multicast-потоки
- проигрыватель YouTube (приложение не очень удобное, но юзабельное)
- в поездках с помощью приложения Kodi для Android подключаюсь к своему NAS и смотрю с него фильмы. Получается такой self-hosted онлайн-кинотеатр
- для скачивания новых фильмов на NAS установил Transmission + web-интерфейс
Также на NAS поставил FTP и Samba, чтобы подключаться с девайсов в локальной сети и NFS для монтирования сетевого диска.
Такой схемой я пользуюсь около года и вот какие выводы сделал:
- приложения Яндекс.Диск/Google Photo удобнее и быстрее. Да, opensource-аналоги не дают такого удобства использования — то тут, то там встречаются мелкие косяки (например в android-приложении seafile фотки при просмотре скачиваются полностью, т.е. не превью сжатое, а фото если весит 5МБ — оно все полетит на телефон, это медленно и занимает место на телефоне; хотя в веб-морде есть превьюхи). Ну и поиск в Гугл.фото по содержанию фотографий (когда в поиске вводишь “горы”, и он показывает все фотографии гор из вашей библиотеки) — это вообще киллер фича, такого в бесплатные аналоги не знаю когда завезут.
- скорость загрузки файлов в Seafile гораздо выше, чем в публичные облака
- смотреть фильмы теперь супер удобно. Особенно в поездках. 4G есть практически везде в России, и теперь не надо закачивать кучу фильмов на телефон — смотрю онлайн, подключаясь с телефона к домашнему серверу. В случае отсутствия связи, например в поезде, подключаюсь по FTP и скачиваю перед отправлением.
- Kodi — супер комбайн, но хотелось бы научиться стримить телевизионный сигнал на телефон, чтобы смотреть ТВ не из дома. Этого еще не понял как сделать.
- чтобы все это настроить пришлось покурить мануалы и подзаморочиться с установкой и наладкой.
Хочу ли я вернуться в публичные облака (Google Drive, Яндекс.Диск)? Нет, не хочу. На мой взгляд, плюсов в такой схеме все же больше, чем минусов. А внутренний параноик теперь спит сладким сном.
Источник
Создание надёжного iSCSI-хранилища на Linux, часть 1
Прелюдия
Сегодня я расскажу вам как я создавал бюджетное отказоустойчивое iSCSI хранилище из двух серверов на базе Linux для обслуживания нужд кластера VMWare vSphere. Были похожие статьи (например), но мой подход несколько отличается, да и решения (тот же heartbeat и iscsitarget), используемые там, уже устарели.
Статья предназначена для достаточно опытных администраторов, не боящихся фразы «патчить и компилировать ядро», хотя какие-то части можно было упростить и обойтись вовсе без компиляции, но я напишу как делал сам. Некоторые простые вещи я буду пропускать, чтобы не раздувать материал. Цель этой статьи скорее показать общие принципы, а не расписать всё по шагам.
Вводные
Требования у меня были простые: создать кластер для работы виртуальных машин, не имеющий единой точки отказа. А в качестве бонуса — хранилище должно было уметь шифровать данные, чтобы враги, утащив сервер, до них не добрались.
В качестве гипервизора был выбран vSphere, как наиболее устоявшийся и законченый продукт, а в качестве протокола — iSCSI, как не требующий дополнительных финансовых вливаний в виде коммутаторов FC или FCoE. С опенсурсными SAS таргетами довольно туго, если не сказать хуже, так что этот вариант тоже был отвергнут.
Осталось хранилище. Разные брендовые решения от ведущих вендоров были отброшены по причине большой стоимости как их самих по себе, так и лицензий на синхронную репликацию. Значит будем делать сами, заодно и поучимся.
В качестве софта было выбрано:
- Debian Wheezy + LTS ядро 3.10
- iSCSI-таргет SCST
- DRBD для репликации
- Pacemaker для управления ресурсами кластера и мониторинга
- Подсистема ядра DM-Crypt для шифрования (инструкции AES-NI в процессоре нам очень помогут)
В итоге, в недолгих муках была рождена такая несложная схема: 
На ней видно, что каждый из серверов имеет по 10 гигабитных интерфейсов (2 встроенных и по 4 на дополнительных сетевых картах). 6 из них подключены к стеку коммутаторов (по 3 к каждому), а остальные 4 — к серверу-соседу.
По ним то и пойдёт репликация через DRBD. Карты репликации при желании можно заменить на 10-Гбит, но у меня были под рукой эти, так что «я его слепила из того, что было».
Таким образом, скоропостижная гибель любой из карт не приведёт к полной неработоспособности какой-либо из подсистем.
Так как основная задача этих хранилищ — надежное хранение больших данных (файл-сервера, архивы почты и т.п.), то были выбраны сервера с 3.5″ дисками:
- Корпус Supermicro SC836E26-R1200 на 16 3.5″ дисков
- Материнская плата Supermicro X9SRi-F
- Процессор Intel E5-2620
- 4 х 8Гб памяти DDR3 ECC
- RAID-контроллер LSI 9271-8i с суперконденсатором для аварийного сброса кэша на флэш-модуль
- 16 дисков Seagate Constellation ES.3 3Tb SAS
- 2 х 4-х портовые сетевые карты Intel Ethernet I350-T4
За дело
Диски
Я создал на каждом из серверов по два RAID10 массива из 8 дисков.
От RAID6 решил отказаться т.к. места хватало и так, а производительность у RAID10 на задачах случайного доступа выше. Плюс, ниже время ребилда и нагрузка при этом идёт только на один диск, а не на весь массив сразу.
В общем, тут каждый решает для себя.
Сетевая часть
С протоколом iSCSI бессмысленно использовать Bonding/Etherchannel для ускорения его работы.
Причина проста — при этом используются хэш-функции для распределения пакетов по каналам, поэтому очень сложно подобрать такие IP/MAC адреса, чтобы пакет от адреса IP1 до IP2 шел по однму каналу, а от IP1 до IP3 — по другому.
На cisco даже есть команда, которая позволяет посмотреть в какой из интерфейсов Etherchannel-а улетит пакет:
Поэтому, для наших целей гораздо лучше подходит использование нескольких путей до LUNа, что мы и будем настраивать.
На коммутаторе я создал 6 VLAN-ов (по одному на каждый внешний интерфейс сервера):
Интерфейсы были сделаны транковыми для универсальности и еще кое-чего, будет видно дальше:
MTU на коммутаторе следует выставить в максимум, чтобы снизить нагрузку на сервера (больше пакет -> меньше количество пакетов в секунду -> меньше генерируется прерываний). В моем случае это 9198:
ESXi не поддерживает MTU больше 9000, так что тут есть еще некоторый запас.
Каждому VLAN-у было выбрано адресное пространство, для простоты имеющее такой вид: 10.1.VLAN_ID.0/24 (например — 10.1.24.0/24). При нехватке адресов можно уложиться и в меньших подсетях, но так удобнее.
Каждый LUN будет представлен отдельным iSCSI-таргетом, поэтому каждому таргету были выбраны «общие» кластерные адреса, которые будут подниматься на ноде, обслуживающей этот таргет в данный момент: 10.1.VLAN_ID.10 и 10.1.VLAN_ID.20
Также у серверов будут постоянные адреса для управления, в моем случае это 10.1.0.100/24 и .200 (в отдельном VLAN-е)
Итак, тут мы устанавливаем на оба сервера Debian в минимальном виде, на этом останавливаться подробно не буду.
Сборка пакетов
Сборку я проводил на отдельной виртуалке, чтобы не захламлять сервера компиляторами и исходниками.
Для сборки ядра под Debian достаточно поставить мета-пакет build-essential и, возможно, еще что-то по мелочи, точно уже не помню.
Качаем последнее ядро 3.10 с kernel.org: и распаковываем:
Далее скачиваем через SVN последнюю ревизию стабильной ветки SCST, генерируем патч для нашей версии ядра и применяем его:
Теперь соберем демон iscsi-scstd:
Получившийся iscsi-scstd нужно будет положить на сервера, к примеру в /opt/scst
Далее конфигурируем ядро под свой сервер.
Включаем шифрование (если нужно).
Не забываем включить вот эти опции для SCST и DRBD:
Собираем его в виде .deb пакета (для этого нужно установить пакеты fakeroot, kernel-package и заодно debhelper):
На выходе получаем пакет kernel-scst-image-3.10.27_1_amd64.deb
Далее собираем пакет для DRBD:
Изменяем файл debian/rules до следующего состояния (там есть стандартный файл, но он не собирает модули ядра):
В файле Makefile.in подправим переменную SUBDIRS, уберем из нее documentation, иначе пакет не соберётся с руганью на документацию.
Получаем пакет drbd_8.4.4_amd64.deb
Всё, собирать больше вроде ничего не надо, копируем оба пакета на сервера и устанавливаем:
Настройка серверов
Интерфейсы у меня были переименованы в /etc/udev/rules.d/70-persistent-net.rules следующим образом:
int1-6 идут к свичу, а drbd1-4 — к соседнему серверу.
/etc/network/interfaces имеет крайне устрашающий вид, который и в кошмарном сне не приснится:
Так как мы хотим иметь отказоустойчивость и по управлению сервером, то применяем военную хитрость: в bonding в режиме active-backup собираем не сами интерфейсы, а VLAN-субинтерфейсы. Тем самым сервер будет доступен до тех пор, пока работает хотя бы один интерфейс. Это избыточно, но пуркуа бы не па. И при этом те же интерфейсы могут свободно использоваться для iSCSI траффика.
Для репликации создан интерфейс bond_drbd в режиме balance-rr, в котором пакеты отправляются тупо последовательно по всем интерфейсам. Ему назначен адрес из серой сети /24, но можно было бы обойтись и /30 или /31 т.к. хоста-то будет всего два.
Так как это иногда приводит к приходу пакетов вне очереди, увеличиваем буффер внеочередных пакетов в /etc/sysctl.conf. Ниже приведу весь файл, что какие опции делают пояснять не буду, очень долго. Можно самостоятельно почитать при желании.
По результатам тестов интерфейс репликации выдает где-то 3.7 Гбит/сек, что вполне приемлимо.
Так как сервер у нас многоядерный, а сетевые карты и RAID-контроллер умеют разделять обработку прерываний по нескольким очередям, то был написан скрипт, который привязывает прерывания к ядрам:
Диски
Перед экспортом дисков мы их зашифруем и забекапим мастер-ключи на всякий пожарный:
Пароль нужно записать на внутренней стороне черепа и никогда не забывать, а бэкапы ключей спрятать куда подальше.
Нужно иметь в виду, что после смены пароля на разделах бэкап мастер-ключа можно будет дешифровать старым паролем.
Далее был написан скрипт для упрощения дешифровки:
Скрипт работает с UUID-ами дисков, чтобы всегда однозначно идентифицировать диск в системе без привязки к /dev/sd*.
Скорость шифрования зависит от частоты процессора и количества ядер, причем запись распараллеливается лучше чем чтение. Проверить с какой скоростью шифрует сервер можно следующим нехитрым способом:
Как видно, скорости не ахти какие, но и они редко будут достигаться на практике т.к. обычно преобладает случайный характер доступа.
Для сравнения, результаты этого же теста на новеньком Xeon E3-1270 v3 на ядре Haswell:
Вот, тут гораздо веселее дело идёт. Частота — решающий фактор, судя по всему.
А если деактивировать AES-NI, то будет в несколько раз медленнее.
Настраиваем репликацию, конфиги с обоих концов должны быть на 100% идентичные.
Тут наиболее интересным параметром является протокол, сравним их.
Запись считается удачной, если блок был записан…
- A — на локальный диск и попал в локальный буфер отправки
- B — на локальный диск и попал в удаленный буфер приема
- С — на локальный и на удаленный диск
Самым медленным (читай — высоколатентным) и, одновременно, надёжным является C, а я выбрал золотую середину.
Далее идёт определение ресурсов, которыми оперирует DRBD и нод, участвующих в их репликации.
У каждого ресурса — свой порт.
Теперь инициализируем метаданные ресурсов DRBD и активируем их, это нужно сделать на каждом сервере:
Далее нужно выбрать какой-то один сервер (можно для каждого ресурса свой) и определяем, что он — главный и с него пойдёт первичная синхронизация на другой:
Всё, пошло-поехало, началась синхронизация.
В зависимости от размеров массивов и скорости сети она будет идти долго или очень долго.
За ее прогрессом можно понаблюдать командой watch -n0.1 cat /proc/drbd, очень умиротворяет и настраивает на философский лад.
В принципе, устройствами уже можно пользоваться в процессе синхронизации, но я советую отдохнуть 🙂
Конец первой части
Для одной части, я думаю, хватит. И так уже много информации для впитывания.
Во второй части я расскажу про настройку менеджера кластера и хостов ESXi для работы с этим поделием.
Источник



