ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Лучшие HEX – редакторы для Linux
В этой статье мы рассмотрим топ лучших шестнадцатеричных редакторов для Linux. Но прежде чем мы начнем, давайте посмотрим на то, что на самом деле является hex-редактором.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps


Про Linux за 5 минут

Что такое Hex-редактор
Hex-редактор, или проще говоря, шестнадцатеричный редактор позволяет вам просматривать и редактировать двоичные файлы. Разница между обычным текстовым редактором и шестнадцатеричным редактором заключается в том, что обычный редактор представляет логическое содержимое файла, тогда как шестнадцатеричный редактор представляет физическое содержимое файла.
Кто использует Hex-редакторы
Шестнадцатеричные редакторы используются для редактирования отдельных байтов данных и в основном используются программистами или системными администраторами. Некоторые из наиболее распространенных случаев — это отладка или обратная инженерия (reverse engineering) двоичных протоколов связи. Конечно, есть много других вещей, которые вы можете использовать в шестнадцатеричных редакторах — например, просмотр файлов с неизвестным форматом файла, выполнение шестнадцатеричного сравнения, просмотр дампа памяти программы и другое.
Большинство из упомянутых шестнадцатеричных редакторов доступны для установки из репозитория по умолчанию с помощью диспетчера пакетов вашего дистрибутива, например:
Если пакет недоступен, перейдите на веб-сайт каждого инструмента, где вы сможете получить отдельный пакет для процедур загрузки и установки, а также подробную информацию о зависимостях.
Xxd Hex Editor
Большинство (если не все) дистрибутивов Linux поставляются с редактором, который позволяет выполнять шестнадцатеричные и двоичные манипуляции. Одним из таких инструментов является инструмент командной строки — xxd, наиболее часто используемый для создания шестнадцатеричного дампа данного файла или стандартного ввода. Он также может конвертировать шестнадцатеричный дамп обратно в исходную двоичную форму.
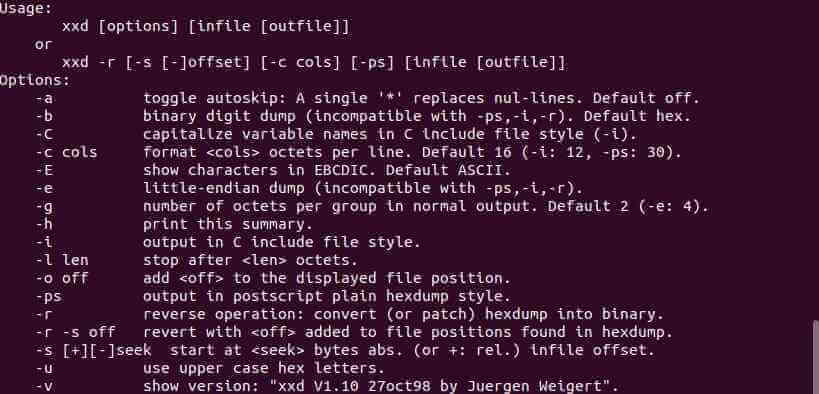
Hexedit Hex Editor
Hexedit — это еще один шестнадцатеричный редактор командной строки, который уже может быть предварительно установлен в вашей ОС. Hexedit показывает и шестнадцатеричное и ASCII представление файла одновременно.
Hexyl Hex Editor
Другой полезный инструмент для проверки двоичного файла — это hexyl, простой просмотрщик шестнадцатеричных данных для терминала Linux, который использует цветной вывод для определения различных категорий байтов.

Его вид разделен на три колонки:
- Смещенный столбец, указывающий количество байтов в файле.
- Шестнадцатеричный столбец, который содержит шестнадцатеричное представление файла.
- Текстовое представление файла.
Установка этого шестнадцатеричного вьюера различна для разных операционных систем, поэтому рекомендуется проверить файл read-me в проекте, чтобы увидеть точные инструкции по установке для вашей ОС. Ссылка на GitHub.
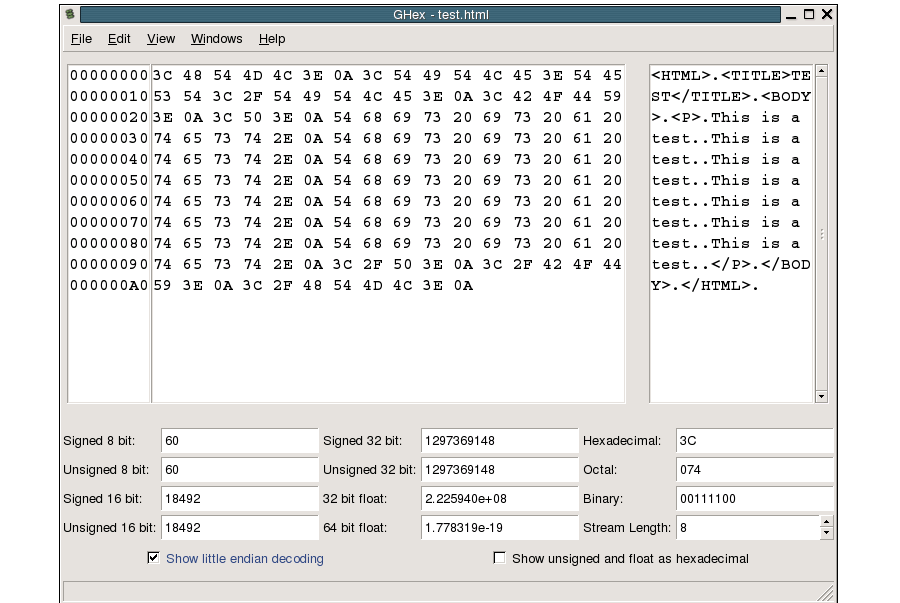
Ghex — GNOME Hex Editor
Ghex — это графический шестнадцатеричный редактор, который позволяет пользователям редактировать двоичный файл как в шестнадцатеричном, так и в ASCII формате. Он имеет многоуровневый механизм отмены и повтора, который некоторые могут найти полезным. Еще одна полезная функция — функции поиска и замены, а также преобразование двоичных, восьмеричных, десятичных и шестнадцатеричных значений.
Bless Hex Editor
Одним из наиболее продвинутых шестнадцатеричных редакторов в этой статье является Bless, похожий на Ghex, он имеет графический интерфейс, который позволяет редактировать большие файлы данных с многоуровневым механизмом отмены/повторения. Он также имеет настраиваемые представления данных, функцию поиска-замены и многопоточные операции поиска и сохранения. Несколько файлов могут быть открыты одновременно с помощью вкладок. Функциональность также может быть расширена с помощью плагинов. Ссылка на GitHub.
Okteta Editor
Okteta — еще один простой редактор для просмотра файлов необработанных данных. Некоторые из основных особенностей октета включают в себя:
- Различные представления символов — традиционные в столбцах или в строках со значением верха символа.
- Редактирование аналогично текстовому редактору.
- Различные профили для просмотра данных.
- Несколько открытых файлов.
- Удаленные файлы по FTP или HTTP.
wxHexEditor
wxHexEditor — еще один из шестнадцатеричных редакторов Linux, обладающий некоторыми расширенными функциями.
whHexEditor предназначен в основном для больших файлов. Он работает быстрее с большими файлами, потому что он не пытается скопировать весь файл в вашу оперативную память. Он имеет низкое потребление памяти и может просматривать несколько файлов одновременно.
Hexcurse — Conx Hex Editor
Hexcurse — это шестнадцатеричный редактор на основе ncurses. Он может открывать, редактировать и сохранять файлы в дружественном терминальном интерфейсе, который позволяет перейти к определенной строке или выполнить поиск. Вы можете легко переключаться между шестнадцатеричными или десятичными адресами, или переключаться между шестнадцатеричными и ASCII-окнами.
Hexer Binary Editor
Hexer — еще один бинарный редактор командной строки. Его отличительная особенность заключается в том, что это Vi-подобный редактор стилей для бинарных файлов. Некоторые из наиболее заметных особенностей — много буферов, многоуровневая отмена, редактирование командной строки с завершением и двоичное регулярное выражение.
Emacs
Emacs является альтернативой текстовому редактору Vim и предоставляет функции редактирования в шестнадцатеричном формате. Простота и удобное переключение между режимами являются важнейшими особенностями Emacs
Заключение
Это был краткий обзор некоторых наиболее часто используемых шестнадцатеричных редакторов в Linux. Какие шестнадцатеричные редакторы вы используете и почему вы предпочитаете именно этот редактор? Что делает его лучше других?
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
Команда hexdump в Linux с примерами
Команда hd или hexdump в Linux используется для фильтрации и отображения указанных файлов или стандартного ввода в удобочитаемом заданном формате. Например, если вы хотите просмотреть исполняемый код программы, вы можете использовать hexdump для этого.
Синтаксис:
Параметры:
- -b: восьмибайтный восьмеричный дисплей. Отобразите входное смещение в шестнадцатеричном формате, за которым следуют шестнадцать разделенных пробелами трехстрочных заполненных нулями байтов входных данных в восьмеричном виде на строку.
Синтаксис:

Первый столбец выходных данных представляет входное смещение в файле.
-c: однобайтовое отображение символов. Отобразите смещение ввода в шестнадцатеричном формате, за которым следуют шестнадцать разделенных пробелами трехстрочных символов, заполненных пробелами, входных данных на строку.
Синтаксис:

-C: канонический шестнадцатеричный + ASCII дисплей. Отобразите смещение ввода в шестнадцатеричном формате, за которым следуют шестнадцать разделенных пробелами двух столбцов шестнадцатеричных байтов, за которыми следуют те же шестнадцать байтов в формате% _p, заключенные в символы «|».
Синтаксис:

-d: двухбайтовый десятичный дисплей. Отобразите входное смещение в шестнадцатеричном формате, за которым следуют восемь разделенных пробелами пятибалочных заполненных нулями двухбайтовых единиц входных данных в десятичном формате без знака на строку.
Синтаксис:

-n длина: где длина является целым числом. Интерпретирует только байты длины.
Синтаксис:

-o: двухбайтовый восьмеричный дисплей. Отобразите входное смещение в шестнадцатеричном формате, за которым следуют восемь разделенных пробелами шести столбцов, заполненных нулями, двухбайтовых количеств входных данных, в восьмеричном, на строку.
Синтаксис:

-s offset: пропустить байты ‘offset’ от начала ввода. По умолчанию смещение интерпретируется как десятичное число. С начальным 0x или 0X смещение интерпретируется как шестнадцатеричное число, в противном случае с начальным 0 смещение интерпретируется как восьмеричное число. Добавление символа b, k или m к смещению заставляет его интерпретироваться как кратное 512, 1024 или 1048576 соответственно.
Синтаксис:

Как вы можете видеть, в выводе пропускаются первые 6 символов, то есть «Hello».
-v: заставить hexdump отображать все входные данные. Без опции -v любое количество групп выходных строк, которые были бы идентичны непосредственно предшествующей группе выходных строк (за исключением входных смещений), заменяется строкой, состоящей из одной звездочки.
Синтаксис:
Мы увидим использование этой опции, когда отобразим вывод, используя флаг -c .

Как вы можете заметить, когда мы используем hd впервые, без -v, когда появляется похожий вывод, он печатает звездочку (*). Но когда мы передаем флаг -v , мы получаем все выходные строки.
-x: двухбайтовый шестнадцатеричный дисплей. Отобразите входное смещение в шестнадцатеричном формате, за которым следует восемь, разделенных пробелами, четыре столбца, заполненные нулями, двухбайтовые количества входных данных в шестнадцатеричном формате на строку.
Источник
hexdump – Команда Linux – Команда Unix
hexdump – ascii, десятичный, шестнадцатеричный, восьмеричный дамп
конспект
[- bcCdovx ] -words [- e format_string ] -words [- f format_file ] -words [- n длина ] -words [- s пропустить ] файл. ..
Описание
Утилита hexdump представляет собой фильтр, который отображает указанные файлы или стандартный ввод, если файлы не указаны, в указанном пользователем формате.
Возможны следующие варианты:
-b
Однобайтовое восьмеричное отображение Отображает смещение ввода в шестнадцатеричном формате, за которым следуют шестнадцать разделенных пробелом трехбайтных заполненных нулями байтов входных данных в восьмеричном виде на строку.
-c
Отображение однобайтовых символов Отображение смещения ввода в шестнадцатеричном формате, за которым следуют шестнадцать разделенных пробелами трехстрочных символов, заполненных пробелом, символов входных данных на строку.
-C
Канонический шестнадцатеричный + ASCII-дисплей Показать смещение ввода в шестнадцатеричном формате, за которым следуют шестнадцать разделенных пробелами двух столбцов шестнадцатеричных байтов, за которыми следуют те же шестнадцать байтов в формате% _p, заключенные в символы “ | ” ,
-d
Двухбайтовое десятичное отображение Отображение входного смещения в шестнадцатеричном формате, за которым следуют восемь разделенных пробелами пятиблочных заполненных нулями двухбайтовых единиц входных данных в десятичном формате без знака на строку.
-e format_string
Укажите строку формата, которая будет использоваться для отображения данных.
-f format_file
Укажите файл, который содержит одну или несколько строк формата, разделенных символом новой строки. Пустые строки и строки, первым непустым символом которых является хеш-метка ( # , игнорируются.
-n Длина
Интерпретировать только длину байтов ввода.
-o
Двухбайтовое восьмеричное отображение Отображает смещение ввода в шестнадцатеричном формате, за которым следуют восемь разделенных пробелами двухбайтных двухбайтовых количеств входных данных, в восьмеричном, на строку.
-s смещение
Пропустить смещение байтов от начала ввода. По умолчанию смещение интерпретируется как десятичное число. С начальным 0x или 0X смещение интерпретируется как шестнадцатеричное число, в противном случае с начальным 0 Смещение интерпретируется как восьмеричное число. Добавление символа b k или m к смещению приводит к его интерпретации как кратное 512 1024 или 1048576 соответственно.
-v
Опция – v заставляет hexdump отображать все входные данные. Без параметра – v любое количество групп выходных строк, которые будут идентичны непосредственно предшествующей группе выходных строк (за исключением входных смещений), заменяется строкой, состоящей из одного звездочка.
-x
Двухбайтовое шестнадцатеричное отображение Отображение входного смещения в шестнадцатеричном формате, за которым следуют восемь, разделенных пробелами, четыре столбца, заполненные нулями, двухбайтовые количества входных данных, в шестнадцатеричном формате, на строку.
Для каждого входного файла последовательно копирует входные данные в стандартный вывод, преобразуя данные в соответствии со строками формата, заданными параметрами – e и – f , в том порядке, в котором они были указаны.
Форматы
Строка формата содержит любое количество единиц формата, разделенных пробелами. Единица формата содержит до трех элементов: счетчик итераций, счетчик байтов и формат.
Счетчик итераций является необязательным положительным целым числом, по умолчанию равным единице. К каждому формату применяется количество итераций.
Число байтов является необязательным положительным целым числом. Если указан, он определяет количество байтов, которые будут интерпретироваться каждой итерацией формата.
Если указан счетчик итераций и/или счетчик байтов, после счетчика итераций и/или до счетчика байтов необходимо поместить один слеш, чтобы устранить их неоднозначность. Любые пробелы до или после косой черты игнорируются.
Формат обязателен и должен быть заключен в двойные кавычки (“”). Он интерпретируется как строка формата в стиле fprintf (см. Fprintf (3)), со следующими исключениями:
- Звездочка (*) не может использоваться в качестве ширины или точности поля.
- Счетчик байтов или точность поля требуется для каждого символа преобразования “ s ” (в отличие от значения по умолчанию fprintf (3), которое печатает всю строку, если точность не указана).
- Символы преобразования “ h ”, “ l ”, “ n ”, “ p ” и “ q ” не поддерживаются.
- Поддерживаются escape-последовательности из одного символа, описанные в стандарте C:
Hexdump также поддерживает следующие дополнительные строки преобразования:
_а [ DOX ]
Отображение входного смещения, накопленного по входным файлам, следующего отображаемого байта. Добавленные символы d o и x определяют основание дисплея как десятичное, восьмеричное или шестнадцатеричное соответственно.
_А [ DOX ]
Идентичен строке преобразования _a , за исключением того, что она выполняется только один раз, когда все входные данные обработаны.
_c
Выведите символы в наборе символов по умолчанию. Непечатаемые символы отображаются в виде трехбуквенных восьмеричных символов, за исключением тех, которые представлены стандартными escape-обозначениями (см. Выше), которые отображаются в виде двухсимвольных строк.
_p
Выведите символы в наборе символов по умолчанию. Непечатаемые символы отображаются как один “ . ”
_u
Выведите символы ASCII США, за исключением того, что управляющие символы отображаются с использованием следующих строчных имен. Символы больше 0xff, шестнадцатеричные, отображаются в виде шестнадцатеричных строк.
000 nul 001 soh 002 stx 003 etx 004 eot 005 enq
006 ack 007 бел 008 bs 009 ht 00A lf 00B vt
00C ff 00D cr 00E, поэтому 00F si 010 dle 011 dc1
012 DC2 013 DC3 014 DC4 015 Nak 016 Syn 017 ETB
018 банок 019 em 01A sub 01B esc 01C fs 01D gs
01E 01F us 0FF del
Значения байтов по умолчанию и поддерживаемых байтов для символов преобразования следующие:
% _ c,% _p,% _u,% c
Один байт считается только.
% d,% i,% o % u,% X,% x
Поддерживается четыре байта по умолчанию, один, два и четыре байта.
% E,% e,% f % G,% g
Восемь байтов по умолчанию, поддерживается четыре байта.
Количество данных, интерпретируемое каждой строкой формата, является суммой данных, требуемых каждой единицей формата, которая представляет собой число итераций, умноженное на количество байтов, или число итераций, умноженное на количество байтов, требуемое форматом, если число байтов не указано.
Входные данные обрабатываются в «блоках», где блок определяется как наибольшее количество данных, указанное в любой строке формата. Строки форматирования интерпретируют меньше данных входного блока, последний блок форматирования которых интерпретирует некоторое количество байтов и не имеет заданного числа итераций, увеличивают счетчик итераций до тех пор, пока не будет обработан весь входной блок или не будет достаточно данных оставаясь в блоке, чтобы удовлетворить формат строки.
Если в результате пользовательской спецификации или hexdump, изменяющего счетчик итераций, как описано выше, счетчик итераций больше единицы, во время последней итерации никакие завершающие пробельные символы не выводятся.
Ошибочно указывать количество байтов, а также несколько символов или строк преобразования, если только все символы, кроме одного, или строки преобразования не являются _a или _A .
Если в результате задания параметра – n или достижения конца файла входные данные только частично удовлетворяют строке формата, входной блок дополняется нулями в достаточной степени, чтобы отобразить все доступные данные (т.е. любые единицы формата, перекрывающие конец данных, будут отображать некоторое количество нулевых байтов).
Дальнейший вывод строк такого формата заменяется эквивалентным количеством пробелов. Эквивалентное количество пробелов определяется как количество пробелов, выводимых символом преобразования s с той же шириной поля и точностью, что и исходный символ преобразования или строка преобразования, но с любым “ + ” “ ” “ # ” удалены символы флагов преобразования и со ссылкой на пустую строку.
Если строки формата не указаны, отображение по умолчанию эквивалентно указанию параметра – x .
в случае успеха выходит 0 и> 0 в случае ошибки.
Источник



