- Распознавание речи на python с помощью pocketsphinx или как я пытался сделать голосового ассистента
- Установка Pocketsphinx
- Распознавание речи при помощи pocketsphinx
- Русская языковая и акустическая модель
- Создаем свой словарь
- Использование pocketsphinx через speech_recognition
- Создание голосового ассистента на Python, часть 1
- # Синтез речи
- # Установка пакетов в Windows
- # Преобразование текста в речь
- # Доступные синтезаторы по умолчанию
- # Установка дополнительных голосов в Windows
- # Выбор голоса
- # Как озвучить системное время в Windows
- # Упражнения tkinter
- # Озвучиваем текст из файла
- # Упражнения tkinter
- # Модуль Google TTS — голоса из интернета
Распознавание речи на python с помощью pocketsphinx или как я пытался сделать голосового ассистента
Это туториал по использованию библиотеки pocketsphinx на Python. Надеюсь он поможет вам
побыстрее разобраться с этой библиотекой и не наступать на мои грабли.
Началось все с того, что захотел я сделать себе голосового ассистента на python. Изначально для распознавания решено было использовать библиотеку speech_recognition. Как оказалось, я не один такой. Для распознавания я использовал Google Speech Recognition, так как он единственный не требовал никаких ключей, паролей и т.д. Для синтеза речи был взят gTTS. В общем получился почти клон этого ассистента, из-за чего я не мог успокоиться.
Правда, успокоиться я не мог не только из-за этого: ответа приходилось ждать долго (запись заканчивалась не сразу, отправка речи на сервер для распознавания и текста для синтеза занимала немало времени), речь не всегда распознавалась правильно, дальше полуметра от микрофона приходилось кричать, говорить нужно было четко, синтезированная гуглом речь звучала ужасно, не было активационной фразы, то есть звуки постоянно записывались и передавались на сервер.
Первым усовершенствованием был синтез речи при помощи yandex speechkit cloud:
Затем настала очередь распознавания. Меня сразу заинтересовала надпись «CMU Sphinx (works offline)» на странице библиотеки. Я не буду рассказывать об основных понятиях pocketsphinx, т.к. до меня это сделал chubakur(за что ему большое спасибо) в этом посте.
Установка Pocketsphinx
Сразу скажу, так просто pocketsphinx установить не получится(по крайней мере у меня не получилось), поэтому pip install pocketsphinx не сработает, упадет с ошибкой, будет ругаться на wheel. Установка через pip будет работать только если у вас стоит swig. В противном случае чтобы установить pocketsphinx нужно перейти вот сюда и скачать установщик(msi). Обратите внимание: установщик есть только для версии 3.5!
Распознавание речи при помощи pocketsphinx
Pocketsphinx может распознавать речь как с микрофона, так и из файла. Также он может искать горячие фразы(у меня не очень получилось, почему-то код, который должен выполняться когда находится горячее слово выполняется несколько раз, хотя произносил его я только один). От облачных решений pocketsphinx отличается тем, что работает оффлайн и может работать по ограниченному словарю, вследствие чего повышается точность. Если интересно, на странице библиотеки есть примеры. Обратите внимание на пункт «Default config».
Русская языковая и акустическая модель
Изначально pocketsphinx идет с английской языковой и акустической моделями и словарем. Скачать русские можно по этой ссылке. Архив нужно распаковать. Затем надо папку /zero_ru_cont_8k_v3/zero_ru.cd_cont_4000 переместить в папку C:/Users/tutam/AppData/Local/Programs/Python/Python35-32/Lib/site-packages/pocketsphinx/model , где это папка в которую вы распаковали архив. Перемещенная папка — это акустическая модель. Такую же процедуру надо проделать с файлами ru.lm и ru.dic из папки /zero_ru_cont_8k_v3/ . Файл ru.lm это языковая модель, а ru.dic это словарь. Если вы все сделали правильно, то следующий код должен работать.
Предварительно проверьте чтобы микрофон был подключен и работал. Если долго не появляется надпись Say something! — это нормально. Большую часть этого времени занимает создание экземпляра LiveSpeech , который создается так долго потому, что русская языковая модель весит более 500(!) мб. У меня экземпляр LiveSpeech создается около 2 минут.
Этот код должен распознавать почти любые произнесенные вами фразы. Согласитесь, точность отвратительная. Но это можно исправить. И увеличить скорость создания LiveSpeech тоже можно.
Вместо языковой модели можно заставить pocketsphinx работать по упрощенной грамматике. Для этого используется jsgf файл. Его использование ускоряет создание экземпляра LiveSpeech . О том как создавать файлы граматики написано здесь. Если языковая модель есть, то jsgf файл будет игнорироваться, поэтому если вы хотите использовать собственный файл грамматики, то нужно писать так:
Естественно файл с грамматикой надо создать в папке C:/Users/tutam/AppData/Local/Programs/Python/Python35-32/Lib/site-packages/pocketsphinx/model . И еще: при использовании jsgf придется четче говорить и разделять слова.
Создаем свой словарь
Словарь — это набор слов и их транскрипций, чем он меньше, тем выше точность распознавания. Для создания словаря с русскими словами нужно воспользоваться проектом ru4sphinx. Качаем, распаковываем. Затем открываем блокнот и пишем слова, которые должны быть в словаре, каждое с новой строки, затем сохраняем файл как my_dictionary.txt в папке text2dict , в кодировке UTF-8. Затем открываем консоль и пишем: C:\Users\tutam\Downloads\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt . Открываем my_dictionary_out.txt , копируем содержимое. Открываем блокнот, вставляем скопированный текст и сохраняем файл как my_dict.dic (вместо «текстовый файл» выберите «все файлы»), в кодировке UTF-8.
Некоторые транскрипции может быть нужно подправить.
Использование pocketsphinx через speech_recognition
Использовать pocketsphinx через speech_recognition имеет смысл только если вы распознаете английскую речь. В speech_recognition нельзя указать пустую языковую модель и использовать jsgf, а следовательно для распознавания каждого фрагмента придется ждать 2 минуты. Проверенно.
Угробив несколько вечеров я понял, что потратил время впустую. В словаре из двух слов(да и нет) сфинкс умудряется ошибаться, причем часто. Отъедает 30-40% celeron’а, а с языковой моделью еще и жирный кусок памяти. А Яндекс почти любую речь распознает безошибочно, при том не ест память и процессор. Так что думайте сами, стоит ли за это браться вообще.
Источник
Создание голосового ассистента на Python, часть 1
Добрый день. Наверное, все смотрели фильмы про железного человека и хотели себе голосового помощника, похожего на Джарвиса. В этом посте я расскажу, как сделать такого ассистента с нуля. Моя программа будет написана на python 3 в операционной системе windows. Итак, поехали!
Работать наш ассистент будет по такому принципу:
- Постоянно «слушать» микрофон
- Распознавать слова в google
- Выполнять команду, либо отвечать
1) Синтез речи
Для начала мы установим в систему windows русские голоса. Для этого переходим по ссылке и скачиваем голоса в разделе SAPI 5 -> Russian. Там есть 4 голоса, можно выбрать любой, какой вам понравится. Устанавливаем и идём дальше.
Нам нужно поставить библиотеку pyttsx3 для синтеза речи:
Затем можно запустить тестовую программу и проверить правильность её выполнения.
2) Распознавание речи
Существует много инструментов для распознавания речи, но они все платные. Поэтому я пытался найти бесплатное решение для моего проекта и нашёл её! Это библиотека speech_recognition.
Также для работы с микрофоном нам необходима библиотека PyAudio.
У некоторых людей возникает проблема с установкой PyAudio, поэтому следует перейти по этой ссылке и скачать нужную вам версию PyAudio. Затем ввести в консоль:
Затем запускаете тестовую программу. Но перед этим вы должны исправить в ней device_index=1 на своё значение индекса микрофона. Узнать индекс микрофона можно с помощью этой программы:
Тест распознавания речи:
Если всё отлично, переходим дальше.
Если вы хотите, чтобы ассистент просто общался с вами (без ИИ), то это можно сделать с помощью бесплатного инструмента DialogFlow от Google. После того, как вы залогинетесь, вы увидите экран, где уже можно создать своего первого бота. Нажмите Create agent. Придумайте боту имя (Agent name), выберете язык (Default Language) и нажмите Create. Бот создан!
Чтобы добавить новые варианты ответов на разные вопросы, нужно создать новый intent. Для этого в разделе intents нажмите Create intent. Заполните поля «Название» и Training phrases, а затем ответы. Нажмите Save. Вот и всё.
Чтобы управлять ботом на python, нужно написать такой код. В моей программе бот озвучивает все ответы.
На сегодня всё. В следующей части я расскажу как сделать умного бота, т.е. чтобы он мог не только отвечать, но и что-либо делать.
Источник
# Синтез речи
Познакомимся, как использовать Python для преобразования текста в речь с использованием кроссплатформенной библиотеки pyttsx3 . Этот пакет работает в Windows, Mac и Linux. Он использует родные драйверы речи, когда они доступны, и работает в оффлайн режиме.
Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Есть функции, которые здесь не рассматриваются, такие как система событий. Вы можете подключить движок к определенным событиям:
- можно посчитать, сколько слов сказано, и обрезать его,
- можно проверить каждое слово и отрезать его, если есть неуместные слова.
Всегда обращайтесь к официальной документации для получения наиболее точной, полной и актуальной информации https://pyttsx3.readthedocs.io/en/latest/
# Установка пакетов в Windows
Используйте pip для установки пакета. В Windows, вам понадобится дополнительный пакет pypiwin32 , который понадобится для доступа к собственному речевому API Windows.
# Преобразование текста в речь
Для первой программой озвучивания текста используем код:
В примере программы даны две фразы на английском и на русском языке. Существует голосовой набор по умолчанию, поэтому вам не нужно выбирать голос. В зависимости от версии windows будет озвучена соответствующая фраза. Например для английской версии windows услышим: «I can speak!»
# Доступные синтезаторы по умолчанию
Доступные голоса будут зависеть от версии установленной систем. Вы можете получить список доступных голосов на вашем компьютере. Обратите внимание, что голоса, имеющиеся у вас на компьютере, могут отличаться от чьей-либо машины.
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Получить список доступных голосов можно так:
Результат будет примерно таким:
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID.
# Установка дополнительных голосов в Windows
При желании можно установить дополнительные языковые пакеты согласно инструкции https://support.microsoft.com/en-us/help/14236/language-packs#lptabs=win10
Для этого выполните указанные ниже действия.
Нажмите кнопку Пуск , затем выберите Параметры > Время и язык > Язык.
В разделе Предпочитаемые языки выберите Добавить язык.
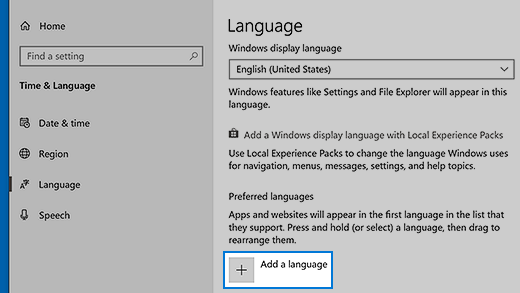
В разделе Выберите язык для установки выберите или введите название языка, который требуется загрузить и установить, а затем нажмите Далее.
В разделе Установка языковых компонентов выберите компоненты, которые вы хотите использовать на языке.
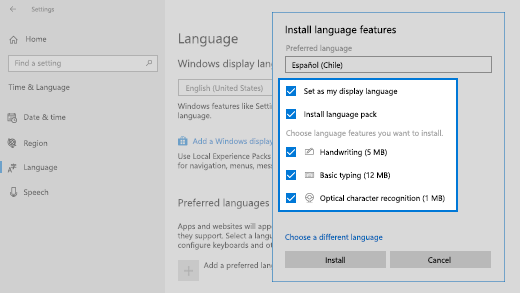
ВНИМАНИЕ: отключите первый пакет: «Install language pack and set as my Windows display language» — «Установите языковой пакет и установите мой язык отображения Windows»
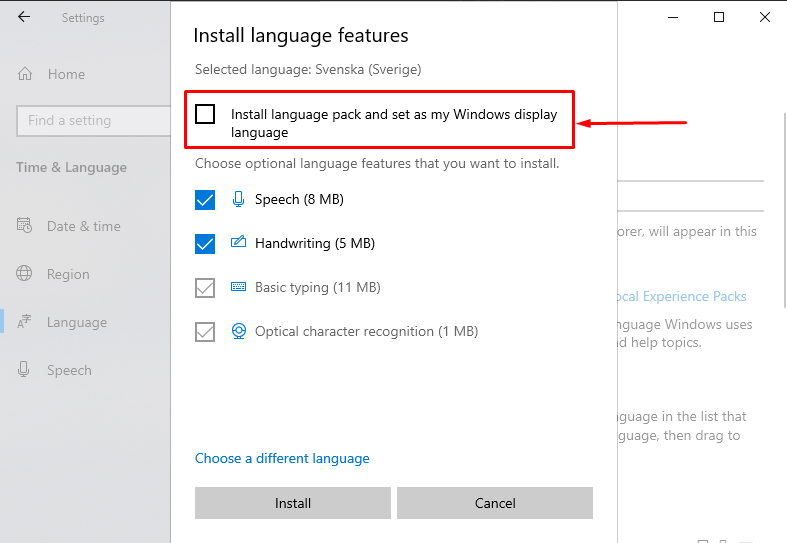
Иначе переустановиться язык отображения операционной системы.
Нажмите Установить.
После установки нового языкового пакета перезагрузка не требуется. Запустив код проверки установленных языков. Новый язык должен отобразиться в списке.
Не все языковые пакеты поддерживают синтез речи. Для этого опция Speech должны быть в описании установки.
# Выбор голоса
Установить голос можно методом setProperty() . Например, используя голосовые идентификаторы, найденные ранее, вы можете настроить голос. В примере показано, как настроить один голос, чтобы сказать что-то, а затем использовать другой голос из другого языка, чтобы сказать что-то другое.
В Windows идентификатором служит адрес записи в системном реестре:
# Как озвучить системное время в Windows
Пример консольного приложения которое будет называть неточное время может быть реализованно следующим кодом:
Привер риложения которое каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+C в Windows.
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь ресурсы производительности, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры.
# Упражнения tkinter
- Напишите программу часы, которая показывает текущее время и имеет кнорку, при нажатии на которую можно ушлышать текуще время.
- Внесите измеения с программу что бы при произненсении времени программа корректно склоняла слова: «часы» и «минуты».
- Добавьте с помощью радиокнопки выбор языка озвучки часов.
# Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
# Упражнения tkinter
- Напишите программу текстовым полем и кнопкой которая будет озвучивать написанное.
- Добавьте меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
# Модуль Google TTS — голоса из интернета
Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Для работы необходимо установить пакет:
Простейший код, который сохраняет текст на русском в аудиофайл:
После запуска этого кода в директории, где лежит скрипт, появится запись. Для воспроизведения в питоне придется использовать pygame или pyglet.
Источник



