- синтезаторы речи с русскими голосами
- Список синтезаторов речи:
- 1. Acapela
- 2. Vokalizer
- 3. RHVoice
- 4. ESpeak
- 5. Festival
- Вместо послесловия
- Программные продукты синтеза речи TTS (Text-To-Speech)
- Infovox 4
- Приложения для разработчиков
- Приложения для создания звуковых файлов
- Скачать Речка (голосовой синтезатор речи) v.2.49 для Windows
- Как сделать говорящую программу на Python самостоятельно?
- Готовим поляну
- Библиотека pyttsx3
- Как озвучить системное время в Windows и Linux
- Обертка для eSpeak NG
- Управляем речью через Speech Dispatcher в Linux
- Модуль Google TTS — голоса из интернета
- Выводим текст через NVDA
- Заключение
- Готовим поляну
- Библиотека pyttsx3
- Как озвучить системное время в Windows и Linux
- Обертка для eSpeak NG
- Управляем речью через Speech Dispatcher в Linux
- Модуль Google TTS — голоса из интернета
- Выводим текст через NVDA
- Заключение
синтезаторы речи с русскими голосами

Все чаще в повседневной жизни стали использовать синтезаторы речи. Синтезаторы речи, как становится видно уже по одному названию, осуществляют синтез речи, то есть форматируют письменный текст в устный.
Благодаря этому можно учить новые иностранные слова с правильным произношением, читать книги не отвлекаясь от своих дел или озвучить текст презентации реалистичными голосами. Изначально разработкой таких программ занимались организации, специализирующиеся на технике для людей с проблемами зрения.
Сейчас же, любой пользователь может скачать одну из программ, установить ее на свой компьютер или телефон и синтезировать речь, в том числе и русскую.
Для этого было разработано множество различных программ, приложенный и даже целых систем. К сожалению, не все из них предназначены для русскоязычной аудитории.
Список синтезаторов речи:
1. Acapela
Acapela — один из самых распространенных речевых синтезаторов во всем мире. Программа распознает и озвучивает тексты более, чем на тридцати языках. Русский язык поддерживается двумя голосами: мужской голос — Николай, женский — Алена.
Женский голос появился значительно позднее мужского и является более усовершенствованным.
Прослушать, как звучат голоса, можно на официальном сайте программы. Достаточно лишь выбрать язык и голос, и набрать свой небольшой текст.
Кстати, для мужского голоса был разработан отдельный словарь ударений, что позволяет достичь еще большей четкости произношения.
Установка программы проходит без проблем. Разработаны версии для операционных систем Windows, Linux, Mac, а также для мобильных ОС Android u IOS.
Программа платная, скачать ее можно с официального сайта Acapela.
2. Vokalizer
Вторым в нашем списке, но не по популярности является движок Милена от разработчика программы Vocalizer компании Nuance.
Голос звучит очень естественно, речь чистая. Есть возможность установить различные словари, а также подкорректировать громкость, скорость и ударение, что не маловажно.
Как и в случае с Акапелой, программа имеет различные версии для мобильных, автомобильных и компьютерных приложений. Прекрасно подходит для чтения книг.
Скачать все версии Vokalizer и русскоязычный движок Милена можно на официальном сайте производителя программы.
3. RHVoice
Синтезатор речи RHVoice был разработан Ольгой Яковлевой. Программа озвучивает русские тексты тремя голосами: Елена, Ирина и Александр. Подробнее об установке и применении, а также прослушать голоса Вы сможете в прошлой статье
Код синтезатора открыт для всех, программы же абсолютно бесплатны.
RHVoice выпущена в двух вариантах: как отдельная программа, так и как приложение к NVDA.
Все версии можно скачать с официального сайта разработчика.
4. ESpeak
Первая версия бесплатного синтезатора речи eSpeak была выпущена в 2006 году. С тех пор компания-разработчик постоянно выпускает все более усовершенствованные версии. Последняя версия была представлена в конце весны две тысячи тринадцатого года.
eSpeak можно установить под следующие операционные системы:
Возможна также компиляция кода для Windows Mobile, но делать ее придется самостоятельно.
А вот с мобильной ОС Android программа работает без проблем, хотя русские словари еще не до конца разработаны. Русскоязычных голосов много, можно выбрать на свой вкус.
Для разработчиков будет интересно узнать, что C++ код программы доступен в сети. Скачать программу, а также посмотреть ее код можно на официальном сайте.
5. Festival
Festival — это целая система распознавания и синтеза речи, которая была разработана в эдинбургском университете.
Программы и все модули абсолютно бесплатно и распространяются по системе open source. Скачать их и ознакомиться с демо-версиями можно на официальном сайте университета Эдинбурга.
Русский голос представлен в одном варианте, но звучание довольно хорошее и ясное, без акцента и с правильной расстановкой ударений.
К сожалению, программа пока может быть установлена только в среде API, Linux. Также есть модуль для работы в Mac OS, но русский язык пока поддерживается не очень хорошо.
Вместо послесловия
Стоит отметить, что любой из вышеприведённых синтезаторов отлично исполнен, но выбор программы индивидуален. Всё объясняется различным произношением голосов. Смею посоветовать второй вариант с голосом Милена. ОЧень выразительный голос, насыщенное звучание и приятная во всех смыслах интонация голоса!
Программные продукты синтеза речи
TTS (Text-To-Speech)
Данная категория программных продуктов, разработанных компанией Acapela Group поможет Вам преобразовать текст в речь, использовать синтез речи при разработке ваших приложений, создавать звуковые файлы на основе текстовых и многое другое.
Infovox 4
Infovox 4 — это голос, который заставит ваш компьютер говорить и сделает вашу жизнь проще. Infovox 4 прочитает вслух для Вас любой текст четким и приятным голосом на вашем родном языке.
Infovox 4 представляет собой программный продукт, который говорит на многих языках и предоставляет несколько голосов для каждого языка. Данное программное обеспечение позволяет адаптировать голоса, помня ваши любимые настройки, а также предоставляет вам простой способ настроить произношение слов и аббревиатур, как вы того желаете.
Основные возможности программы:
- Для каждого языка доступны две версии голосов преобразования текста в речь: голоса высокого качества High Quality (HQ) для обычного, приятного чтения и Colibri голоса с улучшенной разборчивостью речи на высокой скорости чтения.
- Доступно 62 голоса на 26 языках.
- Поддержка SAPI4 и SAPI5 интерфейсов обеспечивает интеграцию со многими программами экранного доступа. Такими как Jaws, ZoomText, Doplhin Hal и Supernova, Window-Eyes, Cobra компании BAUM и многими другими приложениями с доступной речевой функцией.
- Три локальных установки (независимых от наличия USB-ключа).
- Возможность использования infovox4 USB в дополнение к 3 локальным установкам, как портативное решение для персональных компьютеров, где не установлена программа экранного доступа.
- Локальные установки производятся непосредственно с USB-ключа.
- Возможность переноса лицензий локальных установок на USB-ключ и обратно в любое время.
- Меню на основе графического интерфейса облегчает навигацию при помощи программы экранного чтения.
- Возможность регулировки темпа речи, высоты тона (только для Colibri голосов), длительности пауз и настройки эквалайзера для каждого голоса.
- 3 доступных режима чтения: непрерывный, по словам и по буквам.
- Полная поддержка 32 и 64 битных программ экранного доступа и прочих приложений с доступной речевой функцией.
- Infovox 4 работает под управлением OС: Windows XP, Windows Vista, Windows7 и Windows8, с полной поддержкой 32 и 64 битных версий Windows.
Infovox4 включает в себя несколько полнофункциональных приложений:
- NVDA Reader на USB-ключе поможет пользователю моментально получить доступ к любому компьютеру, без необходимости установки и получения прав администратора.
- Speech Creator (Создатель речи) позволяет легко создавать файлы MP3 для личного пользования, из любого текстового файла.
- Voice Manager (Менеджер управления голосами) позволяет создавать новые голоса с персональными настройками, в том числе и на базе имеющихся голосов.
- Download Manager (Менеджер загрузки) позволяет в любое время локально добавлять и удалять голоса, включённые в лицензию.
- Pronunciation Editor (Редактор произношения) позволяет легко управлять словарями, добавлять исключения, служит для тонкой настройки произношения любых слов, акронимов, имен и т.п.
- Также доступна функция обновления, благодаря чему продукт всегда находится в актуальном состоянии.
Приложения для разработчиков
Разработчики приложений для ПК под Windows и Mac OS смогут интегрировать преобразование текста в речь при помощи соответствующих приложений Acapela TTS для Windows и Mac OS.
В разработке приложений для мобильных устройств поможет продукт Acapela TTS для Windows Mobile, Linux, Symbian, iPhone и iPad , а также Android .
Для разработчиков телекоммуникационных и сервисных приложений мы представляем продукты компании Acapela TTS для Windows Server и Linux Server
Если необходимо, чтобы ваше веб-приложение было озвучено, онлайн сервис Voice as a Service поможет вам в этом. Программный интерфейс приложения позволит настроить и контролировать параметры и настройки создания звука. Сервис доступен 7 дней в неделю 24 часа в сутки!
Приложения для создания звуковых файлов
Acapela box
Новейший сервис от компании Acapela, разработанный для создания звуковых файлов по запросу в режиме онлайн. Пользователь платит в зависимости от пользования сервисом и может использовать звуковые файлы по своему усмотрению, все права включены.
Virtual Speaker
Этот инструмент предназначен для профессионалов, которым необходимы функции контроля речи, вывода звука в разных форматах и т.п. Virtual Speaker — это также диктор, который никогда не подхватит простуды, всегда доступен и последователен. Данный продукт подходит тем, кому необходимо получить в результате работы большой объем звуковых файлов.
Acapela Kiosk
Acapela Kiosk новый онлайн-сервис, предназначенный для издателей периодической литературы, которые при помощи данного сервиса могут свое бумажное издание преобразовать в цифровое, получив при этом массу преимуществ, увеличив количество своих читателей и получив в помощь все новейшие цифровые технологии передачи информации.
Acapela Voice Factory
Если вашей компании требуется собственный бренд-голос, или вы хотите, чтобы ваше приложение звучало как никакое другое, то решением этого будет продукт Acapela Voice Factory.
Скачать Речка (голосовой синтезатор речи) v.2.49 для Windows
Программа РЕЧКА для синтеза речи и создания аудиокниг переводит текст в речь, а так же обратно речь в текст. Читает любой текст вслух для вас вместо вас. Можно читать с закрытыми глазами.
Начинает работать сразу после установки, не требуя установки дополнительных программ c голосовыми движками. Хотя, если на компьютере установлен такой, его так же можно использовать для озвучивания текста.
По умолчанию используется сервис от компании Яндекс SpeechKit TTS и STT, обладающий несколькими мужскими и женскими голосами очень похожими на настоящие голоса людей. Единственное требование для этого соединение с интернет.
Возможен режим автоматического чтения текста, скопированного в буфер. Например в любом текстовом редакторе или браузере выделяется и копируется текст, и программа «Речка» сразу начинает читать его вслух.
Можно создавать аудиокниги с диалогами, используя разные голоса устанавливая в тексте маркеры голоса в нужном месте.
В программе имеется встроенный и свой личный пополняемый словарь ударений. Благодаря этим словарям, речь произносится более правильно и воспринимается лучше.
При регистрации в Яндекс.Облаке возможно обратное преобразование речи в текст STT (SpeechToText) отдельных звуковых файлов или сразу с микрофона. Но распознавание речи, конечно пока желает лучшего
Школьникам, студентам и всем познающим мир позволит не бояться больших и толстых книг, а с легкостью освоить любой материал и узнать много нового.
Как сделать говорящую программу на Python самостоятельно?

Синтез речи может пригодиться вам в работе над мобильным помощником, умным домом на Raspberry Pi, искусственным интеллектом, игрой, системой уведомлений и звуковым интерфейсом. Голосовые сообщения донесут информацию до пользователя, которому некогда читать текст. Кроме того, если программа умеет озвучивать свой интерфейс, она доступна незрячим и слабовидящим. Есть системы управления компьютером без опоры на зрение. Одна из самых популярных — NVDA (NonVisual Desktop Access) — написана на Python с добавлением C++.
Давайте посмотрим, как использовать text-to-speech (TTS) в Python и подключать синтезаторы голоса к вашей программе. Эту статью я хотела назвать «Говорящая консоль», потому что мы будем писать консольное приложение для Windows, Linux, а потенциально — и MacOS. Потом решила выбрать более общее название, ведь от наличия GUI суть не меняется. На всякий случай поясню: консоль в данном случае — терминал Linux или знакомая пользователям Windows командная строка.
Цель выберем очень скромную: создадим приложение, которое будет каждую минуту озвучивать текущее системное время.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
- голосовой движок (синтезатор речи) с поддержкой нужных нам языков,
- голоса дикторов для этого движка.
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:
- RHVoice от Ольги Яковлевой — имеет четыре голоса для русского языка (один мужской и три женских), а также поддерживает татарский, украинский, грузинский, киргизский, эсперанто и английский. Работает в Windows, GNU/Linux и Android.
- eSpeak и его ответвление — eSpeak NG — c поддержкой более 100 языков и диалектов, включая даже латынь. NG означает New Generation — «новое поколение». Эта версия разрабатывается сообществом с тех пор, как автор оригинальной eSpeak перестал выходить на связь. Система озвучит ваш текст в Windows, Android, Linux, Mac, BSD. При этом старый eSpeak стабилен в ОС Windows 7 и XP, а eSpeak NG совместим с Windows 8 и 10.

В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64. » или еще что-то. Если не уверены, воспользуйтесь поиском:
find /usr/lib/ -name «espeak-data»
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.

Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
espeak -v ru -f D:\my.txt
espeak-ng -v en «The Cranes are Flying»
echo «Да, это от души. Замечательно. Достойно восхищения» |RHVoice-test -p Aleksandr
Как нетрудно догадаться, первая команда с ключом -f читает русский текст из файла. Чтобы в Windows команда espeak подхватывалась вне зависимости от того, в какой вы директории, добавьте путь к консольной версии eSpeak (по умолчанию — C:\Program Files\eSpeak\command_line) в переменную окружения Path. Вот как это сделать.
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
А теперь примеры!
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
Результат будет примерно таким:
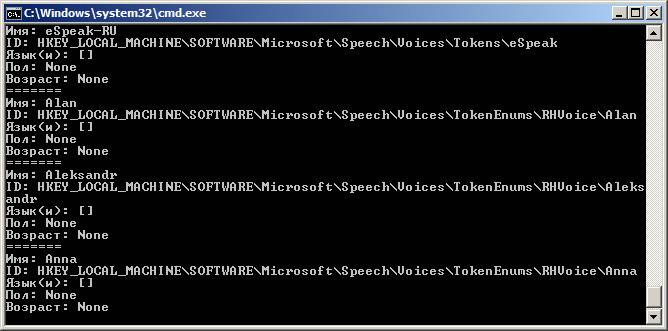
В Linux картина будет похожей, но с другими идентификаторами.
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
# Задать голос по умолчанию
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait().
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoice\Anna’) # Найти Анну от RHVoice
if ru > -1: # Eсли нашли, выбираем этот голос
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС. Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
# Использовать английский голос
tts.say(«Can you hear me say it’s a lovely day?»)
tts.say(«А напоследок я скажу»)
Как озвучить системное время в Windows и Linux

Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
for voice in voices:
if voice.name == ‘Aleksandr’:
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь оперативную память, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры. А пока посмотрим на другие инструменты.
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку. В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
Ура! Наконец-то наше Linux-приложение говорит голосом, похожим на человеческий. Обратите внимание на метод .set_output_module() — он позволяет выбрать любой установленный движок, будь то espeak, rhvoice или festival. После этого синтезатор прочтет текст голосом, предписанным для данного движка по умолчанию. Если задан только язык — голосом по умолчанию для данного языка.
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета

Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Выводим текст через NVDA

Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
elif bit[0] == ’64bit’:
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
Теперь эту заготовку можно применить в коде основной программы:
# … другие реплики или сон
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.
Заключение
Ваша программа уже глаголет устами хотя бы одного из установленных синтезаторов? Поздравляю! Как видите, это не слишком сложно и «в выигрыше даже начинающий». Еще больше радуют перспективы использования TTS в ваших проектах. Все, что можно вывести как текст, можно и озвучить.
Представьте утилиту, которая при внезапной проблеме с экраном телефона или монитора сориентирует пользователя по речевым подсказкам, поможет спокойно сохранить данные и штатно завершить работу. Или как насчет прослушивания входящей почты, когда вы не за монитором? Напишите, когда, на ваш взгляд, TTS полезна, а когда только раздражает. Говорящая программа с какими функциями пригодилась бы вам?
Синтез речи может пригодиться вам в работе над мобильным помощником, умным домом на Raspberry Pi, искусственным интеллектом, игрой, системой уведомлений и звуковым интерфейсом. Голосовые сообщения донесут информацию до пользователя, которому некогда читать текст. Кроме того, если программа умеет озвучивать свой интерфейс, она доступна незрячим и слабовидящим. Есть системы управления компьютером без опоры на зрение. Одна из самых популярных — NVDA (NonVisual Desktop Access) — написана на Python с добавлением C++.
Давайте посмотрим, как использовать text-to-speech (TTS) в Python и подключать синтезаторы голоса к вашей программе. Эту статью я хотела назвать «Говорящая консоль», потому что мы будем писать консольное приложение для Windows, Linux, а потенциально — и MacOS. Потом решила выбрать более общее название, ведь от наличия GUI суть не меняется. На всякий случай поясню: консоль в данном случае — терминал Linux или знакомая пользователям Windows командная строка.
Цель выберем очень скромную: создадим приложение, которое будет каждую минуту озвучивать текущее системное время.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
- голосовой движок (синтезатор речи) с поддержкой нужных нам языков,
- голоса дикторов для этого движка.
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:
- RHVoice от Ольги Яковлевой — имеет четыре голоса для русского языка (один мужской и три женских), а также поддерживает татарский, украинский, грузинский, киргизский, эсперанто и английский. Работает в Windows, GNU/Linux и Android.
- eSpeak и его ответвление — eSpeak NG — c поддержкой более 100 языков и диалектов, включая даже латынь. NG означает New Generation — «новое поколение». Эта версия разрабатывается сообществом с тех пор, как автор оригинальной eSpeak перестал выходить на связь. Система озвучит ваш текст в Windows, Android, Linux, Mac, BSD. При этом старый eSpeak стабилен в ОС Windows 7 и XP, а eSpeak NG совместим с Windows 8 и 10.
В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64. » или еще что-то. Если не уверены, воспользуйтесь поиском:
find /usr/lib/ -name «espeak-data»
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.
Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
espeak -v ru -f D:\my.txt
espeak-ng -v en «The Cranes are Flying»
echo «Да, это от души. Замечательно. Достойно восхищения» |RHVoice-test -p Aleksandr
Как нетрудно догадаться, первая команда с ключом -f читает русский текст из файла. Чтобы в Windows команда espeak подхватывалась вне зависимости от того, в какой вы директории, добавьте путь к консольной версии eSpeak (по умолчанию — C:\Program Files\eSpeak\command_line) в переменную окружения Path. Вот как это сделать.
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
А теперь примеры!
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
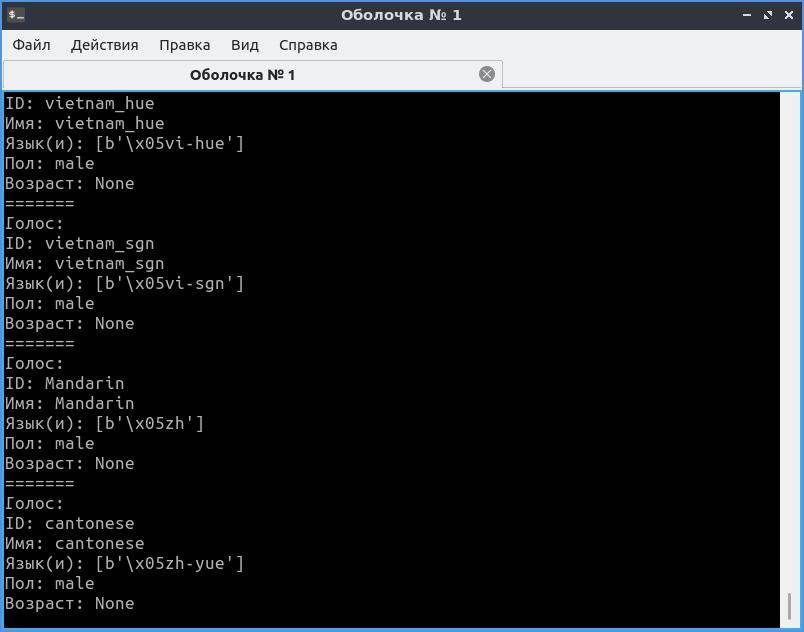
Результат будет примерно таким:
В Linux картина будет похожей, но с другими идентификаторами.
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
# Задать голос по умолчанию
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait().
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoice\Anna’) # Найти Анну от RHVoice
if ru > -1: # Eсли нашли, выбираем этот голос
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС. Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
# Использовать английский голос
tts.say(«Can you hear me say it’s a lovely day?»)
tts.say(«А напоследок я скажу»)
Как озвучить системное время в Windows и Linux
Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
for voice in voices:
if voice.name == ‘Aleksandr’:
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь оперативную память, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры. А пока посмотрим на другие инструменты.
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку. В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
Ура! Наконец-то наше Linux-приложение говорит голосом, похожим на человеческий. Обратите внимание на метод .set_output_module() — он позволяет выбрать любой установленный движок, будь то espeak, rhvoice или festival. После этого синтезатор прочтет текст голосом, предписанным для данного движка по умолчанию. Если задан только язык — голосом по умолчанию для данного языка.
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета
Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Выводим текст через NVDA
Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
elif bit[0] == ’64bit’:
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
Теперь эту заготовку можно применить в коде основной программы:
# … другие реплики или сон
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.
Заключение
Ваша программа уже глаголет устами хотя бы одного из установленных синтезаторов? Поздравляю! Как видите, это не слишком сложно и «в выигрыше даже начинающий». Еще больше радуют перспективы использования TTS в ваших проектах. Все, что можно вывести как текст, можно и озвучить.
Представьте утилиту, которая при внезапной проблеме с экраном телефона или монитора сориентирует пользователя по речевым подсказкам, поможет спокойно сохранить данные и штатно завершить работу. Или как насчет прослушивания входящей почты, когда вы не за монитором? Напишите, когда, на ваш взгляд, TTS полезна, а когда только раздражает. Говорящая программа с какими функциями пригодилась бы вам?



