- Средства системного администратора Linux
- Средства системного администратора Linux
- Администрирование
- Мониторинг
- Централизованное управление пакетами
- Логирование
- Резервное копирование
- Постскриптум
- Блог начинающего сисадмина
- воскресенье, 4 марта 2018 г.
- Что должен знать новичок для работы системным администратором Linux
Средства системного администратора Linux
Средства системного администратора Linux
Совсем недавно (5-8 лет назад) системный администратор Linux был ограничен в средствах администрирования и автоматизации. Где-то можно было обойтись самописными скриптами на bash, Python, Perl, а где-то уже требовалось решение уровня энтерпрайз от таких гигантов, как IBM, Oracle или RedHat.
С развитием Open Source стала развиваться и автоматизация в администрировании. На замену самописным скриптам и программам пришли готовые решения. Эти средства появились не на пустом месте. Это были решения по автоматизации существующих задач любого системного администратора. Зачастую это решения, развиваемые по принципу KISS (акроним для «Keep it simple, stupid»), которые получали большие перспективы развития и распространения.
Конечно, лет 5-10 назад средства централизованного администрирования в Windows были развиты лучше, чем в Linux. Это было небезосновательно, т.к. Windows был широко распространён как среди домашних пользователей, так и в офисной/серверной среде. Microsoft, похоже, не предполагала что когда-то будет соперничать с Linux в серверном сегменте. Но не будем здесь углубляться в эти застойные времена для Microsoft, когда главой корпорации был Стив Балмер.
Администрирование
Одним из часто используемых средств администрирования мною и коллегами до появления ansible/puppet/chef был cssh (Cluster SSH).
Cluster SSH в работе
Работа с cssh была проста, не нужно было повторять одни и те же действия на каждом сервере по очереди, всё сводилось к мультиплексированию ввода в терминале на группу SSH подключений. У этого решения, конечно, были очевидные недостатки — необходимо было взаимодействие с администратором, его контроль. Сегодня средства автоматизации ушли намного дальше в своих возможностях и функциональности и зачастую расширяются плагинами.
13 сентября – 9 октября, Санкт-Петербург и онлайн, Беcплатно
Одно из наиболее распространённых средств автоматизации в администрировании — Ansible. Оно позволяет автоматизировать практически любые задачи системного администратора. Для работы достаточно SSH доступа к хостам. На сайте есть обзорная статья про Ansible, как его настроить и работать. Проект развивался независимо и вскоре был куплен компанией RedHat.
Мониторинг
После настройки сервера и введения его в эксплуатацию для обеспечения SLA и не только необходимо уделить внимание мониторингу.
Мы часто разделяем мониторинг на два отдельных компонента:
- мониторинг с оповещениями,
- статистика по показателям.
Нет необходимости настраивать предупреждения по всем показателям в системе, но собирать показатели системы для статистики и дальнейшего выявлений аномалий — полезно и удобно.
- Zabbix/Nagios/Icinga — используем для получения событий агентами и уведомлений по триггерам.
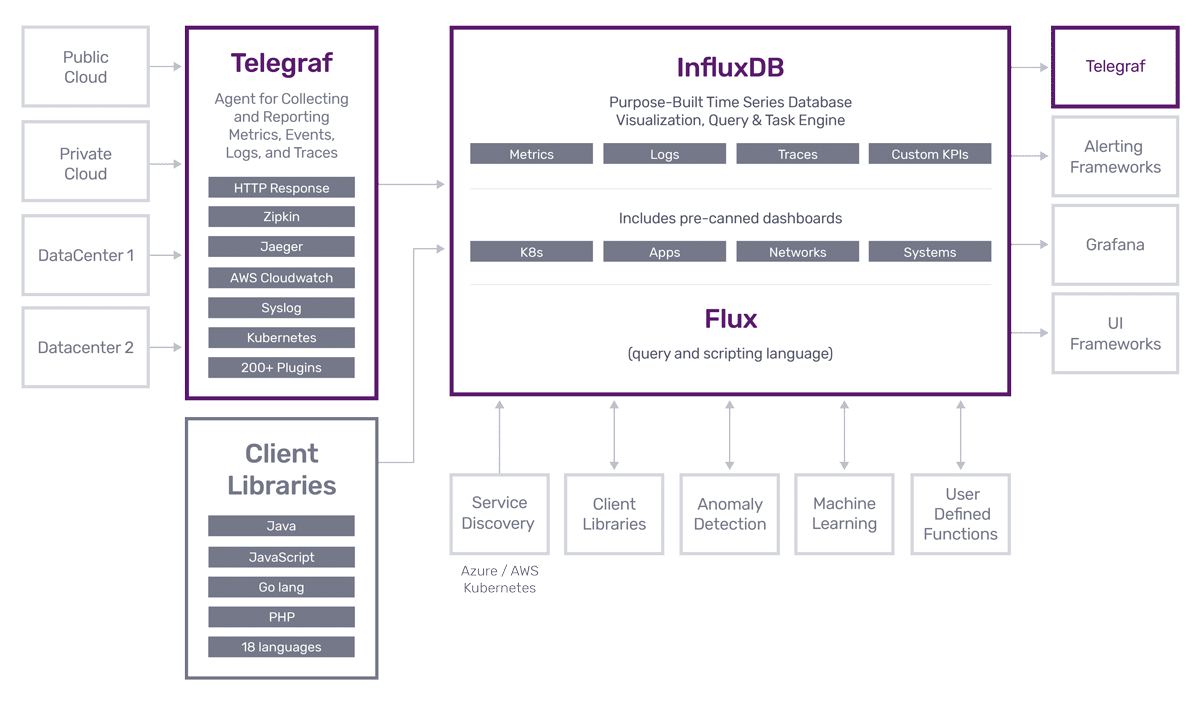
- Grafana + InfluxDB — в эту связку входят также Chronograf, Kapacitor, Telegraf.
-
- InfluxDB — time series база данных, принимает на вход данные с различных источников. Имеет широкий функционал возможностей для работы с данными.
- Chronograf — веб-панель с дашбордами и система управления Influxdb, Kapacitor.
- Kapacitor — обработчик событий.
- Telegraf — агент, отправляет данные с удалённых систем.
- Grafana — всем известная система построения дашбордов/графиков.
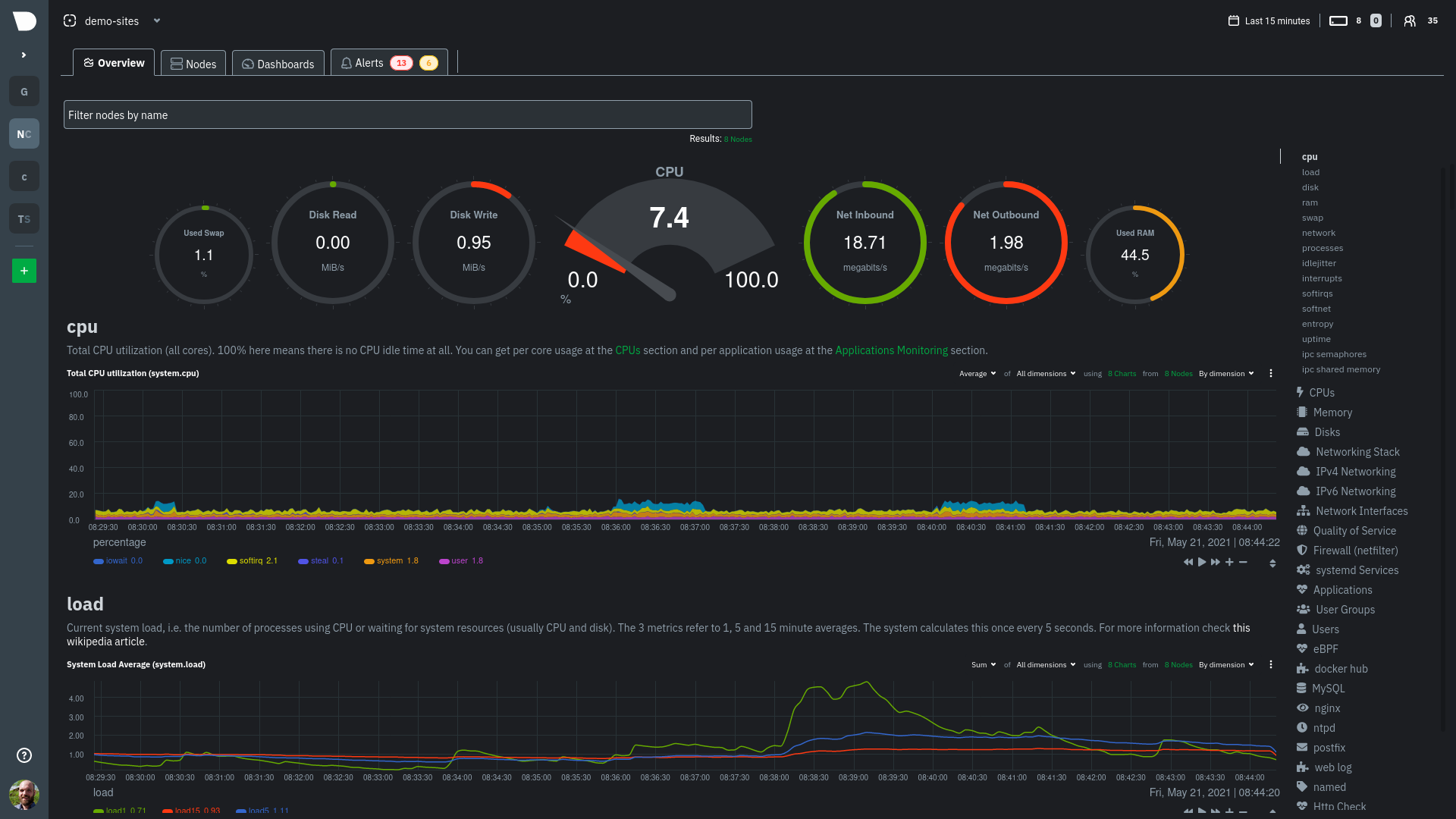
Также в категории мониторинга стоит обратить внимание на Netdata. Это одновременно и агент, и система мониторинга в реальном времени с дашбордом для просмотра статистики, предварительно настроенными графиками и триггерами. После установки остаётся настроить лишь способы оповещений с указанием канала передачи.
Netdata — это «швейцарский нож» в системе мониторинга, обладает широкой функциональностью, поддержкой модулей на Python, Go и не только.
Централизованное управление пакетами
В качестве централизованного управления набором ПО и его обновлениями мы использовали RedHat Spacewalk.
Интерфейс RedHat Spacewalk
С выходом RHEL 7 RedHat провели обновление, вследствие чего заменили Spacewalk на RedHat Satellite, который во многом напоминает Foreman. Для перехода на RedHat Satellite необходимо было бы перенастраивать уже работающие с RedHat Spacewalk системы, отлаживать новое решение (RedHat Satellite) и почти гарантированно бороться с новыми проблемами.
Зачастую в госструктурах и энтерпрайзе широко использовались решения RedHat. И тут со второго плана выходит компания Oracle, которая занималась развитием дистрибутивов Oracle Enterprise Linux/Oracle Unbreakable Enterprise Kernel.
Это продукты, основанные на кодовой базе RedHat Enterprise Linux, но с большим количеством доработок под собственные нужды, в которые том числе входило создание и поддержка среды для, наверное, основного продукта компании Oracle — Oracle Databases.
Но, в отличие от RedHat, дистрибутив которого скачать можно было только по подписке (лицензировании), не говоря уже об обновлениях, Oracle предоставляет это бесплатно. Именно Oracle взялся поддерживать и продолжать развитие Oracle Spacewalk, который вскоре был обновлён в Oracle Linux Manager.
Логирование
С увеличением количества обслуживаемых хостов возникает необходимость централизованного сбор логов. Для этих задач отлично подходят уже готовые Open Source решения, которые мы используем:
Агенты — rsyslog, syslog-ng (доступны в большинстве дистрибутивов)
При небольшом количестве администрируемых хостов можно обойтись syslog-ng как централизованным хранилищем для файлов логов, который будет принимать сообщения на 514 UDP порт. Он умеет раскладывать сообщения по директориям в зависимости от источника (FQDN/IP-адреса), сервиса, дате и прочее.
Резервное копирование
Для резервного копирования выбор достаточно прост. Где-то достаточно rsync + tar (синхронизации и сжатия), а где-то требуется Bacula/Bareos.
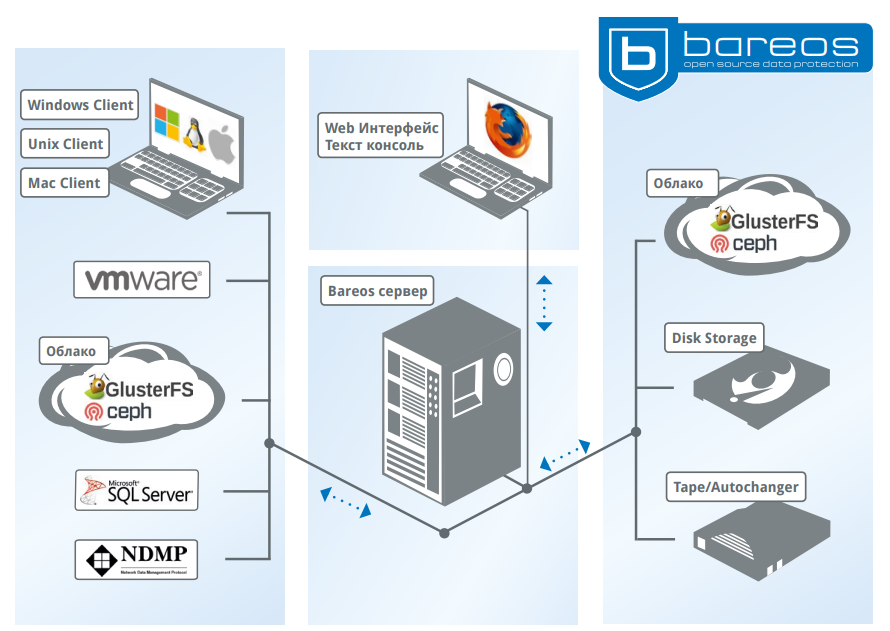
В резервном копировании есть достаточно хорошие проприетарные решения, например, «Veeam backup». Если вы используете виртуализацию VMWare, то здесь Veeam упрощает резервное копирование и предоставляет поддержку.
Также в своих решениях мы используем резервное копирование для /etc директории — etckeeper. Он позволяет автоматизировать сохранение содержимого каталога /etc в хранилище системы контроля версий (VCS), отслеживает, когда ваш пакетный менеджер сохраняет изменения в /etc при установке или обновлении пакетов.
Помещение /etc под контроль версий сейчас рассматривается как лучшая практика в индустрии. Преимуществом etckeeper является то, что он делает этот процесс безболезненным, насколько это возможно, и удобным. При наличии незакоммиченных изменений etckeeper будет ежедневно их сохранять, если это не отключено, и отправлять в централизованный репозиторий.
Иногда случается так, что подготовленный к установке/обновлению пакет программ может перезаписать существующие файлы в /etc , т.к. некоторые заказчики пользуются сторонними службами/пакетами. Etckeeper умеет фиксировать конфигурацию перед установкой пакетов и после, что значительно облегчает работу.
Постскриптум
Выбор любого инструмента зависит от поставленных задач. Если для своих задач вы не нашли готового решения, всегда можно взяться за его реализацию самостоятельно. Обязательно найдутся те, кто вас поддержит и присоединится к развитию вашего решения. Возможно, именно оно будет решать задачи лучше других.
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
Источник
Блог начинающего сисадмина
Здесь уже не будет ничего интересного, лучше загляните сюда: https://medium.com/@Amet13
воскресенье, 4 марта 2018 г.
Что должен знать новичок для работы системным администратором Linux
Прежде всего, системный администратор должен отлично разбираться в операционной системе которую он администрирует. Администратор должен понимать все плюсы и минусы используемой системы, различия в дистрибутивах, используемых интерпретаторов по умолчанию, предустановленном программном обеспечении, управлении системными сервисами, системой инициализации, системой управления пакетами, версиях программного обеспечения в репозиториях, расположении конфигурационных файлов и особенностях настройки дистрибутива.
Например при переходе с Debian-based дистрибутивов на RHEL-based может быть непривычно то, что cron пишет в отдельный лог /var/log/cron , а не в /var/log/syslog , а для определения версии дистрибутива вместо /etc/lsb-release используется файл /etc/redhat-release . Или например при переходе Ubuntu с системы инициализации Upstart на Systemd могут возникнуть некоторые сложности при управлении сервисами, хоть Ubuntu и сохранили обратную совместимость со скриптами Upstart.
Для администрирования сети необходимы базовые понятия работы сетей, как настраивается сетевое соединение в Linux, что такое модель OSI, как работает IP-адресация,в чем отличия протоколов TCP, UDP, ICMP и прочих,как работают утилиты ping, traceroute, как устроен интернет, что такое динамическая маршрутизация и для чего нужен DNS.
Для того чтобы вовремя реагировать на инциденты, возникающие в серверной инфраструктуре необходимо иметь систему мониторинга. Пример таких систем Cacti, Nagios, Munin, Zabbix и многие другие. Мониторинг позволит не только в кратчайшие сроки среагировать на возникшую проблему, но и хранить историю инцидентов, анализировать периодичность возникновения проблем, строить графики для более удобного восприятия человеком.
Для решения возникающих инцидентов необходимо обладать навыками траблшутинга.
В первую очередь важно уметь работать с логами, фильтровать нужную информацию из логов, для этого часто используются утилиты cat , tail , awk , cut , grep , sort , wc и прочие.
Пример подсчета количества ошибок в логе Nginx:
# awk ‘
66192
Также необходимо позаботиться о ротации логов, для уменьшения занятого пространства старыми логами.
Такие инструменты как lsof и strace помогут понять какие файлы и соединения использует работающий процесс, а также какие системные вызовы он совершает.
tcpdump , tshark , iperf , mitmproxy , nmap и прочие инструменты помогут для анализа работы сбоев в сети.
Системные администраторы делятся на два вида, те кто еще не делает резервные копии и те кто уже делает их. Резервные копии нужны для быстрого восстановления потерянной информации.
Два параметра RPO (Recovery Point Objective) и RTO (Recovery Time Objective) определяют время актуальности резервных копий и время необходимое на восстановление копий соответственно.
Необходимо понимать отличия полного резервного копирования, при котором каждый раз копируются все файлы, от дифференциального, и при котором копируются только измененные файлы, и инкрементального, при котором копируются только те файлы, которые изменились с последнего полного или добавочного резервного копирования.
Рекомендуется хранить резервные копии в нескольких местах, в той же стойке где работает сервер, в отдельной стойке от сервера и в другом ЦОДе.
Важно также проверять консистентность резервных копий, обычно для этого используют тестовые стенды.
Существует множество инструментов для создания резервных копий, среди которых можно выделить Bareos, duplicity, rsync. Множество системных администраторов используют свои инструменты в виде скриптов для созданий резервных копий на основе rsync , tar , gzip .
Администратор должен понимать что такое RAID, LVM и как они работают, даже если ему не приходится использовать подобное. Рано или поздно он скорее всего столкнется с RAID при работе с физическими серверами и важно понимать как он работает, так как при неверной конфигурации и замене диска в RAID-массиве возможна полная потеря данных. Также при работе с физическими серверами будет полезно понимание работы IPMI, IP KVM.
Системный администратор должен знать хотя бы один из скриптовых языков программирования (Shell/BASH, Python, Perl, Ruby). Хороший системный администратор не делает одни и те же вещи больше трех раз, скорее всего он уже автоматизировал рутинную работу скриптом.
Отличное знание повседневных инструментов системного администратора значительно упрощает жизнь, единожды настроив конфигурационный файл текстового редактора vim и выучив все внутренние команды текстового редактора позволяет ускорить работу в значительной степени. Использование алиасов, для часто повторяющихся команд, например git add , git commit можно легко заменить на ga и gc .
При управлении парком серверов значительно упрощают жизнь системы управления конфигурациями, такие как Chef, Ansible, SaltStack, Puppet и другие.
Подобные системы позволяют централизованно управлять конфигурациями операционных систем и сервисов установленных на разных серверах. Для этого используются различные конфигурационные файлы именуемые в Puppet cookbook, в Chef — рецептами, а Ansible — playbook. Как правило, подобные конфигурационные файлы представляют собой список команд описанных в синтаксисе YAML или на прочих декларативных языках.
Большое количество модулей позволяет управлять практически любым процессом на сервере, а некоторые системы, такие как Ansible, позволяют управлять удаленными серверами без запуска агентов, исключительно с использованием SSH-соединения.
Для хранения данных приложений используются различные системы управления базами данных. Важно понимать, в чем состоит отличие MySQL от его форков MariaDB и Percona Server. Когда стоит использовать для проекта MySQL, а когда PostgreSQL. Чем отличаются реляционные базы данных от документо-ориентированных (MongoDB, CouchDB), key-value хранилищ (Redis, MemcacheDB) и прочих. Базовые знания SQL-запросов также не помешают.
Рано или поздно системный администратор сталкивается с протоколом LDAP (Lightweight Directory Access Protocol). LDAP используется для централизованного хранения данных о пользователях, таким образом возможно синхронизировать все сервера для поиска информации о пользователях из единого каталога LDAP.
Системному администратору хостинга необходимо понимание работы веб-серверов (Apache, Nginx), режимах работы PHP, оптимизации работы MySQL, дебаге работы скриптов. Также стоит узнать как устроены современные панели управления хостингом (Cpanel, Plesk, Webmin и прочие).
Виртуализация в последние годы все больше и больше используется на серверах. Администратор должен понимать различия в системах виртуализации, чем отличается эмуляция оборудования (QEMU) от полной виртуализации (KVM, Hyper-V), паравиртуализации (Xen) и контейнерной виртуализации (LXC, OpenVZ).
Системный администратор должен обезопасить свою серверную инфраструктуру, для этого необходимо знание системных инструментов обеспечения безопасности (SELinux, AppArmor), фаерволов (Iptables, firewalld, ufw), необходимо отключить, или удалить неиспользуемые сервисы и настроить фаерволл так, чтобы доступ в интернет был только у нужных портов. Необходимо проводить периодические пентестинги для проверки уязвимостей в инфраструктуре, обезопаситься от атак на отказ. Желательно отказаться от паролей в пользу ключей, так как при современных мощностях подобрать пароль к системе стало значительно легче, в случае с ключем подбор займет много лет.
Также важно уметь документировать сетевую и серверную инфраструктуру, проводить периодическую инвентаризацию, вести учет событий. Желательно использовать системы управления проектами, такие как Redmine или Jira, это упростит взаимодействие с пользователями и позволит хранить список задач в структурированном виде.
Немаловажно для системного администратора следить за собственным временем и не перетруждаться, для этого необходимо правильно выбрать средства получения уведомлений, как не отвлекаться на мелкие инциденты и прочее. В книге «Тайм-менеджмент для системных администраторов» Томаса Лимончелли (ISBN 5-93286-090-1) описаны все эти моменты, рекомендуется к прочтению каждому системному администратору.
В комментариях хотелось бы увидеть, что я пропустил или советы от опытных админов.
Источник



