- Как делать автоматические бэкапы сервера в Облачном хранилище
- Требования для выполнения примера
- Создание скрипта для резервного копирования
- Назначение переменных
- Вывод сообщений
- Сбор файлов
- Перенос файлов в объектное хранилище
- Настройка управления потоком
- Пример скрипта
- Автоматизация резервного копирования с помощью Crontab
- Скрипты бэкапа файлов из Linux в облачные хранилища
- Backup данных на OneDrive изLinux CentOS
- Резервное копирования на Google Диск.
- Скрипт бекапа на Яндекс.Диск из Linux
- Элементарный Bash скрипт для резервного копирования данных
- Что должен выполнять наш скрипт?
Как делать автоматические бэкапы сервера в Облачном хранилище
Резервное копирование — важная часть управления любой IT-инфраструктурой. Потребности в резервном копировании у всех разные, а хранение резервных копий в отдельном хранилище является хорошей практикой.
Есть много различных инструментов для работы с объектными хранилищами, например:
В данной инструкции приведен пример создания скрипта, который будет регулярно запускать консольный клиент, архивировать и переносить важные данные в объектное хранилище — Облачное хранилище.
Требования для выполнения примера
В качестве консольного клиента используем S3cmd с инструментом для автоматизации crontab.
Для начала работы потребуется:
- Облачный или выделенный сервер с установленной Ubuntu версии не ниже 18.04.
- Настроенный S3cmd.
- Пользователь в Облачном хранилище, созданный согласно инструкции Создание нового пользователя.
Создание скрипта для резервного копирования
В данной инструкции рассмотрим создание базового bash-скрипта, который создает резервную копию файла или каталога с помощью tar и далее загружает эту резервную копию в Облачное хранилище с помощью утилиты командной строки s3cmd.
Откройте на своем сервере домашнюю директорию:
С помощью редактора nano создайте пустой файл, например, с именем bkupscript:
Начните писать скрипт резервного копирования в текстовом редакторе с шебанга. Шебанг — это директива интерпретатора, которая позволяет запускать скрипты или файлы данных как команды и выглядит как последовательность из двух символов: решетки и восклицательного знака. Включая шебанг в начало скрипта, мы говорим оболочке запускать команды файла в bash.
Назначение переменных
Добавьте в скрипт переменные прямо под шебангом в верхней части текстового файла:
- DATETIME содержит метку времени, которую нужно прикрепить к имени полученного файла, чтобы каждый файл, резервная копия которого хранится в пространстве, имел уникальное имя. Эта временная метка создается путем вызова команды date и форматирования вывода для отображения двух последних цифр года (% y), двух цифр месяца (% m), двух цифр дня (% d), час (% H), минуты (% M) и секунды (% S);
- SRC — это исходный путь для файла или папки, в которую мы делаем резервную копию. $1 указывает, что мы берем это значение из первого параметра, переданного скрипту;
- DST — место назначения файла. В нашем случае это имя пространства, в которое мы загружаем резервную копию. Это имя будет получено из второго параметра, переданного в скрипт, как указано в $2;
- GIVENNAME — выбранное пользователем имя для файла назначения. Результирующее имя файла будет начинаться с GIVENNAME, и к нему будет добавлено DATETIME. Это имя происходит от третьего параметра, переданного скрипту $3.
Вывод сообщений
Добавьте функцию showhelp в скрипт резервного копирования для вывода сообщений в случае сбоя работы скрипта:
Сбор файлов
Прежде чем скрипт сможет передавать что-либо в выбранное пространство, ему сначала необходимо собрать нужные файлы и объединить их в единый пакет, который мы можем загрузить. Это выполняется с помощью утилиты tar, условных операторов и функции tarandzip:
Когда вызывается инструкция if, скрипт выполняет команду tar и ожидает результата. Если команда выполнена успешно, будут выполнены строки после оператора then:
- вывод сообщения о том, что процесс tar успешно завершился;
- возвращение кода ошибки 0, чтобы часть кода, вызывающая эту функцию, знала, что все работает нормально.
Часть else этого скрипта будет выполняться только в том случае, если команда tar обнаружит ошибку при выполнении:
- вывод сообщения о том, что команда tar не выполнена;
- возвращение кода ошибки 1, что указывает на то, что что-то пошло не так.
Заканчивайте скрипт if/then/else фразой fi , что на языке bash означает, что предложение if закончилось.
Завершенная функция tarandzip будет выглядеть так:
Перенос файлов в объектное хранилище
Добавим в скрипт резервного копирования функцию передачи файла movetoSpace в выбранное пространство с помощью команды s3cmd. Используем s3cmd и переменные, которые мы объявили ранее, для создания команды, которая будет помещать файлы резервных копий в выбранное пространство:
- /bin/s3cmd вызывает s3cmd — инструмент командной строки, используемый для управления сегментами хранилища объектов;
- put используется s3cmd для загрузки данных в бакет;
- $ GIVENNAME- $ DATETIME.tar.gz — это имя резервной копии, которая будет загружена в пространство. Он состоит из четвертой и первой объявленных нами переменных, за которыми следует .tar.gz, и создается функцией tarandzip;
- s3: // $ DST ; — место, куда мы загружаем файл;
- s3: // — это схема типа URI, используемая для описания мест хранения объектов в сети, а $DST; — это третья переменная, которую мы объявили ранее.
Добавьте уведомления о том, что процесс переноса файлов начался:
Поскольку команда будет либо успешной, либо неудачной (это означает, что она либо загрузит файлы в выбранное пространство, либо нет), можно сообщить пользователям, сработала ли она, повторив одну из двух строк, содержащихся в if/then/else, например:
В целом функция movetoSpace должна выглядеть так:
Настройка управления потоком
Предполагая, что скрипт настроен правильно, он при запуске должен прочитать команду ввода, присвоить значения из нее каждой переменной, выполнить функцию tarandzip, а затем выполнить функцию movetoSpace.
Если сценарий завершится неудачно между любой из этих точек, он должен напечатать вывод нашей функции showhelp, чтобы помочь пользователям в устранении неполадок.
Мы можем упорядочить отлов ошибки, добавив в конец файла условную инструкцию if / then / else:
Первый оператор if в приведенном выше разделе проверяет, что третья переданная переменная не пуста. Это происходит следующим образом:
- [] — квадратные скобки означают, что то, что находится между ними, является тестом. В этом случае проверка заключается в том, чтобы конкретная переменная не была пустой;
- ! — в данном случае этот символ означает «нет»;
- -z — эта опция указывает на пустую строку и в сочетании с ! мы запрашиваем не пустую строку;
- $ GIVENNAME указывает, что строка, которая не должна быть пустой, является значением, присвоенным переменной $GIVENNAME. Этой переменной присваивается значение, переданное третьим параметром, при вызове скрипта из командной строки. Если мы передадим сценарию менее 3 параметров, в коде не будет третьего параметра для присвоения значения $GIVENNAME, он назначит пустую строку и этот запуск завершится ошибкой.
Пример скрипта
Завершенный скрипт выглядит следующим образом:
После проверки скрипта закройте файл сочетанием клавиш CTRL+Х и сохраните внесенные изменения клавишей Y+ENTER перед выходом из nano.
Автоматизация резервного копирования с помощью Crontab
Настройте задание cron, которое будет использовать скрипт для регулярного резервного копирования в выбранное пространство. В рамках этого примера резервное копирование будет выполняться каждую минуту.
Сделайте скрипт исполняемым:
Отредактируйте файл crontab, чтобы скрипт запускался каждую минуту:
При первом запуске команды crontab -e будет предложено выбрать редактор из списка:
Можно выбрать nano по умолчанию или любой другой текстовый редактор.
Перейдя в crontab, добавьте следующую строку внизу скрипта:
Закройте файл сочетанием клавиш CTRL+Х и сохраните внесенные изменения клавишей Y+ENTER.
Если оставить задание cron запущенным без каких-либо изменений, новый файл будет копироваться в выбранное пространство каждую минуту. Убедившись, что cron работает успешно, перенастройте crontab для резервного копирования файлов с нужным интервалом.
Источник
Скрипты бэкапа файлов из Linux в облачные хранилища
Не так давно, мы размещали статью о подключении популярных бесплатных облачных хранилищ на сервере с CentOS 7. В этой статье мы покажем, как можно использовать данные хранилища для резервного копирования данных с вашего сервера. Я использую эти скрипты для дополнительного резервного копирования файлов сайта и базы данных со своего Linux VPS сервера.
Backup данных на OneDrive изLinux CentOS
Мы будем выполнять резервное копирование сайта и базы данных, а также выполнять проверку на «возраст» бэкапа (удалять бэкапы недельной давности) и отправлять на почту отчет с полной информацией выполнения скрипта. Собственно, сам bash скрипт:
#!/bin/bash
#Копируем файлы сайта во временную директорию
rsync -avzr —progress /var/www/html/ /var/www/tmp/backup/ >> result.txt
#Выполняем дамп базы, помещаем файл дампа во временную директорию
mysqldump joomla > /var/www/tmp/backup/backup.sql
#Создаем архив временной директории
tar -cvzf backup-$(date +%y%m%d).tar.gz —absolute-names /var/www/tmp/backup/ >> result.txt
#Проверяем директорию облака на наличие старых бэкапов, если таковые есть, удаляем
find /root/OneDrive/backup/ -name «backup*.tar.gz» -mtime +7 -exec rm -f <> \; >> result.txt
#Копируем созданный ранее архив в облако
rsync -avzr —progress /root/bin/backup*.tar.gz /root/OneDrive/backup/ >> result.txt
Предварительно перед написанием статьи, я создал уже несколько бэкапов, чтобы можно было продемонстрировать, что скрипт работает корректно (удаляет старые бэкапы и закачивает новые).
Я запустил 3 раза вручную. Были созданы несколько резервных копий, после чего они все успешно были отправлены в облако:
ls -la /root/OneDrive/backup/
Проверяем облако, все три архива с резервными копиями здесь:
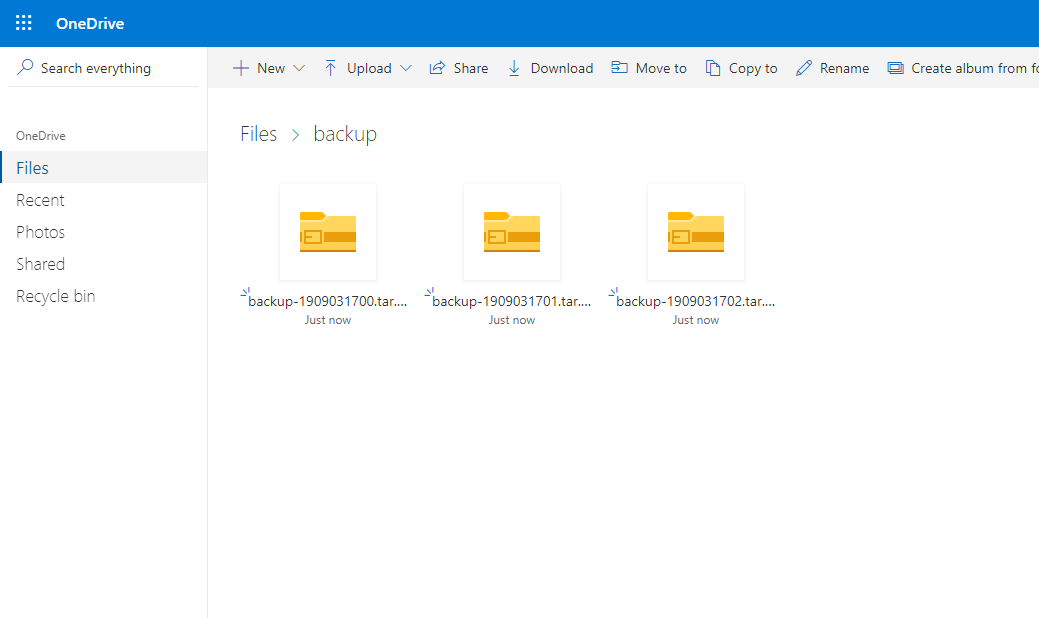
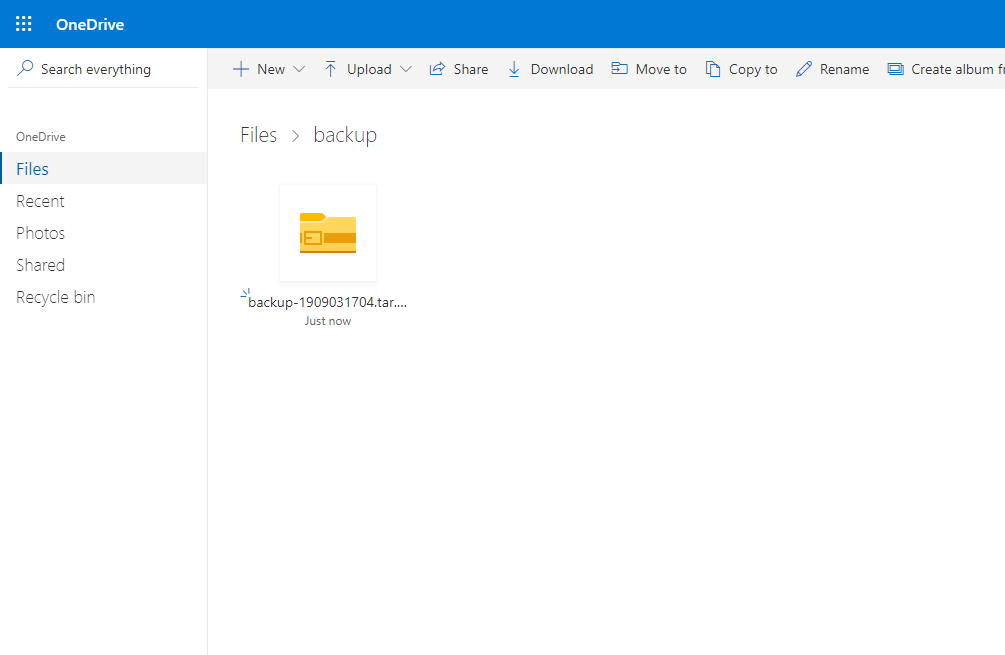
Следующим шагом, я удалил созданные резервные копии с директории на сервере и снова запустил скрипт. Вывод содержимого директории на сервере:
ls -la /root/OneDrive/backup/
Пройдя в веб-интерфейс OneDrive я увидел, что резервные копии удалили и оттуда, автоматически.
Так же после выполнения скрипта, мне пришло письмо на почту:
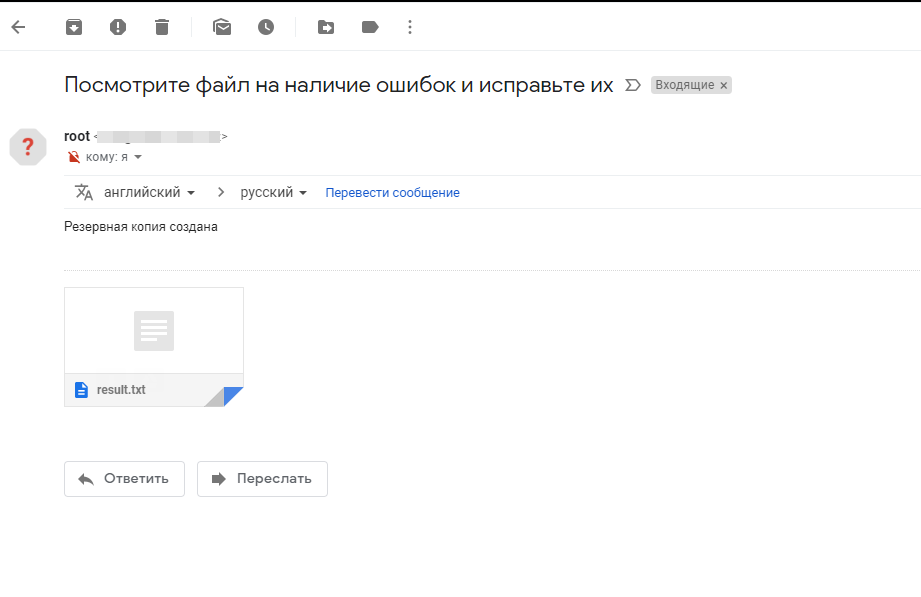 Вот и все, на этом резервное копирование на OneDrive окончено.
Вот и все, на этом резервное копирование на OneDrive окончено.
Резервное копирования на Google Диск.
С резервным копированием в Google Диск в се вышло не так просто как с OneDrive, хотя сама настройка довольно простая. Основная проблема возникла с удалением старых бэкапов с Google Drive, так как на сервер не монтируется директория хранилища. Но после долгого изучения справки drive help, удалось модернизировать наш уже ранее используемый скрипт.
#!/bin/bash
#удаляем файлы которые старше 7дней с g.drive
/usr/sbin/drive list -q «modifiedDate > result.txt
mysqldump joomla > /var/www/tmp/backup/backup.sql
tar -cvzf backup-$(date +%Y%m%d).tar.gz —absolute-names /var/www/tmp/backup/ >> result.txt
#закачиваем файл на g.drive
/usr/sbin/drive upload -f /root/bin/backup*.tar.gz >> result.txt
rm -rf /root/bin/backup*.tar.gz >> result.txt
echo «Посмотрите файл на наличие ошибок и исправьте их» | mail -a «/root/bin/result.txt» -s «Резервная копия создана» — ******@gmail.com
rm -rf /root/bin/result.txt
rm -rf /var/www/tmp/backup/*
Остальные шаги в скрипте я не расписывал, так как они повторяются с предыдущими.
Запустив скрипт, он выполнился:
С веб-интерфейса его так же видно, как и с консоли:
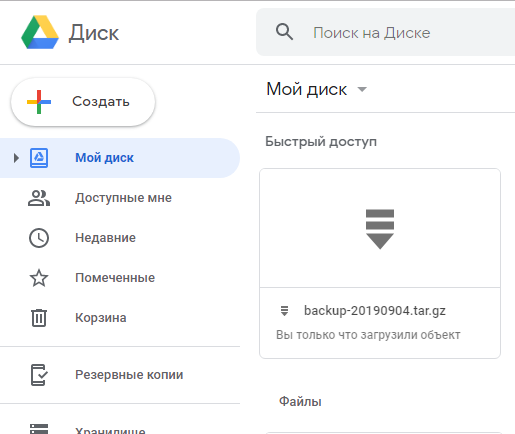
Таким образом мы получаем скрипт, который выполняет проверку на наличие старых бэкапов в облаке Google Диск, удаляет их если они попадают под требования, после чего создает резервную копию сайта и отправляет ее в это же облако.
Скрипт бекапа на Яндекс.Диск из Linux
Данное облачное хранилище я оставил на закуску, так как резервное копирование в Яндекс.Диск является самым простым, т.к. мы смонтировали облачное хранилище Яндекс через WebDav как отдельное дисковое утсройство . Способ все тот же, мы запускаем скрипт, только лишь с небольшой разницей, не нужно делать синхронизацию или заливку файлов специальными командами, работаем как с обычным серверным каталогом. Синхронизация каталога выполняется с помощью rsync. Скрипт будет иметь вид:
#!/bin/bash
rsync -avzr —progress /var/www/html/ /var/www/tmp/backup/ >> result.txt
mysqldump joomla > /var/www/tmp/backup/backup.sql
tar -cvzf backup-$(date +%Y%m%d).tar.gz —absolute-names /var/www/tmp/backup/ >> result.txt
find /mnt/yad/ -name «backup*.tar.gz» -mtime +7 -exec rm -f <> \; >> result.txt
rsync -avzr —progress /root/bin/backup*.tar.gz /mnt/yad/ >> result.txt
rm -rf /root/bin/backup*.tar.gz >> result.txt
echo «Посмотрите файл на наличие ошибок и исправьте их» | mail -a «/root/bin/result.txt» -s «Резервная копия создана» — ****@gmail.com
rm -rf /root/bin/result.txt
rm -rf /var/www/tmp/backup/*
Все тоже самое, только без лишних команд. Если у вас другие пути до облачных хранилищ, меняйте в скрипте на свои.
В конце статьи хотелось бы добавить. Я разместил указанные скрипты в отдельную директорию и запускают их по крону. Если дисковое пространство на ваших облачных дисках позволяет часто создавать бэкапы, создавайте их как можно чаще, я рекомендую не реже одного раза в 3 дня. Используйте ресурсы облачных хранилищ на все 100%.
Примеры заданий в кроне:
0 0 * * 6 /root/bin/backup.sh — запускаем скрипт бэкапа каждую субботу в 00-00
0 0 */3 * * /root/bin/backup.sh — запускаем скрипт бэкапа каждые 3 дня в 00-00
И так далее, настройте бэкапы как вам удобно, когда нагрузка на сервере минимальна.
Источник
Элементарный Bash скрипт для резервного копирования данных
Привет хабралюди, сейчас я расскажу как можно немного автоматизировать рутиную работу по подготовке бэкапов.
В данном случае, мы не будем использовать мощные программы, или даже целые системы для резервного копирования данных, ограничимся самым доступным что у нас есть. А именно — Bash скриптом.
Что должен выполнять наш скрипт?
Бэкапить веб проект, а именно:
— Делать резервную копию базы MySQL.
— Делать резервную копию файлов.
— Структурировать это.
И так, вот наш скрипт:
#!/bin/bash
PROJNAME= #Имя проекта
CHARSET= #Кодировка базы данных (utf8)
DBNAME= #Имя базы данных для резервного копирования
DBFILENAME= #Имя дампа базы данных
ARFILENAME= #Имя архива с файлами
HOST= #Хост MySQL
USER= #Имя пользователя базы данных
PASSWD= #Пароль от базы данных
DATADIR= #Путь к каталогу где будут храниться резервные копии
SRCFILES= #Путь к каталогу файлов для архивирования
PREFIX=`date +%F` #Префикс по дате для структурирования резервных копий
#start backup
echo «[———————————[`date +%F—%H-%M`]———————————]»
echo «[———-][`date +%F—%H-%M`] Run the backup script. »
mkdir $DATADIR/$PREFIX 2> /dev/null
echo «[++———][`date +%F—%H-%M`] Generate a database backup. »
#MySQL dump
mysqldump —user=$USER —host=$HOST —password=$PASSWD —default-character-set=$CHARSET $DBNAME > $DATADIR/$PREFIX/$DBFILENAME-`date +%F—%H-%M`.sql
if [[ $? -gt 0 ]];then
echo «[++———][`date +%F—%H-%M`] Aborted. Generate database backup failed.»
exit 1
fi
echo «[++++——][`date +%F—%H-%M`] Backup database [$DBNAME] — successfull.»
echo «[++++++—-][`date +%F—%H-%M`] Copy the source code project [$PROJNAME]. »
#Src dump
tar -czpf $DATADIR/$PREFIX/$ARFILENAME-`date +%F—%H-%M`.tar.gz $SRCFILES 2> /dev/null
if [[ $? -gt 0 ]];then
echo «[++++++—-][`date +%F—%H-%M`] Aborted. Copying the source code failed.»
exit 1
fi
echo «[++++++++—][`date +%F—%H-%M`] Copy the source code project [$PROJNAME] successfull.»
echo «[+++++++++-][`date +%F—%H-%M`] Stat datadir space (USED): `du -h $DATADIR | tail -n1`»
echo «[+++++++++-][`date +%F—%H-%M`] Free HDD space: `df -h /home|tail -n1|awk ‘
echo «[++++++++++][`date +%F—%H-%M`] All operations completed successfully!»
exit 0
Запускать можно парой способов:
— Простой запуск: ./backup.sh
— Запуск + запись в лог: ./backup.sh | tee backup.log
— а еще его можно в cron запихать: 00 20 * * 7 root sh /home/bond/backup.sh | tee /home/bond/backup/backup.log
После успешного завершения скрипта, мы увидим следующее:
$ sudo sh backup.sh
[———————————[2009-02-14—12-28]———————————]
[———-][2009-02-14—12-28] Run the backup script.
[++———][2009-02-14—12-28] Generate a database backup.
[++++——][2009-02-14—12-29] Backup database [images] — successfull.
[++++++—-][2009-02-14—12-29] Copy the source code project [itmages].
[++++++++—][2009-02-14—12-29] Copy the source code project [itmages] — successfull.
[+++++++++-][2009-02-14—12-29] Stat datadir space (USED): 1,3G /home/bond/backup
[+++++++++-][2009-02-14—12-29] Free HDD space: 49G
[++++++++++][2009-02-14—12-29] All operations completed successfully!
bond@serv:
В итоге наши бэкапы складываются в каталог который вы указали, + резервные копии лежат в каталогах именованых по дате.
Источник



