- Служба балансировки нагрузки windows
- Проблема: один из пользователей потребляет 90% и более CPU
- Что такое Dynamic Fair Share Scheduling (DFSS)?
- Вот так называются три компонента входящие в состав DFSS
- Как включить Dynamic Fair Share Scheduling (DFSS)?
- Балансировка CPU на RDSH хосте
- Как отключать CPU Fair Share
- Пример использования CPU Fair Share
- Балансировка дисковых операций на RDSH хосте
- Балансировка нагрузки сети: описание технологии
- Архитектура службы балансировки нагрузки сети
- Распределение потока данных кластера
- Алгоритм балансировки нагрузки
- Схождение
- Удаленное управление
Служба балансировки нагрузки windows
 Добрый день! Уважаемые читатели и гости одного из крупнейших IT блогов по системному администрированию Pyatilistnik.org. В прошлый раз мы с вами разобрали группы доступности AlwaysOn. Сегодня я хочу рассмотреть еще одну часто встречающуюся проблему в практике системного администратора, речь пойдет о балансировке и распределении системных ресурсов (CPU, Сеть, Диск) на хостах RDS фермы Windows Server 2019, но актуально будет и для более старых версий, вплоть до Windows Server 2012 R2. Мы научимся равномерно распределять нагрузку по пользовательским сессиям с помощью Dynamic Fair Share Scheduling (DFSS).
Добрый день! Уважаемые читатели и гости одного из крупнейших IT блогов по системному администрированию Pyatilistnik.org. В прошлый раз мы с вами разобрали группы доступности AlwaysOn. Сегодня я хочу рассмотреть еще одну часто встречающуюся проблему в практике системного администратора, речь пойдет о балансировке и распределении системных ресурсов (CPU, Сеть, Диск) на хостах RDS фермы Windows Server 2019, но актуально будет и для более старых версий, вплоть до Windows Server 2012 R2. Мы научимся равномерно распределять нагрузку по пользовательским сессиям с помощью Dynamic Fair Share Scheduling (DFSS).
Проблема: один из пользователей потребляет 90% и более CPU
Опишу реальный случай с которым вы обязательно столкнетесь, если у вас в компании используются терминальные столы. И так есть RDS ферма построенная на базе Windows Server 2012 R2 до Windows Server 2019. На каждом из RDSH хостов могут одновременно работать свыше 30 пользователей. В среднем они суммарно не потребляют более 30% процессорных мощностей, но когда приходит период отчетности некоторые пользователи начинают нагружать сервера куда интенсивнее. Очень часто можно встретить, что пользователь работающий с Excel, 1С и похожими программами начинает потреблять 80-90% процессорных мощностей, в результате чего начинают страдать остальные пользователи этого RDSH хоста.
Ранее для решения это проблемы в Windows Server 2008 R2 был замечательный компонент диспетчер системных ресурсов (Windows System Resource Manager), но Microsoft его посчитала устаревшим и выпилила из состава компонентов, аж с Windows Server 2012 R2 и выше. Но не думайте, что доблестные разработчики не подумали чем вам восполнить этот пробел, они придумали и включили в состав Windows Server компонент «Динамическое планирование долевого распределения» или как в оригинале «Dynamic Fair Share Scheduling (DFSS)«.
Что такое Dynamic Fair Share Scheduling (DFSS)?
Так как официального метода вернуть Windows System Resource Manager не существует, а есть лишь костыльные, нам придется работать с тем, что есть. «Динамическое планирование долевого распределения» или как в оригинале «Dynamic Fair Share Scheduling (DFSS)» — это механизм автоматической балансировки и распределения сетевой нагрузки, дисковых, процессорных мощностей между всеми пользовательскими сессиями на RDSH хосте. Все эти три варианта имеют цель предотвратить чрезмерное использование ресурсов одним пользователем и предоставить всем пользователям одинаковые возможности. Однако методы FairShare не гарантируют, что ресурсы не будут исчерпаны, это все еще может иметь место. Если все пользователи используют все ресурсы ЦП, FairShare гарантирует, что все пользователи получат некоторую емкость ЦП, но все же может быть, что все процессоры загружены на 100%, а пользователи испытывают снижение производительности, это нужно учитывать.
Вот так называются три компонента входящие в состав DFSS
- CPU Fair Share — Динамически распределяет процессорное время между пользовательскими сессиями. Тут будет учитываться их количество и интенсивность использования.
- Network Fair Share — Динамически распределяет полосу пропускания сетевого интерфейса между пользовательскими сессиями. Советую использовать совместно с Qos.
- Disk Fair Share — данная функция защищает ваши диски от очень интенсивного использования одним пользователем, позволяет равномерно балансировать дисковые операции между всеми.
Как включить Dynamic Fair Share Scheduling (DFSS)?
Если говорить про Windows Server 2019, то динамическое планирование долевого распределения уже по умолчанию там активно, то же самое и на Windows Server 2016, а вот в Windows Server 2012 R2, ее нужно активировать. Для того чтобы у вас в системе был активен встроенный балансировщик ресурсов DFSS, у вас должна быть выключена одна политика или выставлен нужный ключ реестра.
Балансировка CPU на RDSH хосте
Для того, чтобы у вас на RDS ферме была балансировка процессорных мощностей, необходимо наличие активной политики:
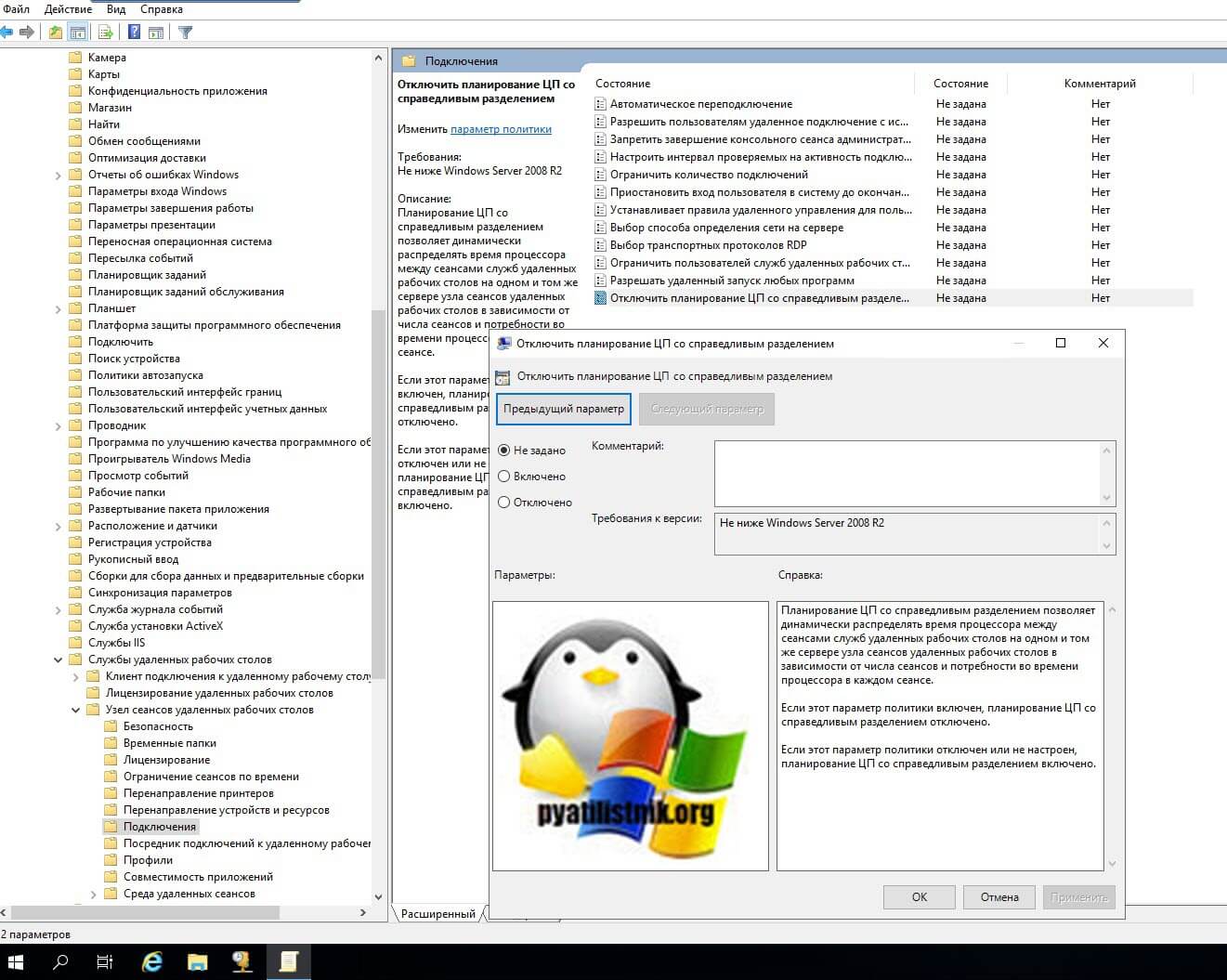
Как я и писал выше функция планирования ЦП со справедливым разделением в 2019 системе включена по умолчанию, и данная политика имеет статус не задано.
Если этот параметр политики включен, то планирование ЦП со справедливым разделением отключено. Если этот параметр политики отключен или не настроен, планирование ЦП со справедливым разделением включено
Так же эта настройка имеет и аналог в виде ключа реестра, найти его можно по пути:
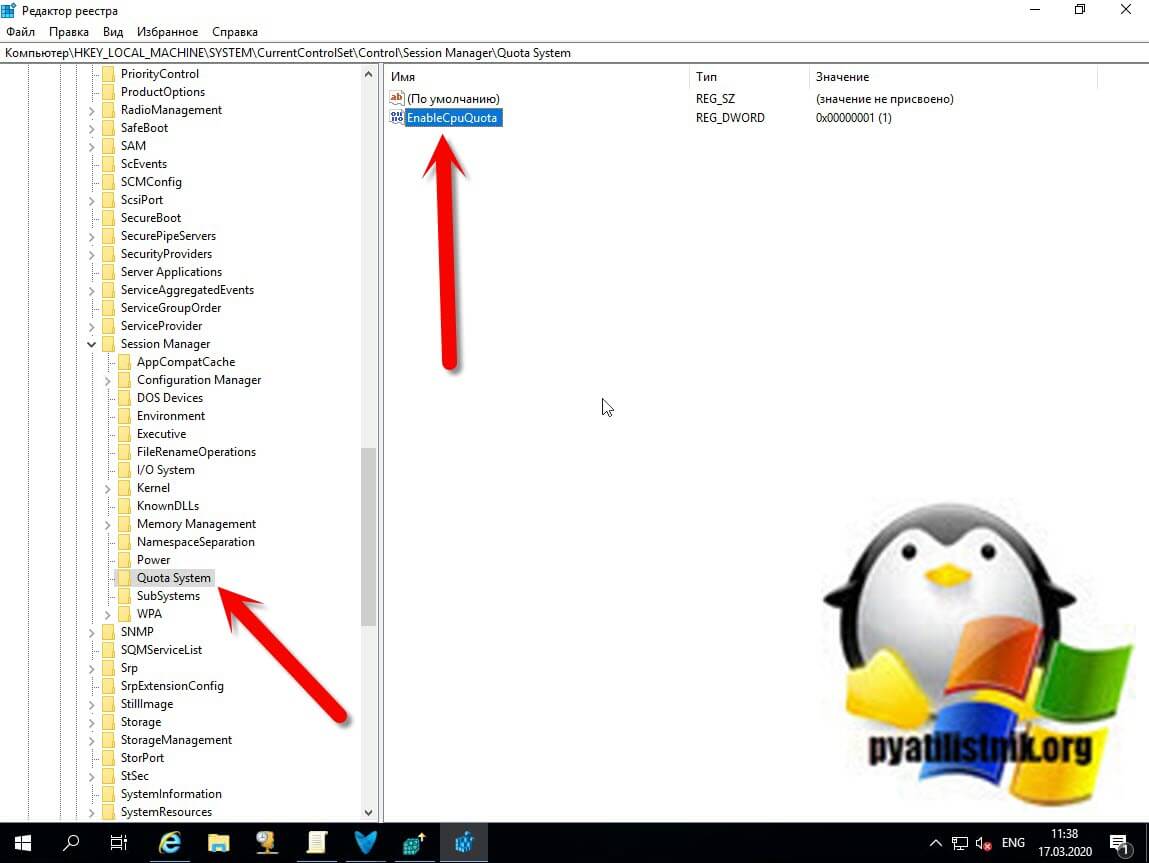
Если ключ EnableCpuQuota имеет значение 1, то значит планирование ЦП со справедливым разделением включено. Хочу отметить, что в Windows Server 2012 R2, хоть в системе и есть политика, но данного ключа нет, а его желательно бы создать если хотите использовать CPU Fair Share.
Как отключать CPU Fair Share
Существуют ситуации, при которых требуется выключить DFSS, приведу пример. Citrix Xenapp также имеет свои собственные политики для разделения процессорного времени между пользователями, и неудивительно, что они не могут сосуществовать с политиками Microsoft. Управление процессорами Citrix не вступит в силу, если DFSS все еще включен. На самом деле, вы получите следующую ошибку на сервере:
Для отключения CPU Fair Share в Windows Server 2019, вам нужно сначала включить политику «Отключить планирование ЦП со справедливым разделением (Turn off Fair Share CPU Scheduling)». Сделать, это можно через групповые политики или же через локальный редактор политик (gpedit.msc).
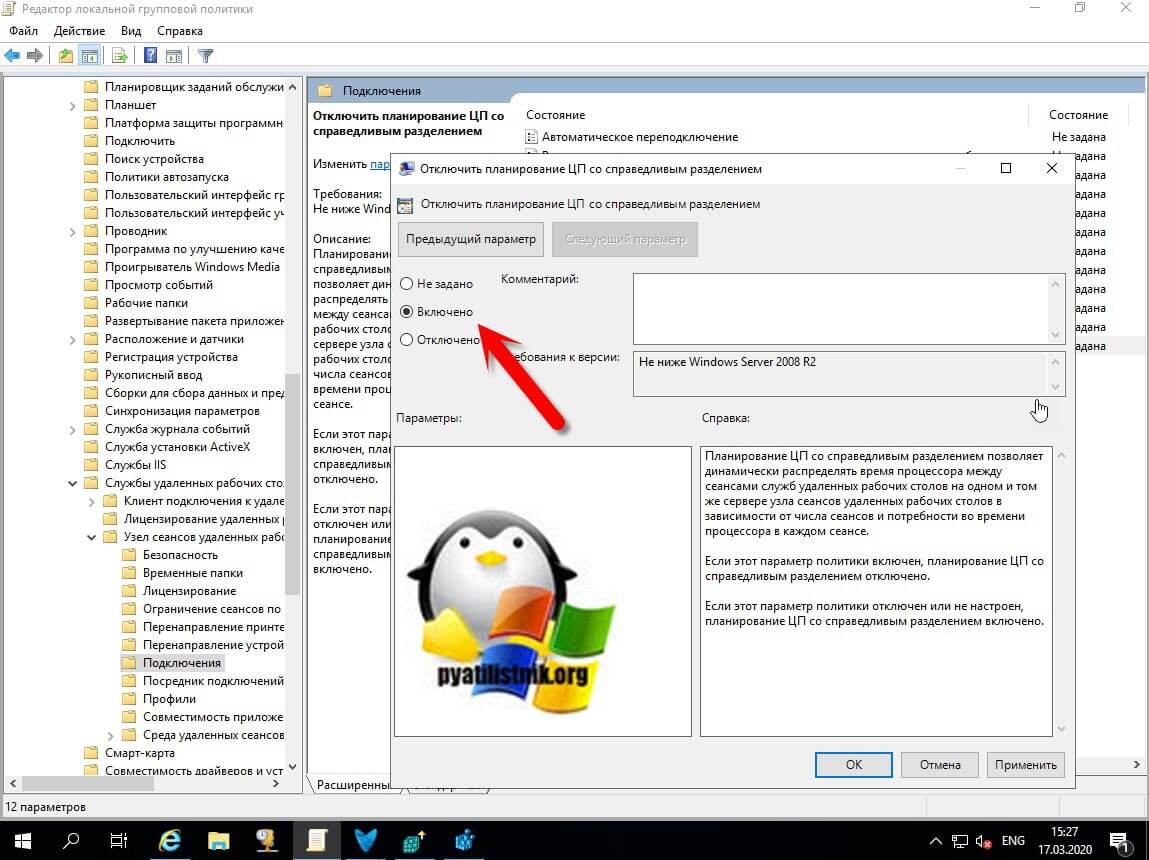
После нужно выполнить обновление групповой политики, когда первое действие выполнено вы можете изменить значение ключа EnableCpuQuota на «0». По идее все должно работать, но иногда бывают случаи, что приходилось произвести перезагрузку сервера.
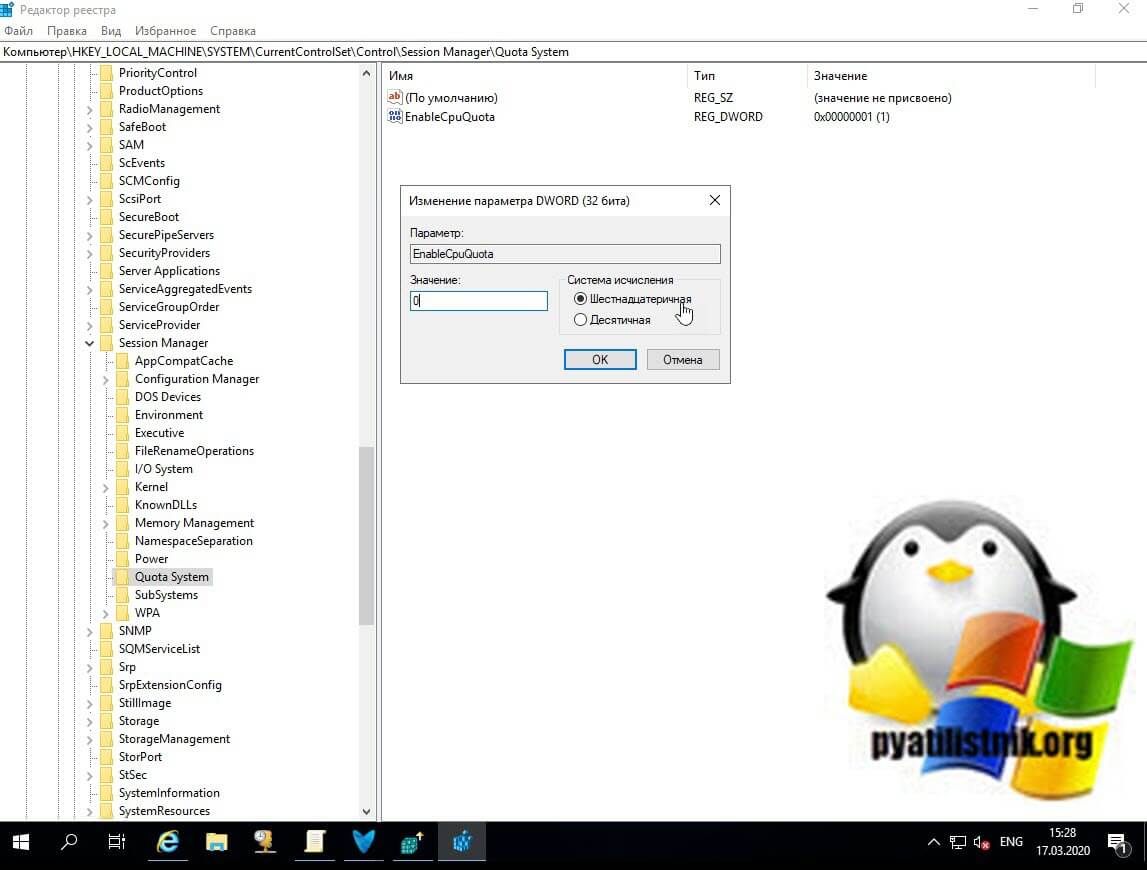
Так же отключить DFSS можно и через PowerShell, для этого введите команду изменяющую значение реестра:

Пример использования CPU Fair Share
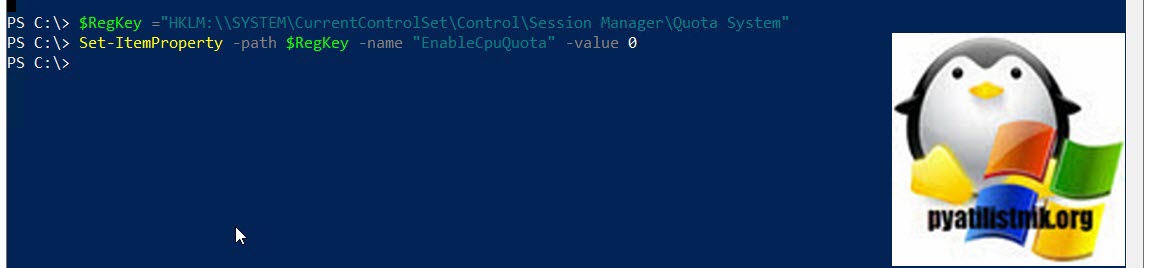
Чтобы показать работу FairShare, я использовал инструмент CPUstress, созданный Тимом Манганом. С помощью этого инструмента вы можете вызвать чрезмерное использование ресурсов процессора. В тесте будут участвовать два пользователя, Барбоскин Геннадий Викторович и Администратор.
Первый тест с включенной опцией динамического распределения процессорного время между пользовательскими сессиями. Я зашел на свою RDS ферму и запустил из под каждого пользователя CPUstress. Как видно из картинки мой процессор загружен на 100% и все его мощности делятся в равных частях между пользователями сервера.
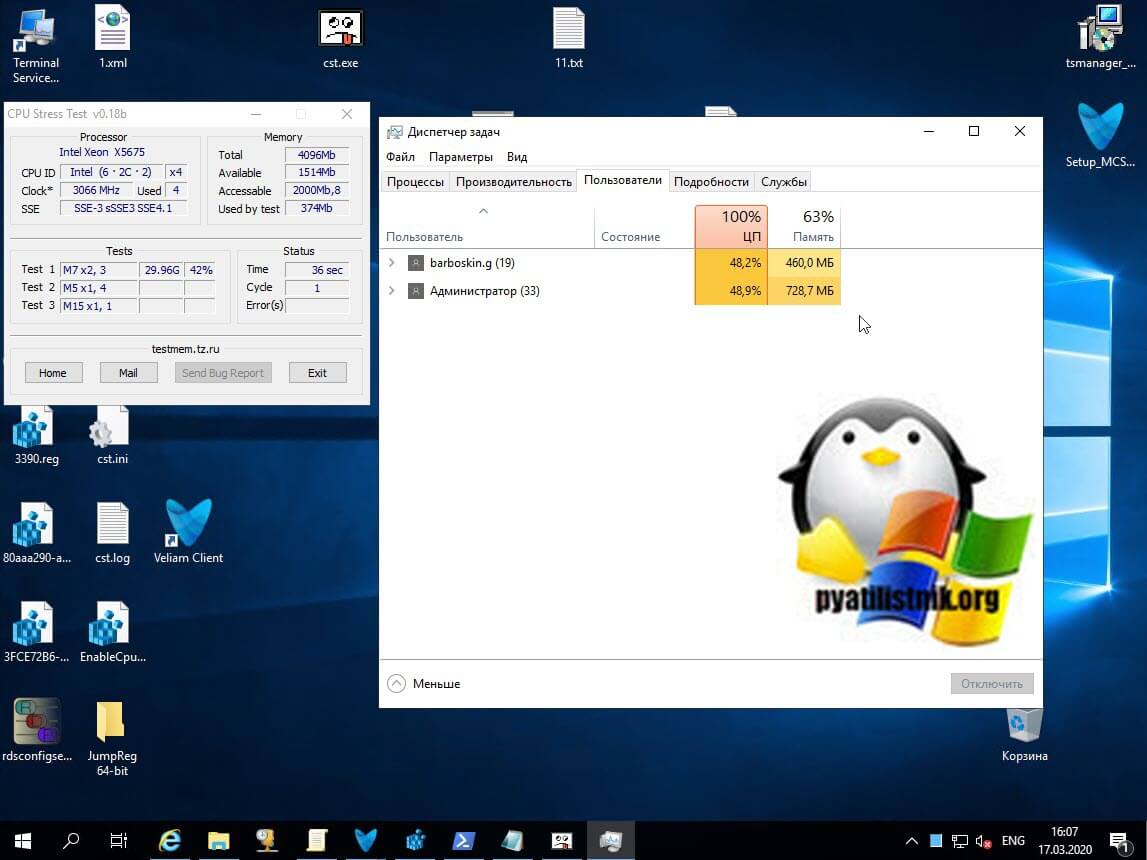
А вот тест когда CPU Fair Share выключен, как видите тут уже идет борьба за ресурсы между пользователями, у администратора в моем примере 73%, а у barboskin.g 25%. Потом эти доли могут кардинально поменяться.
Балансировка дисковых операций на RDSH хосте
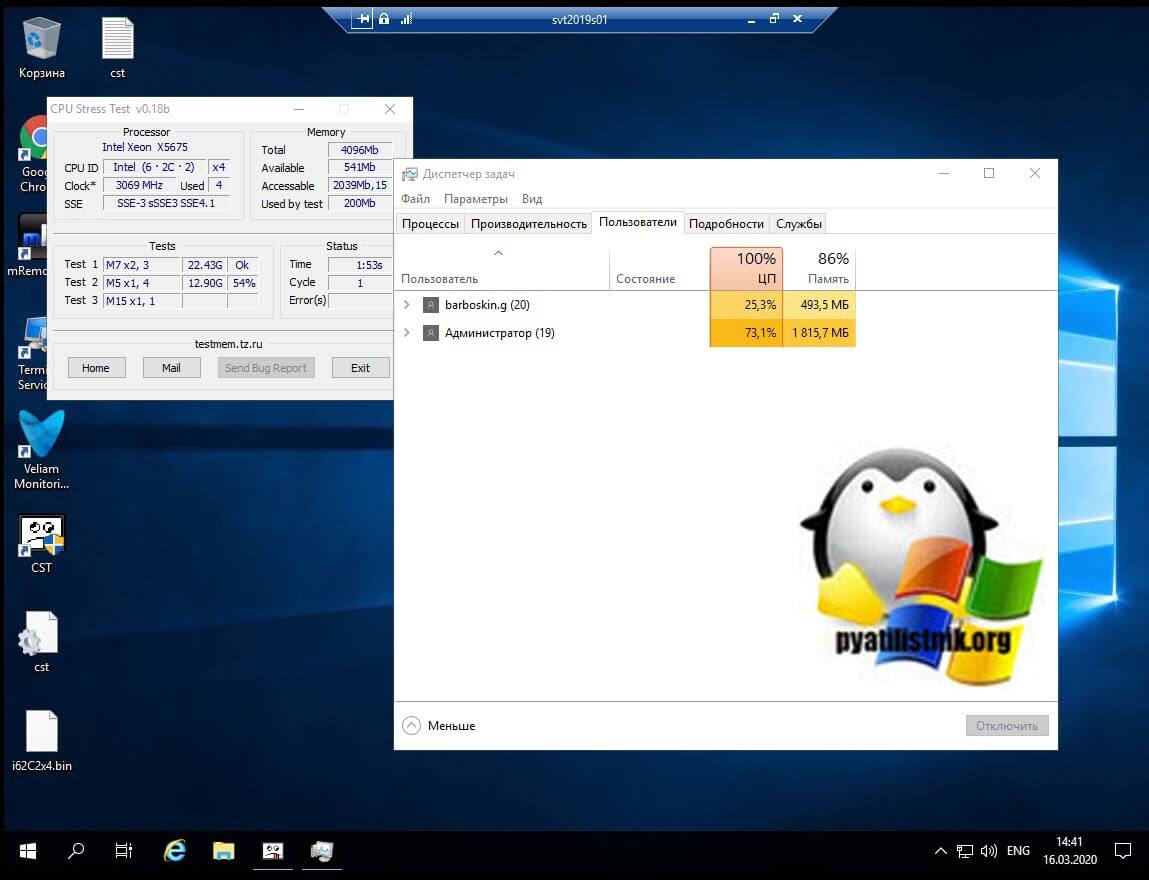
Управление балансировкой дисковых операций осуществляется через компонент Disk Fair Share. Данный компонент включается или выключается исключительно через ключ реестра EnableFairShare.
«1» означает, что компонент активен, а вот «0» отключает Disk Fair Share.
С помощью FairShare of Resources в RD Session Host Microsoft реализовала приятную функциональность. Это здорово, что Microsoft расширила функциональность с помощью Network and Disks, но лично я думаю, что большинство компаний будут чаще использовать CPU FairShare. На этом у меня все, с вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Балансировка нагрузки сети: описание технологии

 Посетителей: 22220 | Просмотров: 31489 (сегодня 0)
Посетителей: 22220 | Просмотров: 31489 (сегодня 0)


![]()
Кластерная технология балансировки нагрузки сети (Network Load Balancing), включенная в операционные системы Microsoft ® Windows ® 2000 Advanced Server и Datacenter Server, повышает масштабируемость и отказоустойчивость критически важных служб, работающих по протоколам TCP/IP, таких как веб-сервер, службы терминалов, службы виртуальных частных сетей и потокового мультимедийного вещания. Служба балансировки нагрузки, являющаяся компонентом ОС Windows 2000, функционирует на всех узлах кластера и не требует для работы специального оборудования. Для обеспечения масштабируемости производительности служба БНС (Балансировка нагрузки сети, Network Load Balancing) распределяет поток данных, передаваемых по протоколу IP, между несколькими узлами кластера. Помимо этого, служба обеспечивает высокую отказоустойчивость, автоматически обнаруживая сбои узлов и перераспределяя поток данных среди оставшихся. Служба БНС включает функции удаленного управления и позволяет осуществлять чередующиеся обновления для ОС Windows NT ® 4.0 и более поздних версий.
Уникальная, полностью распределенная архитектура службы БНС позволяет обеспечивать высочайшую производительность и защиту от сбоев, особенно по сравнению с технологиями распределения нагрузки на основе диспетчеризации. В данном документе подробно описаны основные функции службы балансировки нагрузки, ее внутреннее устройство и параметры производительности.
Архитектура службы балансировки нагрузки сети
Для достижения максимальной пропускной способности и отказоустойчивости служба БНС использует полностью распределенную программную архитектуру. На всех узлах кластера параллельно выполняются одинаковые драйверы службы БНС. Эти драйверы объединяют все узлы в единую сеть для обработки входящего потока данных, поступающих на основной IP-адрес кластера (и на дополнительные IP-адреса многосетевых узлов). Для каждого отдельного узла драйвер выполняет функции фильтра между драйвером сетевого адаптера и стеком протоколов TCP/IP, позволяя распределять поток данных, получаемых узлом. Таким образом, поступающие запросы разделяются и распределяются между узлами кластера.
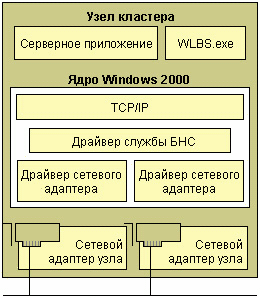
Рисунок 1 — Узел кластера. Ядро Windows 2000
Служба БНС функционирует как сетевой драйвер, расположенный в сетевой модели ниже высокоуровневых протоколов приложений, таких как HTTP и FTP.
Такая архитектура позволяет добиться максимальной пропускной способности за счет использования широковещательной подсети для доставки поступающих данных на все узлы кластера, которая позволяет обойтись без маршрутизации входящих пакетов. Поскольку фильтрация ненужных пакетов работает быстрее, чем маршрутизация (при которой необходимо получить, проверить, перезаписать и повторно отправить каждый пакет), при использовании службы БНС достигается более высокая пропускная способность сети по сравнению с решениями на основе диспетчеризации. При росте скорости работы сервера и сети пропорционально растет и производительность; таким образом устраняется зависимость от производительности аппаратных решений для распределения нагрузки на основе маршрутизации. Например, в гигабитных сетях служба БНС демонстрирует пропускную способность до 250 Мб/с.
Другим ключевым преимуществом полностью распределенной архитектуры службы БНС являются превосходные показатели отказоустойчивости (N–1) для кластера с N узлами. Напротив, в решениях на основе диспетчеризации обязательно имеется центральный элемент, являющийся «узким местом» системы, для устранения которого необходимо использовать резервный диспетчер, обеспечивая лишь однонаправленное перемещение нагрузки при сбое. Такая защита от сбоя менее эффективна по сравнению с полностью распределенной архитектурой.
В архитектуре службы БНС для одновременной доставки поступающих данных на каждый узел кластера используется концентратор и/или коммутатор подсети. Тем не менее, такой подход ведет к увеличению нагрузки на коммутаторы и требует дополнительных ресурсов пропускной способности портов. (Сведения о показателях производительности при использовании коммутаторов см. в разделе «Производительность балансировки нагрузки сети»). Обычно это не влияет на большинство широко используемых приложений (например, веб-службы и мультимедиа-вещание), поскольку входящие данные составляют очень небольшую долю общего потока данных в сети. Тем не менее, если пропускная способность линии связи к коммутатору со стороны клиента значительно выше пропускной способности канала со стороны сервера, входящие данные могут составлять весьма значительную часть общего потока данных. Та же проблема возникает и при подключении нескольких кластеров к одному коммутатору, когда для отдельных кластеров не настроены виртуальные локальные сети LAN.
Полностью конвейерный механизм службы БНС при поступлении пакетов одновременно передает их в стек протоколов TCP/IP и получает пакеты от драйвера сетевого адаптера. Это снижает общее время обработки потока данных и задержку, поскольку стек TCP/IP может обрабатывать пакет одновременно с получением драйвером NDIS следующего пакета. Кроме того, требуется меньше ресурсов для координации операций стека TCP/IP и драйвера, а также, в большинстве случаев, в памяти не создаются дополнительные копии пакетов данных. При отправке пакетов служба БНС также обеспечивает повышенную пропускную способность, малое время задержки и отсутствие накладных издержек производительности за счет увеличения числа пакетов TCP/IP, которые могут быть отправлены за один вызов NDIS. Для достижения столь высокой производительности служба БНС использует пул буферов и дескрипторов пакетов, используемый для конвейерных операций со стеком TCP/IP и драйвером NDIS.
Распределение потока данных кластера
Для распределения входящего потока данных между всеми узлами кластера служба БНС использует широковещательные или многоадресные пакеты протокола второго уровня. В используемом по умолчанию одноадресном режиме служба БНС переназначает аппаратный (MAC) адрес сетевого адаптера, для которого она включена (называемого адаптером кластера), и всем узлам в кластере назначается один MAC-адрес. Таким образом, поступающие пакеты принимаются всеми узлами кластера и передаются службе БНС для фильтрации. Для обеспечения уникальности MAC-адрес формируется на основании основного IP-адреса кластера, указанного на странице свойств службы БНС. Для основного IP-адреса 1.2.33.44 будет использоваться MAC-адрес одноадресного режима 02-BF-11-2-33-44. Служба БНС автоматически изменяет МАС-адрес адаптера кластера путем внесения изменения в реестр и последующей перезагрузки драйвера адаптера; при этом не требуется перезапуск операционной системы.
Если узлы кластера подключены к коммутатору, а не к концентратору, использование общего MAC-адреса может вызвать конфликт, поскольку коммутаторы второго уровня способны работать только с уникальными MAC-адресами источников на всех портах. Для устранения данной проблемы служба БНС модифицирует MAC-адрес источника в исходящих пакетах; MAC-адрес кластера 02-BF-11-2-33-44 преобразуется в адрес вида 02-h-11-2-33-44, где h — приоритет узла внутри кластера (задается в окне свойств службы БНС). Таким образом, коммутатору не передается фактический MAC-адрес кластера, и в результате поступающие в кластер пакеты данных доставляются на все порты коммутатора. Если узлы кластера подключены вместо коммутатора непосредственно к концентратору, в одноадресном режиме службы БНС маскировку исходного MAC-адреса можно отключить, чтобы заблокировать лавинную маршрутизацию исходящих пакетов в коммутаторе. Отключение маскировки производится путем присвоения в реестре параметру MaskSourceMAC службы БНС значения 0. Использование коммутатора исходящих данных по протоколу третьего уровня позволяет также избежать лавинной маршрутизации.
У одноадресного режима работы службы БНС имеется побочный эффект блокирования непосредственной связи между сетевыми адаптерами узлов кластера. Поскольку исходящие пакеты, отправляемые другому узлу кластера, посылаются на MAC-адрес, совпадающий с адресом отправителя, эти пакеты возвращаются отправителю сетевым стеком и никогда не попадут в сеть. Это ограничение можно обойти, установив в каждый сервер кластера второй сетевой адаптер. В таком случае служба БНС обрабатывает данные только от сетевого адаптера подсети, от которого поступают клиентские запросы, а второй адаптер, как правило, подключается к отдельной подсети, предназначенной для связи с другими узлами и серверами файлов и баз данных. Для ритмических сообщений и удаленного управления используется только сетевой адаптер кластера.
Следует отметить, что ограничения одноадресного режима службы БНС не влияют на подключения узлов кластера к узлам, не включенным в кластер. Поток данных из сети, поступающий на выделенный IP-адрес (на адаптер кластера), получают все узлы кластера, поскольку они используют одинаковый MAC-адрес. Поскольку служба БНС никогда не передает распределенные данные на выделенный IP-адрес кластера, они доставляются непосредственно стеку протоколов TCP/IP узла-адресата. На других узлах служба БНС обрабатывает эти пакеты как уже распределенный поток данных (поскольку IP-адрес получателя не совпадает с выделенными IP-адресами других узлов): они могут быть переданы стеку TCP/IP, который их отклонит. Передача чрезмерного объема данных на выделенные IP-адреса при работе в одноадресном режиме может привести к падению производительности, поскольку стек TCP/IP вынужден отклонять большое количество «чужих» пакетов.
Поэтому в службе БНС имеется второй режим, обеспечивающий распределение входящего потока данных всем узлам кластера. При использовании многоадресного режима вместо изменения МАС-адреса адаптера кластера ему присваивается широковещательный адрес второго уровня. Основному IP-адресу кластера 1.2.33.44 будет при этом соответствовать широковещательный MAC-адрес03-BF-11-2-33-44. Поскольку у каждого узла сохраняется уникальный МАС-адрес, в этом режиме нет необходимости устанавливать второй сетевой адаптер для связи между узлами кластера. В нем также отсутствует падение производительности при использовании выделенных IP-адресов.
Для одновременной доставки входящего потока данных всем узлам кластера в однонаправленном режиме работы службы БНС используется лавинная маршрутизация (доставка пакетов во все порты коммутатора, кроме исходного). При использовании многоадресного режима коммутаторы также во многих случаях отправляют пакеты во все порты для доставки широковещательных данных. Тем не менее, в многоадресном режиме системный администратор имеет возможность ограничить лавинную маршрутизацию, настроив в коммутаторе виртуальную сеть для портов, относящихся к узлам кластера. Это может быть сделано путем ручной настройки коммутатора или с помощью протоколов IGMP (Internet Group Management Protocol, межсетевой протокол управления группами) и GARP. Текущая версия службы БНС не имеет автоматической поддержки протоколов IGMP и GMRP.
Она поддерживает протокол ARP (Address Resolution Protocol, протокол разрешения адресов), необходимый для разрешения основного IP-адреса и других виртуальных IP-адресов в широковещательный MAC-адрес кластера. (Выделенный IP-адреспо-прежнему разрешается в МАС-адрес адаптера кластера.) Опыт показывает, что маршрутизаторы Cisco не принимают сигнал ARP от кластера, разрешающего однонаправленные IP-адреса в широковещательные MAC-адреса. Эту проблему можно обойти, добавив в маршрутизатор статическую запись ARP для каждого виртуального IP-адреса. Широковещательный МАС-адрес можно посмотреть в окне свойств службы БНС или с помощью программы удаленного управления Wlbs.exe. В используемом по умолчанию однонаправленном режиме данная проблема отсутствует, поскольку MAC-адрес кластера совпадает с однонаправленным MAC-адресом.
Служба БНС не управляет никакими входящими пакетами данных, кроме данных по протоколам TCP, UDP и GRE (часть потока данных PPTP) для указанных портов. Она не фильтрует данные по протоколам IGMP, ARP (за исключением указанных выше), ICMP или другим IP-протоколам. Все данные по этим протоколам передаются стеку TCP/IP в неизменном виде на всех узлах кластера. В результате для некоторых TCP/IP-программ «точка-точка» (например, ping) при использовании IP-адреса кластера могут генерироваться дублирующиеся отклики. Благодаря надежности протокола TCP/IP и его способности обрабатывать дублированные датаграммы, другие протоколы продолжают правильно работать в кластере. Чтобы избежать данной проблемы, для таких программ можно использовать выделенный IP-адрес.
Алгоритм балансировки нагрузки
Для распределения подключаемых клиентов между узлами кластера служба БНС использует полностью распределенный алгоритм фильтрации. Этот алгоритм был выбран для предоставления узлам кластера возможности быстро и независимо друг от друга принимать решения о распределении нагрузки для каждого входящего пакета. Алгоритм был оптимизирован для обеспечения статистически равномерного распределения нагрузки по большому количеству клиентских узлов, выполняющих постоянные, относительно небольшие запросы (такой тип нагрузки типичен, например, для веб-серверов). Когда количество клиентов невелико и/или объем запросов клиентов меняется в широких пределах, алгоритм распределения нагрузки службы БНС менее эффективен. Тем не менее, простота и скорость работы этого алгоритма позволяют обеспечивать очень высокую производительность, высокую пропускную способность и низкое время отклика для различных типов приложений клиент/сервер.
Служба БНС распределяет поступающие клиентские запросы, направляя определенный процент новых запросов каждому узлу кластера. Процент распределяемой загрузки задается в окне «Свойства балансировки нагрузки сети» для каждого диапазона номеров портов, нагрузку которых необходимо распределять. Алгоритм не способен адаптироваться к изменениям нагрузки каждого узла кластера (в отличие от нагрузки ЦП и использования памяти). Однако сопоставление меняется при изменении количества узлов кластера, в соответствии с которым меняются проценты распределения нагрузки.
При анализе поступающего пакета все узлы одновременно выполняют статическое сопоставление для быстрого выбора узла, который будет обрабатывать пакет. Для сопоставления используется функция случайного выбора, рассчитывающая приоритет узла на основании IP-адреса клиента, номера порта и других данных о состоянии, поддерживаемых для оптимизации распределения нагрузки. Выбранный узел передает пакет из сетевого стека в стек TCP/IP, а другие узлы отклоняют этот пакет. Схема сопоставления меняется только при изменениях состава узлов кластера; в результате комбинация определенного IP-адреса клиента и номера порта всегда сопоставлена одному узлу кластера. Однако узел кластера, которому сопоставлен IP-адрес и порт клиента, нельзя определить заранее, так как функция случайного выбора учитывает текущее и прошлое членство в кластере для минимизации изменений схемы сопоставления.
В алгоритме распределения нагрузки предполагается, что IP-адреса и номера портов клиентов (когда не используется режим привязки клиентов) статистически не связаны. Такое предположение может перестать соответствовать действительности, если на стороне сервера используется брандмауэр, который преобразует адреса клиентов в один IP-адрес, и одновременно включена привязка клиентов. В таком случае все клиентские запросы будут обрабатываться одним узлом кластера, а служба распределения загрузки функционировать не будет. Тем не менее, если привязка клиентов не используется, разброс номеров портов клиентов даже при использовании брандмауэра обычно способен обеспечить хорошее распределение нагрузки.
Как правило, качество распределения статистически определяется количеством клиентов, выполняющих запросы. Такое поведение напоминает подбрасывание монеты, две стороны которой соответствуют количеству узлов кластера (в данной аналогии в кластере два узла), а число бросков соответствует количеству клиентских запросов. Распределение нагрузки улучшается с увеличением количества запросов, подобно тому, как процент бросков монеты, когда выпадает «орел», стремится к 50 с увеличением числа бросков. На практике при включенном режиме привязки для равномерного распределения нагрузки количество клиентов должно значительно превышать количество узлов.
Вследствие стохастического характера набора клиентов могут наблюдаться незначительные временные изменения равномерности распределения нагрузки. Следует отметить, что достижение абсолютно равномерного распределения нагрузки между всеми узлами кластера потребовало бы значительного увеличения производительности (пропускной способности и времени отклика), которые расходовались бы на измерение и реакцию на колебания нагрузки. Стоимость ресурсов, которые дополнительно потребовались для этого, следует сопоставить с потенциальными преимуществами максимально оптимального использования ресурсов узлов кластера (в основном ресурсов ЦП и оперативной памяти). В любом случае необходимо обеспечить избыточность ресурсов кластера для обеспечения обработки нагрузки в случае сбоя одного из узлов. В службе БНС используется простой, но в тоже время эффективный алгоритм распределения нагрузки, обеспечивающий максимально возможную производительность и отказоустойчивость.
Параметры привязки клиентов службы БНС реализованы за счет изменения входных данных алгоритма статического сопоставления. При выборе привязки клиентов в окне «Свойства балансировки нагрузки сети» номера портов клиентов не используются для сопоставления. Поэтому все запросы от одного клиента всегда направляются на один узел кластера. Необходимо отметить, что для этого ограничения значение времени ожидания не указывается (как это обычно бывает в решениях с диспетчеризацией), и это сопоставление будет действовать вплоть до изменения состава кластера. При выборе режима привязки одного клиента алгоритм сопоставления использует полный IP-адрес клиента. Однако при выборе режима привязки адресов класса C алгоритм использует только часть адреса клиента, относящуюся к классу С (первые 24 разряда). Таким образом, все клиенты из одного адресного пространства класса С сопоставлены одному узлу кластера.
При сопоставлении клиентов узлам служба БНС не может непосредственно отслеживать границы сеансов (таких, как сеансы по протоколу SSL), поскольку решения о распределении нагрузки принимаются при установлении подключений TCP до поступления пакетов, содержащих данные сетевых приложений. Кроме того, служба не способна отслеживать границы потоков по протоколу UDP, поскольку границы логических сеансов определяются приложениями. Вместо этого параметры привязки службы БНС используются для поддержания сеансов клиентов. При сбое или отключении узла от кластера все подключения клиентов к нему разрываются. После определения нового состава кластера с помощью процедуры схождения (см. ниже) клиенты, которые были сопоставленные выбывшему узлу, сопоставляются одному из оставшихся узлов. При этом сбой не влияет на сеансы всех остальных клиентов, которых кластер продолжает бесперебойно обслуживать. Таким образом, алгоритм распределения нагрузки минимизирует перерывы в обслуживании клиентов при сбое.
При включении в кластер нового узла инициируется процедура схождения для учета нового члена кластера. После завершения схождения новому узлу сопоставляется минимум клиентов. Служба БНС отслеживает TCP-подключения к каждому узлу, и после завершения текущих подключений следующие подключения затрагиваемых клиентов будут обрабатываться новым узлом. Обработка UDP-потоков новым узлом начинается немедленно. Это может привести к разрыву некоторых клиентских сеансов, включающих несколько подключений или UDP-потоков. Следовательно, узлы необходимо добавлять в кластер в моменты, когда это приведет к разрыву минимального количества сеансов. Чтобы полностью устранить эту проблему, состояние сеансов должно управляться серверными приложениями, чтобы иметь возможность восстановить или возобновить сеанс с любого узла кластера. Например, состояние сеанса может передаваться серверу внутренней базы данных или сохраняться на стороне клиента в файлах cookie. Состояние SSL-сеансов восстанавливается автоматически путем повторной аутентификации клиента.
GRE-поток внутри протокола PPTP — это особый случай сеанса, на который не влияет добавление нового узла в кластер. Поскольку GRE-поток ограничен в пределах длительности управляющего TCP-сеанса, служба БНС отслеживает этот поток совместно с управляющим сеансом. Таким образом, предотвращается разрыв туннельного подключения PPTP при добавлении нового узла.
Схождение
Узлы кластера, работающего под управлением службы БНС, периодически обмениваются многоадресными или широковещательными ритмическими сообщениями. Это позволяет контролировать состояние кластера. При изменении состояния кластера (сбое, отключении или включении нового узла) служба БНС инициирует процесс, называемый схождением, при котором узлы обмениваются ритмическими сообщениями для определения нового узла, текущего состояния кластера и выбора узла с наиболее высоким приоритетом в качестве нового основного узла. При достижении узлами соглашения о текущем состоянии кластера изменения членства в кластере после схождения заносятся в журнал событий Windows 2000.
В процессе схождения узлы продолжают обрабатывать входящий поток данных в обычном режиме, за исключением запросов к вышедшему из строя узлу, которые временно не обслуживаются. Запросы клиентов к работающим узлам обрабатываются как обычно. Процедура схождения заканчивается, когда все узлы сообщают об одинаковом представлении состава кластера в течение нескольких циклов ритмических сообщений. При попытке включить в кластер узел с несогласованными правилами портов или со значением приоритета, которое уже используется одним из узлов, процедура схождения не будет завершена. Таким образом, предотвращается передача части потока данных кластера неправильно настроенному узлу.
После завершения схождения поток данных клиентов перераспределяется между оставшимися узлами. Если узел был добавлен в кластер, процедура схождения позволяет ему начать обработку своей части распределенной нагрузки сети. Расширение состава кластера не влияет на текущие операции и осуществляется полностью прозрачно как для удаленных клиентов, так и для серверных приложений. Однако оно может повлиять на подключения клиентов, поскольку в процессе расширения между подключениями клиенты могут быть сопоставлены другим узлам кластера (см. выше).
В одноадресном режиме ритмические сообщения рассылаются каждым узлом широковещательно, а в многоадресном режиме — многоадресно. Каждое ритмическое сообщение занимает один кадр Ethernet и помечено основным IP-адресом кластера, чтобы обеспечить возможность работы нескольких кластеров внутри одной подсети. Ритмическим сообщениям назначается либо настраиваемое значение, либо шестнадцатеричное значение 886F. По умолчанию период отправки ритмических сообщений равен одной секунде. Это значение можно изменить с помощью параметра реестра AliveMsgPeriod. При выполнении процедуры схождения для ускорения процесса период отправки сообщения снижается вдвое. Даже в больших кластерах полоса пропускания, занимаемая ритмическими сообщениями, крайне невелика (например, 24 КБ/с в 16-узловом кластере).
При работе службы БНС предполагается, что узел кластера функционирует правильно до тех пор, пока он участвует в обмене ритмическими сообщениями между узлами кластера. Если другие узлы не получают от одного из серверов ритмические сообщения в течение нескольких периодов обмена сообщениями, запускается процедура схождения. Количество пропущенных сообщений, после которого начинается схождение, по умолчанию равно пяти, однако его можно изменить с помощью параметра реестра AliveMsgTolerance.
При получении ритмического сообщения от нового узла или противоречивого сообщения, свидетельствующего о проблемах в распределении загрузки, процедура схождения запускается немедленно. После получения ритмического сообщения от нового узла каждый узел проверяет, не обрабатывают ли другие узлы запросы от тех же клиентов. Такая ситуация может возникать при объединении подсети кластера после разделения. Скорее всего, для нового узла уже было выполнено схождение в отделенном фрагменте и он не получает данных от клиентов. Такая ситуация возможна, если коммутатор вносит заметную задержку в подключение узла к подсети. Если узел кластера определяет эту проблему, а другой узел после последней процедуры схождения получил большее число подключений клиентов, он немедленно прекращает обработку клиентских данных для заданного диапазона портов. Поскольку оба узла обмениваются ритмическими сообщениями, узел, на который приходится большее количество подключений, продолжает обрабатывать запросы, а другой узел ожидает завершения схождения, чтобы начать обработку своей части нагрузки. Такой эвристический алгоритм устраняет возможные конфликты распределения загрузки при объединении разделенного ранее кластера. Данное событие заносится в журнал.
Удаленное управление
Механизм удаленного управления службой БНС использует протокол UDP по порту 2504. Его датаграммы отправляются на основной IP-адрес кластера. Поскольку датаграммы обрабатываются драйверами службы балансировки нагрузки на каждом узле кластера, они должны направляться в подсеть кластера (а не в подсеть, к которой подключен кластер). Команды удаленного управления, отдаваемые в пределах кластера, передаются в локальную подсеть кластера в виде



