- Команда sort в Linux с примерами
- Сохранить результат в другом файле
- Сортировка по номеру столбца
- Проверьте отсортированное состояние файла
- Отсортированные данные
- Удалить повторяющиеся элементы
- Сортировка с помощью конвейера в команде
- Случайная сортировка
- Сортировка данных из нескольких файлов
- Сортировать с присоединением
- Сравнить файлы с помощью сортировки
- Заключение
- Команда sort в Linux
- Синтаксис
- Опции
- Вывод результатов в файл
- Вывод результатов в обратном порядке
- Сортировка по заданным полям
- Удаление дублирующих записей
- Проверка сортировки
- Заключение
- Команда SORT в Linux / Unix с примерами
Команда sort в Linux с примерами
Команда SORT в Linux используется для упорядочивания записей в определенном порядке в соответствии с используемой опцией. Это помогает в сортировке данных в файле построчно. Команда SORT имеет разные функции, которым она следует в результате команд. Во-первых, строки с номерами будут предшествовать буквенным строкам. Строки с строчными буквами будут отображаться раньше, чем строки с тем же символом в верхнем регистре.
Предпосылка
Вам необходимо установить Ubuntu на виртуальный ящик и настроить его. Пользователи должны быть созданы, чтобы иметь права доступа к приложениям.
Синтаксис
Пример
Это простой пример сортировки файла, имеющего данные об именах. Эти имена расположены не по порядку, и для того, чтобы упорядочить их, вам необходимо их отсортировать.
Итак, рассмотрим файл с именем file1.txt. Мы отобразим содержимое файла с помощью добавленной команды:
Теперь используйте команду для сортировки текста в файле:
Сохранить результат в другом файле
Используя команду сортировки, вы узнаете, что ее результат только отображается, но не сохраняется. Чтобы зафиксировать результат, нам нужно его сохранить. Для этого используется опция —o в команде сортировки.
Рассмотрим пример имени sample1.txt с названиями автомобилей. Мы хотим отсортировать их и сохранить полученные данные в отдельном файле. Во время выполнения создается файл с именем result.txt, и в нем сохраняется соответствующий вывод. Данные из sample1.txt передаются в результирующий файл, а затем с помощью —o соответствующие данные сортируются. Мы отобразили данные с помощью команды cat:
$ sort –o result.txt sample1.txt
Вывод показывает, что данные отсортированы и сохранены в другом файле.
Сортировка по номеру столбца
Сортировка выполняется не только по одному столбцу. Мы можем отсортировать один столбец из-за второго столбца. Приведем пример текстового файла, в котором есть имена и оценки студентов. Мы хотим расположить их в порядке возрастания. Поэтому мы будем использовать в команде ключевое слово —k. В то время как —n используется для числовой сортировки.
Поскольку есть два столбца, поэтому 2 используется с n.
Проверьте отсортированное состояние файла
Если вы не уверены, отсортирован данный файл или нет, удалите это сомнение с помощью команды, которая проясняет путаницу и отображает сообщение. Мы рассмотрим два основных примера:
Теперь рассмотрим несортированный файл с названиями овощей.
В команде будет использоваться ключевое слово —c. Это проверит, отсортированы ли данные в файле или нет. Если данные не отсортированы, то вывод будет отображать номер строки первого слова, в котором присутствует несортированность, а также слово.
Из приведенного вывода вы можете понять, что 3- е слово в файле было неуместным.
Отсортированные данные
В этом случае, когда данные уже организованы, больше ничего делать не нужно. Рассмотрим файл result.txt.
Из результата вы можете видеть, что не отображается сообщение, указывающее на то, что данные в соответствующем файле уже отсортированы.
Удалить повторяющиеся элементы
Вот самый полезный вариант. Это помогает удалить повторяющиеся слова в файле и упорядочить элемент файла. Он также поддерживает согласованность данных в файле.
Представьте, что имя файла file2.txt содержит имена субъектов, но одна тема повторяется несколько раз. Затем команда сортировки будет использовать ключевое слово —u для удаления дублирования и родства:
Теперь вы можете видеть, что повторяющиеся элементы удаляются из вывода и что данные также сортируются.
Сортировка с помощью конвейера в команде
Если мы хотим отсортировать данные файла, предоставив список каталога относительно размеров файлов, мы включим все соответствующие данные каталога. ’Ls’ используется в команде, и -l отобразит его. Pipe поможет в упорядоченном отображении файлов.

Случайная сортировка
Иногда, выполняя какую-либо функцию, можно нарушить аранжировку. Если вы хотите расположить данные в любой последовательности и если нет критериев для сортировки, предпочтительнее случайная сортировка. Рассмотрим файл с именем sample3.txt, содержащий названия континентов.
Соответствующие выходные данные показывают, что файл отсортирован, а элементы расположены в другом порядке.
Сортировка данных из нескольких файлов
Одна из самых полезных команд сортировки — это одновременная сортировка данных из разных файлов. Это можно сделать с помощью команды find. Выходные данные команды find будут действовать как входные данные для команды после канала, который является командой сортировки. Ключевое слово Find используется для выдачи только одного файла в каждой строке, или мы можем сказать, что оно использует разрыв после каждого слова.
Например, давайте рассмотрим три файла с именами sample1.txt, sample2.txt и sample3.txt. Здесь «?» представляет собой любое число, за которым следует слово «образец». Find извлечет все три файла, и их данные будут отсортированы с помощью команды sort с инициативой pipe:
Выходные данные показывают, что данные всех файлов серии sample.txt отображаются и упорядочены в алфавитном порядке.

Сортировать с присоединением
Теперь мы представляем пример, который сильно отличается от тех, которые обсуждались ранее в этом руководстве. В дополнение к сортировке мы использовали join. Этот процесс выполняется таким образом, что оба файла сначала сортируются, а затем объединяются с помощью ключевого слова join.
Рассмотрим два файла, которые вы хотите объединить.
Теперь используйте приведенный ниже запрос, чтобы применить данную концепцию:
Из вывода видно, что данные обоих файлов объединены в отсортированном виде.
Сравнить файлы с помощью сортировки
Мы также можем принять концепцию сравнения двух файлов. Техника такая же, как и для стыковки. Сначала сортируются два файла, а затем данные в них сравниваются.
Рассмотрим те же два файла, что и в предыдущем примере. Sample2.txt и sample3.txt:
Данные сортируются и упорядочиваются поочередно. Начальная строка файла sample2.txt записывается рядом с первой строкой файла sample3.txt.
Заключение
В этой статье мы рассказали об основных функциях и параметрах команды сортировки. Команда сортировки Linux очень полезна для обслуживания данных и фильтрации всех бесполезных элементов из файлов.
Источник
Команда sort в Linux
sort – простая и очень полезная команда, которая меняет порядок строк в текстовом файле, то есть осуществляет их сортировку по алфавиту или в соответствии с числовыми значениями. По умолчанию правила сортировки следующие:
- строки, начинающиеся с цифр, выводятся раньше строк, начинающихся с букв;
- строки, начинающиеся с букв, выводятся в алфавитном порядке;
- строки, начинающиеся со строчных букв, выводятся раньше строк, начинающихся с таких же заглавных.
Правила сортировки можно изменять при помощи опций. Мы рассмотрим их ниже.
Синтаксис
Основной синтаксис команды следующий
Команда также может быть использована в составе конвейеров (пайпов). Например
Опции
Как видим, сейчас строки выводятся в том же порядке как и были записаны. Для его сортировки в алфавитном порядке выполните команду:
Вы получите следующий результат:
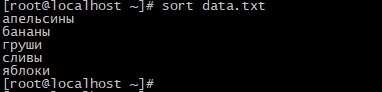
Как видим сейчас строки отсортированы в алфавитном порядке.
Вывод результатов в файл
Команда sort не изменяет исходный файл, а просто выводит его содержимое в отсортированном виде. Чтобы сохранить результаты сортировки, воспользуйтесь опцией -o или перенаправлением вывода:
Выведем файл output.txt:
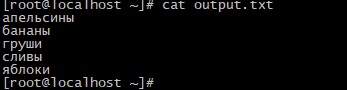
Вывод результатов в обратном порядке
Опция -r позволяет выводить результаты сортировки в обратном порядке:
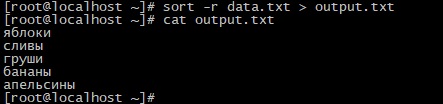
Сортировка по заданным полям
Для сортировки по определенным полям используется опция –k. Она указывается в следующем формате:
Где ПОЛЕ1 и т.д. – номер поля (столбца), по которому осуществляется сортировка. Для примера создадим новый файл prices.txt со следующим содержимым:
Для его сортировки по второму столбцу можно выполнить следующую команду:
Результат будет следующим
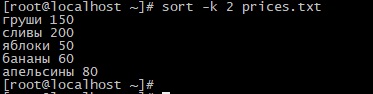
На первый взгляд кажется что команда сработала неправильно. Действительно, кажется что в самом верху должны стоять сливы, а яблоки нижней строкой, да и апельсины дороже банан. Но на самом деле команда sort воспринимает цифры не как число, а как строку, т.е сортировка происходит по первой цифре. Вот тогда все встает на свои места команда вывела последовательность не числовую сортировку «200-150-80-60-50» а строковую «1-2-5-6-8».
Опцию -k можно задавать в более сложном виде. Каждое поле задается в виде X.Y, где X – номер поля, а Y – начальная позиция поля, с которой начинается сортировка. Для примера создадим файл employee.txt со следующим содержимым:
Если просто указать номер поля, результат сортировки будет следующим:

Значение начальной позиции сортировки 4 заставит команду игнорировать первые 3 буквы и начнет сортировку с 4-й, т.е после «ст.» и «мл.»
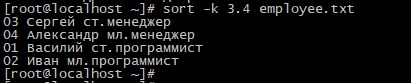
Удаление дублирующих записей
Опция -u удаляет из результатов дублирующие записи и выводит только уникальные поля. Допустим, у нас есть файл cars.txt со следующими данными:
Выведет следующий результат:
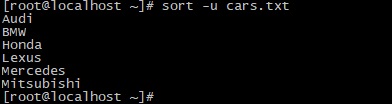
Проверка сортировки
Опция -с позволяет проверить, отсортированы ли данные в файле. Если выполнение команды с этой опцией не возвращает никакого результата, значит, строки файла уже упорядочены. Иначе будут выведены строки, нарушающие порядок сортировки. Допустим, файл cars2.txt содержит следующие данные:
Audi
Cadillac
BMW
Dodge
Для проверки выполним следующую команду:
Вот ее результат.
Мы видим, что строка «BMW» нарушает порядок сортировки:
Заключение
Команда sort – простой, но очень мощный и полезный при работе с данными инструмент. У нее есть множество разнообразных опций, помимо уже рассмотренных, которые можно узнать на соответствующей man-странице. Кроме того, ее можно использовать совместно с командами find и join для поиска по большому количеству файлов или объединения результатов.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Команда SORT в Linux / Unix с примерами
Команда SORT используется для сортировки файла, упорядочивая записи в определенном порядке. По умолчанию команда sort сортирует файл, предполагая, что его содержимое — ASCII. Используя опции в команде сортировки, она также может быть использована для числовой сортировки.
- Команда SORT сортирует содержимое текстового файла построчно.
- sort — это стандартная программа командной строки, которая печатает строки ввода или объединения всех файлов, перечисленных в списке аргументов, в отсортированном порядке.
- Команда sort — это утилита командной строки для сортировки строк текстовых файлов. Он поддерживает сортировку по алфавиту, в обратном порядке, по номеру, по месяцам, а также может удалять дубликаты.
- Команда sort также может сортировать элементы, находящиеся не в начале строки, игнорировать чувствительность к регистру и возвращать, отсортирован файл или нет. Сортировка выполняется на основе одного или нескольких ключей сортировки, извлеченных из каждой строки ввода.
- По умолчанию весь ввод принимается как ключ сортировки. Пробел является разделителем полей по умолчанию.
Команда sort следует этим функциям, как указано ниже:
- Строки, начинающиеся с цифры, появятся перед строками, начинающимися с буквы.
- Строки, начинающиеся с буквы, которая появляется раньше в алфавите, будут появляться перед строками, начинающимися с буквы, которая появляется позже в алфавите.
- Строки, начинающиеся со строчной буквы, появятся перед строками, начинающимися с той же буквы в верхнем регистре.
Примеры
Предположим, вы создали файл данных с именем file.txt
Сортировка файла: теперь используйте команду сортировки
Синтаксис:
Примечание. Эта команда фактически не меняет входной файл, то есть file.txt.
Функция сортировки с файлом микширования, то есть с заглавными и строчными буквами: если у нас есть файл микширования с прописными и строчными буквами, то сначала сортируются строчные буквы, а затем заглавные.
Пример:
Создайте файл mix.txt
Теперь используйте команду сортировки
Опции с функцией сортировки
- -o Опция: Unix также предоставляет нам специальные возможности, например, если вы хотите записать вывод в новый файл output.txt, перенаправить вывод, как это, или вы также можете использовать встроенную опцию сортировки -o, которая позволяет вам указать выходной файл.
Использование параметра -o функционально аналогично перенаправлению вывода в файл.
Примечание: ни один из них не имеет преимущества перед другим.
Пример: входной файл такой же, как указано выше.
Синтаксис:
-r Опция:сортировка в обратном порядке : вы можете выполнить сортировку в обратном порядке, используя флаг -r. флаг -r — это опция команды сортировки, которая сортирует входной файл в обратном порядке, то есть по убыванию по умолчанию.
Пример: входной файл такой же, как указано выше.
Синтаксис:
-n Опция: Для сортировки файла Численно используется опция -n. Опция -n также предопределена в unix, как и вышеупомянутые опции. Эта опция используется для сортировки файла с числовыми данными, присутствующими внутри.
Пример :
Давайте рассмотрим файл с номерами:
Опция -nr : для сортировки файла с числовыми данными в обратном порядке мы можем использовать комбинацию двух опций, как указано ниже.
Пример: числовой файл такой же, как указано выше.
Синтаксис:
-k Опция : Unix предоставляет возможность сортировки таблицы по любому номеру столбца с помощью опции -k.
Используйте опцию -k для сортировки по определенному столбцу. Например, используйте «-k 2» для сортировки по второму столбцу.
Пример :
Давайте создадим таблицу с 2 столбцами
Опция -c: эта опция используется, чтобы проверить, был ли данный файл уже отсортирован или нет & проверяет, отсортирован ли уже файл, передайте опцию -c для сортировки. Это приведет к записи в стандартный вывод, если есть строки, которые не в порядке. Инструмент сортировки может использоваться, чтобы понять, отсортирован ли этот файл и какие строки не в порядке.
Пример :
Предположим, существует файл со списком автомобилей с именем cars.txt.
Параметр -u: для сортировки и удаления дубликатов передайте параметр -u для сортировки. Это запишет отсортированный список в стандартный вывод и удалит дубликаты.
Эта опция полезна, так как удаляемые дубликаты дают нам избыточный файл.
Пример. Предположим, существует файл со списком автомобилей с именем cars.txt.
Параметр -M: для сортировки по месяцам укажите параметр -M для сортировки. Это запишет отсортированный список в стандартный вывод, упорядоченный по названию месяца.
Пример:
Предположим, что следующий файл существует и сохраняется как months.txt
февраль
январь
марш
августейший
сентябрь
Использование опции -M с сортировкой позволяет нам заказать этот файл.
Применение и использование команды сортировки
- Он может сортировать любой тип файла, будь то табличный файл, текстовый файл, числовой файл и так далее.
- Сортировка может быть осуществлена напрямую из одного файла в другой, не мешая текущей работе.
- Сортировка файлов таблиц по столбцам была упрощена и упрощена.
- Так много вариантов доступно для сортировки всеми возможными способами.
- Наиболее выгодное использование заключается в том, что конкретный файл данных может использоваться много раз, поскольку в предоставленном входном файле не вносятся никакие изменения.
- Исходные данные всегда безопасны и не мешают.
Эта статья предоставлена Мохаком Агравалом . Если вы как GeeksforGeeks и хотели бы внести свой вклад, вы также можете написать статью с помощью contribute.geeksforgeeks.org или по почте статьи contribute@geeksforgeeks.org. Смотрите свою статью, появляющуюся на главной странице GeeksforGeeks, и помогите другим вундеркиндам.
Пожалуйста, пишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по обсуждаемой выше теме.
Источник



