- Команда sort в Linux с примерами
- Сохранить результат в другом файле
- Сортировка по номеру столбца
- Проверьте отсортированное состояние файла
- Отсортированные данные
- Удалить повторяющиеся элементы
- Сортировка с помощью конвейера в команде
- Случайная сортировка
- Сортировка данных из нескольких файлов
- Сортировать с присоединением
- Сравнить файлы с помощью сортировки
- Заключение
- Сортировка файлов по имени linux
- Наши партнеры
- Вывод списка файлов с сортировкой
- Вывод директорий над файлами
- COREUTILS. Команда sort. Сортировка вывода программ
Команда sort в Linux с примерами
Команда SORT в Linux используется для упорядочивания записей в определенном порядке в соответствии с используемой опцией. Это помогает в сортировке данных в файле построчно. Команда SORT имеет разные функции, которым она следует в результате команд. Во-первых, строки с номерами будут предшествовать буквенным строкам. Строки с строчными буквами будут отображаться раньше, чем строки с тем же символом в верхнем регистре.
Предпосылка
Вам необходимо установить Ubuntu на виртуальный ящик и настроить его. Пользователи должны быть созданы, чтобы иметь права доступа к приложениям.
Синтаксис
Пример
Это простой пример сортировки файла, имеющего данные об именах. Эти имена расположены не по порядку, и для того, чтобы упорядочить их, вам необходимо их отсортировать.
Итак, рассмотрим файл с именем file1.txt. Мы отобразим содержимое файла с помощью добавленной команды:
Теперь используйте команду для сортировки текста в файле:
Сохранить результат в другом файле
Используя команду сортировки, вы узнаете, что ее результат только отображается, но не сохраняется. Чтобы зафиксировать результат, нам нужно его сохранить. Для этого используется опция —o в команде сортировки.
Рассмотрим пример имени sample1.txt с названиями автомобилей. Мы хотим отсортировать их и сохранить полученные данные в отдельном файле. Во время выполнения создается файл с именем result.txt, и в нем сохраняется соответствующий вывод. Данные из sample1.txt передаются в результирующий файл, а затем с помощью —o соответствующие данные сортируются. Мы отобразили данные с помощью команды cat:
$ sort –o result.txt sample1.txt
Вывод показывает, что данные отсортированы и сохранены в другом файле.
Сортировка по номеру столбца
Сортировка выполняется не только по одному столбцу. Мы можем отсортировать один столбец из-за второго столбца. Приведем пример текстового файла, в котором есть имена и оценки студентов. Мы хотим расположить их в порядке возрастания. Поэтому мы будем использовать в команде ключевое слово —k. В то время как —n используется для числовой сортировки.
Поскольку есть два столбца, поэтому 2 используется с n.
Проверьте отсортированное состояние файла
Если вы не уверены, отсортирован данный файл или нет, удалите это сомнение с помощью команды, которая проясняет путаницу и отображает сообщение. Мы рассмотрим два основных примера:
Теперь рассмотрим несортированный файл с названиями овощей.
В команде будет использоваться ключевое слово —c. Это проверит, отсортированы ли данные в файле или нет. Если данные не отсортированы, то вывод будет отображать номер строки первого слова, в котором присутствует несортированность, а также слово.
Из приведенного вывода вы можете понять, что 3- е слово в файле было неуместным.
Отсортированные данные
В этом случае, когда данные уже организованы, больше ничего делать не нужно. Рассмотрим файл result.txt.
Из результата вы можете видеть, что не отображается сообщение, указывающее на то, что данные в соответствующем файле уже отсортированы.
Удалить повторяющиеся элементы
Вот самый полезный вариант. Это помогает удалить повторяющиеся слова в файле и упорядочить элемент файла. Он также поддерживает согласованность данных в файле.
Представьте, что имя файла file2.txt содержит имена субъектов, но одна тема повторяется несколько раз. Затем команда сортировки будет использовать ключевое слово —u для удаления дублирования и родства:
Теперь вы можете видеть, что повторяющиеся элементы удаляются из вывода и что данные также сортируются.
Сортировка с помощью конвейера в команде
Если мы хотим отсортировать данные файла, предоставив список каталога относительно размеров файлов, мы включим все соответствующие данные каталога. ’Ls’ используется в команде, и -l отобразит его. Pipe поможет в упорядоченном отображении файлов.

Случайная сортировка
Иногда, выполняя какую-либо функцию, можно нарушить аранжировку. Если вы хотите расположить данные в любой последовательности и если нет критериев для сортировки, предпочтительнее случайная сортировка. Рассмотрим файл с именем sample3.txt, содержащий названия континентов.
Соответствующие выходные данные показывают, что файл отсортирован, а элементы расположены в другом порядке.
Сортировка данных из нескольких файлов
Одна из самых полезных команд сортировки — это одновременная сортировка данных из разных файлов. Это можно сделать с помощью команды find. Выходные данные команды find будут действовать как входные данные для команды после канала, который является командой сортировки. Ключевое слово Find используется для выдачи только одного файла в каждой строке, или мы можем сказать, что оно использует разрыв после каждого слова.
Например, давайте рассмотрим три файла с именами sample1.txt, sample2.txt и sample3.txt. Здесь «?» представляет собой любое число, за которым следует слово «образец». Find извлечет все три файла, и их данные будут отсортированы с помощью команды sort с инициативой pipe:
Выходные данные показывают, что данные всех файлов серии sample.txt отображаются и упорядочены в алфавитном порядке.

Сортировать с присоединением
Теперь мы представляем пример, который сильно отличается от тех, которые обсуждались ранее в этом руководстве. В дополнение к сортировке мы использовали join. Этот процесс выполняется таким образом, что оба файла сначала сортируются, а затем объединяются с помощью ключевого слова join.
Рассмотрим два файла, которые вы хотите объединить.
Теперь используйте приведенный ниже запрос, чтобы применить данную концепцию:
Из вывода видно, что данные обоих файлов объединены в отсортированном виде.
Сравнить файлы с помощью сортировки
Мы также можем принять концепцию сравнения двух файлов. Техника такая же, как и для стыковки. Сначала сортируются два файла, а затем данные в них сравниваются.
Рассмотрим те же два файла, что и в предыдущем примере. Sample2.txt и sample3.txt:
Данные сортируются и упорядочиваются поочередно. Начальная строка файла sample2.txt записывается рядом с первой строкой файла sample3.txt.
Заключение
В этой статье мы рассказали об основных функциях и параметрах команды сортировки. Команда сортировки Linux очень полезна для обслуживания данных и фильтрации всех бесполезных элементов из файлов.
Источник
Сортировка файлов по имени linux
Наши партнеры
Библиотека сайта rus-linux.net
НАЗВАНИЕ
sort — сортировка и/или слияние файлов
ОПИСАНИЕ
Команда sort сортирует строки, входящие во все исходные файлы, и выдает результат на стандартный вывод. Если имена файлов не указаны, или в качестве файла указан -, исходная информация поступает со стандартного ввода.
При упорядочении используется один или несколько ключей сортировки, выделяемых из каждой вводимой строки. По умолчанию ключ сортировки один — вся строка, а порядок является лексикографическим, соответствующим принятой кодировке символов.
Следующие опции изменяют стандартный порядок работы: -c Проверить, является ли (единственный) исходный файл уже отсортированным. На стандартный вывод ничего не выдается. В стандартный протокол выводится соответствующее сообщение только в случае нарушения упорядоченности строк.
-m Только слияние исходных файлов, которые предполагаются отсортированными.
-u Опция уникальности: из всех совпадающих строк выводить только одну.
-o выходной_файл Результат направляется не на стандартный вывод, а в выходной_файл, который может совпадать с одним из исходных.
-yкилобайт Количество дополнительной памяти, используемой командой sort, существенно влияет на скорость ее работы. Если опция -y отсутствует, sort начинает работу, используя область памяти некоторого стандартного размера, а в случае необходимости запрашивает дополнительную память. Если опция -y задана с аргументом, команда sort начинает работу, используя указанное число килобайт памяти, если только не нарушены ограничения сверху или снизу; в этом случае используется соответствующее крайнее значение. Таким образом, указание -y0 гарантирует использование минимального объема памяти. Опция -y без аргумента задает область памяти максимального размера.
-zдлина Во время сортировки запоминается размер самой длинной строки, так что для фазы слияния команда sort может отвести буфер нужного размера. Если, в силу действия опций -c или -m, фаза сортировки пропускается, используется некоторый стандартный размер. Наличие строк, превышающих по длине буфер, приводит к аварийному завершению команды. Задание заведомо достаточной длины гарантирует нормальное выполнение слияния.
Следующие опции позволяют выбрать нужный способ сравнения: -d «Словарный» порядок: при сравнении являются значимыми только буквы, цифры, пробелы и знаки табуляции.
-f Преобразовывать малые буквы в большие.
-i При нечисловых сравнениях игнорировать символы с (восьмеричными) кодами, не лежащими в пределах 040-0176.
-M Сравнивать как месяца. Первые три символа, отличные от пробела, сравниваются таким образом, что «JAN» -n Числовое сравнение. Начальные пробелы отбрасываются, затем цифровые цепочки символов, содержащие быть может знак минус и десятичную точку, сравниваются как числа. Эта опция включает опцию -b (см. ниже). Отметим, что опция -b действует только на ключи сортировки с наложенными ограничениями.
-r Заменить результат сравнения на противоположный.
Если опции, задающие способ сравнения, указаны до ограничений на ключи сортировки, то они применяются глобально ко всем ключам. Если же соответствующие флаги ассоциированы с определенными ключами сортировки (см. ниже), они воздействуют только на «свои» ключи.
Полем называется минимальная последовательность символов, за которой следует разделитель полей или перевод строки. По умолчанию символом-разделителем считается пробел или символ табуляции. Пробелы и табуляции сразу вслед за разделителем (если они есть) принадлежат следующему полю. Все пробелы в начале строки входят в первое поле. На трактовку разделителей влияют следующие опции: -b Игнорировать начальные пробелы при определении начала и конца ключей сортировки. Если опция -b указана перед первым аргументом +позиция_1, она действует на все ключи с наложенными ограничениями. Флаг b можно связать и с отдельными ключами сортировки (см. ниже).
-tразделитель Использовать заданный символ как разделитель полей. Разделитель не является частью поля (хотя и может входить в ключ сортировки). Каждое вхождение разделителя является значимым, то есть два рядом стоящих разделителя ограничивают пустое поле.
При наложении ограничения на ключ сортировки указывается позиция начала ключа (+позиция_1) и позиция сразу за концом ключа (-позиция_2). Если опция -позиция_2 отсутствует, ключ занимает весь остаток строки.
Позиция_1 и позиция_2 задаются как пара m.n, возможно, с последующими флагами bdfiMnr. Начальная позиция задается как +m.n, что означает (n+1)-ый символ в (m+1)-ом поле (поля и символы нумеруются с единицы). Отсутствие .n означает .0, то есть первый символ (m+1)-го поля. Если указан флаг b, то n отсчитывается от первого непробела в (m+1)-ом поле; +m.0b означает первый непробел в (m+1)-ом поле.
Позиция за концом ключа записывается как -m.n, что означает (n+1)-ый символ (включая разделители) после последнего символа m-го поля. Если .n опущено, то подразумевается .0, то есть разделитель после m-го поля. Если указан флаг b, то n отсчитывается от первого непробела в (m+1)-ом поле.
Если указано несколько ключей сортировки, то более поздние используются только в случае равенства более ранних. Если значения ключей сортировки двух строк совпадают, строки упорядочиваются с учетом всех символов.
ПРИМЕРЫ
- Отсортировать файл f1, используя в качестве ключа второе поле:
- Отсортировать по убыванию содержимое файлов f2 и f3, поместив результат в файл f4. Ключом сортировки служит первый символ второго поля:
- Отсортировать по убыванию содержимое файлов f5 и f6. Ключом сортировки служит первый непробел второго поля:
- Распечатать файл паролей [см. passwd], отсортировав его по числовым значениям идентификаторов пользователей (третье поле, поля разделяются символом :):
- Распечатать строки уже отсортированного файла f7, выводя лишь первую из строк с одинаковыми третьими полями:
Если в последней строке файла пропущен символ возврата каретки, то он добавляется автоматически, о чем выдается предупреждение.
ПРЕДОСТЕРЕЖЕНИЯ
Не гарантируется сохранение порядка следования строк с равными ключами.
Не оговаривается приоритет различных способов сравнения (например, числового и словарного), поэтому задавать комбинацию флагов dMn не имеет смысла.
Источник
Вывод списка файлов с сортировкой
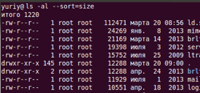 Поделюсь удобными параметрами команды ls для сортировки списка файлов. Команда ls предназначена для вывода списка файлов и директорий, но по умолчанию она сортирует список по имени.
Поделюсь удобными параметрами команды ls для сортировки списка файлов. Команда ls предназначена для вывода списка файлов и директорий, но по умолчанию она сортирует список по имени.
Для того, чтобы отсортировать список файлов используются следующие опции:
| Опция | Эквивалентная опция | Описание |
|---|---|---|
| -U | —sort=none | без сортировки |
| -X | —sort=extension | сортировка по расширению файла |
| -S | —sort=size | сортировка по размеру |
| -t | —sort=time | сортировка по времени изменения |
| -v | выполнять сортировку по версиям файлов | |
| -r | выполнять сортировку в обратном порядке |
Например, мы хотим отсортировать список по размеру файлов, тогда выполняем команду:
Это эквивалентно следующей команде:
Аналогично, например, если мы хотим получить список, отсортированный по расширению файлов:
Вывод директорий над файлами
Обычно команда ls выводит директории вперемешку с файлами. Некоторые реализации команды ls поддерживают полезную опцию: —group-directories-first. Если данная опция указана, то все директории будут выводится над списком файлов, что очень удобно.
Дополнительную информацию по команде ls вы можете получить, выполнив в терминале: man ls.
Источник
COREUTILS. Команда sort. Сортировка вывода программ
Скорее всего пакет coreutils у вас уже установлен, хотя бы потому, что удалить его нельзя, но на всякий случай проверьте:
dpkg -l | grep coreutils #для debian-based дистрибутивов
Если в первой колонке вывода будет стоять буква «i», означающая installed, значит все в порядке.
Пользоваться утилитой sort для сортировки вывода программ предельно просто. Для этого достаточно просто перенаправить вывод какой-либо программы на поток ввода sort:
Данная конструкция сначала вызовет команду ls, которая считает содержимое каталога, а затем передаст результат команде sort, которая отсортирует его по алфавиту (ключ -d указывает использовать алфавит в качестве шаблона).
Другой пример использования команды sort в linux — это сортировка содержимого файла. Отсортируем, например, строки, содержащиеся в файле /etc/passwd, с целью получения имен пользователей по алфавиту:
sort -d /etc/passwd
Но что делать, если вы хотите, используя тот же файл, отсортировать строки уже не по имени пользователя, а, например, по их уникальному идентификатору (UID)? Утилита sort умеет работать и с таблицами — сортировать по столбцу. Вернее изначально, sort как раз и работает с таблицами, вот только в качестве разделителя она по-умолчанию использует пробел и знак табуляции для разделения столбцов, знак переноса строки для разделения строк. Так как файл /etc/passwd использует «:» для разделения столбцов, то этот символ нужно передать sort при помощи ключа «-t» явно, а далее просто указать номер столбца с помощью ключа «-k». Но только ничего не получится, если опять же не указать шаблон. В данном случае нам понадобиться сортировать числа — поэтому вместо «-d» (по алфавиту) стаим -n (по числам). Вот, что получилось:
sort -n -t : -k 2,2 /etc/passwd
Внимательный читатель спросит: «Почему в качестве параметра ключа «-k» мы указали не просто номер столбца, а номер столбца через запятую с его же номером?». Ответ прост. Ключ «-k» очень мощный. Он позволяет гибко выбирать сортируемое поле. Используя предыдущий пример, немного изменим параметры ключа «-k»:
sort -n -t : -k 2.2,2.4 /etc/passwd
Добавив точку, мы тем самым сузили диапазон для проведения сортировки. Теперь команда расшифровывается так: отсортируй содержимое файл /etc/passwd, приняв в качестве исходных данных символ со второго по четвертый во 2-ом столбце.
Приведем еще один классный пример. Представим, что у нас закончилось место в разделе /home, и мы хотим узнать 10 самых объемных каталогов и файлов внутри /home с целью понять, куда копать:
du -a /home | sort -n | tail
Сначала командой du мы проходимся по всем файлам и подкаталогам /home, затем сортируем полученные строки по возрастанию и, наконец, tail’ом отображаем последние 10
На этом возможности команды soft не исчерпываются. Полезным может оказаться ключ «-r», позволяющий сортировать строки в обратном порядке. Его не стоит путать с ключом «-R», который совершенно случайным образом сортирует содержимое файла или вывода программы. Должно быть такая функция тоже кому-то будет полезной.
Также стоит обратить ваше внимание на ключ «-u», который заставляет sort выводит только уникальные значения. Т.е., если при сортировке выяснится, что сортируемые значения одинаковы, будет выведено только то, которое первым попало в поле зрения sort. Ключ «-u» не работает для значений, например «1» и » 1″ (один и пробел один), так как пробел тоже считается символом. Чтобы этого избежать применяют ключ «-b», позволяющий игнорировать пробелы перед сортируемой строкой.
Источник



