- Сортировка по нескольким полям linux
- Наши партнеры
- Команда sort в Linux
- Синтаксис
- Опции
- Вывод результатов в файл
- Вывод результатов в обратном порядке
- Сортировка по заданным полям
- Удаление дублирующих записей
- Проверка сортировки
- Заключение
- Примеры использования утилиты sort
- Принципы, по которым команда sort linux сортирует строки
- Пример сортировки и обратной сортировки
- Сортировка по колонке и по нескольким полям
- Использование sort для удаления дубликатов
- Попытка сортировать по двум полям, затем сначала
- 2 ответа
Сортировка по нескольким полям linux
Наши партнеры
Библиотека сайта rus-linux.net
НАЗВАНИЕ
sort — сортировка и/или слияние файлов
ОПИСАНИЕ
Команда sort сортирует строки, входящие во все исходные файлы, и выдает результат на стандартный вывод. Если имена файлов не указаны, или в качестве файла указан -, исходная информация поступает со стандартного ввода.
При упорядочении используется один или несколько ключей сортировки, выделяемых из каждой вводимой строки. По умолчанию ключ сортировки один — вся строка, а порядок является лексикографическим, соответствующим принятой кодировке символов.
Следующие опции изменяют стандартный порядок работы: -c Проверить, является ли (единственный) исходный файл уже отсортированным. На стандартный вывод ничего не выдается. В стандартный протокол выводится соответствующее сообщение только в случае нарушения упорядоченности строк.
-m Только слияние исходных файлов, которые предполагаются отсортированными.
-u Опция уникальности: из всех совпадающих строк выводить только одну.
-o выходной_файл Результат направляется не на стандартный вывод, а в выходной_файл, который может совпадать с одним из исходных.
-yкилобайт Количество дополнительной памяти, используемой командой sort, существенно влияет на скорость ее работы. Если опция -y отсутствует, sort начинает работу, используя область памяти некоторого стандартного размера, а в случае необходимости запрашивает дополнительную память. Если опция -y задана с аргументом, команда sort начинает работу, используя указанное число килобайт памяти, если только не нарушены ограничения сверху или снизу; в этом случае используется соответствующее крайнее значение. Таким образом, указание -y0 гарантирует использование минимального объема памяти. Опция -y без аргумента задает область памяти максимального размера.
-zдлина Во время сортировки запоминается размер самой длинной строки, так что для фазы слияния команда sort может отвести буфер нужного размера. Если, в силу действия опций -c или -m, фаза сортировки пропускается, используется некоторый стандартный размер. Наличие строк, превышающих по длине буфер, приводит к аварийному завершению команды. Задание заведомо достаточной длины гарантирует нормальное выполнение слияния.
Следующие опции позволяют выбрать нужный способ сравнения: -d «Словарный» порядок: при сравнении являются значимыми только буквы, цифры, пробелы и знаки табуляции.
-f Преобразовывать малые буквы в большие.
-i При нечисловых сравнениях игнорировать символы с (восьмеричными) кодами, не лежащими в пределах 040-0176.
-M Сравнивать как месяца. Первые три символа, отличные от пробела, сравниваются таким образом, что «JAN» -n Числовое сравнение. Начальные пробелы отбрасываются, затем цифровые цепочки символов, содержащие быть может знак минус и десятичную точку, сравниваются как числа. Эта опция включает опцию -b (см. ниже). Отметим, что опция -b действует только на ключи сортировки с наложенными ограничениями.
-r Заменить результат сравнения на противоположный.
Если опции, задающие способ сравнения, указаны до ограничений на ключи сортировки, то они применяются глобально ко всем ключам. Если же соответствующие флаги ассоциированы с определенными ключами сортировки (см. ниже), они воздействуют только на «свои» ключи.
Полем называется минимальная последовательность символов, за которой следует разделитель полей или перевод строки. По умолчанию символом-разделителем считается пробел или символ табуляции. Пробелы и табуляции сразу вслед за разделителем (если они есть) принадлежат следующему полю. Все пробелы в начале строки входят в первое поле. На трактовку разделителей влияют следующие опции: -b Игнорировать начальные пробелы при определении начала и конца ключей сортировки. Если опция -b указана перед первым аргументом +позиция_1, она действует на все ключи с наложенными ограничениями. Флаг b можно связать и с отдельными ключами сортировки (см. ниже).
-tразделитель Использовать заданный символ как разделитель полей. Разделитель не является частью поля (хотя и может входить в ключ сортировки). Каждое вхождение разделителя является значимым, то есть два рядом стоящих разделителя ограничивают пустое поле.
При наложении ограничения на ключ сортировки указывается позиция начала ключа (+позиция_1) и позиция сразу за концом ключа (-позиция_2). Если опция -позиция_2 отсутствует, ключ занимает весь остаток строки.
Позиция_1 и позиция_2 задаются как пара m.n, возможно, с последующими флагами bdfiMnr. Начальная позиция задается как +m.n, что означает (n+1)-ый символ в (m+1)-ом поле (поля и символы нумеруются с единицы). Отсутствие .n означает .0, то есть первый символ (m+1)-го поля. Если указан флаг b, то n отсчитывается от первого непробела в (m+1)-ом поле; +m.0b означает первый непробел в (m+1)-ом поле.
Позиция за концом ключа записывается как -m.n, что означает (n+1)-ый символ (включая разделители) после последнего символа m-го поля. Если .n опущено, то подразумевается .0, то есть разделитель после m-го поля. Если указан флаг b, то n отсчитывается от первого непробела в (m+1)-ом поле.
Если указано несколько ключей сортировки, то более поздние используются только в случае равенства более ранних. Если значения ключей сортировки двух строк совпадают, строки упорядочиваются с учетом всех символов.
ПРИМЕРЫ
- Отсортировать файл f1, используя в качестве ключа второе поле:
- Отсортировать по убыванию содержимое файлов f2 и f3, поместив результат в файл f4. Ключом сортировки служит первый символ второго поля:
- Отсортировать по убыванию содержимое файлов f5 и f6. Ключом сортировки служит первый непробел второго поля:
- Распечатать файл паролей [см. passwd], отсортировав его по числовым значениям идентификаторов пользователей (третье поле, поля разделяются символом :):
- Распечатать строки уже отсортированного файла f7, выводя лишь первую из строк с одинаковыми третьими полями:
Если в последней строке файла пропущен символ возврата каретки, то он добавляется автоматически, о чем выдается предупреждение.
ПРЕДОСТЕРЕЖЕНИЯ
Не гарантируется сохранение порядка следования строк с равными ключами.
Не оговаривается приоритет различных способов сравнения (например, числового и словарного), поэтому задавать комбинацию флагов dMn не имеет смысла.
Источник
Команда sort в Linux
sort – простая и очень полезная команда, которая меняет порядок строк в текстовом файле, то есть осуществляет их сортировку по алфавиту или в соответствии с числовыми значениями. По умолчанию правила сортировки следующие:
- строки, начинающиеся с цифр, выводятся раньше строк, начинающихся с букв;
- строки, начинающиеся с букв, выводятся в алфавитном порядке;
- строки, начинающиеся со строчных букв, выводятся раньше строк, начинающихся с таких же заглавных.
Правила сортировки можно изменять при помощи опций. Мы рассмотрим их ниже.
Синтаксис
Основной синтаксис команды следующий
Команда также может быть использована в составе конвейеров (пайпов). Например
Опции
Как видим, сейчас строки выводятся в том же порядке как и были записаны. Для его сортировки в алфавитном порядке выполните команду:
Вы получите следующий результат:
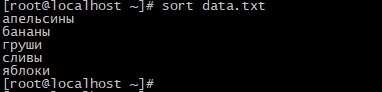
Как видим сейчас строки отсортированы в алфавитном порядке.
Вывод результатов в файл
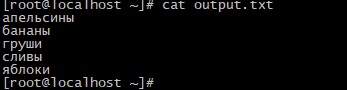
Команда sort не изменяет исходный файл, а просто выводит его содержимое в отсортированном виде. Чтобы сохранить результаты сортировки, воспользуйтесь опцией -o или перенаправлением вывода:
Выведем файл output.txt:
Вывод результатов в обратном порядке
Опция -r позволяет выводить результаты сортировки в обратном порядке:
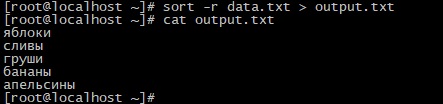
Сортировка по заданным полям
Для сортировки по определенным полям используется опция –k. Она указывается в следующем формате:
Где ПОЛЕ1 и т.д. – номер поля (столбца), по которому осуществляется сортировка. Для примера создадим новый файл prices.txt со следующим содержимым:
Для его сортировки по второму столбцу можно выполнить следующую команду:
Результат будет следующим
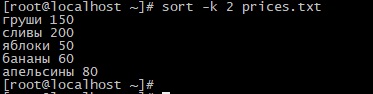
На первый взгляд кажется что команда сработала неправильно. Действительно, кажется что в самом верху должны стоять сливы, а яблоки нижней строкой, да и апельсины дороже банан. Но на самом деле команда sort воспринимает цифры не как число, а как строку, т.е сортировка происходит по первой цифре. Вот тогда все встает на свои места команда вывела последовательность не числовую сортировку «200-150-80-60-50» а строковую «1-2-5-6-8».
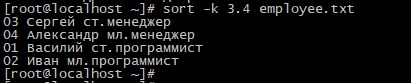
Опцию -k можно задавать в более сложном виде. Каждое поле задается в виде X.Y, где X – номер поля, а Y – начальная позиция поля, с которой начинается сортировка. Для примера создадим файл employee.txt со следующим содержимым:
Если просто указать номер поля, результат сортировки будет следующим:

Значение начальной позиции сортировки 4 заставит команду игнорировать первые 3 буквы и начнет сортировку с 4-й, т.е после «ст.» и «мл.»
Удаление дублирующих записей
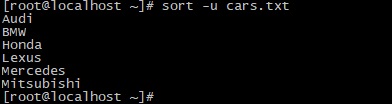
Опция -u удаляет из результатов дублирующие записи и выводит только уникальные поля. Допустим, у нас есть файл cars.txt со следующими данными:
Выведет следующий результат:
Проверка сортировки
Опция -с позволяет проверить, отсортированы ли данные в файле. Если выполнение команды с этой опцией не возвращает никакого результата, значит, строки файла уже упорядочены. Иначе будут выведены строки, нарушающие порядок сортировки. Допустим, файл cars2.txt содержит следующие данные:
Audi
Cadillac
BMW
Dodge
Для проверки выполним следующую команду:
Вот ее результат.
Мы видим, что строка «BMW» нарушает порядок сортировки:
Заключение
Команда sort – простой, но очень мощный и полезный при работе с данными инструмент. У нее есть множество разнообразных опций, помимо уже рассмотренных, которые можно узнать на соответствующей man-странице. Кроме того, ее можно использовать совместно с командами find и join для поиска по большому количеству файлов или объединения результатов.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Примеры использования утилиты sort
sort — UNIX‐ утилита, сортирует содержимое указанных файлов, с учётом установленной в среде переменных локализации.
Утилиту sort можно использовать для сортировки текста из одного или нескольких файлов или c помощью нее может быть выполнена сортировка вывода linux для какой-либо команды, например использования утилиты sort для обнаружения DoS-атак.
Принципы, по которым команда sort linux сортирует строки
Пример сортировки и обратной сортировки
Прямая сортировка файл, по принципам описанным выше, происходит по умолчанию. Просто вызовите команду sort и укажите нужный файл. Например, мы хотим отсортировать по алфавиту файл служб Linux (/etc/services), который хранит информацию о многочисленных службах, которые клиентские приложения могут использовать на компьютере. Внутри файла services находятся имя службы, номер порта и протокол, который он использует, и любые применимые псевдонимы.
Для обратной сортировки используйте ключ r, команда будет выглядеть так:
Сортировка по колонке и по нескольким полям
В этом примере мне нужно вывести все лог файлы и отсортировать их по колонке с названием месяца. Колонка указывается опцией -k, номер колонки для вывода команды ls седьмой. Итого получим такую команду для запуска:
Для сортировки по числовому значению используется опция -n:
Мы можем сортировать данные по нескольким полям, например, отсортируем вывод ls по второму первично и вторично девятому полях:
Использование sort для удаления дубликатов
Команда sort Linux позволяет не только сортировать строки, но и удалять дубликаты, для этого есть опция -u.
Источник
Попытка сортировать по двум полям, затем сначала
Я пытаюсь сортировать по нескольким столбцам. Результаты не ожидаются.
Вот мои данные (people.txt):
Правильно работает следующее:
Но следующее не работает должным образом:
Я пытался сортировать по фамилии, а затем по имени, но вы увидите, что Villamors не в правильном порядке. Я надеялся сортировать по фамилии, а затем, когда фамилии совпадали, сортировать по имени.
Кажется, что-то о том, как это должно работать, я не понимаю. Я мог бы сделать это другим способом (используя awk), но я хочу понять, как это сделать.
Я использую стандартную оболочку Bash в Mac OS X.
2 ответа
Ключевая спецификация, такая как -k2 , означает учет всех полей от 2 до конца строки. Поэтому Villamor 44 заканчивается до Villamor 50 . Поскольку эти два не равны, первое сравнение в sort -k2 -k1 достаточно, чтобы различать эти две строки, а второй ключ сортировки -k1 не вызывается. Если у двух Villamors был одинаковый возраст, -k1 заставил бы их сортировать по имени.
Чтобы сортировать по одному столбцу, используйте -k2,2 как спецификацию ключа. Это означает использование полей от # 2 до # 2, т. Е. Только второе поле.
является избыточным: он эквивалентен sort -k2
. Чтобы отсортировать фамилии, затем имена, затем возраст, запустите
или эквивалентно sort -k2,2 -k1
, поскольку есть только эти три поля и разделители одинаковы. Фактически, вы получите тот же эффект от sort -k2,2
, потому что sort использует всю строку в качестве последнего средства, когда все ключи в подмножество строк идентично.
Также обратите внимание, что разделитель полей по умолчанию — это переход между непустым и пустым, поэтому ключи будут содержать ведущие пробелы (в вашем примере для первой строки первый ключ будет «Emily» , но второй ключ » Bedford» . Добавьте опцию -b , чтобы снять эти пробелы:
Это также можно сделать с помощью каждой клавиши, добавив флаг b в конце спецификации запуска ключа:
Но что-то иметь в виду: как только вы добавляете один такой флаг в спецификацию ключа, глобальные флаги (например, -n , -r ) ) больше не применяются к ним, поэтому лучше избегать смешивания флажков с ключами и глобальных флагов.
С GNU sort вы делаете это так, не уверены в MacOS:
Обновить в соответствии с комментарием. Цитируется из man sort :
Источник



