Первое, что мы узнаем об SQL – это как писать выражения SELECT для выборки данных из таблицы. Такие выражения выглядят просто и очень похоже на обычный разговорный язык.
Но настоящие запросы зачастую гораздо сложнее, чем простые выражения SELECT.
Во-первых, нужные данные обычно разбиты на несколько разных таблиц. Это естественное следствие нормализации данных, которая является характерным свойством любой хорошо спланированной модели БД. SQL позволяет объединить эти данные.
В прошлом администраторы БД и разработчики помещали все нужные таблицы и/или представления в оператор FROM, а затем использовали оператор WHERE, чтобы определить, как должны комбинироваться записи из одной таблицы с записями из другой (чтобы сделать этот текст чуть-чуть более читаемым, я в дальнейшем буду писать просто «таблица», а не «таблица и/или представление»).
Однако, чтобы стандартизовать объединение данных, понадобилось довольно много времени. Это было сделано с помощью оператора JOIN (ANSI-SQL 92). К сожалению, некоторые детали использования оператора JOIN так и остаются неизвестными очень многим.
Прежде чем показать различный синтаксис JOIN, поддерживаемый T-SQL (в SQL Server 2008), я опишу несколько концепций, которые не следует забывать при любом соединении данных из двух или нескольких таблиц.
Начало: одна таблица, никакого JOIN
Если запрос обращается только к одному объекту, синтаксис будет очень простым, и никакое соединение не потребуется. Выражение будет старым добрым » SELECT fields FROM object » с другими необязательными операторами (то есть WHERE, GROUP BY, HAVING или ORDER BY).
Однако конечные пользователи не знают, что администраторы БД обычно прячут множество сложных соединений за одним красивым и простым в использовании представлением. Это делается по разным причинам, от безопасности данных до производительности БД. Например, администратор может дать конечному пользователю разрешение на доступ к одному представлению вместо нескольких рабочих таблиц, что, очевидно, повышает сохранность данных. А если говорить о производительности, можно создать представление, используя правильные параметры для соединения записей из разных таблиц, правильно использовать индексы и тем самым повысит производительность запроса.
Как бы то ни было, соединения в БД всегда есть, даже если конечный пользователь их и не видит.
Логика, стоящая за соединением таблиц
Много лет назад, когда я начинал работать с SQL, я узнал, что есть несколько типов соединения данных. Но мне потребовалось некоторое время, чтобы точно понять, что я делаю, соединяя таблицы. Возможно из-за того, что люди боятся математики, не часто можно услышать, что вся идея соединений таблиц – это теория множеств. Несмотря на заковыристое название, концепция так проста, что изучается в начальной школе.
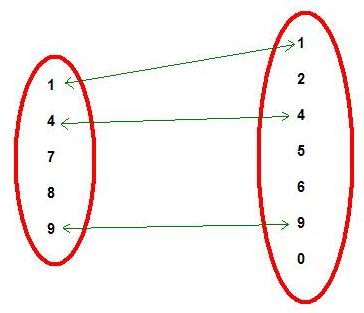
Рисунок 1 очень похож на картинки из учебника для первого класса. Идея в том, чтобы найти в разных множествах соответствующие объекты. Это как раз то, чем занимается JOIN в SQL!
Рисунок 1. Комбинируем объекты из разных множеств.
Если вы поняли эту аналогию, все становится более осмысленным.
Представьте, что 2 множества на рисунке 1 – это таблицы, а цифры – это ключи, используемые для соединения таблиц. Таким образом, в каждом из множеств вместо целой записи мы видим только ключевые поля каждой таблицы. Результирующий набор комбинаций будет определяться типом используемого соединения, и это я как раз и собираюсь показать. Чтобы проиллюстрировать примеры, возьмем 2 таблицы, показанные ниже:
Таблица Table1
Скрипт для создания и заполнения таблиц приведен ниже:
Как можно заметить, этот скрипт не полностью обеспечивает ссылочную целостность. Я намеренно оставил таблицы без внешних ключей, чтобы лучше объяснить функциональность разных типов JOIN. Но я сделал это исключительно в целях обучения. Внешние ключи крайне полезны для обеспечения непротиворечивости данных, и их нельзя исключить ни из одной реальной БД.
Теперь мы готовы. Давайте рассмотрим типы JOIN, имеющиеся в T-SQL, их синтаксис и результаты, генерируемые ими.
INNER JOIN
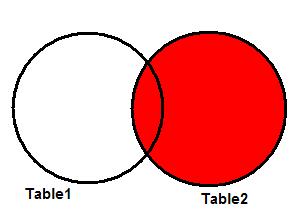
Это наиболее часто используемое в SQL соединение. Оно возвращает пересечение двух множеств. В терминах таблиц, оно возвращает только записи из обеих таблиц, отвечающие указанному критерию.
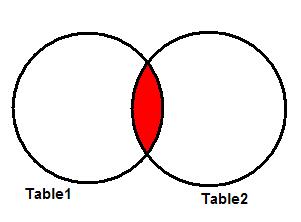
На рисунке 2 показана диаграмма Венна, иллюстрирующая пересечение двух таблиц. Результат операции – закрашенная область.
Рисунок 2. INNER JOIN.
Теперь посмотрите на синтаксис объединения данных из таблиц Table1 и Table2 с использованием INNER JOIN.
Вот набор результатов, возвращаемый этим выражением:
Заметьте, что выдаются только данные из записей, имеющих одинаковые значения key2 в таблицах Table1 и Table2 .
Противоположностью INNER JOIN является OUTER JOIN. Существует три типа OUTER JOIN – полный, левый и правый. Рассмотрим каждый из них.
FULL JOIN
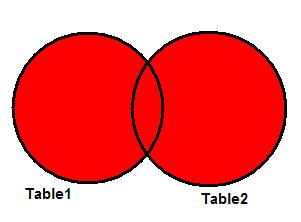
Полностью это соединение называется FULL OUTER JOIN (зарезервированное слово OUTER необязательно). FULL JOIN работает как объединение двух множеств. На рисунке 3 показана диаграмма Венна для FULL JOIN двух таблиц. Результатом операции опять же является закрашенная область.
Рисунок 3. FULL JOIN.
Синтаксис почти такой же, как показанный выше:
Набор результатов, возвращаемых этим выражением, выглядит так:
FULL JOIN возвращает все записи из таблиц Table1 и Table2 , без повторяющихся данных.
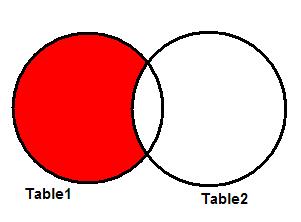
LEFT JOIN
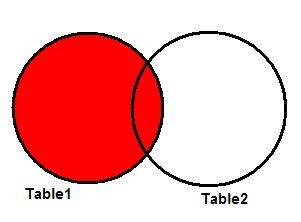
Также известен как LEFT OUTER JOIN, и является частным случаем FULL JOIN. Дает все запрошенные данные из таблицы в левой части JOIN плюс данные из правой таблицы, пересекающиеся с первой таблицей. На рисунке 4 показана диаграмма Венна, иллюстрирующая LEFT JOIN для двух таблиц.
Рисунок 4. LEFT JOIN.
Результатом этого выражения будет:
Третья и четвертая записи ( key1 равен 6 и 7) содержат NULL-значения в последнем поле, потому что для них нет информации из второй таблицы. Это значит, что у нас есть значение в поле key2 в Table1 , но нет соответствующего ему значения в Table2 .
RIGHT JOIN
Также известен как RIGHT OUTER JOIN, и является еще одним частным случаем FULL JOIN. Он выдает все запрошенные данные из таблицы, стоящей в правой части оператора JOIN, плюс данные из левой таблицы, пересекающиеся с правой. Диаграмма Венна для RIGHT JOIN двух таблиц показана на рисунке 5.
Рисунок 5. RIGHT JOIN.
Как видите, синтаксис очень похож на показанный выше:
Результатом этого выражения будет:
Как видите, теперь записи с key1 , равным 6 и 7, отсутствуют в результатах, потому что для них нет соответствующих записей в правой таблице. Четыре записи содержат NULL в первом поле, поскольку для них нет данных в левой таблице.
CROSS JOIN
CROSS JOIN – это на самом деле Декартово произведение. При использовании CROSS JOIN генерируется точно тот же результат, что и при вызове двух таблиц (разделенных запятой) без всякого JOIN вообще. Это значит, что мы получим огромный набор результатов, где каждая запись из Table1 будет дублирована для каждой записи из Table2 . Если в Table1 содержится N1 записей, а в Table2 – N2 записей, в результате будет N1 х N2 записей.
Я не верю, что есть какой-то способ представить этот результат в виде диаграммы Венна. Я предполагаю, что это должно быть трехмерное изображение. Если это действительно так, то диаграмма будет более запутывающей, чем объяснение.
Синтаксис CROSS JOIN таков:
Поскольку в Table1 содержится 5 записей, а в Table2 – еще 7, результат этого запроса будет содержать 35 записей (5 x 7).
Совершенно честно, я не могу сейчас припомнить ни одной реальной ситуации, когда мне понадобилось бы сгенерировать декартово произведение двух таблиц. Но если оно вам понадобится, есть CROSS JOIN.
Кроме всего прочего, стоит подумать и о производительности. Допустим, что вы случайно запустили на рабочем сервере запрос, содержащий CROSS JOIN для двух таблиц по миллиону записей в каждой. Это, несомненно, добавит вам головной боли. Возможно, у вашего сервера начнутся проблемы с производительностью, поскольку это запрос будет исполняться долго, и потреблять при этом существенное количество ресурсов сервера.
SELF JOIN
Оператор JOIN можно использовать для комбинирования любой пары таблиц, включая комбинацию таблицы с самой собой. Это и есть «SELF JOIN».
Посмотрите на классический пример, возвращающий имя начальника сотрудника (по таблице 1). В этом примере мы полагаем, что значение в field2 – фактически кодовый номер босса, следовательно, он связан с key1.
А вот результат запроса:
Последняя запись в данном примере показывает, что у Гарри нет начальника, другими словами, он №1 в иерархии компании.
Исключение пересечения множеств
Посмотрев на последнюю диаграмму Венна из приведенных выше, можно задаться простым вопросом: что, если мне нужны все записи из Table1, кроме тех, для которых есть соответствующие записи в Table2 . Что ж, это крайне полезно в повседневной работе, но для этого, очевидно, не нужен особый оператор JOIN.
Рисунок 6. Непересекающиеся записи в Таблице 1.
Посмотрите на предыдущие наборы результатов, и вы увидите, что нужно всего лишь добавить в SQL-запрос оператор WHERE, чтобы найти записи, содержащие NULL в ключе Table2 . Это даст нам набор результатов, соответствующий диаграмме Венна, показанной на рисунке 6.
Можно в этом запросе написать LEFT JOIN, например:
И, наконец, набор результатов будет выглядеть так:
При выполнении таких запросов нужно правильно выбирать поле для оператора WHERE. Нужно использовать поле, не допускающее NULL-значений. В противном случае набор результатов может содержать ненужные записи. Поэтому я и предложил использовать ключ второй таблицы, точнее, ее первичный ключ. Поскольку первичные ключи не могут содержать NULL-значения, это гарантирует, что набор результатов будет таким, как и предполагалось.
Слово о планах исполнения
По ходу действия мы подошли к важному моменту. Обычно мы не задумываемся об этом, но нужно знать, что планы исполнения SQL-запросов сперва вычисляют результат операторов FROM и JOIN (если таковой имеется), а только затем исполняют оператор WHERE.
Это верно как для SQL Server, так и для любой другой РСУБД.
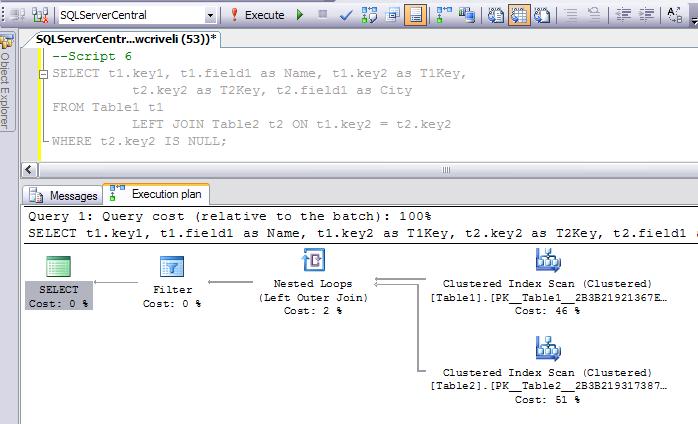
Базовое понимание работы SQL важно для любого администратора БД или разработчика. Это помогает в работе. Если вам интересно, посмотрите на план выполнения запроса, приведенного выше (рисунок 7).
Рисунок 7. План исполнения запроса, использующего LEFT JOIN.
JOIN и индексы
Посмотрите еще раз на план исполнения запроса. Заметьте, он использует кластерные индексы для обеих таблиц. Использование индексов – лучший способ ускорить выполнение запросов. Но нужно обращать внимание на ряд деталей.
При создании запросов мы ожидаем, что SQL Server Query Optimizer будет использовать индексы таблиц для увеличения производительности. Мы также можем помочь Query Optimizer-у выбрать индексированные поля, являющиеся частью запроса.
Например, при использовании оператора JOIN, идеальный подход состоит в том, чтобы соединение основывалось на индексированных полях. Посмотрев в план исполнения, можно заметить, что используется кластерный индекс для Table2 . Этот индекс был автоматически создан по key2 при создании таблицы, поскольку key2 – это первичный ключ этой таблицы.
С другой стороны, таблица Table1 не индексирована по полю key2 . Из-за этого оптимизатор запросов пытается быть умным и увеличить производительность запроса к key2, используя единственный доступный индекс. Это табличный кластерный индекс, основанный на key1 , первичном ключе Table1 . Как видите, оптимизатор запросов – действительно умное средство. Но вы сильно поможете ему, если создадите новый (некластерный) индекс по key2 .
Если не забывать о ссылочной целостности, поле key2 должно быть внешним ключом Table1 , поскольку оно связано с другим полем другой таблицы (то есть Table2.key2 ).
Лично я считаю, что внешние ключи должны присутствовать во всех реальных моделях БД. Причем это хорошая идея – создавать некластерные индексы для всех внешних ключей. Вы всегда будете исполнять множество запросов, а также использовать оператор JOIN, основываясь на первичных и внешних ключах.
Важно: SQL Server автоматически создает кластерный индекс для первичных ключей. Однако по умолчанию он ничего не делает с внешними ключами. Проверьте, что ваша СУБД настроена надлежащим образом.
Неравенства
При создании SQL-запросов, использующих оператор JOIN, мы обычно сравниваем, равно ли одно поле одной таблицы другому полю другой таблицы. Но это не обязательный синтаксис. Можно использовать любой логический оператор, например, «не равно» (<>), «больше» (>), «меньше» ( Table1 , ту, у которой key1 равен 3. Проблема в том, что есть 6 записей и Table2, удовлетворяющая условиям соединения. Посмотрите на результат запроса:
Источник
SQL Tutorial
SQL is a standard language for storing, manipulating and retrieving data in databases.
Our SQL tutorial will teach you how to use SQL in: MySQL, SQL Server, MS Access, Oracle, Sybase, Informix, Postgres, and other database systems.
Examples in Each Chapter
With our online SQL editor, you can edit the SQL statements, and click on a button to view the result.
Example
Click on the «Try it Yourself» button to see how it works.
SQL Exercises
SQL Examples
Learn by examples! This tutorial supplements all explanations with clarifying examples.
SQL Quiz Test
Test your SQL skills at W3Schools!
SQL References
At W3Schools you will find a complete reference for keywords and function:
SQL Data Types
Data types and ranges for Microsoft Access, MySQL and SQL Server.
SQL Exam — Get Your Diploma!
Kickstart your career
Get certified by completing the course
We just launched W3Schools videos
COLOR PICKER
LIKE US
Get certified by completing a course today!
CODE GAME
Report Error
If you want to report an error, or if you want to make a suggestion, do not hesitate to send us an e-mail:
Thank You For Helping Us!
Your message has been sent to W3Schools.
Top Tutorials
Top References
Top Examples
Web Courses
W3Schools is optimized for learning and training. Examples might be simplified to improve reading and learning. Tutorials, references, and examples are constantly reviewed to avoid errors, but we cannot warrant full correctness of all content. While using W3Schools, you agree to have read and accepted our terms of use, cookie and privacy policy.
 Home
Home  Home
Home  �����
�����  �������
�������  ��������
��������