- Работа с «плохими» файлами в командной строке в Linux
- В названии файла есть служебный символ bash
- Имя файла начинается с дефиса
- Удаляем по wildcard
- Файлы с управляющим символом в названии
- Удаление файлов с символами utf8
- Перекодировка имени файла
- Автокомплит
- Удаляем файл через меню выбора
- Удаление по номеру inode
- Удаление по hex-коду
- How To: Configure TABs in SQL Developer
- Open the preferences, go to the Database page.
- Click on the ‘Edit’ button next to the profile dropdown control
- Go to the Indentation page and inspect the ‘Spaces’ property
- Update: Version 4.2 and Higher
- Почему ошибка при компилации?
- SQL Tabs for Mac
- Review
- Free Download
- specifications
- Minimalist and multi-platform SQL client for designed to help you explore, query and run scripts on MySQL, MariaDB, Postgresql, Amazon Redshift, MS SQL, and AlaSQL databases
- What’s new in SQL Tabs 1.0.0:
- Streamlined database managing workflow for experienced users
- Explore and query the most popular databases, from MySQL to MS SQL and Amazon Redshift
- Feature packed and minimalist cross-platform SQL client
- Символы Unicode: о чём должен знать каждый разработчик
- Введение в кодировку
- Краткая история кодировки
- Проблемы с ASCII
- Что такое кодовые страницы ASCII?
- Безумие какое-то.
- Так появился Unicode
- Unicode Transform Protocol (UTF)
- Что такое UTF-8 и как она работает?
- Напоследок про UTF
- Это всё?
- Заключение
Работа с «плохими» файлами в командной строке в Linux
При работе в командной строке администраторы часто сталкиваются с необходимостью что-то сделать с определенным файлом: удалить, переместить, скопировать. При выполнении подобных задач зачастую приходится обращаться к файлам по имени, что может быть затруднительно, поскольку в именах файлов могут встречаться самые разные символы. Даже те, которых нет на клавиатуре. В этом плане работу может облегчить файловый менеджер, в котором файл можно просто выделить и совершить с ним нужное действие. Но для тех, кто привык работать исключительно в командной строке, предлагаются следующие способы.
В качестве shell-оболочки рассмотрим bash, как самую используемую. А в качестве операции над файлами рассмотрим удаление, как самую деструктивную.
Ситуации могут быть разными. В текущей директории могут быть файлы, которые нужно удалить вместе с теми, которые нужно оставить. Имена у них могут быть самыми разными. Причем первые от последних могут отличаться только одним каким-нибудь заковыристым символом.
В названии файла есть служебный символ bash
Самый простой случай. Для удаления файлов, содержащих в своем названии служебные символы вроде пробелов, кавычек, двойных кавычек, звездочек, обратные кавычки и др. можно заэкранировать обратным слешем или использовать одинарные кавычки:
С помощью одинарных кавычек нельзя удалить файл, в названии которого есть одинарная кавычка, даже заэкранировав ее.
С полным списком служебных символов и механизмом экранирования в bash можно ознакомиться в man bash. Раздел QUOTING.
Имя файла начинается с дефиса
Удалить файл, начинающийся с дефиса простым экранированием не получится, и команда rm будет воспринимать дефис, как начало своего аргумента. Решить проблему довольно просто:
Удаляем по wildcard
Если удаление файлов попадает под wildcard-маску, то можно удалить всю группу файлов:
Файлы с управляющим символом в названии
В названии файла может встречаться управляющий ASCII-символ, такой как перевод строки (\n), табуляция (\t), backspace (\b). Это символы с ASCII-кодами менее 0x20, а также символы DELETE и ESC. Для удаления таких файлов подходит конструкция:
Другим способом удаления таких файлов являяется ввод управляющего символа с клавиатуры. Для этого нужно воспользоваться комбинацией клавиш, которая экранирует следующий введенный символ, тем самым запрещая системе обрабатывать его. Как правило, эта комбинация CTRL+V. Точно убедиться в этом можно с помощью команды stty -a, посмотрев на параметр lnext. Удалим файл, содержащий символ ESC:
Удаление файлов с символами utf8
Если имя файла содержит символ в кодировке utf8, который мы не можем набрать на клавиатуре, то удалить такой файл можно выделением его мышкой, копированием в буфер обмена и последующей вставкой на ввод команды rm. Главное условие состоит в том, что наш терминал должен работать в кодировке utf8. Кодировка выставляется в настройках терминала. Будь то xterm, putty или брутальный linux tty.
Перекодировка имени файла
Подозревая, что имя файла находится в кодировке, отличной от кодировки терминала, мы можем выполнить перекодирование всех файлов в текущей директории. В результате файлы с битой кодировкой будут перекодированы, а файлы с ascii-символами изменений не претерпят. Существенный плюс этого способа – приведение всех файлов в читабельный вид.
Как видно, чтобы осуществить правильное перекодирование нужно знать две кодировки: предполагаемую кодировку файла и кодировку нашего терминала. Наиболее трудно распознать предполагаемую кодировку файла по непонятным символам. Есть замечательная табличка
Также можно воспользоваться сторонними программами, которые попытаются распознать кодировку автоматически. Например, онлайн-декодер Лебедева.
Если вы встретили такие символы в примонтированном media-носителе или смонтированном разделе Windows, не спешите ничего перекодировать. Возможно, вы просто указали неправильные опции монтирования.
Автокомплит
В случае, если в директории название требуемого файла начинается уникально, и это название можно однозначно сформировать автокомплитом, то это довольно простой способ удалить файл:
Удаляем файл через меню выбора
Если мы дошли сюда, дело плохо. Попробуем удалить конкретный файл, составив для этого меню выбора. В итоге, все что нам останется сделать – это выбрать нужный пункт меню вместо ввода имени файла. Для этого нам нужно запрограммировать действие, которое будет происходить с файлом или файлами после ввода нами нужных пунктов меню.
Удаление по номеру inode
Удалить файл можно по его номеру inode. Номер inode уникально идентифицирует файл в файловой системе. Узнать номер inode можно с помощью команды ls, а удалить – с помощью find. Недостаток этого способа, такой же, как у предыдущего. Неудобно, в случае большого числа файлов.
Удаление по hex-коду
И нельзя не упомянуть один суровый метод. Удаление по hex-кодам. Суть такова: мы узнаем hex-коды всех байтов в имени файла, а затем удаляем файл, указывая вместо имени hex-коды.
Хорошо, все-таки, что на практике такие файлы попадаются нечасто.
Источник
How To: Configure TABs in SQL Developer
As often happens, my ideas for blog posts are provided by end users asking for help. Sometimes I know the answer, sometimes I don’t. This is one of the latter cases. Chet AKA @oraclenerd asked me:
‘Tell me how to find the preference in sqldev to make a tab 2 spaces?’
I knew it had to be in there somewhere. This is a pretty basic setting for any word processor or IDE. Basically you want to control how many spaces are inserted when you hit the TAB key.
The default is ‘2.’
The problem with default settings is that they are likely to make half the users happy, a third non-plussed, and the rest genuinely upset. The idea is to shoot for something that offends the least number of users and aim for ‘the right thing’, kind of like Google’s ‘Do No Harm’ motto.
Since we can’t make everyone happy, we provide options for the end user to customize and fine tune their experience. The problem here was that it was REALLY hard to find this particular option. The search mechanism in the preferences dialog doesn’t reach the page where this particular setting was stored, and the label for the setting isn’t ideal.
So let’s get down to brass tacks and show you exactly how to configure this setting in SQL Developer.
Open the preferences, go to the Database page.
Easy enough. Now click on the ‘SQL Formatting’ sub page and then on ‘Oracle Formatting.’  The Formatting Options Page for Oracle Connections
The Formatting Options Page for Oracle Connections
Click on the ‘Edit’ button next to the profile dropdown control
Go to the Indentation page and inspect the ‘Spaces’ property
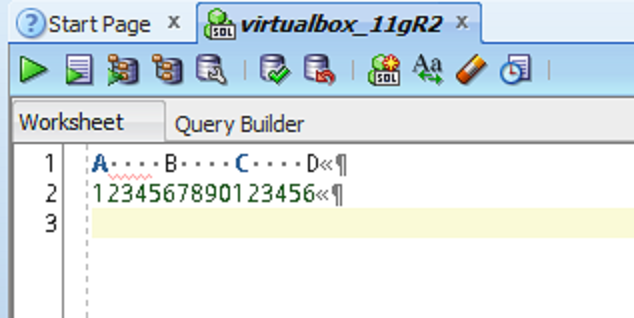
It’s currently set to ‘2.’ Change it to the desired setting. If I change it to 5, when I hit the ‘tab’ key, SQL Developer will insert 4 spaces leaving the cursor on the 5th curpos on the current line.
 The Spaces preferences controls the TAB key behavior
The Spaces preferences controls the TAB key behavior
You can easily observe the new behavior in the worksheet if you enable the ‘Show Whitespace Characters’ option under the ‘Code Editor’ and ‘Display’ page in the preferences.  Seeing is believing!
Seeing is believing!
Update: Version 4.2 and Higher
Pretty much the same difference.
However, we completely changed the formatter – enough so that we couldn’t preserve your settings, including this one for the indent/tab stop. So you’ll need to reset it. And it’s in a different place now.
Источник
Почему ошибка при компилации?
совсем не знаком с питоном , никогда не компилировал программы , делаю по гайду https://github.com/dwservice/agent/wiki/Setup-the-.
но при компиляции выдает ошибку 
кто может помочь с ошибкой или может у кого нибудь есть настроенная среда чтоб скомпилировать один раз? Мне в коде буквально пару мест удалить надо
- Вопрос задан более двух лет назад
- 155 просмотров


Павел, да, так не лучше. Прогоните через онлайн декодер строку с некорректной кодировкой www.online-decoder.com/ru
Вариант на скрине имеет большие шансы декодироваться в читаемый вид

Добрый день!
Python не компилируется. Это интерпретируемый язык (конечно, можно получить exe файл, но с наличием бубна).
Если только начинаете знакомиться с Python, то для начала пойдёт и IDLE(можно найти тут https://www.python.org/) вместо eclipse. Если же всё таки хотите работать в eclipse, то посмотрите в сторону PyDev (плагин).
Так же для начала было бы неплохо пробежаться по https://pythonworld.ru/samouchitel-python
там похоже не только питон но еще и С++ и еще что то , честно говоря совсем нет возможности и желания убивать столько времени, по сути нужно просто получить инсталятор с кусочком вырезанного кода
если у вас есть возможность мне помочь , может платно?
Источник
SQL Tabs for Mac
Review
Free Download
specifications
Minimalist and multi-platform SQL client for designed to help you explore, query and run scripts on MySQL, MariaDB, Postgresql, Amazon Redshift, MS SQL, and AlaSQL databases
What’s new in SQL Tabs 1.0.0:
- Google Firestore support
- Built-in save password dialog
- MSSQL connection options
- MSSQL native driver
Read the full changelog
SQL Tabs is an open source and Electron-based cross-platform SQL client that makes it simple and straightforward to both explore and query databases using your Mac.
The SQL Tabs app helps you manage multiple types of databases, from MySQL, MariaDB, Postgresql, Amazon Redshift, MS SQL, to AlaSQL, and it can be used in on today’s most popular platforms (i.e. macOS, Windows, and Linux).
Streamlined database managing workflow for experienced users
Even though SQL Tabs features a seemingly simple and minimalist tab-based interface, its looks are quite deceiving seeing that even connecting to a database requires you to have at least a minimum of previous knowledge on how a database works.
Thankfully, if you haven’t connected to a database before, SQL Tabs’ developer provides you with extensive online documentation designed to get you up and running in just a few minutes.
Explore and query the most popular databases, from MySQL to MS SQL and Amazon Redshift
Once you connect to your database, you can start exploring it using SQL Tabs’ menu, which helps you to get detailed information about the database, to run SQL scripts, as well as view the current object’s information and the full history for the current work session.
SQL Tabs also comes with more advanced features such as Markdown rendering, rich scripts output, and the capability to generate charts using your queries’ results.
Additionally, SQL Tabs provides you with bright and dark user interface themes, for working during the day and at night, and it has two editing modes, a classic one and a Vim one for users who don’t want to use the mouse while managing their databases.
Feature packed and minimalist cross-platform SQL client
On the whole, SQL Tabs is a streamlined and comprehensive SQL client, that manages to pack most of the features needed for exploring and querying a database.
The only downside would be a steeper learning curve than the usual, although easily avoidable if you first read SQL Tabs’ online documentation.
Источник
Символы Unicode: о чём должен знать каждый разработчик

Если вы пишете международное приложение, использующее несколько языков, то вам нужно кое-что знать о кодировке. Она отвечает за то, как текст отображается на экране. Я вкратце расскажу об истории кодировки и о её стандартизации, а затем мы поговорим о её использовании. Затронем немного и теорию информатики.
Введение в кодировку
Компьютеры понимают лишь двоичные числа — нули и единицы, это их язык. Больше ничего. Одно число называется байтом, каждый байт состоит из восьми битов. То есть восемь нулей и единиц составляют один байт. Внутри компьютеров всё сводится к двоичности — языки программирования, движений мыши, нажатия клавиш и все слова на экране. Но если статья, которую вы читаете, раньше была набором нулей и единиц, то как двоичные числа превратились в текст? Давайте разберёмся.
Краткая история кодировки
На заре своего развития интернет был исключительно англоязычным. Его авторам и пользователям не нужно было заботиться о символах других языков, и все нужды полностью покрывала кодировка American Standard Code for Information Interchange (ASCII).
ASCII — это таблица сопоставления бинарных обозначений знакам алфавита. Когда компьютер получает такую запись:
то с помощью ASCII он преобразует её во фразу «Hello world».
Один байт (восемь бит) был достаточно велик, чтобы вместить в себя любую англоязычную букву, как и управляющие символы, часть из которых использовалась телепринтерами, так что в те годы они были полезны (сегодня уже не особо). К управляющим символам относился, например 7 (0111 в двоичном представлении), который заставлял компьютер издавать сигнал; 8 (1000 в двоичном представлении) — выводил последний напечатанный символ; или 12 (1100 в двоичном представлении) — стирал весь написанный на видеотерминале текст.
В те времена компьютеры считали 8 бит за один байт (так было не всегда), так что проблем не возникало. Мы могли хранить все управляющие символы, все числа и англоязычные буквы, и даже ещё оставалось место, поскольку один байт может кодировать 255 символов, а для ASCII нужно только 127. То есть неиспользованными оставалось ещё 128 позиций в кодировке.
Вот как выглядит таблица ASCII. Двоичными числами кодируются все строчные и прописные буквы от A до Z и числа от 0 до 9. Первые 32 позиции отведены для непечатаемых управляющих символов.

Проблемы с ASCII
Позиции со 128 по 255 были пустыми. Общественность задумалась, чем их заполнить. Но у всех были разные идеи. Американский национальный институт стандартов (American National Standards Institute, ANSI) формулирует стандарты для разных отраслей. Там утвердили позиции ASCII с 0 по 127. Их никто не оспаривал. Проблема была с остальными позициями.
Вот чем были заполнены позиции 128-255 в первых компьютерах IBM:
Какие-то загогулины, фоновые иконки, математические операторы и символы с диакретическим знаком вроде é. Но разработчики других компьютерных архитектур не поддержали инициативу. Всем хотелось внедрить свою собственную кодировку во второй половине ASCII.
Все эти различные концовки назвали кодовыми страницами.
Что такое кодовые страницы ASCII?
Здесь собрана коллекция из более чем 465 разных кодовых страниц! Существовали разные страницы даже в рамках какого-то одного языка, например, для греческого и китайского. Как можно было стандартизировать этот бардак? Или хотя бы заставить его работать между разными языками? Или между разными кодовыми страницами для одного языка? В языках, отличающихся от английского? У китайцев больше 100 000 иероглифов. ASCII даже не может всех их вместить, даже если бы решили отдать все пустые позиции под китайские символы.
Эта проблема даже получила название Mojibake (бнопня, кракозябры). Так говорят про искажённый текст, который получается при использовании некорректной кодировки. В переводе с японского mojibake означает «преобразование символов».
Пример бнопни (кракозябров).
Безумие какое-то.
Именно! Не было ни единого шанса надёжно преобразовывать данные. Интернет — это лишь монструозное соединение компьютеров по всему миру. Представьте, что все страны решили использовать собственные стандарты. Например, греческие компьютеры принимают только греческий язык, а английские отправляют только английский. Это как кричать в пустой пещере, тебя никто не услышит.
ASCII уже не удовлетворял жизненным требованиям. Для всемирного интернета нужно было создать что-то другое, либо пришлось бы иметь дело с сотнями кодовых страниц.
��� Если только ������ вы не хотели ��� бы ��� читать подобные параграфы. �֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
Так появился Unicode
Unicode расшифровывают как Universal Coded Character Set (UCS), и у него есть официальное обозначение ISO/IEC 10646. Но обычно все используют название Unicode.
Этот стандарт помог решить проблемы, возникавшие из-за кодировки и кодовых страниц. Он содержит множество кодовых пунктов (кодовых точек), присвоенных символам из языков и культур со всего мира. То есть Unicode — это набор символов. С его помощью можно сопоставить некую абстракцию с буквой, на которую мы хотим ссылаться. И так сделано для каждого символа, даже египетских иероглифов.
Кто-то проделал огромную работу, сопоставляя каждый символ во всех языках с уникальными кодами. Вот как это выглядит:
Префикс U+ говорит о том, что это стандарт Unicode, а число — это результат преобразования двоичных чисел. Стандарт использует шестнадцатеричную нотацию, которая является упрощённым представлением двоичных чисел. Здесь вы можете ввести в поле что угодно и посмотреть, как это будет преобразовано в Unicode. А здесь можно полюбоваться на все 143 859 кодовых пунктов.
Уточню на всякий случай: речь идёт о большом словаре кодовых пунктов, присвоенных всевозможным символам. Это очень большой набор символов, не более того.
Осталось добавить последний ингредиент.
Unicode Transform Protocol (UTF)
UTF — протокол кодирования кодовых пунктов в Unicode. Он прописан в стандарте и позволяет кодировать любой кодовый пункт. Однако существуют разные типы UTF. Они различаются количеством байтов, используемых для кодировки одного пункта. В UTF-8 используется один байт на пункт, в UTF-16 — два байта, в UTF-32 — четыре байта.
Но если у нас есть три разные кодировки, то как узнать, какая из них применяется в конкретном файле? Для этого используют маркер последовательности байтов (Byte Order Mark, BOM), который ещё называют сигнатурой кодировки (Encoding Signature). BOM — это двухбайтный маркер в начале файл, который говорит о том, какая именно кодировка тут применена.
В интернете чаще всего используют UTF-8, она также прописана как предпочтительная в стандарте HTML5, так что уделю ей больше всего внимания.
Этот график построен в 2012-м, UTF-8 становилась доминирующей кодировкой. И всё ещё ею является.
Что такое UTF-8 и как она работает?
UTF-8 кодирует с помощью одного байта каждый кодовый пункт Unicode с 0 по 127 (как в ASCII). То есть если вы писали программу с использованием ASCII, а ваши пользователи применяют UTF-8, они не заметят ничего необычного. Всё будет работать как задумано. Обратите внимание, как это важно. Нам нужно было сохранить обратную совместимость с ASCII в ходе массового внедрения UTF-8. И эта кодировка ничего не ломает.
Как следует из названия, кодовый пункт состоит из 8 битов (один байт). В Unicode есть символы, которые занимают несколько байтов (вплоть до 6). Это называют переменной длиной. В разных языках удельное количество байтов разное. В английском — 1, европейские языки (с латинским алфавитом), иврит и арабский представлены с помощью двух байтов на кодовый пункт. Для китайского, японского, корейского и других азиатских языков используют по три байта.
Если нужно, чтобы символ занимал больше одного байта, то применяется битовая комбинация, обозначающая переход — он говорит о том, что символ продолжается в нескольких следующих байтах.
И теперь мы, как по волшебству, пришли к соглашению, как закодировать шумерскую клинопись (Хабр её не отображает), а также значки emoji!
Подытожив сказанное: сначала читаем BOM, чтобы определить версию кодировки, затем преобразуем файл в кодовые пункты Unicode, а потом выводим на экран символы из набора Unicode.
Напоследок про UTF
Коды являются ключами. Если я отправлю ошибочную кодировку, вы не сможете ничего прочесть. Не забывайте об этом при отправке и получении данных. В наших повседневных инструментах это часто абстрагировано, но нам, программистам, важно понимать, что происходит под капотом.
Как нам задавать кодировку? Поскольку HTML пишется на английском, и почти все кодировки прекрасно работают с английским, мы можем указать кодировку в начале раздела .
Важно сделать это в самом начале , поскольку парсинг HTML может начаться заново, если в данный момент используется неправильная кодировка. Также узнать версию кодировки можно из заголовка Content-Type HTTP-запроса/ответа.
Если HTML-документ не содержит упоминания кодировки, спецификация HTML5 предлагает такое интересное решение, как BOM-сниффинг. С его помощью мы по маркеру порядка байтов (BOM) можем определить используемую кодировку.
Это всё?
Unicode ещё не завершён. Как и в случае с любым стандартом, мы что-то добавляем, убираем, предлагаем новое. Никакие спецификации нельзя назвать «завершёнными». Обычно в год бывает 1-2 релиза, найти их описание можно здесь.
Если вы дочитали до конца, то вы молодцы. Предлагаю сделать домашнюю работу. Посмотрите, как могут ломаться сайты при использовании неправильной кодировки. Я воспользовался этим расширением для Google Chrome, поменял кодировку и попытался открывать разные страницы. Информация была совершенно нечитаемой. Попробуйте сами, как выглядит бнопня. Это поможет понять, насколько важна кодировка.
Заключение
При написании этой статьи я узнал о Майкле Эверсоне. С 1993 года он предложил больше 200 изменений в Unicode, добавил в стандарт тысячи символов. По состоянию на 2003 год он считался самым продуктивным участником. Он один очень сильно повлиял на облик Unicode. Майкл — один из тех, кто сделал интернет таким, каким мы его сегодня знаем. Очень впечатляет.
Надеюсь, мне удалось показать вам, для чего нужны кодировки, какие проблемы они решают, и что происходит при их сбоях.
Источник



