- The strings Command
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Как использовать команду Strings в Linux
- Использование команды strings
- Установка минимальной длины строки
- Ограничение вывода команды strings командой less
- Использование strings с файлами объектов
- Поиск в конкретной области файла
- Вывод номера строки
- Вывод управляющих символов
- Мы не ограничены только файлами
- Поиск нескольких файлов сразу
- Команда strings распутана
- strings
- find printable strings in files
- Print all strings in a binary
- Limit results to strings at least *length* characters long
- Prefix each result with its offset within the file
- Prefix each result with its offset within the file in hexadecimal
- SYNOPSIS
- DESCRIPTION
- OPTIONS
- COPYRIGHT
- SEE ALSO
The strings Command
The strings command returns each string of printable characters in files. Its main uses are to determine the contents of and to extract text from binary files (i.e., non-text files).
Characters are the basic symbols that are used to write or print a language. For example, the characters used by the English language consist of the letters of the alphabet, numerals, punctuation marks and a variety of symbols (e.g., the ampersand, the dollar sign and the arithmetic symbols). Printable characters are those which actually display on a monitor screen, as opposed to those that perform other functions, such as indicating a new line or a tab. A string is any finite sequence of characters, and it can be as few as one character.
The basic syntax of the strings command is
When used without any options, strings displays all strings that are at least four characters in length in the files whose names are supplied as arguments (i.e., input data). Strings that are on separate lines in the input files are shown on separate lines on the screen, and an attempt is made to display all strings found on a single line in a file on a single line on the screen (although there may be a carryover to subsequent lines in the event that numerous strings are found on a single line).
Perhaps the most commonly used of strings’s few options is -n, which, when followed by an integer, tells it to return strings which are at least the number of that integer in length. For example, the following would display all strings in the files named file1 and file2 that consist of at least two characters:
The -t option tells strings to also return the offset position for each line on which one or more strings are found. This option is followed by a letter indicating the numbering system to be used, i.e., o for octal, d for decimal and x for hexadecimal. Each printing character, each space and the start of each new line add one to the count. Thus, for example, for a file named file3 which contains the string abcd followed by a single space and then by the string efghi on the first line and the string jklm on the second line, the following command would return the number 0 before the strings in the first line and the number 11 before the string in the second line:
The -f option tells strings to begin each line of its output with the name of the file from which it is returning a particular string, followed by a colon and then by several spaces. This can be useful when simultaneously searching for strings in multiple files.
Created January 26, 2006.
Copyright © 2006 The Linux Information Project. All Rights Reserved.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Как использовать команду Strings в Linux
Нужно просмотреть текст внутри двоичного файла или файла данных? Команда Linux strings извлечет и выведет на терминал биты текста, которые называются «строками».
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps


Linux полон команд, которые могут выглядеть как решения в поисках проблем. Команда strings одна из них. Так, зачем же она нужна? Есть ли похожая команда, которая перечисляет строки для печати из двоичного файла?
Давайте вернемся назад. Двоичные файлы, такие как программные файлы, могут содержать строки читаемого человеком текста. Но как мы их видим? Если использовать cat или less , то, скорее всего, зависнет окно терминала. Программы, предназначенные для работы с текстовыми файлами, не могу обрабатывать исполняемые файлы, содержащие непечатаемые символы.
Большая часть данных в двоичном файле нечитабельна и не могут быть выведены в окно терминала каким-либо образом, так как нет знаков или стандартных символов для представления двоичных значений, которые не соответствуют буквенно-цифровым символам, знакам пунктуации или пробелам. В совокупности они называются «печатаемыми» символами. Остальные — «непечатаемые» символы.
Поэтому попытка просмотра или поиска текстовых строк в двоичном файле или файле данных является проблемой. И вот здесь на помощь спешит strings . Он извлекает строки печатаемых символов из файлов, чтобы другие команды могли использовать эти строки без необходимости контактировать с непечатаемыми символами.
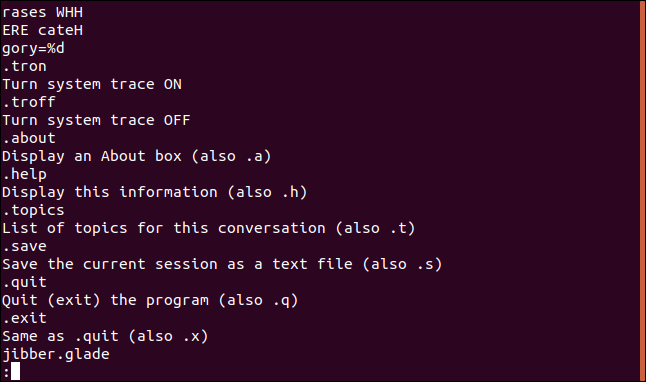
Использование команды strings
На самом деле нет ничего сложного в этой команде: просто передаем команде название файла.
Как пример, мы попробуем просмотреть содержимое исполняемого файла jibber с помощью strings .
На скриншоте ниже список строк, извлечённых из указанного файла:

Установка минимальной длины строки
По умолчанию, команда strings ищет строки, содержащие четыре и более символов. Чтобы изменить значение по умолчанию используется ключ –n .
Имейте ввиду, что чем короче минимальная длина, тем больше шансов получить на выводе бесполезного материала.
Некоторые двоичные значения имеют то же числовое значение, что и значение, представляющее печатаемый символ. Если два из этих числовых значений находятся рядом в файле, а минимальная длина, равна двум, эти байты будут отображаться как строки.
Чтобы установить длину строки равной двум, используйте следующую команду:
Теперь у нас на выводе есть строки, длина который равна двум и более символам. Учтите, что пробел тоже считается печатаемым символом.

Ограничение вывода команды strings командой less
Чтобы ограничить объем выведенной информации вывод команды strings можно передать команде less , а затем прокруткой просматривать всю информацию:
Теперь мы видим список, выводимый командой less , где начало списка отображено первым:
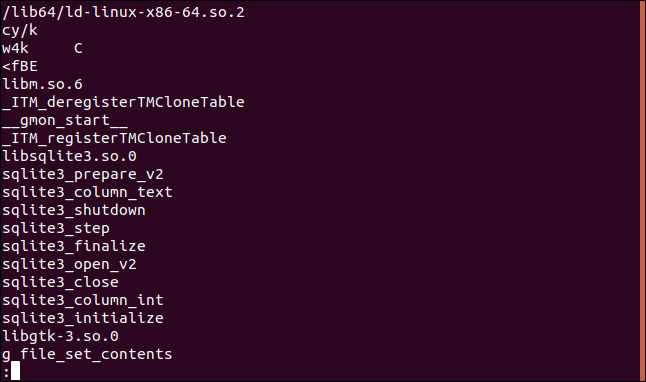
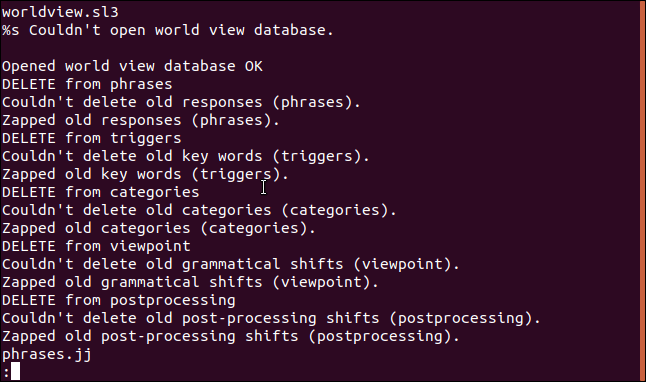
Использование strings с файлами объектов
Обычно исходный код программ компилируется в файлы объектов. Они в свою очередь связаны с файлами библиотек, чтобы создать исполняемый файл. У нас есть файл объектов jibber , давайте посмотрим, что в нем:
Данные выводятся в таблице по 8 колонок, каждая из строк которой заканчивается на букву “H” . В данном примере у нас SQL запрос.

Но если прокрутить ниже, то можно заметить, что форматирование не относится ко всему файлу.
Думаю, интересно видеть разницу между текстовыми строками файла объектов и конечного исполняемого файла.
Поиск в конкретной области файла
Скомпилированные программы имеют различные области, которые используются для хранения текста. По умолчанию, strings ищет текст во всем файле. Это так же, как если бы вы использовали параметр -a (all). Для поиска строк только в инициализированных, загруженных разделах данных в файле используйте параметр -d (data).
Если нет особой причины, то вполне можно обойтись значением по умолчанию.
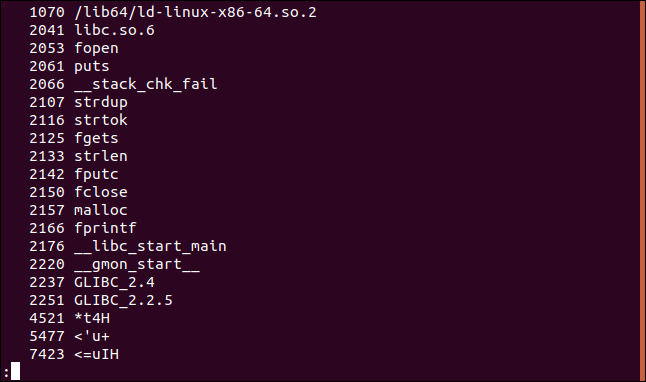
Вывод номера строки
Иногда бывает необходимо узнать точное смещение, расположение строки в файле. В этом нам поможет ключ –o (offset).
В данном случае номера строки показаны в восьмеричной системе.
Для получения значений в других системах исчисления, достаточно использовать опцию –t , а затем передать нужный ключ: d (десятичная система), x (шестнадцатеричная) или o (восьмеричная). Опция –t с ключом o равнозначна запуску команды strings с ключом –o .
Теперь номера строк показаны в десятичной системе:
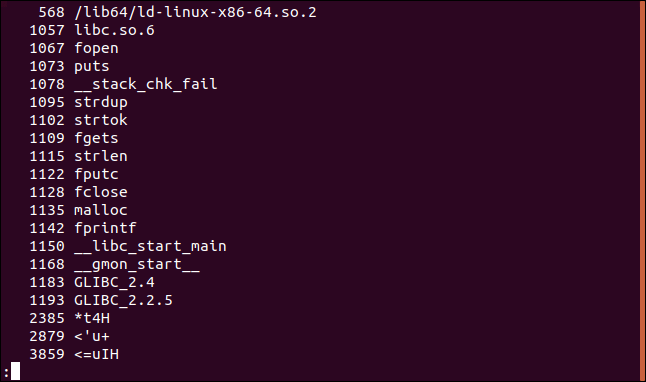
А тут в шестнадцатеричной:
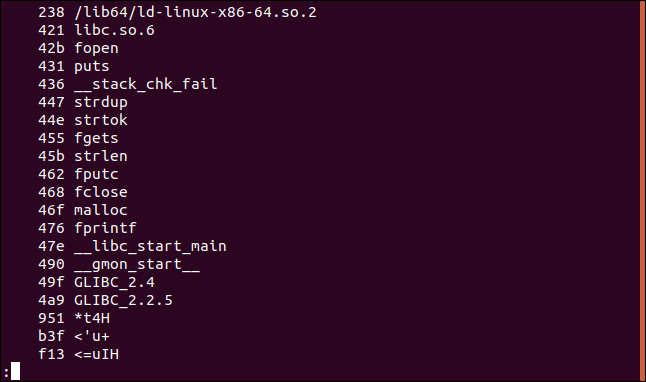
Вывод управляющих символов
Команда strings принимает знаки табуляции и пробела, как часть строки, игнорируя при этом символ начала новой строки — /r или возврата каретки — /r . Чтобы включить их отображение нужно добавить ключ –w .
Ниже мы видим пустую строку. Это результат работы управляющих символов: либо символа новой строки, либо символ возврата каретки.
Мы не ограничены только файлами
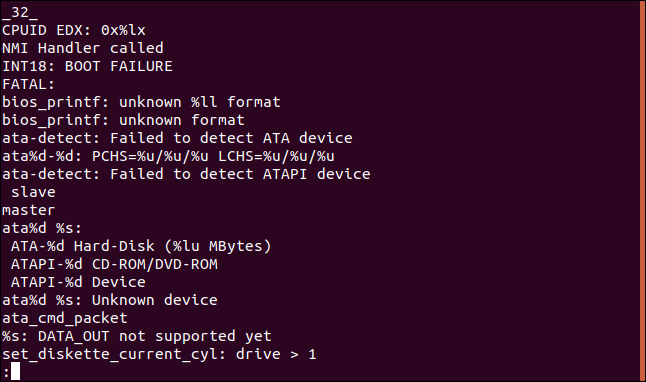
Мы можем использовать строки с любым, что есть или может создать поток байтов.
С помощью этой команды мы можем просмотреть содержимое оперативной памяти (RAM) нашего компьютера. Нам нужно использовать >sudo, потому что мы получаем доступ /dev/mem . Это символьного файл устройства, в котором хранится изображение оперативной памяти компьютера.
В списке не все содержимое оперативной памяти, а лишь то, что команда strings смогла извлечь.
Поиск нескольких файлов сразу
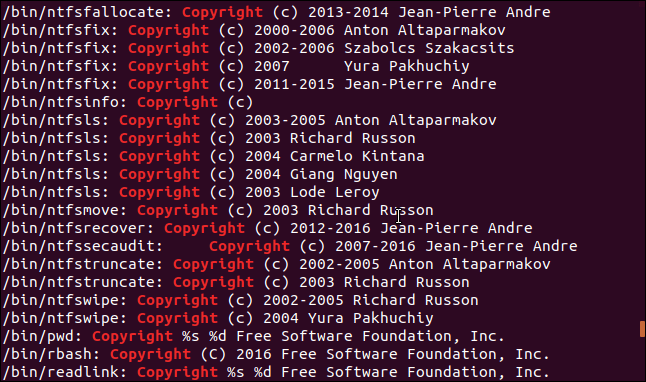
Маски можно использовать для выбора групп файлов для поиска. Символ * обозначает нуль и больше символов, а символ «?» означает любой отдельный символ. Можно также указать в командной строке множество имен файлов.
Мы будем использовать маску для поиска всех исполняемых файлов в каталоге /bin . Поскольку список будет содержать результаты из многих файлов, будет использоваться параметр -f (имя файла). Имя файла будет напечатано в начале каждой строки. Затем можно просмотреть файл, в котором была найдена данная строка.
Затем передадим результаты через grep и выведем строки, содержащие слово «Copyright»:
Мы получаем упорядоченный список с об авторских правах каждого файла в каталоге /bin , с именем файла в начале каждой строки.
Команда strings распутана
Команда strings – это не какая-то тайная команда. Это обычная команда Linux. Он делает выполняет конкретные задачи и делает это очень хорошо. Это еще один из преимуществ Linux, и действительно мощных в сочетании с другими командами. Когда вы видите, как он может оперировать двоичными файлами и другими инструментами, такими как grep, начинаете по-настоящему ценить функциональность этой слегка непонятной команды.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
strings
find printable strings in files
Print all strings in a binary
Limit results to strings at least *length* characters long
Prefix each result with its offset within the file
Prefix each result with its offset within the file in hexadecimal
SYNOPSIS
DESCRIPTION
For each file given, GNU strings prints the printable character sequences that are at least 4 characters long (or the number given with the options below) and are followed by an unprintable character.
Depending upon how the strings program was configured it will default to either displaying all the printable sequences that it can find in each file, or only those sequences that are in loadable, initialized data sections. If the file type is unrecognizable, or if strings is reading from stdin then it will always display all of the printable sequences that it can find.
For backwards compatibility any file that occurs after a command-line option of just — will also be scanned in full, regardless of the presence of any -d option.
strings is mainly useful for determining the contents of non-text files.
OPTIONS
Scan the whole file, regardless of what sections it contains or whether those sections are loaded or initialized. Normally this is the default behaviour, but strings can be configured so that the -d is the default instead. The — option is position dependent and forces strings to perform full scans of any file that is mentioned after the — on the command line, even if the -d option has been specified.
Only print strings from initialized, loaded data sections in the file. This may reduce the amount of garbage in the output, but it also exposes the strings program to any security flaws that may be present in the BFD library used to scan and load sections. Strings can be configured so that this option is the default behaviour. In such cases the -a option can be used to avoid using the BFD library and instead just print all of the strings found in the file.
Print the name of the file before each string.
Print a summary of the program usage on the standard output and exit.
-min-len -n min-len —bytes=min-len
Print sequences of characters that are at least min-len characters long, instead of the default 4.
Like -t o. Some other versions of strings have -o act like -t d instead. Since we can not be compatible with both ways, we simply chose one.
-t radix —radix=radix
Print the offset within the file before each string. The single character argument specifies the radix of the offset—o for octal, x for hexadecimal, or d for decimal.
-e encoding —encoding=encoding
Select the character encoding of the strings that are to be found. Possible values for encoding are: s = single-7-bit-byte characters (ASCII, ISO 8859, etc., default), S = single-8-bit-byte characters, b = 16-bit bigendian, l = 16-bit littleendian, B = 32-bit bigendian, L = 32-bit littleendian. Useful for finding wide character strings. (l and b apply to, for example, Unicode UTF-16/UCS-2 encodings).
-T bfdname —target=bfdname
Specify an object code format other than your system’s default format.
Print the program version number on the standard output and exit.
By default tab and space characters are included in the strings that are displayed, but other whitespace characters, such a newlines and carriage returns, are not. The -w option changes this so that all whitespace characters are considered to be part of a string.
By default, output strings are delimited by a new-line. This option allows you to supply any string to be used as the output record separator. Useful with —include-all-whitespace where strings may contain new-lines internally.
Read command-line options from file. The options read are inserted in place of the original @file option. If file does not exist, or cannot be read, then the option will be treated literally, and not removed. Options in file are separated by whitespace. A whitespace character may be included in an option by surrounding the entire option in either single or double quotes. Any character (including a backslash) may be included by prefixing the character to be included with a backslash. The file may itself contain additional @file options; any such options will be processed recursively.
COPYRIGHT
Copyright (c) 1991-2021 Free Software Foundation, Inc.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, with no Front-Cover Texts, and with no Back-Cover Texts. A copy of the license is included in the section entitled GNU Free Documentation License.
SEE ALSO
ar (1), nm (1), objdump (1), ranlib (1), readelf (1) and the Info entries for binutils.
Источник



