- 9.2. Работа со строками
- 9.2.1. Использование awk при работе со строками
- 9.2.2. Дальнейшее обсуждение
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Как использовать команду Strings в Linux
- Использование команды strings
- Установка минимальной длины строки
- Ограничение вывода команды strings командой less
- Использование strings с файлами объектов
- Поиск в конкретной области файла
- Вывод номера строки
- Вывод управляющих символов
- Мы не ограничены только файлами
- Поиск нескольких файлов сразу
- Команда strings распутана
- String functions � linux
- Footnotes
9.2. Работа со строками
Bash поддерживает на удивление большое количество операций над строками. К сожалению, этот раздел Bash испытывает недостаток унификации. Одни операции являются подмножеством операций подстановки параметров, а другие — совпадают с функциональностью команды UNIX — expr. Это приводит к противоречиям в синтаксисе команд и перекрытию функциональных возможностей, не говоря уже о возникающей путанице.
Длина строки
$ <#string>expr length $string expr «$string» : ‘.*’
Пример 9-10. Вставка пустых строк между параграфами в текстовом файле
Длина подстроки в строке (подсчет совпадающих символов ведется с начала строки)
expr match «$string» ‘$substring’
expr «$string» : ‘$substring’
где $substring — регулярное выражение.
Index
expr index $string $substring
Номер позиции первого совпадения в $string c первым символом в $substring.
Эта функция довольно близка к функции strchr() в языке C.
Извлечение подстроки
Извлекает подстроку из $string, начиная с позиции $position.
Если строка $string — » * » или » @ » , то извлекается позиционный параметр (аргумент), [1] с номером $position.
Извлекает $length символов из $string, начиная с позиции $position.
Если $string — » * » или » @ » , то извлекается до $length позиционных параметров (аргументов), начиная с $position.
expr substr $string $position $length
Извлекает $length символов из $string, начиная с позиции $position.
expr match «$string» ‘\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение.
expr «$string» : ‘\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение.
expr match «$string» ‘.*\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение. Поиск начинается с конца $string.
expr «$string» : ‘.*\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение. Поиск начинается с конца $string.
Удаление части строки
Удаление самой короткой, из найденных, подстроки $substring в строке $string. Поиск ведется с начала строки
Удаление самой длинной, из найденных, подстроки $substring в строке $string. Поиск ведется с начала строки
Удаление самой короткой, из найденных, подстроки $substring в строке $string. Поиск ведется с конца строки
Удаление самой длинной, из найденных, подстроки $substring в строке $string. Поиск ведется с конца строки
Пример 9-11. Преобразование графических файлов из одного формата в другой, с изменением имени файла
Замена подстроки
Замещает первое вхождение $substring строкой $replacement.
Замещает все вхождения $substring строкой $replacement.
Подстановка строки $replacement вместо $substring. Поиск ведется с начала строки $string.
Подстановка строки $replacement вместо $substring. Поиск ведется с конца строки $string.
9.2.1. Использование awk при работе со строками
В качестве альтернативы, Bash-скрипты могут использовать средства awk при работе со строками.
Пример 9-12. Альтернативный способ извлечения подстрок
9.2.2. Дальнейшее обсуждение
Дополнительную информацию, по работе со строками, вы найдете в разделе Section 9.3 и в секции, посвященной команде expr. Примеры сценариев:
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Как использовать команду Strings в Linux
Нужно просмотреть текст внутри двоичного файла или файла данных? Команда Linux strings извлечет и выведет на терминал биты текста, которые называются «строками».
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps


Linux полон команд, которые могут выглядеть как решения в поисках проблем. Команда strings одна из них. Так, зачем же она нужна? Есть ли похожая команда, которая перечисляет строки для печати из двоичного файла?
Давайте вернемся назад. Двоичные файлы, такие как программные файлы, могут содержать строки читаемого человеком текста. Но как мы их видим? Если использовать cat или less , то, скорее всего, зависнет окно терминала. Программы, предназначенные для работы с текстовыми файлами, не могу обрабатывать исполняемые файлы, содержащие непечатаемые символы.
Большая часть данных в двоичном файле нечитабельна и не могут быть выведены в окно терминала каким-либо образом, так как нет знаков или стандартных символов для представления двоичных значений, которые не соответствуют буквенно-цифровым символам, знакам пунктуации или пробелам. В совокупности они называются «печатаемыми» символами. Остальные — «непечатаемые» символы.
Поэтому попытка просмотра или поиска текстовых строк в двоичном файле или файле данных является проблемой. И вот здесь на помощь спешит strings . Он извлекает строки печатаемых символов из файлов, чтобы другие команды могли использовать эти строки без необходимости контактировать с непечатаемыми символами.
Использование команды strings
На самом деле нет ничего сложного в этой команде: просто передаем команде название файла.
Как пример, мы попробуем просмотреть содержимое исполняемого файла jibber с помощью strings .
На скриншоте ниже список строк, извлечённых из указанного файла:

Установка минимальной длины строки
По умолчанию, команда strings ищет строки, содержащие четыре и более символов. Чтобы изменить значение по умолчанию используется ключ –n .
Имейте ввиду, что чем короче минимальная длина, тем больше шансов получить на выводе бесполезного материала.
Некоторые двоичные значения имеют то же числовое значение, что и значение, представляющее печатаемый символ. Если два из этих числовых значений находятся рядом в файле, а минимальная длина, равна двум, эти байты будут отображаться как строки.
Чтобы установить длину строки равной двум, используйте следующую команду:
Теперь у нас на выводе есть строки, длина который равна двум и более символам. Учтите, что пробел тоже считается печатаемым символом.

Ограничение вывода команды strings командой less
Чтобы ограничить объем выведенной информации вывод команды strings можно передать команде less , а затем прокруткой просматривать всю информацию:
Теперь мы видим список, выводимый командой less , где начало списка отображено первым:
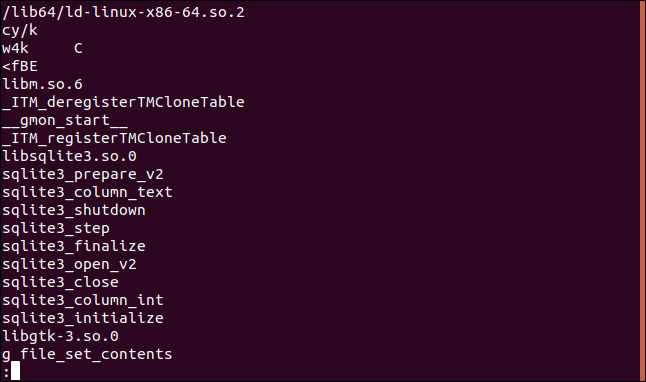
Использование strings с файлами объектов
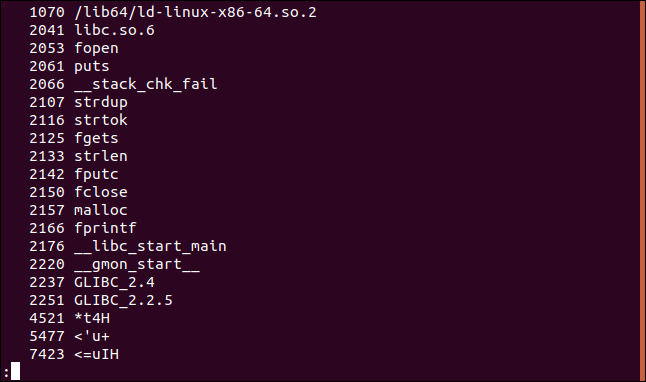
Обычно исходный код программ компилируется в файлы объектов. Они в свою очередь связаны с файлами библиотек, чтобы создать исполняемый файл. У нас есть файл объектов jibber , давайте посмотрим, что в нем:
Данные выводятся в таблице по 8 колонок, каждая из строк которой заканчивается на букву “H” . В данном примере у нас SQL запрос.

Но если прокрутить ниже, то можно заметить, что форматирование не относится ко всему файлу.
Думаю, интересно видеть разницу между текстовыми строками файла объектов и конечного исполняемого файла.
Поиск в конкретной области файла
Скомпилированные программы имеют различные области, которые используются для хранения текста. По умолчанию, strings ищет текст во всем файле. Это так же, как если бы вы использовали параметр -a (all). Для поиска строк только в инициализированных, загруженных разделах данных в файле используйте параметр -d (data).
Если нет особой причины, то вполне можно обойтись значением по умолчанию.
Вывод номера строки
Иногда бывает необходимо узнать точное смещение, расположение строки в файле. В этом нам поможет ключ –o (offset).
В данном случае номера строки показаны в восьмеричной системе.
Для получения значений в других системах исчисления, достаточно использовать опцию –t , а затем передать нужный ключ: d (десятичная система), x (шестнадцатеричная) или o (восьмеричная). Опция –t с ключом o равнозначна запуску команды strings с ключом –o .
Теперь номера строк показаны в десятичной системе:
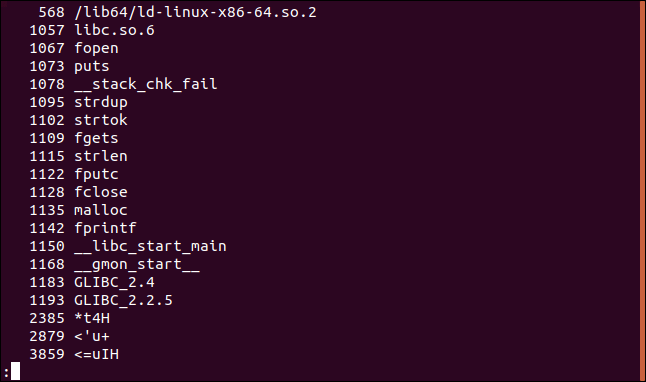
А тут в шестнадцатеричной:
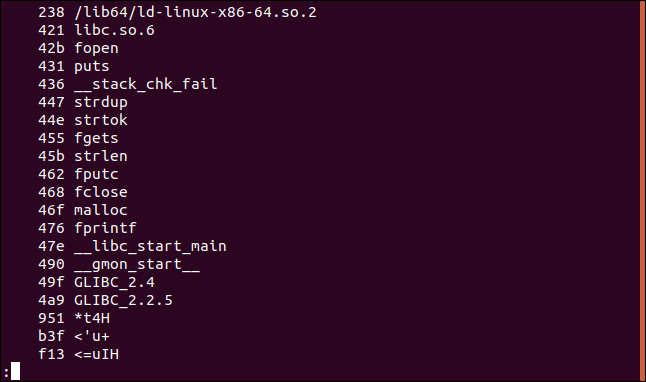
Вывод управляющих символов
Команда strings принимает знаки табуляции и пробела, как часть строки, игнорируя при этом символ начала новой строки — /r или возврата каретки — /r . Чтобы включить их отображение нужно добавить ключ –w .
Ниже мы видим пустую строку. Это результат работы управляющих символов: либо символа новой строки, либо символ возврата каретки.
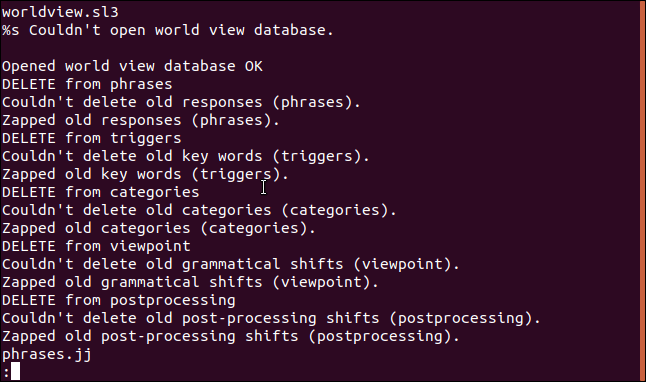
Мы не ограничены только файлами
Мы можем использовать строки с любым, что есть или может создать поток байтов.
С помощью этой команды мы можем просмотреть содержимое оперативной памяти (RAM) нашего компьютера. Нам нужно использовать >sudo, потому что мы получаем доступ /dev/mem . Это символьного файл устройства, в котором хранится изображение оперативной памяти компьютера.
В списке не все содержимое оперативной памяти, а лишь то, что команда strings смогла извлечь.
Поиск нескольких файлов сразу
Маски можно использовать для выбора групп файлов для поиска. Символ * обозначает нуль и больше символов, а символ «?» означает любой отдельный символ. Можно также указать в командной строке множество имен файлов.
Мы будем использовать маску для поиска всех исполняемых файлов в каталоге /bin . Поскольку список будет содержать результаты из многих файлов, будет использоваться параметр -f (имя файла). Имя файла будет напечатано в начале каждой строки. Затем можно просмотреть файл, в котором была найдена данная строка.
Затем передадим результаты через grep и выведем строки, содержащие слово «Copyright»:
Мы получаем упорядоченный список с об авторских правах каждого файла в каталоге /bin , с именем файла в начале каждой строки.
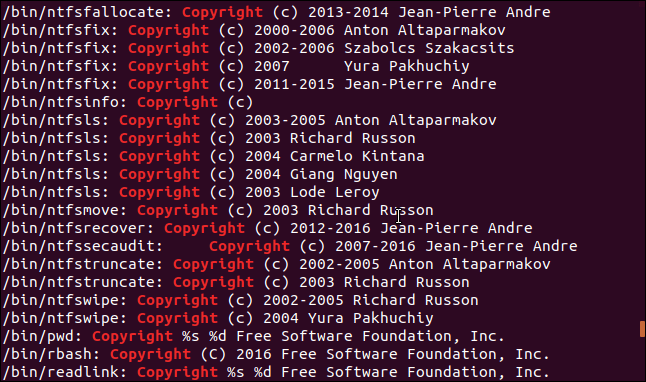
Команда strings распутана
Команда strings – это не какая-то тайная команда. Это обычная команда Linux. Он делает выполняет конкретные задачи и делает это очень хорошо. Это еще один из преимуществ Linux, и действительно мощных в сочетании с другими командами. Когда вы видите, как он может оперировать двоичными файлами и другими инструментами, такими как grep, начинаете по-настоящему ценить функциональность этой слегка непонятной команды.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
String functions � linux
The functions in this section look at or change the text of one or more strings.
gawk understands locales (see section Where You Are Makes a Difference) and does all string processing in terms of characters, not bytes. This distinction is particularly important to understand for locales where one character may be represented by multiple bytes. Thus, for example, length() returns the number of characters in a string, and not the number of bytes used to represent those characters. Similarly, index() works with character indices, and not byte indices.
CAUTION: A number of functions deal with indices into strings. For these functions, the first character of a string is at position (index) one. This is different from C and the languages descended from it, where the first character is at position zero. You need to remember this when doing index calculations, particularly if you are used to C.
In the following list, optional parameters are enclosed in square brackets ([ ]). Several functions perform string substitution; the full discussion is provided in the description of the sub() function, which comes toward the end, because the list is presented alphabetically.
Those functions that are specific to gawk are marked with a pound sign (‘ # ’). They are not available in compatibility mode (see section Command-Line Options):
| • Gory Details | More than you want to know about ‘ \ ’ and ‘ & ’ with sub() , gsub() , and gensub() . |
asort( source [ , dest [ , how ] ] ) # asorti( source [ , dest [ , how ] ] ) #
These two functions are similar in behavior, so they are described together.
NOTE: The following description ignores the third argument, how , as it requires understanding features that we have not discussed yet. Thus, the discussion here is a deliberate simplification. (We do provide all the details later on; see Sorting Array Values and Indices with gawk for the full story.)
Both functions return the number of elements in the array source . For asort() , gawk sorts the values of source and replaces the indices of the sorted values of source with sequential integers starting with one. If the optional array dest is specified, then source is duplicated into dest . dest is then sorted, leaving the indices of source unchanged.
When comparing strings, IGNORECASE affects the sorting (see section Sorting Array Values and Indices with gawk ). If the source array contains subarrays as values (see section Arrays of Arrays), they will come last, after all scalar values. Subarrays are not recursively sorted.
For example, if the contents of a are as follows:
A call to asort() :
results in the following contents of a :
The asorti() function works similarly to asort() ; however, the indices are sorted, instead of the values. Thus, in the previous example, starting with the same initial set of indices and values in a , calling ‘ asorti(a) ’ would yield:
NOTE: Due to implementation limitations, you may not use either SYMTAB or FUNCTAB as arguments to these functions, even if providing a second array to use for the actual sorting. Attempting to do so produces a fatal error. This restriction may be lifted in the future.
Search the target string target for matches of the regular expression regexp . If how is a string beginning with ‘ g ’ or ‘ G ’ (short for “global”), then replace all matches of regexp with replacement . Otherwise, treat how as a number indicating which match of regexp to replace. Treat numeric values less than one as if they were one. If no target is supplied, use $0 . Return the modified string as the result of the function. The original target string is not changed.
gensub() is a general substitution function. Its purpose is to provide more features than the standard sub() and gsub() functions.
gensub() provides an additional feature that is not available in sub() or gsub() : the ability to specify components of a regexp in the replacement text. This is done by using parentheses in the regexp to mark the components and then specifying ‘ \ N ’ in the replacement text, where N is a digit from 1 to 9. For example:
As with sub() , you must type two backslashes in order to get one into the string. In the replacement text, the sequence ‘ \0 ’ represents the entire matched text, as does the character ‘ & ’.
The following example shows how you can use the third argument to control which match of the regexp should be changed:
In this case, $0 is the default target string. gensub() returns the new string as its result, which is passed directly to print for printing.
If the how argument is a string that does not begin with ‘ g ’ or ‘ G ’, or if it is a number that is less than or equal to zero, only one substitution is performed. If how is zero, gawk issues a warning message.
If regexp does not match target , gensub() ’s return value is the original unchanged value of target .
gsub( regexp , replacement [ , target ] )
Search target for all of the longest, leftmost, nonoverlapping matching substrings it can find and replace them with replacement . The ‘ g ’ in gsub() stands for “global,” which means replace everywhere. For example:
replaces all occurrences of the string ‘ Britain ’ with ‘ United Kingdom ’ for all input records.
The gsub() function returns the number of substitutions made. If the variable to search and alter ( target ) is omitted, then the entire input record ( $0 ) is used. As in sub() , the characters ‘ & ’ and ‘ \ ’ are special, and the third argument must be assignable.
Search the string in for the first occurrence of the string find , and return the position in characters where that occurrence begins in the string in . Consider the following example:
If find is not found, index() returns zero.
With BWK awk and gawk , it is a fatal error to use a regexp constant for find . Other implementations allow it, simply treating the regexp constant as an expression meaning ‘ $0
Return the number of characters in string . If string is a number, the length of the digit string representing that number is returned. For example, length(«abcde») is five. By contrast, length(15 * 35) works out to three. In this example, 15 * 35 = 525, and 525 is then converted to the string «525» , which has three characters.
If no argument is supplied, length() returns the length of $0 .
NOTE: In older versions of awk , the length() function could be called without any parentheses. Doing so is considered poor practice, although the 2008 POSIX standard explicitly allows it, to support historical practice. For programs to be maximally portable, always supply the parentheses.
If length() is called with a variable that has not been used, gawk forces the variable to be a scalar. Other implementations of awk leave the variable without a type. (d.c.) Consider:
If —lint has been specified on the command line, gawk issues a warning about this.
With gawk and several other awk implementations, when given an array argument, the length() function returns the number of elements in the array. (c.e.) This is less useful than it might seem at first, as the array is not guaranteed to be indexed from one to the number of elements in it. If —lint is provided on the command line (see section Command-Line Options), gawk warns that passing an array argument is not portable. If —posix is supplied, using an array argument is a fatal error (see section Arrays in awk ).
match( string , regexp [ , array ] )
Search string for the longest, leftmost substring matched by the regular expression regexp and return the character position (index) at which that substring begins (one, if it starts at the beginning of string ). If no match is found, return zero.
The regexp argument may be either a regexp constant ( / … / ) or a string constant ( » … » ). In the latter case, the string is treated as a regexp to be matched. See section Using Dynamic Regexps for a discussion of the difference between the two forms, and the implications for writing your program correctly.
The order of the first two arguments is the opposite of most other string functions that work with regular expressions, such as sub() and gsub() . It might help to remember that for match() , the order is the same as for the ‘
The match() function sets the predefined variable RSTART to the index. It also sets the predefined variable RLENGTH to the length in characters of the matched substring. If no match is found, RSTART is set to zero, and RLENGTH to -1.
This program looks for lines that match the regular expression stored in the variable regex . This regular expression can be changed. If the first word on a line is ‘ FIND ’, regex is changed to be the second word on that line. Therefore, if given:
If array is present, it is cleared, and then the zeroth element of array is set to the entire portion of string matched by regexp . If regexp contains parentheses, the integer-indexed elements of array are set to contain the portion of string matching the corresponding parenthesized subexpression. For example:
In addition, multidimensional subscripts are available providing the start index and length of each matched subexpression:
There may not be subscripts for the start and index for every parenthesized subexpression, because they may not all have matched text; thus, they should be tested for with the in operator (see section Referring to an Array Element).
The array argument to match() is a gawk extension. In compatibility mode (see section Command-Line Options), using a third argument is a fatal error.
patsplit( string , array [ , fieldpat [ , seps ] ] ) #
Divide string into pieces (or “fields”) defined by fieldpat and store the pieces in array and the separator strings in the seps array. The first piece is stored in array [1] , the second piece in array [2] , and so forth. The third argument, fieldpat , is a regexp describing the fields in string (just as FPAT is a regexp describing the fields in input records). It may be either a regexp constant or a string. If fieldpat is omitted, the value of FPAT is used. patsplit() returns the number of elements created. seps [ i ] is the possibly null separator string after array [ i ] . The possibly null leading separator will be in seps [0] . So a non-null string with n fields will have n+1 separators. A null string will not have neither fields nor separators.
The patsplit() function splits strings into pieces in a manner similar to the way input lines are split into fields using FPAT (see section Defining Fields by Content).
Before splitting the string, patsplit() deletes any previously existing elements in the arrays array and seps .
split( string , array [ , fieldsep [ , seps ] ] )
Divide string into pieces separated by fieldsep and store the pieces in array and the separator strings in the seps array. The first piece is stored in array [1] , the second piece in array [2] , and so forth. The string value of the third argument, fieldsep , is a regexp describing where to split string (much as FS can be a regexp describing where to split input records). If fieldsep is omitted, the value of FS is used. split() returns the number of elements created. seps is a gawk extension, with seps [ i ] being the separator string between array [ i ] and array [ i +1] . If fieldsep is a single space, then any leading whitespace goes into seps [0] and any trailing whitespace goes into seps [ n ] , where n is the return value of split() (i.e., the number of elements in array ).
The split() function splits strings into pieces in the same way that input lines are split into fields. For example:
splits the string «cul-de-sac» into three fields using ‘ — ’ as the separator. It sets the contents of the array a as follows:
and sets the contents of the array seps as follows:
The value returned by this call to split() is three.
As with input field-splitting, when the value of fieldsep is » » , leading and trailing whitespace is ignored in values assigned to the elements of array but not in seps , and the elements are separated by runs of whitespace. Also, as with input field splitting, if fieldsep is the null string, each individual character in the string is split into its own array element. (c.e.) Additionally, if fieldsep is a single-character string, that string acts as the separator, even if its value is a regular expression metacharacter.
Note, however, that RS has no effect on the way split() works. Even though ‘ RS = «» ’ causes the newline character to also be an input field separator, this does not affect how split() splits strings.
Modern implementations of awk , including gawk , allow the third argument to be a regexp constant ( / … / ) as well as a string. (d.c.) The POSIX standard allows this as well. See section Using Dynamic Regexps for a discussion of the difference between using a string constant or a regexp constant, and the implications for writing your program correctly.
Before splitting the string, split() deletes any previously existing elements in the arrays array and seps .
If string is null, the array has no elements. (So this is a portable way to delete an entire array with one statement. See section The delete Statement.)
If string does not match fieldsep at all (but is not null), array has one element only. The value of that element is the original string .
In POSIX mode (see section Command-Line Options), the fourth argument is not allowed.
sprintf( format , expression1 , …)
Return (without printing) the string that printf would have printed out with the same arguments (see section Using printf Statements for Fancier Printing). For example:
assigns the string ‘ pi = 3.14 (approx.) ’ to the variable pival .
Examine str and return its numeric value. If str begins with a leading ‘ 0 ’, strtonum() assumes that str is an octal number. If str begins with a leading ‘ 0x ’ or ‘ 0X ’, strtonum() assumes that str is a hexadecimal number. For example:
Using the strtonum() function is not the same as adding zero to a string value; the automatic coercion of strings to numbers works only for decimal data, not for octal or hexadecimal. 47
Note also that strtonum() uses the current locale’s decimal point for recognizing numbers (see section Where You Are Makes a Difference).
sub( regexp , replacement [ , target ] )
Search target , which is treated as a string, for the leftmost, longest substring matched by the regular expression regexp . Modify the entire string by replacing the matched text with replacement . The modified string becomes the new value of target . Return the number of substitutions made (zero or one).
The regexp argument may be either a regexp constant ( / … / ) or a string constant ( » … » ). In the latter case, the string is treated as a regexp to be matched. See section Using Dynamic Regexps for a discussion of the difference between the two forms, and the implications for writing your program correctly.
This function is peculiar because target is not simply used to compute a value, and not just any expression will do—it must be a variable, field, or array element so that sub() can store a modified value there. If this argument is omitted, then the default is to use and alter $0 . 48 For example:
sets str to ‘ wither, water, everywhere ’ , by replacing the leftmost longest occurrence of ‘ at ’ with ‘ ith ’.
If the special character ‘ & ’ appears in replacement , it stands for the precise substring that was matched by regexp . (If the regexp can match more than one string, then this precise substring may vary.) For example:
changes the first occurrence of ‘ candidate ’ to ‘ candidate and his wife ’ on each input line. Here is another example:
This shows how ‘ & ’ can represent a nonconstant string and also illustrates the “leftmost, longest” rule in regexp matching (see section How Much Text Matches?).
The effect of this special character (‘ & ’) can be turned off by putting a backslash before it in the string. As usual, to insert one backslash in the string, you must write two backslashes. Therefore, write ‘ \\& ’ in a string constant to include a literal ‘ & ’ in the replacement. For example, the following shows how to replace the first ‘ | ’ on each line with an ‘ & ’:
As mentioned, the third argument to sub() must be a variable, field, or array element. Some versions of awk allow the third argument to be an expression that is not an lvalue. In such a case, sub() still searches for the pattern and returns zero or one, but the result of the substitution (if any) is thrown away because there is no place to put it. Such versions of awk accept expressions like the following:
For historical compatibility, gawk accepts such erroneous code. However, using any other nonchangeable object as the third parameter causes a fatal error and your program will not run.
Finally, if the regexp is not a regexp constant, it is converted into a string, and then the value of that string is treated as the regexp to match.
substr( string , start [ , length ] )
Return a length -character-long substring of string , starting at character number start . The first character of a string is character number one. 49 For example, substr(«washington», 5, 3) returns «ing» .
If length is not present, substr() returns the whole suffix of string that begins at character number start . For example, substr(«washington», 5) returns «ington» . The whole suffix is also returned if length is greater than the number of characters remaining in the string, counting from character start .
If start is less than one, substr() treats it as if it was one. (POSIX doesn’t specify what to do in this case: BWK awk acts this way, and therefore gawk does too.) If start is greater than the number of characters in the string, substr() returns the null string. Similarly, if length is present but less than or equal to zero, the null string is returned.
The string returned by substr() cannot be assigned. Thus, it is a mistake to attempt to change a portion of a string, as shown in the following example:
It is also a mistake to use substr() as the third argument of sub() or gsub() :
(Some commercial versions of awk treat substr() as assignable, but doing so is not portable.)
If you need to replace bits and pieces of a string, combine substr() with string concatenation, in the following manner:
Return a copy of string , with each uppercase character in the string replaced with its corresponding lowercase character. Nonalphabetic characters are left unchanged. For example, tolower(«MiXeD cAsE 123») returns «mixed case 123» .
Return a copy of string , with each lowercase character in the string replaced with its corresponding uppercase character. Nonalphabetic characters are left unchanged. For example, toupper(«MiXeD cAsE 123») returns «MIXED CASE 123» .
In awk , the ‘ * ’ operator can match the null string. This is particularly important for the sub() , gsub() , and gensub() functions. For example:
Although this makes a certain amount of sense, it can be surprising.
Footnotes
Unless you use the —non-decimal-data option, which isn’t recommended. See section Allowing Nondecimal Input Data for more information.
Note that this means that the record will first be regenerated using the value of OFS if any fields have been changed, and that the fields will be updated after the substitution, even if the operation is a “no-op” such as ‘ sub(/^/, «») ’.
This is different from C and C++, in which the first character is number zero.
Источник



