- Виртуальный сетевой интерфейс в linux. TAP vs TUN
- Создаем виртуальный интерфейс в linux вручную
- Создаем интерфейс типа tun
- Создаем интерфейс типа tap
- Создаем интерфейс типа dummy
- Создаем виртуальный интерфейс в linux с помощью systemd-networkd
- Создаем интерфейс типа tun
- Создаем интерфейс типа tap
- Создаем интерфейс типа dummy
- OpenVPN Ubentu Server 20.04. Интерфейс tap0 создается, но не UPается сам
- Как работают сети, часть 2: отказоустойчивость с teaming, режем соединения с Traffic Control, а так же tap-интерфейсы и Linux Bridge
- Зачем нужны teaming, bonding, link aggregation и port trunking?
- Спускаемся с небес на землю
- Проверяем работу teaming
- Запускаем виртуальную машину с CentOS через libvirt
- Изучаем Linux Bridge
- tap-интерфейсы
- Как ограничить скорость интернета в libvirt?
- Что такое Linux Traffic Control?
- Добавляем второй интерфейс
- Устанавливаем и настраиваем teaming
- Проверяем работу teaming
- Пара слов о правильной автоматизации
- Подводим итоги
- Дополнительное чтение
Виртуальный сетевой интерфейс в linux. TAP vs TUN
Читатели, не нуждающиеся в теоретическом изложении концепции виртуальных сетевый интерфейсов Linux, могут сразу перейти к настройке по ссылкам:
Создавать сетевые интерфейсы в linux нам позволяют различные модули ядра. Но там, где для реальных железных сетевых карт эти модули ядра, или как их еще называют — драйверы, обеспечивают прием данных от стека TCP/IP и их формирование уже в виде электрического сигнала на сетевой карте, драйверы виртуальных сетевых интерфейсов (loopback) могут лишь, приняв эти данные, отдать их какому-нибудь приложению для дальнейшей обработки. Такая функциональность может быть востребована, если на вашем сервере установлены программы, использующие стек TCP/IP для обмена данными и, понятно, не нуждающиеся в выводе этих данных в реальную сеть. Пример: веб-сайт на drupal связывается с базой данных, установленной на этом же сервере:
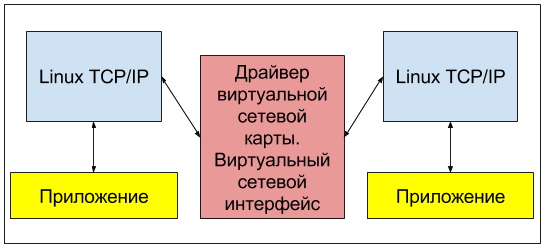
Другим распростаренным примером использования виртуальных сетевых интерфейсов (loopback) в linux может быть их использование для целей построения виртуальных частных сетей — VPN. Вы наверняка слышали о таких технологиях как OpenVPN, GRE, WireGuard и т.д. Каждый из этих демонов создает виртуальный сетевой интерфейс который служит для прозрачной маршрутизации данных между узлами, находящимися на удалении друг от друга и не имеющих возможности прямого взаимодействия. Рассмотрим общую сетевую топологию на примере OpenVPN:
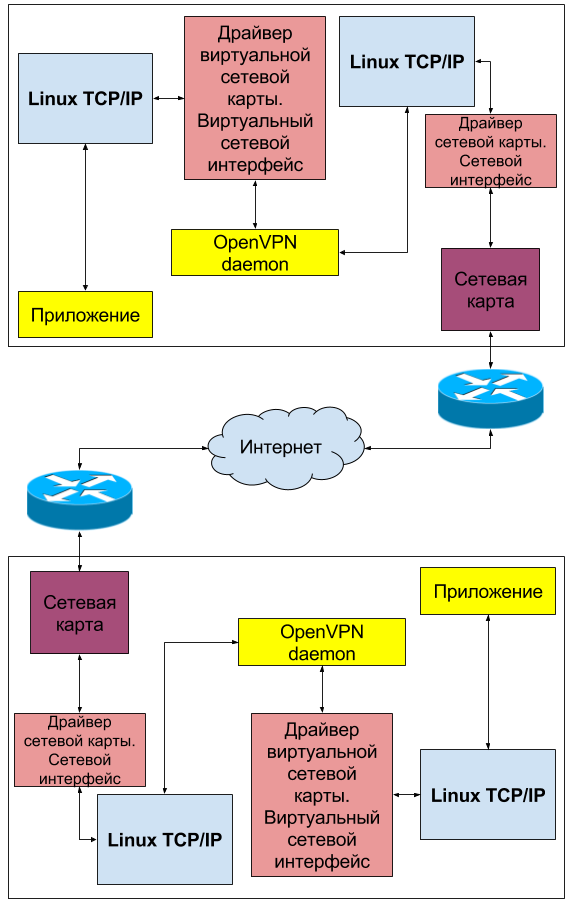
От используемого драйвера зависит тип интерфейса, его скорость, допустимый размер MTU и т. д. Совсем даже не обязательно, что загружать драйвер в ядро вам придется самостоятельно. Скорее всего, создавая интерфейс нужного типа, система сама подберет и загрузит требуемый драйвер. Вам лишь останется сконфигурировать уже работающий loopback интерфейс. В данной статье мы рассмотрим 3 возможных на конец 2016 года типа виртуальных интерфейсов в linux: tun, tap и dummy. Отличие интерфейсов tun и tap заключается в том, что tap старается больше походить на реальный сетевой интерфейс, а именно он позволяет себе принимать и отправлять ARP запросы, обладает MAC адресом и может являться одним из интерфейсов сетевого моста, так как он обладает полной поддержкой ethernet — протокола канального уровня (уровень 2). Интерфейс tun этой поддержки лишен, поэтому он может принимать и отправлять только IP пакеты и никак не ethernet кадры. Он не обладает MAC-адресом и не может быть добавлен в бридж. Зато он более легкий и быстрый за счет отсутствия дополнительной инкапсуляции и прекрасно подходит для тестирования сетевого стека или построения виртуальных частных сетей (VPN). Виртуальный интерфейс типа dummy очень похож на tap, разница лишь в том, что он реализуется другим модулем ядра.
Создаем виртуальный интерфейс в linux вручную
Создавать и удалять интерфейсы, назначать IP и MAC адреса, изменять MTU и многое другое нам помогает утилита ip. Пользоваться ip удобно и легко, но помните, что произведенные изменения будут потеряны после перезагрузки компьютера. Используйте ip в целях тестирования.
Создаем интерфейс типа tun
ip tuntap add dev tun0 mode tun
ip address add 192.168.99.1/30 dev tun0
ip address show tun0
2: tun0:
mtu 1500 qdisc noop state DOWN group default qlen 500
link/none
inet 192.168.99.1/30 scope global tun0
valid_lft forever preferred_lft forever
Как видим у нас теперь есть виртуальный интерфейс с именем «tun0», у него есть IP-адрес, и ни слова о MAC-адресе — всё, как мы и рассчитывали. Его уже можно пинговать, и на нем уже можно запускать слушающие сервисы. Но что будет, если мы попытаемся добавить этот интерфейс в бридж?
ip link set dev tun0 master br0
RTNETLINK answers: Invalid argument
Команда ip логичным образом выдала ошибку — нет никакого смысла добавлять в бридж интерфейс, не обладающий поддержкой ethernet.
Создаем интерфейс типа tap
ip tuntap add dev tap0 mode tap
ip address add 192.168.99.5/30 dev tap0
ip address show tap0
3: tap0:
mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d6:1c:67:cd:6f:80 brd ff:ff:ff:ff:ff:ff
inet 192.168.99.5/30 scope global tap0
valid_lft forever preferred_lft forever
У нас теперь появился новый виртуальный интерфейс с именем «tap0», у него есть как IP-адрес, так и MAC-адреса. Его также можно пинговать, и на нем также можно запускать слушающие сервисы. Команда, добавляющая интерфейс в бридж уже не выдаст ошибку, потому что это интерфейс, обладающий поддержкой ethernet:
ip link set dev tap0 master br0
Создаем интерфейс типа dummy
ip link add dev dum0 type dummy
ip address add 192.168.99.9/30 dev dum0
ip address show dum0
4: dum0:
mtu 1500 qdisc noop master br0 state DOWN group default qlen 1000
link/ether 1a:37:3b:0f:da:be brd ff:ff:ff:ff:ff:ff
inet 192.168.99.9/30 scope global dum0
valid_lft forever preferred_lft forever
Вы наверняка заметили, что команда для добавления интерфейса изменилась. Ничего необычного. Так написана утилита «ip». Ну и конечно, виртуальный интерфейс типа dummy можно легко добавить в бридж:
ip link set dev dum0 master br0
Создаем виртуальный интерфейс в linux с помощью systemd-networkd
В systemd-networkd за создание интерфейсов отвечают одни конфигурационные файлы, имеющие суффикс «.netdev», а за их настройку другие, имеющие суффикс «.network». Соответственно нам понадобиться в /etc/systemd/network создать по паре конфигурационных файлов для каждого из исследуемых типов интерфейсов
Создаем интерфейс типа tun
Создадим соответственно файлы tun0.netdev с содержимым:
[NetDev]
Name=tun0
Kind=tun
Создаем интерфейс типа tap
Создадим соответственно файлы tap0.netdev с содержимым:
[NetDev]
Name=tap0
Kind=tap
Создаем интерфейс типа dummy
Создадим соответственно файлы dum0.netdev с содержимым:
[NetDev]
Name=dum0
Kind=dummy
Стоит отметить, что если вы планируете маршрутизировать траффик через виртуальные интерфейсы ( а, используя их для цели создания виртуальных частных сетей (VPN), вы точно этого хотите), то в конфигурационный файл в секии «Network» следует добавить диррективу «IPForward=yes».
Источник
OpenVPN Ubentu Server 20.04. Интерфейс tap0 создается, но не UPается сам
Доброго времени суток. В связи с последними событиями, часть сотрудников хотят на удаленку пересадить. Настраиваю OpenVPN на Ubuntu Serser 20.04. Все настроил, но есть один косяк — tap0 после старта OpenVPN создается в дауне и пока не сделаешь ifconfig tap0 192.168.8.4 up соединения нет. Вручную на серваке ввел (скриптом даже), все работает
Внутренняя сеть предприятия 10.127.x.x внешний IP пусть будет 1.2.3.4 (если в моей ошибке потребуется, пускай так выглядит) на tap0 вешаю 192.168.8.4 (для примера как в конфиге, потом может переделаю)
server-bridge 192.168.8.4 255.255.255.0 192.168.8.128 192.168.8.254 #@@ tup0 enp6s0
keepalive 10 120
push «dhcp-option DNS 10.127.1.5»
push «dhcp-option DNS 10.127.1.6»
push «dhcp-option MyORG myorg.local»
push «route 10.127.0.0 255.255.0.0»
push «route 192.168.8.0 255.255.255.0»
Что я не доделал, что бы заработало на автомате?
Перезагрузку делаешь — только после ifconfig tap0 192.168.8.4 начинает работать.
Или я по каким-то древним инструкциям пытаюсь настроить и сейчас по другому более правильно настраивать доступ с домашних компов к своим рабочим?


По древней инструкции https://openvpn.net/community-resources/ethernet-bridging/ как раз положен скрипт, делающий up. Вот другая, может ещё более древняя: https://help.ubuntu.com/community/OpenVPN , там скрипты дёргает openvpn сервер.
Поэтому вопрос, по каким именно инструкциям делаете вы?
По каким делаю, сейчас не скажу (конфиг я показал). Я дома, сервак на работе. Я то все настроил, работает, но вот ТАПу почему-то вручную только стартовать приходится. Если его только запихать в старт после сервиса openvn как вариант. Но это не правильно по идее. Сам опенвпн его должен поднимать. Ну а если его поднимать отдельно потом, то пока мой косяк, что я с синтаксисом запуска запутался. Просто ifconfig тд.дп. уже не канает как раньше можно было в rc.скриптах
Источник
Как работают сети, часть 2: отказоустойчивость с teaming, режем соединения с Traffic Control, а так же tap-интерфейсы и Linux Bridge

В статье Как работают сети: что такое свитч, роутер, DNS, DHCP, NAT, VPN и ещё с десяток необходимых вещей я рассказал про основные компоненты компьютерных сетей. Её прочтение необходимо перед тем, как браться за текст ниже.
За основу статьи взята настройка teaming в Linux. Настраивать его мы будем в виртуальном окружении, а значит, нам понадобится libvirt, который мы изучили в статье Основы виртуализации и введение в KVM.
На этот раз мы не будем вслепую полагаться на работу libvirt. Вместо этого мы попытаемся понять, что кроется за парой строчек простого XML-файлика, определяющего виртуалку или сети. В результате мы узнаем, как работают и для чего нужны Linux bridge, tap-интерфейсы и Linux Traffic Control, и как они используются для виртуализации.
Начнём мы с того, что такое teaming.
Зачем нужны teaming, bonding, link aggregation и port trunking?
Если не погружаться в полемику, рассмотр конкретной технической реализации и набора фич, то термины teaming, bonding, link aggreation и port trunking означают одно и то же: объединение нескольких физических сетевых интерфейсов в один логический, с целью увеличить пропускную способность и/или обеспечить отказоустойчивость.
Мы будем использовать термин «teaming», потому что именно он используется в современных весиях Linux.
Помимо teaming, в Linux есть bonding, на замену которому и пришёл teaming. Чем в контексте Linux teaming отличается от bonding можно почитать в документации от Red Hat — согласно табличке по ссылке, использовать teaming в новых окружениях особого смысла нет, но здесь я могу ошибаться. Максимально любопытному читателю предлагается прочитать документацию по bonding — мало ли, вдруг придётся работать именно с ним.
Я не буду погружаться в миллион деталей касательно того, как именно работает teaming. Хочешь ли ты уже сейчас знать, что teaming реализован в виде маленького шустрого драйвера для ядра Linux и набора пользовательских API для пущей гибкости и расширяемости? Наверное, нет. Но когда такое желание появится, в конце статьи будет восхитительный список ссылок, в том числе на подробнейшее описание внутреннего строения teaming в Linux.
Теперь разберёмся, что значит «увеличить пропускную способность» и «обеспечить отказоустойчивость».
Допустим, у сервера один NIC. Если он сгорит, то сервер останется без сети. А если у сервера два NIC, то сервер будет видеть их как два разных NIC, с двумя разными IP-адресами. В результате, одно и тоже соединение знает только об одном интерфейсе. Если сгорит один из двух, то все соединения, проходящие через сгоревший NIC, пропадут без шанса на реабилитацию.

А вот если использовать teaming, оба NIC будут спрятаны за одним программным интерфейсом, за который и отвечает teaming. Благодаря этому, если один из NIC сгорит или, например, его вырвут из сервера, то никакого перебоя в связи не будет, так как трафик автоматически пойдёт через оставшийся в живых интерфейс. С отказоустойчивостью разобрались.

Теперь допустим, что у нас есть сервер на котором хранится куча файлов, которые постоянно скачивает кто угодно из локальной сети. Если в этот файловый сервер воткнут один NIC и два других сервера будут пытаться скачивать файлы одновременно, они будут делить пропускную способность этого NIC пополам. А если в файловом сервере будет два NIC, объединённых при помощи teaming, то каждый из скачивающих серверов будет наслаждаться максимальной (для одного NIC) скоростью скачивания.

Спускаемся с небес на землю
Очень важно сделать отступление и разъяснить пару моментов.
Во-первых, если сервер с одним NIC будет пытаться скачать файл с сервера, в котором два NIC, то скорость скачивания не удвоится — потому что скорость будет ограничена пропускной способностью NIC скачивающего сервера. Другое дело, если в оба сервера воткнуть по два NIC.

Во-вторых, если в сервер воткнуть два NIC и попытаться скачать большой файл, то от наличия второго NIC скорость скачивания не удвоится (но слегка увеличится, возможно). Преимущество будет во время параллельного скачивания нескольких файлов — тогда трафик пойдёт как надо, и оба файла будут качаться, теоретически, с максимальной скоростью, доступной каждому из NIC.
В-третьих, наличие teaming не решает все проблемы с отказоустойчивостью. Не забываем, что NIC подсоединены к роутеру (или свитчу, или к мосту, или к хабу). И если сгорит роутер (или свитч, или мост, или хаб), то даже пять NIC на сервере не спасут от падения сети. Поэтому нужно думать ещё и об отказоустойчивости роутеров (а так же свитчей, мостов и хабов).
Проверяем работу teaming
Теперь мы знаем, зачем нужен teaming. Проверять его работу в реальных условиях проблематично — нужны железки и провода. У меня под рукой есть только ноутбук с одним NIC, а значит, чтобы провести интересные тесты, придётся воспользоваться виртуализацией. Напомню, что максимально желательно заранее прочитать нашу статью про виртуализацию, чтобы не только разобраться в теме, но и настроить локальное окружение для работы с libvirt + KVM.
Запускаем виртуальную машину с CentOS через libvirt
В файлике заменяем в самом конце PUBLIC_KEY на свой публичный SSH ключик.
Запускаем новую виртуалку этой командой (не забудь обновить путь до Kickstart файла и до образа с Centos):
Размер диска и ОЗУ на твоё усмотрение.
Ищем IP адрес при помощи sudo virsh net-dhcp-leases default и пытаемся зайти по SSH root пользователем. Получилось? Идём дальше.
Изучаем Linux Bridge
Все ресурсы, управляемые libvirt — виртуалки, сети, хранилища — описаны в XML файлах. Внося изменения в эти файлы, можно менять состояние ресурсов. Например, можно изменить настройки сетевого интерфейса нашей виртуалки.
Откроем XML виртуалки:
И найдём там определение сетевого интерфейса:
Здесь мы видим, в какую сеть «воткнут» этот интерфейс (а правильнее: в свитч какой сети) — , видим (и можем поменять) MAC-адрес этого интерфейса и остальные его параметры.
Убедимся в том, что этот интерфейс и правда воткнут в виртуальный свитч, из которого и состоит сеть libvirt. Чтобы узнать, какой именно свитч используется для сети мы можем посмотреть XML определение самой сети:
Вот определение свитча:
. Теперь мы знаем, что он называется virbr0 . При помощи команды brctl посмотрим, какие интерфейсы к нему подключены:
Два интерфейса — один принадлежит хосту, а другой нашей виртуалке (vnet0). У интерфейса хоста есть IP адрес внутри сети libvirt (192.168.122.1/24), и через этот интерфейс идёт весь трафик виртуалок во внешний мир. Ты можешь сам убедиться в этом, поигравшись с командами ip r и ip addr на хосте и внутри виртуалки, а также посмотрев результат traceroute до соседней виртуалки и, например, до mkdev.me.
Теперь посмотрим какие MAC-адреса у подсоединённых интерфейсов:
Результат, конечно, сбивает с толку. Почему адрес NIC хоста выводится дважды, а NIC виртуалки — трижды? И почему в одном случае NIC виртуалки начинается с «52», а в двух других — с «fe»? И почему в первом случае «is local?» равно «no» и выводится какой-то ageing timer? Сейчас попробуем разобраться.
Чтобы понять, почему MAC-адреса дублируются, нам понадобится другая утилита для работы с Linux Bridge — bridge . С её помощью мы сможем посмотреть Forwarding Database (fdb). fdb — это, грубо говоря, таблица маршрутизации на втором уровне сети. Обычно мы имеем дело с маршрутизацией на третьем уровне, или, если так понятней, на уровне IP-адресов. Но свитч чаще всего относится ко второму уровню и оперирует MAC адресами. Посмотрим fdb для моста virbr0:
Мы проигнорируем 01:00:5e:00:00:01 , 01:00:5e:00:00:fb , а также все строки, начинающиеся с 33:33 . В отдельной статье я расскажу про IPv6 и чем он отличается от IPv4, после чего станет понятно, зачем нужны эти бесконечно дублирующиеся записи. Пока что сделаем вид, что их вовсе нет:
Так же выкинем строчки, ответственные за сам свитч, оставив только записи, релевантные для нашей виртуалки:
У Linux Bridge (да и не только у него) есть способность добавлять записи в fdb динамически, «обучаясь» на проходящем трафике. Пришли фреймы от MAC-адреса 52:54:00:95:3f:7b? Добавим его автоматом, судя по всему он подключён к свитчу. А если от него долго не будет вестей, то так же автоматом и удалим. Именно это и означают колонки «is local?» и «ageing» — первая показывает, настроен ли интерфейс в свитче статически (
= воткнут в него напрямую), а вторая показывает сколько прошло времени с последнего контакта с этим интерфейсом.
Команда bridge fdb не показывает ageing, но мы видим маршрут, который был автоматически добавлен:
В случае статически настроенных интерфейсов ageing не имеет смысла, потому что свитч всегда знает, что они подключены. За подключение интерфейсов виртуалки к свитчу отвечает libvirt (а на самом деле — qemu), поэтому особого смысла в динамическом добавлении маршрутов нет — свитч и так знает всё, что нужно про соединение с виртуалкой. Поэтому мы можем вырубить learning полностью:
Теперь у нас всего две записи для интерфейса виртуалки:
Внимательный читатель уже давно кричит в экран: «почему MAC-адрес виртуалки и MAC-адрес в свитче разные. «. Это отличный вопрос.
Как убедиться, что libvirt и правда использует QEMU? Заходим в /var/log/libvirt/qemu , ищем лог с названием виртуалки и видим примерно такое.
tap-интерфейсы
И правда, если зайти в виртуалку и посмотреть MAC-адрес её NIC, мы увидим 52:54:00:95:3f:7b , в то время как brctl showmacs показывает fe:54:00:95:3f:7b . Разница лишь в первых двух символах — fe вместо 52 . Дело в том, что для каждой виртуалки libvirt создаёт на хосте специальный интерфейс — tap-интерфейс.
tap-интерфейс — это такой виртуальный интерфейс, работающий на уровне ядра Linux. Вместо того, чтобы принимать и передавать данные на физическом уровне, tap-интерфейс получает данные программно и программно же их передаёт.
Если сильно упрощать, то tap-интерфейс — это файловый дескриптор, в который, в нашем случае, Linux bridge отправляет Ethernet фреймы. QEMU считывает их из этого дескриптора и отправляет в виртуалку.
Не знаешь, что такое файловый дескриптор? Не беда. Мы об этом расскажем в отдельной статье. Подпишись на нашу рассылку (форма внизу), чтобы узнать о её появлении первым.
Для виртуалки это выглядит так, будто бы фреймы пришли на физический интерфейс — тот самый, у которого MAC-адрес 52:54:00:95:3f:7b . Это очень важно: tap-интерфейс — это реализация виртуализации сетевого интерфейса, и виртуалка ничего не знает об этой реализации. Виртуалка считает, что у неё полноценный физический интерфейс.
Нам сейчас не очень важно, как именно и когда создаётся tap-интерфейс. libvirt на то и существует, чтобы спрятать от нас множество мелких деталей до тех пор, пока у нас не появится необходимость в них разбираться. Тем не менее, давай выполним на хосте пару команд, просто чтобы знать, куда смотреть в будущем.
Во-первых, давай глянем полный конфиг виртуалки. Когда мы смотрели интерфейс виртуалки через virsh edit , мы наблюдали статичный постоянный конфиг. Но конфиг уже запущенной виртуалки слегка отличается, так как в процессе запуска libvirt делает разные полезные штуки — например, создаёт tap-интерфейс и связь между ним и виртуалкой. Давай посмотрим, как выглядит конфиг интерфейса уже запущенной виртуалки:
Здесь уже виден наш tap-интерфейс: . tap-интерфейсы существуют на хосте, и мы можем посмотреть их список командой ip tuntap :
И так как это полноценный (хоть и виртуальный) интерфейс, мы увидим его в списке интерфейсов хоста:
В конце будет пара ссылок на статьи, в которых можно узнать больше про tap и tun. tun — это как tap, только не на втором уровне сети, а на третьем.
Как ограничить скорость интернета в libvirt?
Продемонстрировать отказоустойчивость сервера с настроенным teaming будет весьма несложно. Но вот как показать повышенную пропускную способность?
Откроем редактирование XML-определения виртуалки: virsh edit teaming , найдём там определение интерфейса виртуалки и добавим блок :
Теперь скорость соединения будет ограничена 128kbs. Мы можем задать скорость скачивания и прочие детали при помощи различных атрибутов как для входящих, так и для исходящих соединений. О всех доступных опциях лучше всего читать в документации libvirt. А пока проверим, что ограничение и правда действует. Сначала перезапустим виртуалку:
Зайдём туда по SSH и попробуем скачать какой-нибудь файл через, например, wget :
Смотрим на процесс скачивания и видим, что скорость и правда ограничена. Но как это работает?
Что такое Linux Traffic Control?
Traffic control позволяет детально управлять пакетами, которые проходят через сетевое устройство. Можно указать скорость обработки очереди пакетов, можно фильтровать и отмечать пакеты и выкидывать их, если они не соответствуют нашим требования. При желании можно сделать так, чтобы, например, у SSH соединения сохранялась всегда одна и та же скорость, даже если через тот же интерфейс идёт скачивание крупных файлов. В общем, полный набор инструментов для работы с сетевыми пакетами — была б фантазия для чего их применить.
Quality of Service (QoS) — синоним Traffic Control.
Как и все хорошие вещи в этой жизни, управление сетевыми пакетами проходит в ядре Linux — через packet scheduler. А чтобы настроить его работу, существует утилита tc . Traffic Control в Linux — штука очень гибкая, комплексная, мощная. Постараемся рассмотреть основные компоненты контроля трафика, а затем посмотрим как их настроил libvirt.
Контроль трафика основан на старых добрых очередях, обработка которых контролируется через Queueing Disciplines (qdisc). У каждого сетевого интерфейса есть одна очередь по-умолчанию, к которой не применяется никаких особенных правил — пакеты входят в очередь, а затем достаются оттуда как можно быстрее. Если в сети есть неполадки, то пакеты могут какое-то время проваляться в очереди — таким образом избежав утраты данных при передаче.
Является ли qdisc очередью? После изучения многих источников, можно сказать, что термины «queue» и «qdisc» взаимозаменяют друг друга. В основе всего лежит очередь как структура данных, а qdisc — это некие правила обработки этой очереди.
Но от одной FIFO очереди толку мало. Поэтому Linux позволяет строить сложные деревья из очередей, с разными правилами обработки пакетов от разных источников, для разных портов.
qdisc’s бывают двух типов — без классов (classless qdisc) и с классами (classful qdisc). qdisc’s без классов просто пропускают через себя трафик (с какой-нибудь обработкой, типа добавления задержки выпуска пакета из очереди). qdisc с классами содержат в себе другие очереди и классы, и как правило фильтруют пакеты и распихивают их по нескольким очередям сразу.
Не волнуйся, если не до конца поймёшь всё, что мы увидим дальше. Внимательно изучи материалы по Linux Traffic Control в конце статьи, а затем вернись к примерам выше — тогда всё станет ясно.
Что нас интересует сейчас, так это взаимосвязь между в определении интерфейса виртуалки и настройками контроля траффика на хосте. Как я уже сказал, за настройку отвечает утилита tc , при помощи которой мы можем легко увидеть, что именно libvirt нам настроил:
У нашего tap-интерфейса три qdisc. У каждого интерфейса есть две «ненастоящие» qdisc — root и ingress. Ненастоящие они из-за того, что сами по себе они ничего не делают, а являются точками к которым подключаются другие qdisc.
При этом, к ingress нельзя прикрепить ничего, кроме фильтрации пакетов и опционального отказа от пакета. Реализовано это так, потому что у нас нет настоящего контроля за входящими данными — мы не можем влиять на уровне OS на скорость входящего трафика. В том числе поэтому не существует настоящей защиты от DDoS. Всё, что мы можем — это как можно быстрее и раньше блокировать трафик или помечать его для последующей обработки — именно этим и занимается ingress qdisc, которая стоит в самом начале обработки входящего трафика. Мы не добавляли никакой фильтрации для входящего трафика, поэтому ingress qdisc выглядит скучно.
Две остальные qdisc связаны друг с другом. Во главе стоит qdisc htb 1: , родителем которого является root. Ниже неё по дереву находится qdisc sfq 2: — это видно по parent 1:1 . htb и sfq — это отдельные типы очередей, встроенные в Linux. По ссылкам объяснение их работы вместе с картинками. Если вкратце, то htb позволяет ограничивать скорость трафика, а sfq пытается равномерно распределить выходящие пакеты. При этом htb — это classful qdisc, а sfq — classless ( man tc докажет).
Теперь глянем классы:
Вот он, наш ограничитель скорости — мы видим те самые заветные 1024Kbit .
И снова — libvirt спрятал от нас сложную и дико полезную часть Linux, позволив несколькими человекопонятными строчками XML настроить Linux packet scheduler для tap-интерфейса виртуальной машины.
Добавляем второй интерфейс
Пора перейти к teaming. Но для этого нам нужен второй интерфейс, который очень легко добавить при помощи virsh:
Ты можешь убедиться в наличии нового интерфейса либо посмотрев XML виртуалки, либо зайдя в неё и выполнив ip addr , либо выполнив ту же самую команду на хосте, на котором появился новый tap-интерфейс. DHCP-сервер даже любезно выдал новому интерфейсу IP-адрес — хоть он нам и не нужен.
Время настроить teaming!
Устанавливаем и настраиваем teaming
Заходим по SSH (или при помощи Spice) в виртуалку и отключаем одно из соединений:
Если ты зашёл в виртуалку по SSH через IP-адрес интерфейса, соединение которого выключил, то тебе придётся зайти заново — ведь teaming ещё не настроен.
Ставим teamd: yum install teamd NetworkManager-team -y . Подгружаем модуль: modprobe team . Убеждаемся, что всё в порядке: lsmod | grep team .
У меня после установки NetworkManager-team вылеза ошибка Error: Could not create NMClient object: GDBus.Error:org.freedesktop.DBus.Error.UnknownMethod: Method «GetManagedObjects» with signature «» on interface «org.freedesktop.DBus.ObjectManager» doesn’t exist . Ребут помог.
Дальше у нас есть на выбор несколько вариантов настройки teaming:
- Путём ручного редактирования network-scripts
- При помощи nmcli — здесь нам пригодится man nmcli-examples
- При помощи nmtui
Первые два способа вынуждают нас запоминать разные последовательности команд, в то время как текстовый интерфейс nmtui позволит сделать всё быстро и просто. Но быстро и просто можно сделать и самому, поэтому посмотрим, как сделать всё через nmcli :
Теперь у нас есть team интерфейс с одним настоящим интерфейсом и IP-адресом. Теперь, если ты зашёл в виртуалку по SSH, выйди и зайди снова используя IP team интерфейса — иначе потерешь соединения, выполняя следующую команду:
Нам нужно убрать любые настроенные соединения у используемых для team интерфейсов. Добавляем второй интерфейс:
Посмотрим на наш новый интерфейс и его адрес командой ip addr :
team0 выводится точно так же, как любой другой интерфейс, у него есть IP-адрес, MAC-адрес и даже свой qdisc. Мы уже немного знаем про Traffic Control, поэтому строчки типа qdisc pfifo_fast и qlen 1000 нас не удивляют. Ещё обратим внимание на то, что у все трёх интерфейсов теперь одинаковые MAC-адреса — это поведение по-умолчанию, но его можно изменить при желании.
Теперь немного поиграем с настройками нашего team. Teaming поддерживает разные режимы работы, называемые runners . Самый простой — это roundrobin . Из названия понятно, что интерфейсы, в которые будут идти пакеты, будут обрабатываться по кругу. Есть ещё, например, activebackup — в этом случае используется только один интерфейс, и если он упадёт, трафик автоматически пойдёт на следующий доступный. man teamd.conf описывает
остальные доступные режимы. Примеры определения runners можно глянуть /usr/share/doc/teamd/example_configs/ (если такой папки нет, то попробуй locate example_configs ). Мы же попробуем activebackup .
Цель упражнения такая: настроить activebackup , в котором новый интерфейс будет основным, а медленный интерфейс (ограниченный при помощи tc ) — бэкапом. А затем мы запустим в виртуалке скачку крупного файла и «выдернем» новый, быстрый интерфейс из сервера.
Последняя команда покажет примеры использования опции team.config:
При грамотном использовании man и прочих доступных в системе информационных средств нам не нужно будет хаотично гуглить что попало. Мы можем просто внимательно изучить локальную документацию и найти подробнейшие описания с кучей примеров! Ещё один пример конфигурации мы может обнаружить в man teamd.conf :
Создадим файлик teaming-demo.conf с похожим содержимым, но обновленным для наших интерфейсов:
Здесь вы задали режим activebackup и выдали интерфейсу ens9 (быстрому) больший приоритет. Подгрузим эти настройки:
При помощи teamdctl team0 state убедимся, что настройки применились:
Упс, ещё не применились! Дело в том, что конфиг загружается при создании team-интерфейса. Воспользуемся этим как возможностью проверить, выдержат ли наши настройки ребут, и перезапустим виртуалку. Если всё прошло успешно, то после перезапуска мы сможем зайти в виртуалку по SSH, выполнить teamdctl team0 state и увидеть такое:
Время вырвать интерфейс!
Проверяем работу teaming
В видео ниже я сначала зайду в виртуалку и стартану скачивание файла в отдельной сессии, а затем отцеплю основной интерфейс при помощи virsh. Вернувшись в сессию со скачкой файла, можно увидеть, что скорость упала до 128кбс, но само скачивание не прервалось, несмотря на то, что одного из интерфейсов не стало.
Пара слов о правильной автоматизации
Прежде чем перейти к итогам, снова поговорим о реальной жизни. Пара вещей, которые нужно держать в голове:
- Руками teaming настраивать каждый раз необязательно. Его можно настроить, например, при помощи Kickstart
- nmcli , tc и другие утилиты очень полезны для быстрой настройки и дебага, но в реальном окружении нужно всё автоматизировать при помощи подходящих инструментов — например, Chef/Puppet/Ansible.
Подводим итоги
Изначально я думал, что это будет небольшая статья про teaming в Linux. Но как только я начал её писать, сразу понял, что придётся рассказать о многих других вещах.
Мы только что вживую потрогали свитчи, погрузившись в такие детали, как fdb.
Мы узнали, что такое tap-интерфейсы, и какую роль они играют в виртуализации сетей в Linux.
Мы посмотрели Linux Traffic Control, и теперь мы знаем чуть больше о Linux networking stack. Теоретически, вооружившись tc мы теперь сможем выстраивать очень хитрые цепочки обработки сетевого трафика.
Наконец, мы пощупали teaming, убедившись в его эффективности. Возможно, однажды это пригодится нам в работе. А если нет, то мы, по крайней мере, будем знать о том, что так можно и как это работает.
Всю дорогу мы использовали libvirt и теперь знаем, насколько сильно он облегчает работу. За парой строчек XML-конфигурации скрывается сложная и гибкая настройка множества встроенных в Linux инструментов, работающих на самых разных уровнях. И в сумме эти инструменты и предоставляют виртуализацию, на которой, напомню, построены все современные облачные платформы.
Надеюсь, теперь сети стали для тебя чуточку понятней, виртуализация кажется не такой волшебной штукой, а зацепки и примеры использования дюжины разных инструментов помогут тебе более эффективно разбираться в любых связанных с инфраструктурой проблемах.
Дополнительное чтение
В ходе подготовки к этой статьи были прочитаны сотни статей, страниц документации и отрывков книг. Мы покрыли множество разных тем, но ни в одну не копнули по-настоящему глубоко. Ниже как раз ссылки для углублённого изучения материала:
- man tc , man teamd.config , man bridge , man brctl — в первую очередь лучше смотреть документацию, которая уже доступна на машине.
- teamd infrastructure specification расскажет о внутреннем устройстве teaming в Linux простыми словами создателей teamd
- Configure Network Teaming — документация по teaming от RedHat
- Linux Bridge and Virtual Networking — в этой статье автор показывает, как создать Linux bridge и подключить к нему пару интерфейсов самостоятельно, без помощи libvirt.
- Tap Interfaces and Linux Bridge — тот же автор, но на этот раз про tap-интерфейсы, в картинках и с очень хорошими объяснениями
- Tun/Tap interface tutorial — статья 2010 года, в которой показано создание новых интерфейсов кодом на C
- QEMU Networking — хорошие объяснения различных видов сетей в QEMU
- VLAN filter support on bridge — анонс поддержки VLAN для Linux Bridge
- Proper isolation of Linux bridge — о практическом применение VLAN в Linux Bridge, очень доступно и в картинках
- Linux Advanced Routing & Traffic ControlHOWTO — огромная мини-книжка про Traffic Control , с очень доступными объяснениями и иллюстрациями (в виде ASCII,правда)
- Differentiated Service on Linux HOWTO — иллюстрированное объеснение почти всех нужных типов qdisc. Посмотри там про HTB и sfq, чтобы мгновенно понять, как они работают.

Мы рассказываем, как стать более лучшим разработчиком, как поддерживать и эффективно применять свои навыки. Информация о вакансиях и акциях эксклюзивно для более чем 8000 подписчиков. Присоединяйся!

- mkdev
- Менторы
- Специализации
- Контент
- Стать ментором
- О проекте
- Для компаний
- Что такое менторство
- Как проходит обучение
- Цены
- FAQ
- Impressum
- Аккаунт
- Записаться
- Войти
- Соцсети





© Copyright 2014 — 2021 mkdev | Privacy Policy | Lang: Russian
Источник



