- How to Schedule a Task in Linux?
- Schedule tasks in Linux
- Task scheduler in linux
- 13.1 Introduction #Edit source
- 13.1.1 Preemption #Edit source
- 13.1.2 Timeslice #Edit source
- 13.1.3 Process Priority #Edit source
- 13.2 Process Classification #Edit source
- 13.3 Completely Fair Scheduler #Edit source
- 13.3.1 How CFS Works #Edit source
- 13.3.2 Grouping Processes #Edit source
- 13.3.3 Kernel Configuration Options #Edit source
- 13.3.4 Terminology #Edit source
- 13.3.4.1 Scheduling Policies #Edit source
- 13.3.5 Changing Real-time Attributes ofВ Processes with chrt #Edit source
- 13.3.6 Runtime Tuning with sysctl #Edit source
- 13.3.7 Debugging Interface and Scheduler Statistics #Edit source
- 13.4 For More Information #Edit source
How to Schedule a Task in Linux?
In the case of Linux, it comes with two basic but powerful tools: Cron daemon (default task scheduler) and at (more suitable for one-time task scheduling).
In this guide, check out how to schedule a task in Linux.
Schedule tasks in Linux
Cron
The cron daemon is responsible for running a lot of jobs at specific times. These tasks are generally run in the background at scheduled times. It offers great flexibility irrespective of the task, irrespective of the interval (hour, week, month, year, or whatever).
Cron keeps track of its actions using the crontab file. The crontab file is a script that contains all the necessary information to run all the cron jobs.
Let’s have a quick look at some of the basic usage of cron. In the case of any of the following commands, it’ll be configured for the root user if it’s run with sudo privilege. For the demonstration, I’ve grabbed a sample crontab file from here.
To list all the scheduled cron jobs for the current user, run the following command. It’ll print all the contents of the crontab file.
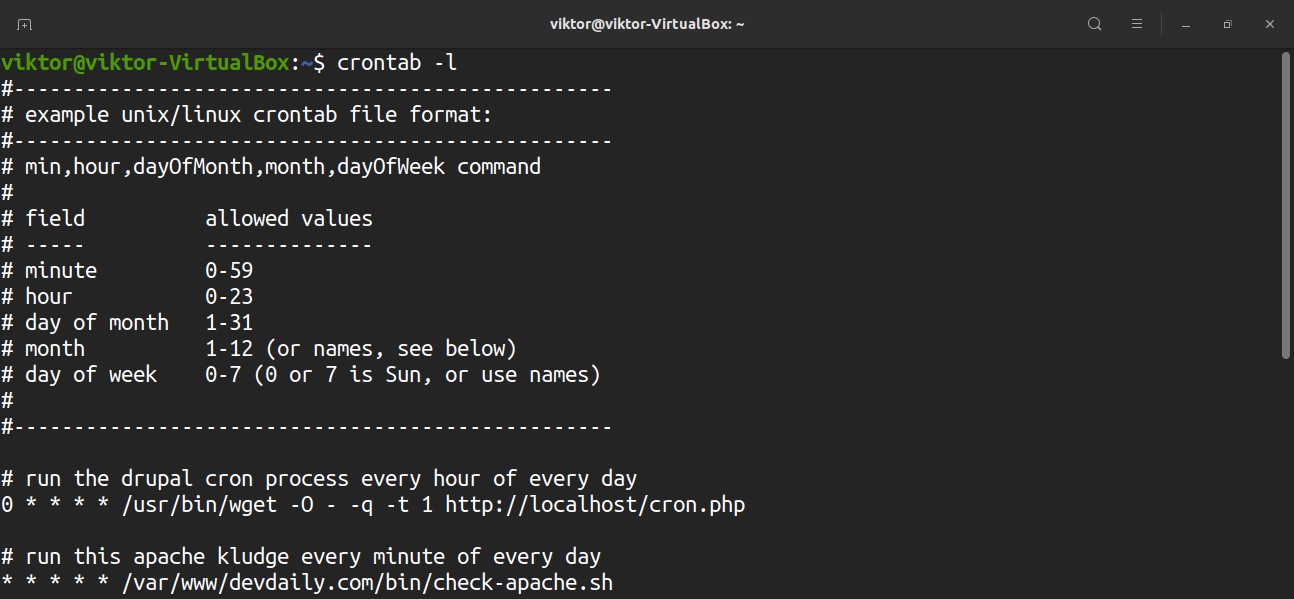
Want the cron job list for a different user? Run this command instead.
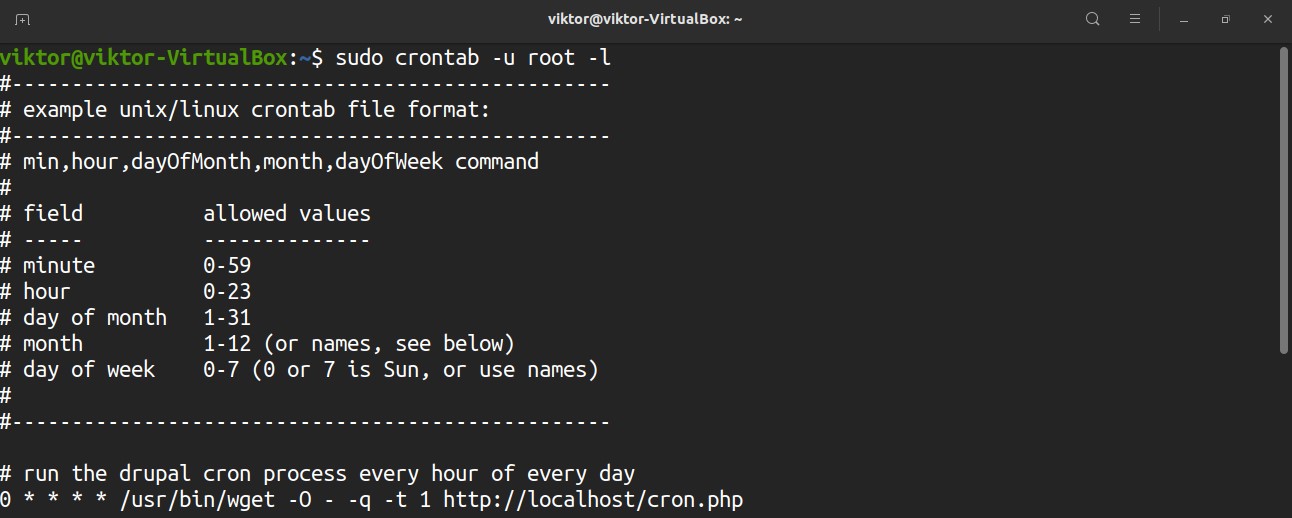
To edit the crontab script, run the command. To edit the crontab file for root, run the following command with sudo privilege.
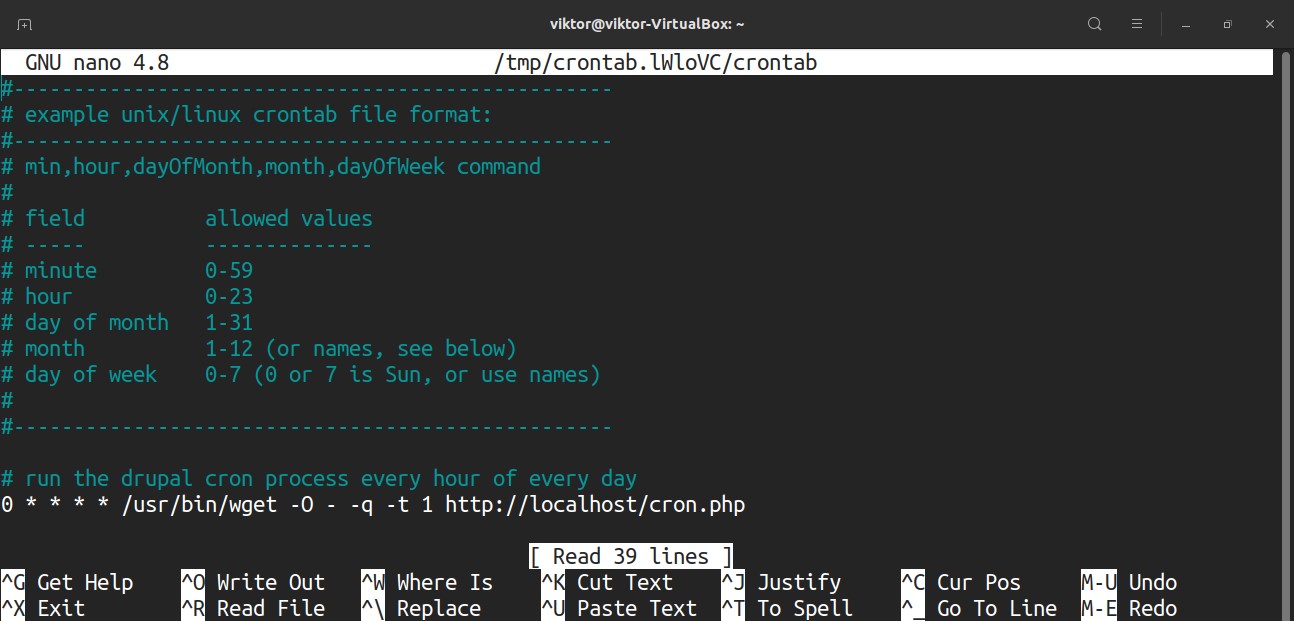
Each line in the crontab script defines a task. Here’s a quick breakdown of the crontab entries.
Here’s a list of all the possible values for all these fields. If used an asterisk (*) instead of a numeric value, every possible value of the field will be used.
- minute: 0 to 59
- hours: 0 to 23
- day of the month: 1 to 31
- month: 1 to 12
- day of the week: 0 (Sunday) to 6 (Saturday)
For an in-depth guide on how to use crontab to automate tasks, check out how to setup cron jobs in Linux. Here’s another quick example of a cron job running every minute.
at
While cron is the primary way of task scheduling, at offers the ability to run a command/script at a specific time or at a fixed interval, note that at will run the target job once whereas cron would re-run the job at the interval. The at tool is less popular compared to cron, but it’s relatively easier to use. You can use certain keywords like midnight or teatime (4 P.M.).
This tool doesn’t come pre-installed in most of the Linux distros. To install at, run the appropriate command according to your distro.
For Debian/Ubuntu and derivatives.

For CentOS/RHEL and derivatives.
Источник
Task scheduler in linux
Modern operating systems, such as SUSEВ® Linux Enterprise Server , normally run many tasks at the same time. For example, you can be searching in a text file while receiving an e-mail and copying a big file to an external hard disk. These simple tasks require many additional processes to be run by the system. To provide each task with its required system resources, the Linux kernel needs a tool to distribute available system resources to individual tasks. And this is exactly what the task scheduler does.
The following sections explain the most important terms related to a process scheduling. They also introduce information about the task scheduler policy, scheduling algorithm, description of the task scheduler used by SUSE Linux Enterprise Server , and references to other sources of relevant information.
13.1 Introduction #Edit source
The Linux kernel controls the way that tasks (or processes) are managed on the system. The task scheduler, sometimes called process scheduler , is the part of the kernel that decides which task to run next. It is responsible for best using system resources to guarantee that multiple tasks are being executed simultaneously. This makes it a core component of any multitasking operating system.
13.1.1 Preemption #Edit source
The theory behind task scheduling is very simple. If there are runnable processes in a system, at least one process must always be running. If there are more runnable processes than processors in a system, not all the processes can be running all the time.
Therefore, some processes need to be stopped temporarily, or suspended , so that others can be running again. The scheduler decides what process in the queue will run next.
As already mentioned, Linux, like all other Unix variants, is a multitasking operating system. That means that several tasks can be running at the same time. Linux provides a so called preemptive multitasking, where the scheduler decides when a process is suspended. This forced suspension is called preemption . All Unix flavors have been providing preemptive multitasking since the beginning.
13.1.2 Timeslice #Edit source
The time period for which a process will be running before it is preempted is defined in advance. It is called a timeslice of a process and represents the amount of processor time that is provided to each process. By assigning timeslices, the scheduler makes global decisions for the running system, and prevents individual processes from dominating over the processor resources.
13.1.3 Process Priority #Edit source
The scheduler evaluates processes based on their priority. To calculate the current priority of a process, the task scheduler uses complex algorithms. As a result, each process is given a value according to which it is “ allowed ” to run on a processor.
13.2 Process Classification #Edit source
Processes are usually classified according to their purpose and behavior. Although the borderline is not always clearly distinct, generally two criteria are used to sort them. These criteria are independent and do not exclude each other.
One approach is to classify a process either I/O-bound or processor-bound .
I/O stands for Input/Output devices, such as keyboards, mice, or optical and hard disks. I/O-bound processes spend the majority of time submitting and waiting for requests. They are run very frequently, but for short time intervals, not to block other processes waiting for I/O requests.
On the other hand, processor-bound tasks use their time to execute a code, and usually run until they are preempted by the scheduler. They do not block processes waiting for I/O requests, and, therefore, can be run less frequently but for longer time intervals.
Another approach is to divide processes by type into interactive , batch , and real-time processes.
Interactive processes spend a lot of time waiting for I/O requests, such as keyboard or mouse operations. The scheduler must wake up such processes quickly on user request, or the user will find the environment unresponsive. The typical delay is approximately 100 ms. Office applications, text editors or image manipulation programs represent typical interactive processes.
Batch processes often run in the background and do not need to be responsive. They usually receive lower priority from the scheduler. Multimedia converters, database search engines, or log files analyzers are typical examples of batch processes.
Real-time processes must never be blocked by low-priority processes, and the scheduler guarantees a short response time to them. Applications for editing multimedia content are a good example here.
13.3 Completely Fair Scheduler #Edit source
Since the Linux kernel version 2.6.23, a new approach has been taken to the scheduling of runnable processes. Completely Fair Scheduler (CFS) became the default Linux kernel scheduler. Since then, important changes and improvements have been made. The information in this chapter applies to SUSE Linux Enterprise Server with kernel version 2.6.32 and higher (including 3.x kernels). The scheduler environment was divided into several parts, and three main new features were introduced:
The core of the scheduler was enhanced with scheduling classes . These classes are modular and represent scheduling policies.
Completely Fair Scheduler
Introduced in kernel 2.6.23 and extended in 2.6.24, CFS tries to assure that each process obtains its “ fair ” share of the processor time.
For example, if you split processes into groups according to which user is running them, CFS tries to provide each of these groups with the same amount of processor time.
As a result, CFS brings optimized scheduling for both servers and desktops.
13.3.1 How CFS Works #Edit source
CFS tries to guarantee a fair approach to each runnable task. To find the most balanced way of task scheduling, it uses the concept of red-black tree . A red-black tree is a type of self-balancing data search tree which provides inserting and removing entries in a reasonable way so that it remains well balanced.
When CFS schedules a task it accumulates “ virtual runtime ” or vruntime . The next task picked to run is always the task with the minimum accumulated vruntime so far. By balancing the red-black tree when tasks are inserted into the run queue (a planned time line of processes to be executed next), the task with the minimum vruntime is always the first entry in the red-black tree.
The amount of vruntime a task accrues is related to its priority. High priority tasks gain vruntime at a slower rate than low priority tasks, which results in high priority tasks being picked to run on the processor more often.
13.3.2 Grouping Processes #Edit source
Since the Linux kernel version 2.6.24, CFS can be tuned to be fair to groups rather than to tasks only. Runnable tasks are then grouped to form entities, and CFS tries to be fair to these entities instead of individual runnable tasks. The scheduler also tries to be fair to individual tasks within these entities.
The kernel scheduler lets you group runnable tasks using control groups. For more information, see ChapterВ 9, Kernel Control Groups.
13.3.3 Kernel Configuration Options #Edit source
Basic aspects of the task scheduler behavior can be set through the kernel configuration options. Setting these options is part of the kernel compilation process. Because kernel compilation process is a complex task and out of this document’s scope, refer to relevant source of information.
Warning: Kernel Compilation
If you run SUSE Linux Enterprise Server on a kernel that was not shipped with it, for example on a self-compiled kernel, you lose the entire support entitlement.
13.3.4 Terminology #Edit source
Documents regarding task scheduling policy often use several technical terms which you need to know to understand the information correctly. Here are some:
Delay between the time a process is scheduled to run and the actual process execution.
The relation between granularity and latency can be expressed by the following equation:
where gran stands for granularity, lat stand for latency, and rtasks is the number of running tasks.
13.3.4.1 Scheduling Policies #Edit source
The Linux kernel supports the following scheduling policies:
Scheduling policy designed for special time-critical applications. It uses the First In-First Out scheduling algorithm.
Scheduling policy designed for CPU-intensive tasks.
Scheduling policy intended for very low prioritized tasks.
Default Linux time-sharing scheduling policy used by the majority of processes.
Similar to SCHED_FIFO , but uses the Round Robin scheduling algorithm.
13.3.5 Changing Real-time Attributes ofВ Processes with chrt #Edit source
The chrt command sets or retrieves the real-time scheduling attributes of a running process, or runs a command with the specified attributes. You can get or retrieve both the scheduling policy and priority of a process.
In the following examples, a process whose PID is 16244 is used.
To retrieve the real-time attributes of an existing task:
Before setting a new scheduling policy on the process, you need to find out the minimum and maximum valid priorities for each scheduling algorithm:
In the above example, SCHED_OTHER, SCHED_BATCH, SCHED_IDLE polices only allow for priority 0, while that of SCHED_FIFO and SCHED_RR can range from 1 to 99.
To set SCHED_BATCH scheduling policy:
For more information on chrt , see its man page ( man 1 chrt ).
13.3.6 Runtime Tuning with sysctl #Edit source
The sysctl interface for examining and changing kernel parameters at runtime introduces important variables by means of which you can change the default behavior of the task scheduler. The syntax of the sysctl is simple, and all the following commands must be entered on the command line as root .
To read a value from a kernel variable, enter
To assign a value, enter
To get a list of all scheduler related sysctl variables, enter
Note that variables ending with “ _ns ” and “ _us ” accept values in nanoseconds and microseconds, respectively.
A list of the most important task scheduler sysctl tuning variables (located at /proc/sys/kernel/ ) with a short description follows:
When CFS bandwidth control is in use, this parameter controls the amount of run-time (bandwidth) transferred to a run queue from the task’s control group bandwidth pool. Small values allow the global bandwidth to be shared in a fine-grained manner among tasks, larger values reduce transfer overhead. See https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt.
A freshly forked child runs before the parent continues execution. Setting this parameter to 1 is beneficial for an application in which the child performs an execution after fork. For example make -j performs better when sched_child_runs_first is turned off. The default value is 0 .
Enables the aggressive CPU yielding behavior of the old O(1) scheduler by moving the relinquishing task to the end of the runnable queue (right-most position in the red-black tree). Applications that depend on the sched_yield(2) syscall behavior may see performance improvements by giving other processes a chance to run when there are highly contended resources (such as locks). On the other hand, given that this call occurs in context switching, misusing the call can hurt the workload. Only use it when you see a drop in performance. The default value is 0 .
Amount of time after the last execution that a task is considered to be “ cache hot ” in migration decisions. A “ hot ” task is less likely to be migrated to another CPU, so increasing this variable reduces task migrations. The default value is 500000 (ns).
If the CPU idle time is higher than expected when there are runnable processes, try reducing this value. If tasks bounce between CPUs or nodes too often, try increasing it.
Targeted preemption latency for CPU bound tasks. Increasing this variable increases a CPU bound task’s timeslice. A task’s timeslice is its weighted fair share of the scheduling period:
timeslice = scheduling period * (task’s weight/total weight of tasks in the run queue)
The task’s weight depends on the task’s nice level and the scheduling policy. Minimum task weight for a SCHED_OTHER task is 15, corresponding to nice 19. The maximum task weight is 88761, corresponding to nice -20.
Timeslices become smaller as the load increases. When the number of runnable tasks exceeds sched_latency_ns / sched_min_granularity_ns , the slice becomes number_of_running_tasks * sched_min_granularity_ns . Prior to that, the slice is equal to sched_latency_ns .
This value also specifies the maximum amount of time during which a sleeping task is considered to be running for entitlement calculations. Increasing this variable increases the amount of time a waking task may consume before being preempted, thus increasing scheduler latency for CPU bound tasks. The default value is 6000000 (ns).
Minimal preemption granularity for CPU bound tasks. See sched_latency_ns for details. The default value is 4000000 (ns).
The wake-up preemption granularity. Increasing this variable reduces wake-up preemption, reducing disturbance of compute bound tasks. Lowering it improves wake-up latency and throughput for latency critical tasks, particularly when a short duty cycle load component must compete with CPU bound components. The default value is 2500000 (ns).
Warning: Setting the Right Wake-up Granularity Value
Settings larger than half of sched_latency_ns will result in no wake-up preemption. Short duty cycle tasks will be unable to compete with CPU hogs effectively.
Quantum that SCHED_RR tasks are allowed to run before they are preempted and put to the end of the task list.
Period over which real-time task bandwidth enforcement is measured. The default value is 1000000 (Вµs).
Quantum allocated to real-time tasks during sched_rt_period_us. Setting to -1 disables RT bandwidth enforcement. By default, RT tasks may consume 95%CPU/sec, thus leaving 5%CPU/sec or 0.05s to be used by SCHED_OTHER tasks. The default value is 950000 (Вµs).
Controls how many tasks can be migrated across processors for load-balancing purposes. Because balancing iterates the runqueue with interrupts disabled (softirq), it can incur in irq-latency penalties for real-time tasks. Therefore increasing this value may give a performance boost to large SCHED_OTHER threads at the expense of increased irq-latencies for real-time tasks. The default value is 32 .
This parameter sets the period over which the time spent running real-time tasks is averaged. That average assists CFS in making load-balancing decisions and gives an indication of how busy a CPU is with high-priority real-time tasks.
The optimal setting for this parameter is highly workload dependent and depends, among other things, on how frequently real-time tasks are running and for how long.
13.3.7 Debugging Interface and Scheduler Statistics #Edit source
CFS comes with a new improved debugging interface, and provides runtime statistics information. Relevant files were added to the /proc file system, which can be examined simply with the cat or less command. A list of the related /proc files follows with their short description:
Contains the current values of all tunable variables (see SectionВ 13.3.6, “Runtime Tuning with sysctl ”) that affect the task scheduler behavior, CFS statistics, and information about the run queues (CFS, RT and deadline) on all available processors. A summary of the task running on each processor is also shown, with the task name and PID, along with scheduler specific statistics. The first being tree-key column, it indicates the task’s virtual runtime, and its name comes from the kernel sorting all runnable tasks by this key in a red-black tree. The switches column indicates the total number of switches (involuntary or not), and naturally the prio refers to the process priority. The wait-time value indicates the amount of time the task waited to be scheduled. Finally both sum-exec and sum-sleep account for the total amount of time (in nanoseconds) the task was running on the processor or asleep, respectively.
Displays statistics relevant to the current run queue. Also domain-specific statistics for SMP systems are displayed for all connected processors. Because the output format is not user-friendly, read the contents of /usr/src/linux/Documentation/scheduler/sched-stats.txt for more information.
Displays scheduling information on the process with id PID.
13.4 For More Information #Edit source
To get a compact knowledge about Linux kernel task scheduling, you need to explore several information sources. Here are some:
For task scheduler System Calls description, see the relevant manual page (for example man 2 sched_setaffinity ).
A useful lecture on Linux scheduler policy and algorithm is available in http://www.inf.fu-berlin.de/lehre/SS01/OS/Lectures/Lecture08.pdf.
A good overview of Linux process scheduling is given in Linux Kernel Development by Robert Love (ISBN-10: 0-672-32512-8). See https://www.informit.com/articles/article.aspx?p=101760.
A very comprehensive overview of the Linux kernel internals is given in Understanding the Linux Kernel by Daniel P. Bovet and Marco Cesati (ISBN 978-0-596-00565-8).
Technical information about task scheduler is covered in files under /usr/src/linux/Documentation/scheduler .
Источник



