- Установка Tesseract для OCR
- Знакомство с программой
- Установка Tesseract
- Проверка правильности установки
- Проверка Tesseract OCR
- Ограничения Tesseract
- Резюме
- Применение OCR Tesseract совместно с Python
- Установка пакета Tesseract для Python
- Распознавание текста с помощью Tesseract и Python
- Результаты OCR
- Резюме
- Начало работы с оптическим распознаванием символов (OCR) с Tesseract в Symfony 3
- 1. Установите Tesseract в вашей системе
- Windows
- Ubuntu
- MacOS
- MacPorts
- Homebrew
- 2. Установите PHP-оболочку Tesseract
- 3. Реализация в контроллере
- 4. Поддержка языков
- 5. Пользовательские параметры
- Изменить путь к исполняемому файлу
- Сегментация страницы
- Установите языки для распознавания
- Используйте слова из списка
- Белый список персонажей
- Установить значение конфигурации
Установка Tesseract для OCR
OCR — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующихся для представления символов в компьютере.
Знакомство с программой
Tesseract первоначально разработана Hewlett Packard в 1980-х годах, в 2005 году был опубликован её исходный код. В августе 2006 г. Google купил её и открыл исходные тексты под лицензией Apache 2.0 для последующей разработки.
Программное обеспечение Tesseract работает со многими естественными языками от английского (первоначально) до панджаби. С момента обновления в 2015 году он поддерживает более 100 письменных языков и содержит обучаемый код для других языков. Поддержка русского языка реализована подключением дополнительных модулей.
Первоначально программа была написана на C, в 1998 году была перенесена на C ++. У неё нет графического интерфейса, но есть сторонние программные проекты, которые обертывают Tesseract для предоставления графического интерфейса пользователя.
Установка Tesseract
Чтобы использовать библиотеку Tesseract, необходимо установить её в операционную систему.
Для пользователей MacOS воспользуемся brew:
Если используется операционная система Ubuntu:
Пользователям Windows официальных бинарных сборок Tesseract не предоставляется, поэтому рекомендуется воспользоваться поисковыми системами для поисков сторонних сборок.
Проверка правильности установки
Чтобы проверить, что Tesseract был успешно установлен, выполним следующую команду:
В командную строку должна распеваться версия Tesseract, а также список совместимых библиотек форматов файлов изображений.
Если появилась ошибка:
тогда вернитесь к предыдущему шагу и устраните ошибки установки. Кроме того, может потребоваться обновить переменную окружения PATH (только для продвинутых пользователей).
Проверка Tesseract OCR
Для того чтобы получить разумные результаты в Tesseract OCR нужно предварительно обработать цифровыми фильтрами поступающие изображения.
При использовании Tesseract рекомендуется:
- Использовать входные изображения с максимально высоким разрешением и DPI;
- Применение пороговых фильтров для выделения текста из фона;
- Максимально чёткое сегментирование переднего плана по сравнению с задним фоном, без пикселяции или деформаций символов.
- Применение коррекции текста к входному изображению для обеспечения правильного выравнивания текста.
Отклонения от этих рекомендаций могут привести к неправильным результатам OCR.
Теперь применим OCR к следующему изображению:

Запустим команду в терминале:
Tesseract правильно распознал текст «Testing Tesseract OCR» и распечатал его в терминале.
Ограничения Tesseract
К сожалению, этот синтетический пример достаточно далёк от реальности. Если распознаваемый текст плохо отделим от фона или он сильно пикселирован, то Tesseract скорее всего вернёт ошибочные результаты. Tesseract лучше всего подходит для конвейерной обработки документов, в которых изображения сканируются, обрабатываются цифровыми фильтрами, а затем к ним применяется оптическое распознавание символов.
Следует отметить, что Tesseract не является готовым решением для OCR, которое сможет работать во всех приложениях обработки изображений и компьютерного зрения. Для сложных частных случаев необходимо применить методы извлечения признаков, машинное обучение и искусственный интеллект.
Резюме
Если обрабатываемые изображения не будут содержать чёткого текста, Tesseract даст плохие результаты. В случае зашумлённых входных изображений, получить лучшую точность можно обучая пользовательскую модель машинного обучения.
Tesseract лучше всего подходит для ситуаций с изображениями высокого разрешения, где текст переднего плана чётко отделим от фона.
Применение OCR Tesseract совместно с Python
Как показывают исследования, Tesseract лучше всего справляется с работой, когда существует чёткое отделение текста переднего плана от фона. На практике это гарантировать чрезвычайно сложно. Следовательно, необходимо обучать классификаторы и детекторы, специфичные для данной задачи.
Тем не менее будет полезно воспользоваться OCR tesseract через язык программирования Python, когда нужно применить OCR к собственным проектам, при условии, что будут получены хорошие и чистые тексты.
Примеры таких проектов с OCR могут быть мобильный сканер документов, из которых нужно извлечь текстовую информацию или служба, которая сканирует бумажные медицинские карточки для размещения этой информации в базе данных…
В этой статье будет рассказано, как установить пакет Tesseract OCR для Python, а затем напишем простой Python скрипт для распознавания текста с картинок.
Установка пакета Tesseract для Python
Чтобы установить pytesseract воспользуемся менеджером пакетов Python pip. Также рекомендуется использовать виртуальную среду чтобы устанавливать свой набор пакетов для разных проектов. В данном случае virtualenv называется cv.
Затем установим Pillow (удобный клон PIL для Python) от которого зависит pytesseract.
Примечание: pytesseract не обеспечивает настоящей привязки к Python. Скорее, он является простой обёрткой для двоичного файла tesseract. Если познакомиться с проектом по подробнее, то станет ясно, что библиотека сохраняет изображение во временный файл на диске, а затем вызывает двоичный файл tesseract и полученный результат записывает в файл.
Рассмотрим код, который отделяет текст переднего плана от фона, а затем применим установленный pytesseract.
Распознавание текста с помощью Tesseract и Python
Создадим файл с именем ocr.py:
Теперь применим OCR к изображению, используя pytesseract:
Вызов оператора pytesseract.image_to_string преобразует изображение в строку текста. Обратите внимание, что была передана ссылка на временный файл картинки.
print(text) – распечатывает результата распознавания скрипта в терминал. В ваших собственных приложениях вы можете выполнить некоторые дополнительные действия, например, проверку орфографии или обработку естественного языка.
В заключении, строки с cv2.imshow обрабатывают исходное и предварительно обработанное изображение на экране в отдельных окнах. input(‘pause…’) сообщает программе, что нужно ожидать пользовательского нажатия клавиши перед выходом из сценария.
Результаты OCR
Теперь, когда готов ocr.py протестируем его для выполнения OCR на некоторых примерах входных изображений.
В этом разделе проверим OCR двух образцов изображений.
- Сначала пропустим каждое изображение через двоичный файл Tesseract.
- Затем передадим каждое изображение скрипту ocr.py (который выполняет предварительную обработку перед отправкой их в tesseract).
- Сравним результаты обоих этих методов и выявим ошибки.

Это изображение содержит на переднем плане текст черного цвета на фоне, который частично белый и частично рассеянный с искусственно создаваемыми круговыми пятнами.
В этом случае Tesseract отлично справился с ошибками. Теперь подтвердим, что скрипт ocr.py также работает:
Скрипт правильно распознал текстовое содержимое из изображения выведя его в консоль.
Затем протестируем Tesseract и наш скрипт на изображении, предварительно обработанным фильтром с шумом «соль и перец».

Результаты работы двоичного файла tesseract:
К сожалению, tesseract не смог распознать текст без ошибок.
Однако, используя метод предварительной обработки blur в ocr.py, можем получить лучшие результаты, для этого установим переменную preprocess в blur.
Этап предварительной обработки blur позволило Tesseract правильно распознать OCR и вывести желаемый текст.
Таким образом были получены приемлемые результаты с tesseract для OCR, но лучшая точность будет получена от обучения пользовательских классификаторов символов на определенных наборах шрифтов, которые используются на реальных изображениях.
Примечание. Если текст повернут, нужно также выполнить предварительную обработку.
Резюме
В этой статье было продемонстрировано применение OCR движка tesseract с языком программирования Python. Что позволило нам применять алгоритмы OCR из собственных сценариев Python.
Самый большой недостаток связан с ограничениями самого Tesseract – он работает когда на переднем плане есть чрезвычайно чистые фрагменты текста. Кроме того, эти фрагменты должны быть как можно более высокого разрешения (DPI), а символы входного изображения не были подвергнуты «пикселированию» после сегментации.
OCR не является новой технологией, но по-прежнему является областью исследований в компьютерной науке, особенно при применении OCR к реальным изображениям. Глубокое обучение и сверточные нейронные сети (CNN), безусловно, позволяют получать более высокую точность, но до почти идеальной системы распознавания ещё очень далеко. Кроме того, сейчас предлагается много OCR приложений на разных сайтах, в которых применены лучшие из алгоритмов распознавания, но они являются коммерческими и требуют лицензирования для использования в собственных проектах.
Если ни Tesseract, ни сторонние сервисы не предоставят достаточной точности, то нужно переосмыслить свой набор данных и задуматься о обучении своего классификатора символов. Это особенно предпочтительно, если набор данных зашумлён и/или содержит очень специфические шрифты. Примеры конкретных шрифтов включают в себя цифры на кредитной карте, номера счета и номера маршрута, найденные в проездных билетах или стилизованный текст, используемый в графическом дизайне.
Начало работы с оптическим распознаванием символов (OCR) с Tesseract в Symfony 3
Давайте представим, что вам нужно оцифровать страницу книги или печатного документа, вы будете использовать сканер для создания изображения реальной страницы. Однако, несмотря на то, что у вас есть права на редактирование содержимого отсканированной книги, вы не можете редактировать его на своем компьютере, потому что это изображение, и вы не можете просто отредактировать изображение, как если бы это был цифровой документ. Да, пользователь может использовать программы, которые создают PDF с возможностью выбора текста, а затем они могут делать то, что хотят, однако, как разработчик, вы можете предложить своему пользователю возможность извлекать текст из изображений с помощью технологии оптического распознавания символов. Чтобы достичь цели преобразования изображений в текст, мы собираемся использовать Tesseract, написанный на C ++, установить его в системе, а затем использовать командную строку с оболочкой PHP.
В этой статье вы узнаете, как извлечь текст из изображения в проекте Symfony с помощью Tesseract.
1. Установите Tesseract в вашей системе
Чтобы использовать API оптического распознавания символов, как упоминалось в статье, мы собираемся использовать Tesseract. Тессеракт является механизмом оптического распознавания символов (OCR) с открытым исходным кодом, доступным по лицензии Apache 2.0. Его можно использовать напрямую с помощью API для извлечения печатного, рукописного или печатного текста из изображений. Он поддерживает широкий спектр языков (которые должны быть установлены). Tesseract поддерживает различные форматы вывода: обычный текст, hocr (html) и pdf.
Процесс установки Tesseract в вашей системе зависит от используемой вами операционной системы:
Windows
Процесс установки очень прост, просто следуйте инструкциям мастера. Однако мы рекомендуем вам установить в настройках непосредственно все языки, которые вам нужны для tesseract (только те, которые вам нужны, в противном случае процесс загрузки займет много времени) и зарегистрировать tesseract в PATH:
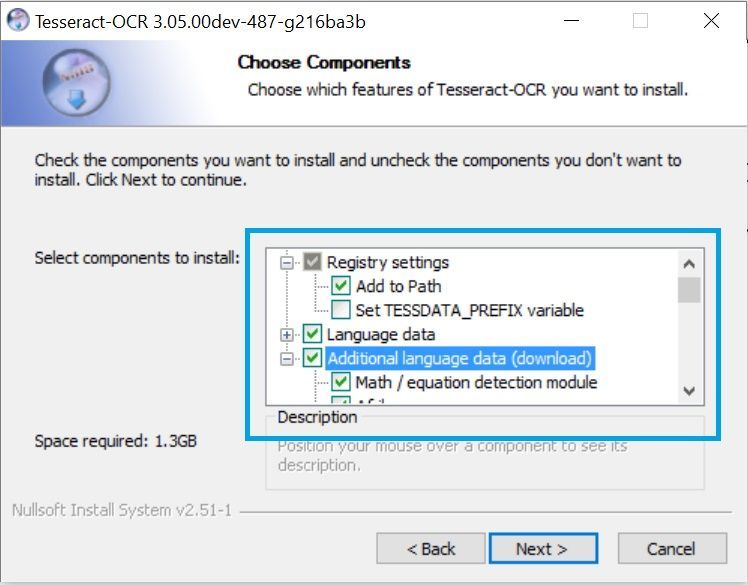
Подождите, пока установка закончится, и вы готовы к работе. Вы можете проверить, правильно ли он был установлен, запустив новое окно командной строки. tesseract -v (это должно вывести установленную версию).
Ubuntu
Установите Tesseract с помощью следующей команды:
Затем установите языки, которые необходимо распознать (например, -deu, -fra, -eng, -spa требуемый английский):
Тогда tesseract должен быть доступен на любом терминале и, следовательно, доступен для наших сценариев PHP позже.
MacOS
Если вы используете Mac OS X, вы можете установить tesseract, используя либо MacPorts или же Homebrew:
MacPorts
Чтобы установить Tesseract, запустите эту команду:
Чтобы установить любые языковые данные, выполните:
Полный список доступных langcodes можно найти на Страница тессеракт MacPorts.
Homebrew
Чтобы установить Tesseract, запустите эту команду:
Если вам нужна дополнительная информация или вашей операционной системы нет в списке, обратитесь к Установка вики репозитория Tesseract в Github здесь.
2. Установите PHP-оболочку Tesseract
Для работы с Tesseract с помощью PHP мы будем использовать самый известный Wrapper of Tesseract, написанный @thiagoalessio. Тессеракт OCR для PHP является полезной и очень простой в использовании оболочкой инструкций командной строки для Tesseract OCR внутри PHP.
Предпочтительный способ установки — через композитор, вы можете выполнить следующую команду прямо в терминале:
Или, если хотите, отредактируйте composer.json файл и добавьте следующую зависимость и выполните затем composer install :
После установки вы сможете использовать Wrapper в ваших контроллерах Symfony.
Замечания: вам нужно установить указанную версию, как в документации библиотеки, метод распознавания текста на изображении с использованием Tesseract $tesseract->run() , В старых версиях вам нужно использовать $tesseract->recognize() вместо.
3. Реализация в контроллере
Использование библиотеки довольно просто и легко понять:
В следующем примере показано, как распознать текст следующего изображения:

Обратите внимание, что файл будет находиться в /your-project/web/text.jpeg :
Перейдите к маршруту, который соответствует действию индекса этого контроллера, и вы увидите, как выводится распознанный текст изображения.
4. Поддержка языков
Как вы знаете, в мире есть другие языки, в которых используются специальные символы, поэтому Tesseract предлагает различные языковые пакеты. Например, если вы попытаетесь распознать следующее изображение без немецкого пакета:

В результате вы получите «грифон». Это совсем не так, это происходит потому, что эти персонажи немецкого языка. Чтобы решить эту проблему, вам нужно добавить немецкий пакет (обозначается как deu ):
Теперь, как результат, вы должны получить «grüßen», как и ожидалось. Вы можете настроить одновременную работу нескольких языков, указав несколько аргументов:
Замечания: чтобы использовать разные языки, вам также понадобятся соответствующие пакеты.
5. Пользовательские параметры
Если вы уже прочитали некоторое содержание документация по использованию Tesseract с командной строкой, Вы знаете, что есть много свойств, которые вы можете изменить. Оболочка PHP tesseract предоставляет несколько методов для наиболее часто используемых опций:
Изменить путь к исполняемому файлу
По разным причинам у вас может не быть доступного tesseract непосредственно в переменной окружения PATH, поэтому выполнение команды с помощью оболочки php « tesseract imagename.jpeg outputbase «не будет работать. Вы можете указать расположение исполняемого файла tesseract с помощью исполняемого метода:
Сегментация страницы
Вы можете установить режим сегментации страницы с помощью ->psm($mode) инструкция, которая инструктирует тессеракт, как интерпретировать данное изображение:
Возможные значения для сегментации страницы:
| Значение | Описание |
| Только ориентация и обнаружение сценариев (OSD). | |
| 1 | Автоматическая сегментация страницы с помощью экранного меню. |
| 2 | Автоматическая сегментация страницы, но без OSD или OCR. |
| 3 | Полностью автоматическая сегментация страниц, но без OSD. (Это значение используется по умолчанию, если ни один не предоставлен) |
| 4 | Предположим, что один столбец текста переменного размера. |
| 5 | Предположим, что один однородный блок текста вертикально выровнен. |
| 6 | Предположим, что один единый блок текста. |
| 7 | Рассматривайте изображение как одну текстовую строку. |
| 8 | Рассматривайте изображение как одно слово. |
| 9 | Рассматривайте изображение как одно слово в кругу. |
| 10 | Относитесь к изображению как к одному персонажу. |
Установите языки для распознавания
Вы можете определить один или несколько языков, которые будут использоваться во время распознавания, используя ->lang($lang1, $lang2) метод. Вы можете получить список все поддерживаемые языки по tesseract в документации здесь:
Используйте слова из списка
Вы можете предоставить список. этот список должен быть простым текстовым файлом, содержащим список слов, которые вы хотите, чтобы tesseract считал обычными словарными словами, например ( mywords.txt ):
И добавьте это с оберткой:
Этот список действительно полезен при работе с контентом, который содержит техническую терминологию.
Белый список персонажей
Вы можете даже ограничить символы, которые распознает tesseract, например, с помощью следующего изображения:
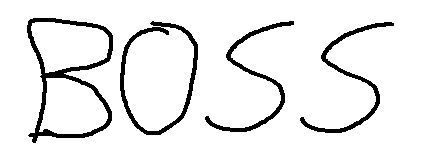
Тессеракт узнает «BOSS» , Это здорово, потому что на картинке кажется, что кто-то написал БОСС, но пользователь (вероятно, ребенок или кто-то с плохой каллиграфией) написал число «8055» ? Вот где белый список пригодится, в этом случае мы можем ограничить символы для распознавания только чисел, используя диапазон от 0 до 9:
Предоставление в результате ожидаемого числа «8055».
Установить значение конфигурации
Tesseract предлагает более 600 настраиваемых свойств (вы можете перечислить их, используя в консоли tesseract —print-parameters ) что вы можете изменить с помощью ->config($propertyName, $value) :
Если вам нужна дополнительная информация о поддерживаемых методах этой оболочки, пожалуйста, посетите официальный репозиторий здесь.



