- Как проверить работоспособность SSD/HDD в Linux
- Проверка работоспособности SSD накопителя с помощью Smartctl
- Ubuntu
- RHEL и CentOS
- FEDORA
- Проверка работоспособности SSD/HDD
- Проверка работоспособности SSD/HDD дисков с помощью Gnome
- Установка Gnome Disks
- Заключение
- База знаний wiki
- Содержание
- Проверка состояния жестких дисков в Linux
- Задача:
- Решение:
- 6 приложений для анализа жесткого диска в Linux
- Командная строка
- Baobab
- KDirStat и GdMap
- Filelight
- Philesight
- xdiskusage
- Проверка жесткого диска в Linux
- Установка Smartmontools
- Проверка жесткого диска в smartctl
- Автоматическая диагностика в smartd
- Проверка диска на ошибки в GUI
- Выводы
- Оцените статью:
- Об авторе
- 9 комментариев
Как проверить работоспособность SSD/HDD в Linux
SMART (Технология самоконтроля, анализа и отчетности) — это функция, включенная во все современные жесткие диски и твердотельные накопители для мониторинга и тестирования надежности. Он проверяет различные атрибуты диска, чтобы обнаружить возможность отказа диска. Существуют различные инструменты, которые доступны в Linux и Windows для выполнения интеллектуальных тестов работоспособности.
Из этой инструкции вы узнаете, как проверить работоспособность SSD/HDD в Linux с помощью CLI и GUI
Здесь объясняются два метода:
- Использование Smartctl
- Использование Gnome disk
Проверка работоспособности SSD накопителя с помощью Smartctl
Smartctl — это утилита командной строки, которая может быть использована для проверки состояния жесткого диска или SSD с поддержкой S.M.A.R.T в системе Linux.
Утилита Smartctl utility tool поставляется вместе с пакетом smartmontools.Smartmontools доступна по умолчанию во всех дистрибутивах Linux, включая Ubuntu, RHEL, Centos и Fedora.
Как установить smartmontools в Linux:
Ubuntu
$ sudo apt install smartmontools
Запустите службу с помощью следующей команды.
RHEL и CentOS
$ sudo yum install smartmontools
FEDORA
$ sudo dnf install smartmontools
Служба Smartd запустится автоматически после успешной установки.
Если вдруг Smartd не запустился, сделать это можно командой:
Проверка работоспособности SSD/HDD
Чтобы проверить общее состояние введите команду:
Опишу команды подробнее:
d – Указывает тип устройства.
ata – тип устройства ATA, используйте scsi для типа устройства SCSI.
H – Проверяет устройство, чтобы сообщить о его состоянии и работоспособности.
 Проверка общего состояния
Проверка общего состояния
Полученный результат указывает на то, что диск исправен. Если устройство сообщает о неисправном состоянии работоспособности, это означает, что устройство уже вышло из строя или может выйти из строя очень скоро.
Это указывает на неудачное использование и появляется возможность получить дополнительную информацию.
Вы можете увидеть следующие атрибуты:
[ID 5] Reallocated Sectors Count – Количество секторов, перераспределенных из-за ошибок чтения.
[ID 187] Reported Uncorrect – Количество неисправимых ошибок при доступе к сектору чтения/записи.
[ID 230] Индикатор износа носителя – Текущее состояние работы диска на основе срока службы.
Если вы видите 100 — это лучшее значение. А если видите 0 — это ХУДШЕЕ значение.
Дополнительные сведения см. в разделе Сведения о интеллектуальных атрибутах.
Чтобы инициировать расширенный тест (long), выполните следующую команду:
Чтобы выполнить самотестирование, введите команду:
Чтобы найти результат самопроверки диска, используйте эту команду.
Чтобы оценить время выполнения теста, выполните следующую команду.
Вы можете распечатать журналы ошибок диска с помощью команды:
Проверка работоспособности SSD/HDD дисков с помощью Gnome
С помощью утилиты GNOME disks вы можете получить информацию о ваших SSD-дисков. Можете отформатировать диски, создать образ диска, выполнить стандартные тесты SSD-дисков и восстановить образ диска.
Установка Gnome Disks
В Ubuntu 20.04 приложение GNOME поставляется с установленным инструментом GNOME disk. Если вы не можете найти инструмент, используйте следующую команду для его установки.
$ sudo apt-get install gnome-disk-utility
GNOME Disk теперь установлен, далее вы можете перейти в меню рабочего стола и запустить его. Из приложения вы можете просмотреть все подключенные диски. А также можете использовать следующую команду для запуска приложения GNOME Disk.
Для того чтоб выполнить тест, запустите GNOME disks и выберите диск, который вы хотите протестировать. Вы можете найти быструю оценку дисков, таких как размер, разделение, серийный номер, температура и работоспособность. Нажмите на значок шестеренки и выберите SMART Data & Self-tests.
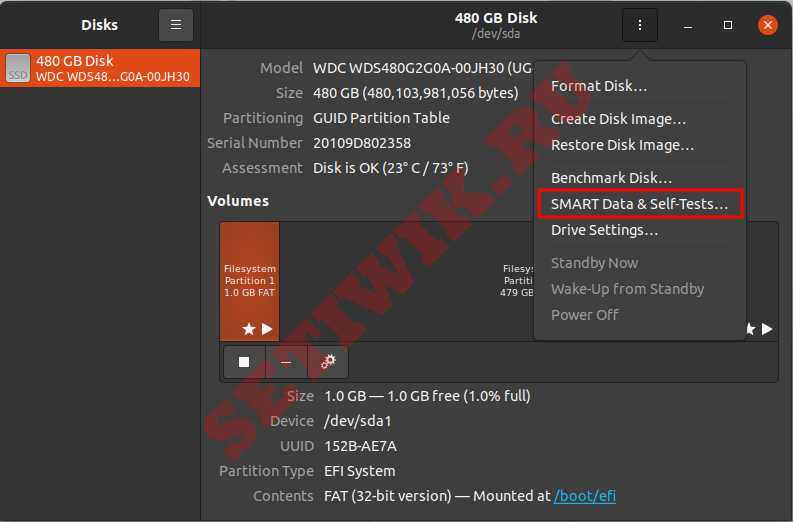 GNOME disks данные и самопроверки
GNOME disks данные и самопроверки
В новом окне вы можете найти результаты последнего теста. В правом верхнем углу окна вы можете обнаружить, что интеллектуальная опция включена. Если SMART отключен, его можно включить, нажав на ползунок. Чтобы начать новый тест, нажмите на кнопку Начать тестирование.
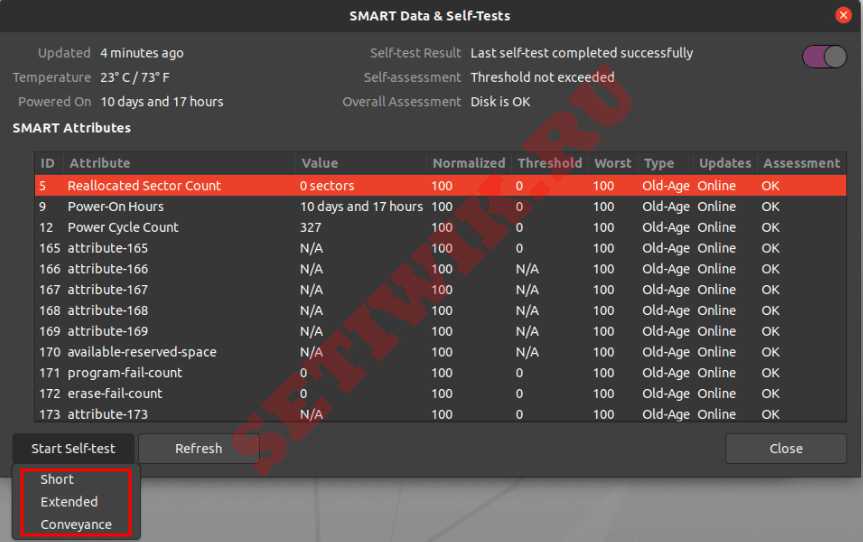 GNOME disks работает самотестирование
GNOME disks работает самотестирование
Как только будет нажата кнопка Начать Тестирование, появится выпадающее меню для выбора типа тестов:
- Короткие
- Расширенные
- Транспортировочные.
Выберите тип теста и введите свой пароль sudo. На индикаторе прогресса можно увидеть процент завершения теста.
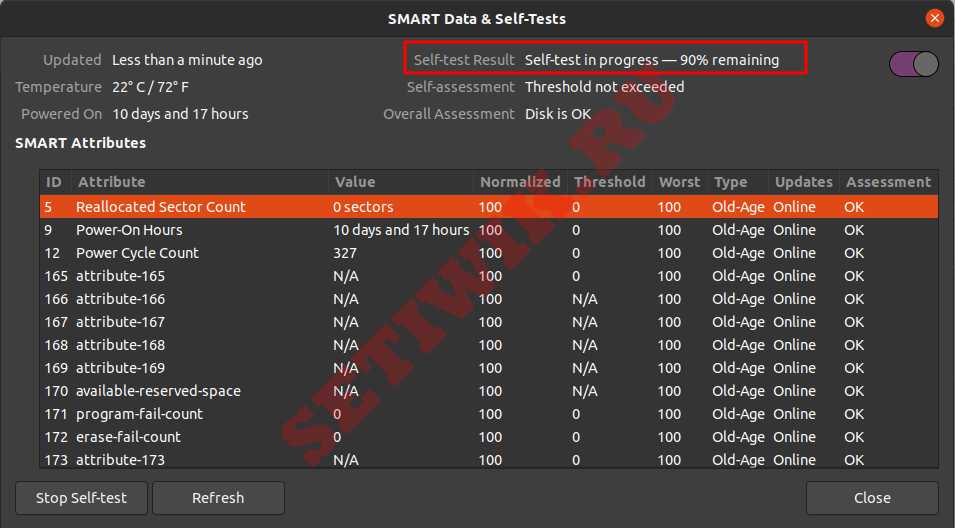 Результат самопроверки
Результат самопроверки
Заключение
В этой инструкции я объяснил основную концепцию технологии S. M. A. R. T,. Кроме того, я рассказал о том, как установить утилиту командной строки smartctl компьютер с Linux и как ее можно использовать для мониторинга работоспособности жестких дисков. У вас также есть представление о утилите GNOME Disks utility tool для мониторинга SSD-накопителей. Надеюсь, что эта статья поможет вам контролировать ваши SSD-диски с помощью утилиты smartctl и GNOME Disks.
Источник
База знаний wiki
Продукты
Статьи
Содержание
Проверка состояния жестких дисков в Linux
Слова для поиска: проверка дисков, hdparm, badblocks, smart, smartctl, iostat, mdstat
Задача:
Проверить состояние жестких дисков на выделенном сервере, наличие сбойных блоков на HDD, анализ S.M.A.R.T
Решение:
В этой статье будут рассмотрены способы проверки и диагностики HDD в Linux. Полученная информация поможет проанализировать состояние жестких дисков, и, если это необходимо, заменить носитель до того, как он вышел из строя неожиданно и в самый не подходящий для этого момент.
Задуматься о состоянии HDD следует по некоторым признакам поведения системы в целом: резко выросла общая нагрузка на дисковую подсистему, упала скорость чтения/записи, другие проблемы косвенно указывающие что с HDD что-то не то.
Ниже я приведу основные команды, выполнять их необходимо из-под учётной записи root
Чтобы получить список подключенных HDD в систему, выполнить:
Мы получим листинг всех подключенных накопителей, их размер и имена устройств в системе.
Для того, чтобы посмотреть какие устройства и куда смонтированы, выполнить:
Узнать сколько на каждом из смонтированном носителе занято пространства, выполнить:
Если мы используем софтовых RAID, его состояние мы можем проверить следующей командой:
Если всё в порядке, то мы увидим что-то подобное:
Из вывода видно состояние raid (active), название устройства raid (md0) и какие устройства в него включены (sdb1[0] sdc1[1]), какой именно raid собран (raid1), в нём два диска и они оба работают в raid ([2/2] [UU])
Смотрим скорость чтения с накопителя
Где /dev/sdX — имя устройства которое необходимо проверить.
Полезной программой для анализа нагрузки на диски является iostat, входящей в пакет sysstat Ставим:
Теперь смотрим вывод iostat по всем дискам в системе:
С интервалом 10 секунд:
Или по определённому накопителю:
Полученные данные покажут нам нагрузку на устройства хранения, статистику по вводу/выводу, процент утилизации накопителя.
Переходим непосредственно к проверке накопителей. Проверка на наличие сбойных блоков осуществляется при помощи программы badblocks. Для проверки жесткого диска на бэдблоки, выполнить:
Где /dev/sdX — имя устройства которое необходимо проверить. Если программа обнаружит наличие сбойных блоков, она выведет их количество на консоль. Выполнение данной операции может занять продолжительное время (до нескольких часов) и желательно её выполнение на размонтированной файловой системе, либо в режиме read-only.
Для того, чтобы записать сбойные блоки, выполняем:
Где /tmp/badblock — файл куда программа запишет номера сбойных блоков.
Теперь при помощи программы e2fsck мы можем пометить сбойные блоки и они будут в дальнейшем игнорироваться системой. ВНИМАНИЕ! Данная операция должна проводиться на размонтированной файловой системе, либо в режиме read-only! Проверенное устройство и устройство на накотором будут помечаться сбойные блоки должно быть одно и тоже!
Если были обнаружены сбойные блоки на диске, есть тенденция появления новых бэдблоков, необходимо задуматься о скорейшем копировании данных и замене данного носителя. Приведённые выше команды помогут выявить сбойные блоки и пометить их как таковые, но не спасут «сыпящийся» диск.
Также в своём инструментарии полезно использовать данные полученные из S.M.A.R.T. дисков.
Ставим пакет smartmontools
Получаем данные S.M.A.R.T. жесткого диска:
Где /dev/sdX — имя устройства которое необходимо проверить.
Вы получите вывод атрибутов S.M.A.R.T., значение каждого из которых хорошо описаны в Википедии
Для сохранности данных настоятельно рекомендуем делать backup (резервное копирование). Это поможет в кратчайшие сроки восстановить необходимые данные и настройки в форс-мажорных обстоятельствах.
Источник
6 приложений для анализа жесткого диска в Linux
Командная строка
Если вы истинный линуксоид, самый легкий и быстрый способ – использовать команду «df» в командной строке. Просто напечатать:
в терминале, и он покажет вам загрузку жесткого диска в процентах

Как видно из представленного выше скриншота, способ может служить лишь в качестве быстрого просмотра доступного места на диске и определенно не является самым удобным для проведения анализа жесткого диска.
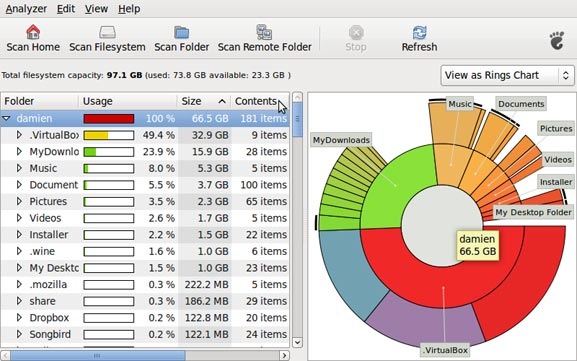
Baobab
Большинство линукс-дистрибутивов с Gnome(в частности Убунту), используют Baobab в качестве дефолтного приложения для просмотра диска.Это замечательное приложение, способное до последней папки разделить и проанализировать структуру хранения данных на жестком диске. Просто укажите папки необходимые для сканирования, и в результате получите круговую диаграмму, отражающую количество занимаемого места каждым файлом.
KDirStat и GdMap
Если вы использовали WinDirStat в Windows, то согласитесь, что это очень удобное приложение, позволяющее анализировать и оптимизировать ваше дисковое пространство. Однако мало людей знают, что WinDirStat это на самом деле клон KDirStat. KDirStat обладает той же функциональностью что и WinDirStat (или может быть наоборот), за исключением того, что он предназначен для использования в Linux. Несмотря на то, что KDirStat разрабатывался для KDE, он также совместим с любым оконным менеджером X11.
KDirStat отображает ваши папки/файлы в виде прямоугольников. Чем больше размер файла, тем больше прямоугольник. Это позволяет вам быстро просмотреть файловую систему, и легко определить какая папка/файл занимают много места на жестком диске.

Gd Map это эквивалент KDirStat для Gnome, кроме того что он не отображает древовидную структуру папок, и не позволяет очищать жесткий диск.
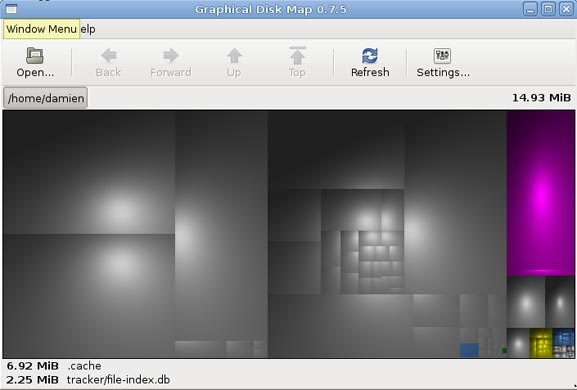
Filelight
Подобно Baobab, Filelight, создает интерактивную карту концентрических, сегментированных колец, помогающих визуализировать использование диска на вашем компьютере.Вы легко можете приблизить нужные папки, путем клика на соответствующем сегменте колец.
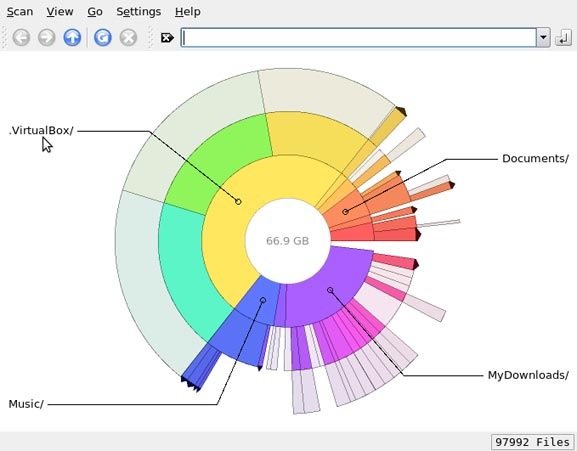
Philesight
Philesight это реализация Filelight в качестве веб-приложения, может быть запущена на удаленном сервере, не имеющим графического интерфейса. Philesight использует командную строку для генерации PNG-файлов в браузере и включает CGI-скрипты для навигации по файловой системе. Одна из ее особенностей, красочная радуга концентрических колец, что делает ее весьма приятной на вид.

xdiskusage
xdiskusage маленькая программка, отображающая файловую систему иерархически, слева направо, прямоугольными фигурами, с размерами, соответствующими размеру файлов. Если вы сканируете домашнюю папку, слева будет находится прямоугольник, отображающий полностью папку home, а справа все файлы, находящиеся внутри нее.
Вы легко можете приближать/удалять, нужные папки, по двойному щелчку на соответствующем прямоугольнике.
Источник
Проверка жесткого диска в Linux
Если и есть то, с чем вы очень не хотите столкнуться в вашей операционной системе, то это неожиданный выход из строя жестких дисков. С помощью резервного копирования и технологии хранения RAID вы можете очень быстро вернуть все данные на место, но потеря аппаратного устройства может очень сильно сказаться на бюджете, особенно если вы такого не планировали.
Чтобы избежать таких проблем можно использовать пакет smartmontools. Это программный пакет для управления и мониторинга устройств хранения данных с помощью технологии Self-Monitoring Analysis and Reporting Technology или просто SMART.
Большинство современных ATA/SATA/SCSI/SAS накопителей информации предоставляют интерфейс SMART. Цель SMART — мониторинг надежности жесткого диска, для выявления различных ошибок и своевременного реагирования на их появление. Пакет smartmontools состоит из двух утилит — smartctl и smartd. Вместе они представляют мощную систему мониторинга и предупреждения о возможных поломках HDD в Linux. Дальше будет подробно рассмотрена проверка жесткого диска linux.
Установка Smartmontools
Пакет smartmontools есть в официальных репозиториях большинства дистрибутивов Linux, поэтому установка сводится к выполнению одной команды. В Debian и основанных на нем системах выполните:
sudo apt install smartmontools
sudo yum install smartmontools
Во время установки надо выбрать способ настройки почтового сервера. Можно его вовсе не настраивать, если вы не собираетесь отправлять уведомления о проблемах с диском на почту.

Отправлять почту получится только на веб-сервере, к которому привязан домен, на локальной машине можно выбрать пункт только для локального использования и тогда почта будет складываться в локальную папку и её можно будет посмотреть утилитой mail. Теперь можно переходить к диагностике жесткого диска Linux.
Проверка жесткого диска в smartctl
Сначала узнайте какие жесткие диски подключены к вашей системе:
ls -l /dev | grep -E ‘sd|hd’
В выводе будет что-то подобное:

Здесь sdX это имя устройства HDD подключенного к компьютеру.
Для отображения информации о конкретном жестком диске (модель устройства, S/N, версия прошивки, версия ATA, доступность интерфейса SMART) Запустите smartctl с опцией info и именем жесткого диска. Например, для /dev/sda:
smartctl —info /dev/sda

Хотя вы можете и не обратить внимания на версию SATA или ATA, это один из самых важных факторов при поиске замены устройству. Каждая новая версия ATA совместима с предыдущими. Например, старые устройства ATA-1 и ATA-2 прекрасно будут работать на ATA-6 и ATA-7 интерфейсах, но не наоборот. Когда версии ATA устройства и интерфейса не совпадают, возможности оборудования не будут полностью раскрыты. В данном случае для замены лучше всего выбрать жесткий диск SATA 3.2.
Запустить проверку жесткого диска ubuntu можно командой:
smartctl -s on -a /dev/sda

Здесь опция -s включает флаг SMART на указном устройстве. Вы можете его убрать если поддержка SMART уже включена. Информация о диске разделена на несколько разделов, В разделе READ SMART DATA находится общая информация о здоровье жесткого диска.
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment rest result: PASSED
Этот тест может быть пройден (PASSED) или нет (FAILED). В последнем случае сбой неизбежен, начинайте резервное копирование данных с этого диска.
Следующая вещь которую можно посмотреть, когда выполняется диагностика HDD в linux, это таблица SMART атрибутов.

В SMART таблице записаны параметры, определенные для конкретного диска разработчиком, а также порог отказа для этих параметров. Таблица заполняется автоматически и обновляется на основе прошивки диска.
- ID # — идентификатор атрибута, как правило, десятичное число между 1 и 255;
- ATTRIBUTE_NAME — название атрибута;
- FLAG — флаг обработки атрибута;
- VALUE — это поле представляет нормальное значение для состояния данного атрибута в диапазоне от 1 до 253, 253 — лучшее состояние, 1 — худшее. В зависимости от свойств, начальное значение может быть от 100 до 200;
- WORST — худшее значение value за все время;
- THRESH — самое низкое значение value, после перехода за которое нужно сообщить что диск непригоден для эксплуатации;
- TYPE — тип атрибута, может быть Pre-fail или Old_age. Все атрибуты по умолчанию считаются критическими, то-есть если диск не прошел проверку по одному из атрибутов, то он уже считается не пригодным (FAILED) но атрибуты old_age не критичны;
- UPDATED — показывает частоту обновления атрибута;
- WHEN_FAILED — будет установлено в FAILING_NOW если значение атрибута меньше или равно THRESH, или в «—» если выше. В случае FAILING_NOW, лучше как можно скорее выполнить резервное копирование, особенно если тип атрибута pre-fail.
- RAW_VALUE — значение, определенное производителем.
Сейчас вы думаете, да smartctl хороший инструмент, но у меня нет возможности запускать его каждый раз вручную, было бы неплохо автоматизировать все это дело чтобы программа запускалась периодически и сообщала мне о результатах проверки. И это возможно, с помощью smartd.
Автоматическая диагностика в smartd
Автоматическая диагностика HDD в Linux настраивается очень просто. Сначала отредактируйте файл конфигурации smartd — /etc/smartd.conf. Добавьте следующую строку:
/dev/sda -m myemail@mydomain.com -M test
- -m — адрес электронной почты для отправки результатов проверки. Это может быть адрес локального пользователя, суперпользователя или внешний адрес, если настроен сервер для отправки электронной почты;
- -M — частота отправки писем. once — отправлять только одно сообщение о проблемах с диском. daily — отправлять сообщения каждый день если была обнаружена проблема. diminishing — отправлять сообщения через день если была обнаружена проблема. test — отправлять тестовое сообщение при запуске smartd. exec — выполняет указанную программу в место отправки почты.
Сохраните изменения и перезапустите smartd:
sudo systemctl restart smartd
Вы должны получить на электронную почту письмо о том, что программа была запущена успешно. Это будет работать только если на компьютере настроен почтовый сервер.

Также можно запланировать тесты по своему графику, для этого используйте опцию -s и регулярное выражение типа T/MM/ДД/ДН/ЧЧ, где:
Здесь T — тип теста:
- L — длинный тест;
- S — короткий тест;
- C — тест перемещения (ATA);
- O — оффлайн тест.
Остальные символы определяют дату и время теста:
- ММ — месяц в году;
- ДД — день месяца;
- ЧЧ — час дня;
- ДН — день недели (от 1 — понедельник 7 — воскресенье;
- MM, ДД и ЧЧ — указываются с двух десятичных цифр.
Точка означает все возможные значения, выражение в скобках (A|B|C) — означает один из трех вариантов, выражение в квадратных скобках 5 означает диапазон (от 1 до 5).
Например, чтобы выполнять полную проверку жесткого диска linux каждый рабочий день в час дня добавьте опцию -s в строчку конфигурации вашего устройства:
/dev/sda -m myemail@mydomain.com -M once -s (L /../../1/13)
Если вы хотите чтобы утилита сканировала и проверяла все устройства, которые есть в системе используйте вместо имени устройства директиву DEVICESCAN:
DEVICESCAN -m myemail@mydomain.com -M once -s (L /../../2/13)
Проверка диска на ошибки в GUI
В графическом интерфейсе тоже можно посмотреть информацию из SMART. Для этого можно воспользоваться приложением Gnome Диски, откройте его из главного меню, выберите нужный диск, а затем кликните по пункту Данные самодиагностики и SMART в контекстном меню:

В открывшемся окне вы увидите те же данные диагностики SMART, а также все атрибуты SMART и их состояние:

Выводы
Если вы хотите быстро проверить механическую работу жесткого диска, посмотреть его физическое состояние или выполнить более-менее полное сканирование поверхности диска используйте smartmontools. Не забывайте выполнять регулярное сканирование, потом будете себя благодарить. Вы уже делали это раньше? Будете делать? Или используете другие методы? Напишите в комментариях!

Оцените статью:
Об авторе
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
9 комментариев
Вы слишком замудрили в данной статье. Легче написать smartctl —scan и всё сразу видно.
И ещё у меня такую ошибку выдало Error 4324 occurred at disk power-on lifetime: 15035 hours (626 days + 11 hours)
А куда обращатся непонятно.
Подскажите пожалуйста, можно ли получить карту диска, наподобие таковой в виктории, программой под линукс?
Не знаю такой, как вариант после проверки диска командой:
ddrescue -n -f /dev/sdX /dev/null file.log
или после клонирования на другое устройство можно посмотреть графическую карту с помощью:
ddrescueview file.log
Консольный вариант: ddrescuelog -t file.log
whdd наверное хорошо, только deb пакетов нет, а из исходников не собирается.
hard disk sentinel через ./ запустил и окей
Здравствуйте!
У меня получается непонятка.
По smart характеристикам диск хороший,
но после запуска самотестирования выдает ошибки чтения в одних и тех же секторах
Что это значит?
счас приведу выхлоп
sudo smartctl —all /dev/sda
.
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always — 0
2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline — 0
3 Spin_Up_Time 0x0027 100 100 001 Pre-fail Always — 1795
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always — 3920
5 Reallocated_Sector_Ct 0x0033 100 100 050 Pre-fail Always — 0
7 Seek_Error_Rate 0x000b 100 100 050 Pre-fail Always — 0
8 Seek_Time_Performance 0x0005 100 100 050 Pre-fail Offline — 0
9 Power_On_Hours 0x0032 074 074 000 Old_age Always — 10664
10 Spin_Retry_Count 0x0033 178 100 030 Pre-fail Always — 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always — 3627
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always — 372
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always — 67
193 Load_Cycle_Count 0x0032 096 096 000 Old_age Always — 49523
194 Temperature_Celsius 0x0022 100 100 000 Old_age Always — 36 (Min/Max 7/47)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always — 0
197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always — 272
198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline — 7
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always — 0
220 Disk_Shift 0x0002 100 100 000 Old_age Always — 0
222 Loaded_Hours 0x0032 076 076 000 Old_age Always — 9681
223 Load_Retry_Count 0x0032 100 100 000 Old_age Always — 0
224 Load_Friction 0x0022 100 100 000 Old_age Always — 0
226 Load-in_Time 0x0026 100 100 000 Old_age Always — 266
240 Head_Flying_Hours 0x0001 100 100 001 Pre-fail Offline — 0
в то же время внутренний лог говорит о фиксации 79 ошибок:
SMART Error Log Version: 1
ATA Error Count: 79 (device log contains only the most recent five errors)
а вот результаты самотестирования, которые я запускал:
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Selective offline Completed: read failure 00% 10662 516606384
# 2 Selective offline Completed: read failure 00% 10662 516606376
# 3 Selective offline Completed: read failure 00% 10662 516606376
# 4 Selective offline Completed: read failure 00% 10662 516606368
# 5 Selective offline Completed: read failure 00% 10662 516606368
# 6 Selective offline Completed: read failure 00% 10661 164354232
# 7 Selective offline Completed without error 00% 10661 —
# 8 Selective offline Completed: read failure 00% 10661 102832
# 9 Selective offline Completed: read failure 00% 10660 100296
#10 Short offline Completed: read failure 00% 10660 100296
#11 Selective offline Completed without error 00% 10660 —
#12 Short offline Completed: read failure 00% 10659 100296
#13 Extended offline Completed: read failure 00% 10371 100296
#14 Extended offline Aborted by host 90% 10367 —
#15 Short offline Completed: read failure 00% 10367 100296
#16 Short offline Completed: read failure 00% 10367 100296
#17 Short offline Completed: read failure 00% 10363 100296
#18 Short offline Completed: read failure 00% 10363 100296
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 516606384 1953525160 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
из них видно куча bad секторов, а смарт атрибуты(выше) говорят что все ок.
Что это означает, не подскажете?
Источник



