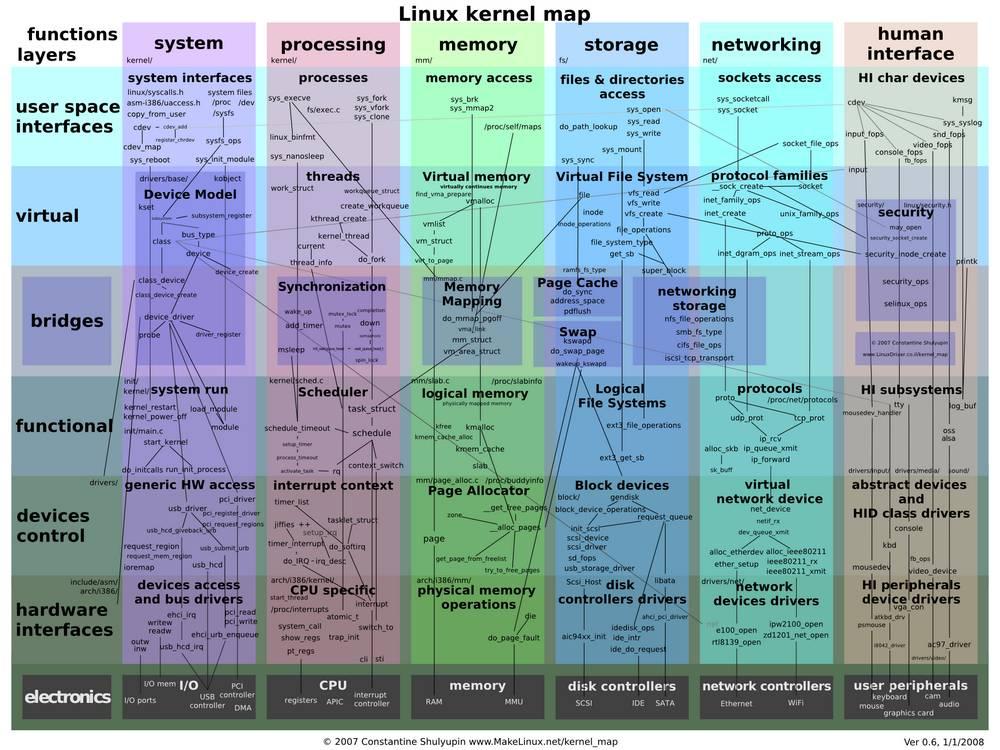
Linux Kernel: How Does it Work and What Version to Use
Normally, when we talk about Linux, we usually do it in relation to distributions such as Ubuntu, Debian, Mint, etc. However, these distributions are not operating systems as such, but rather are “adaptations” of an open source operating system: Linux. And, therefore, despite the peculiarities of each one, they all share the same base, what we know as Linux Kernel .
Linux, as its own documentation indicates, was born as a clone of another operating system called Unix. Specifically as an alternative system inspired by Minix (which, in turn, cloned the concepts of Unix). Due to its properties, Linux is a real operating system, although nobody uses it as such, but rather uses distributions since, with them, it becomes much more useful and easy to use.
For this reason, it is not usually said ” I am going to install Linux ” referring to a specific operating system, but rather that what we install are versions, or distributions, of this kernel, created by companies or by the community, that share the same base: the Kernel.
What is the kernel and what is it for
The Linux kernel is the core of the operating system . This is the most important piece of software in any operating system. Windows has its own private kernel, Apple has its own (based on Unix, by the way), and Linux is the kernel used by all distributions. And its main function is to be in charge of controlling the computer hardware.
Specifically, this kernel is responsible for managing system memory and process time , managing all processes , controlling system calls and connections between processes and allowing all software to have access to the hardware , especially the connected peripherals. to the computer.
The kernel is so important when controlling hardware that, of its more than 28 million lines of code, most of it is drivers. And this, while good for compatibility, is starting to be a problem for performance.
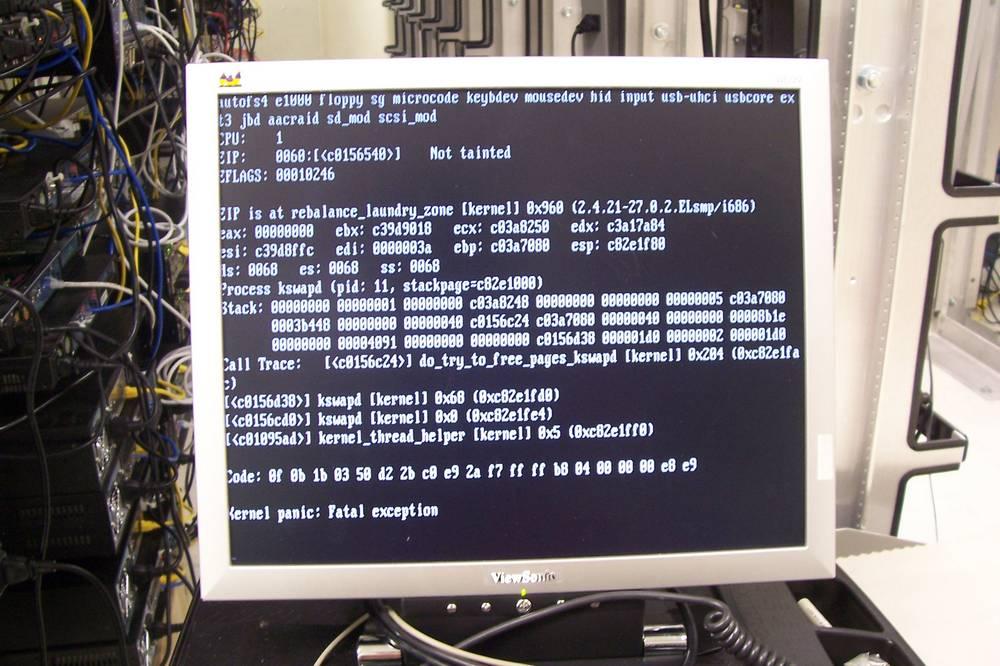
Under normal conditions, users never interact with it . While users have limited access to hardware, the kernel has full access and control over it. He is responsible for ensuring that everything works well, that it is done safely, and that there are no errors. If a process crashes in user space, Linux continues to function . And you can even try to recover the system by having control over the PC. However, if an error occurs in kernel space, then the whole system stops working. It is what we know as the ” Kernel Panic “, the equivalent of the blue screen in Linux.
Versions
It is true that the current versions of the kernel have nothing to do with the first ones from 1991. However, this kernel is in constant development. And every few weeks we usually see new releases. But not all are equally important, since it depends to a great extent on their numbering.
Linux kernel versions can have 4 numbers indicating the version: abcd
- a indicates the version. This number is the one that changes the least, since the jump is usually only made when there are extremely large changes in the system. In all its history, it has only changed 5 times, in 2004, for version 1.0, in 2006, for version 2.0, in 2011, for version 3.0, in 2015, for version 4.0, and in 2019 to give rise to the current version, 5.0.
- b indicates subversion. When new versions are released, but they are really minor updates (new drivers, optimizations, fixes, etc), then instead of changing the version, the subversion number is changed.
- c indicates the revision level . This number is often changed, for example when minor changes are made, such as security patches, bug fixes, etc.
- d is the last sublevel of the version. It is hardly used, but it is reserved so that, if a version with a very serious bug is released, the new version is released with this sublevel including exclusively the correction of said serious bug.
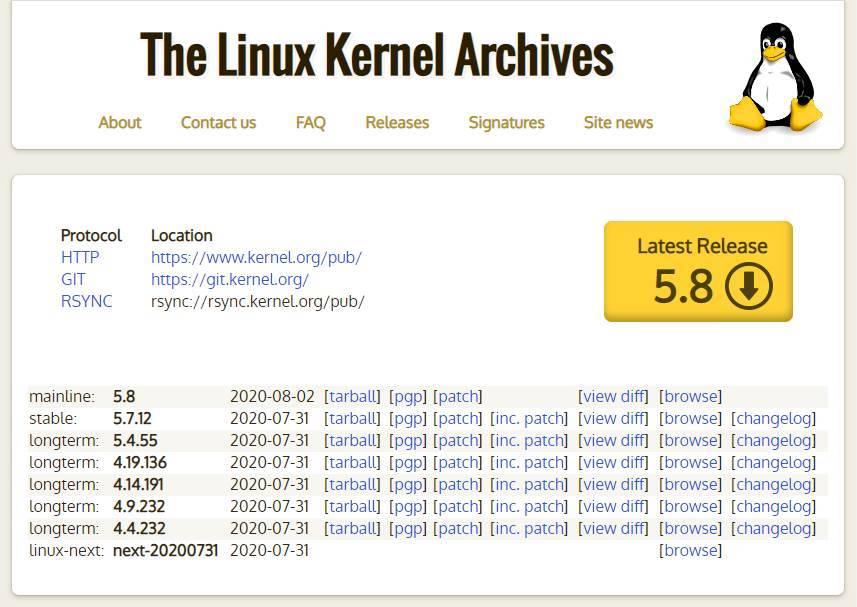
All versions of the Linux kernel are public and open source. We can find them in this link . But they are not compiled, rather it is the users themselves who have to compile them to be able to use them in their distribution. And this is not exactly a simple task. Luckily, the communities responsible for the development of the different distributions usually bring us compiled and optimized versions of the Kernel, which we can install as any patch.
Which version of Linux to choose
When we talk about software, we always recommend having the latest version of everything. This is the best way to ensure that, due to a security breach, our PC is endangered. With the Linux kernel it is the same, it is always recommended to have the latest version. However, you always have to do it carefully.

One of the reasons the kernel is so big is because it doesn’t remove anything. As old as it is. Thanks to this, it is possible to continue using the latest versions of Linux on the first computers where it was launched for the first time in 1991. Each update what it usually does is add drivers and change functions to optimize the general operation of the PC.
But it may happen that a version brings a bug that makes our PC not work properly, and even that the performance is not as expected. In that case, simply reinstalling a previous version should bring the operating system back to normal. Although we will lose support for the newer hardware components.
The best, and easiest for most, is to update the Kernel as we update the distribution from its repositories. Thus we will avoid these problems by “always being up to date”.
Is the kernel the operating system?
The kernel is one of the most important parts of the operating system. But it is not the only one necessary to be able to call Linux, today, an operating system as such. As we have explained, this kernel has all the drivers and everything necessary to control the software and allow the user to access it. But, to be really useful, it must have other components on top of it before reaching the user.
- Demon controller . Whether Init.d, Systemd, or any other similar software, it is necessary to have a subsystem above the kernel that is responsible for starting all the processes (daemons) necessary for the Kernel to start working. Without it we only have many lines of code that will not be executed.
- The processes . Daemons, daemons, or better known as processes, are all the components that remain loaded in the system memory (controlled by the kernel) and that allow Linux to function. The graphical server, for example, is the daemon that will control the desktop.
- Graphic server . Known as X, it is in charge of being able to see the graphics on the screen. If we are going to use Linux in text mode, from the terminal, it is not necessary. But if we are going to use it with a desktop, it is necessary to have a working x-server.
- Desk. As its name suggests, the computer desktop, where we will have all our programs and where the windows will open. There are many desktops for Linux, such as GNOME, KDE, or LXDE. Each one with its own characteristics, advantages and disadvantages.
- Programs. Everything we run from the desktop. It is already the highest layer, and the point through which we interact with the computer.
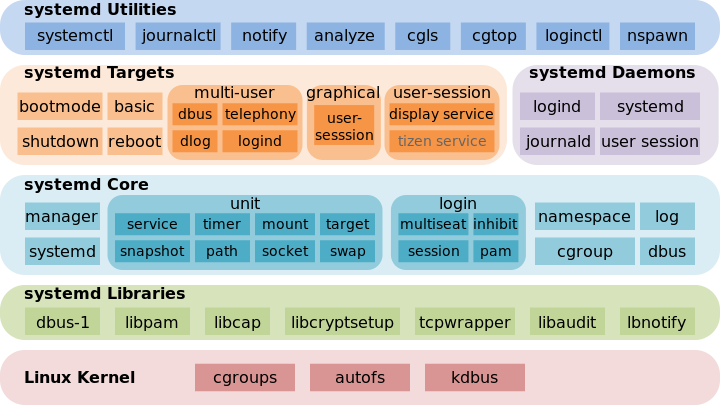
When the kernel, and everything else, works in accordance, that is when we can talk about the operating system. Or what is the same, Linux distribution .
Источник
To talk about linux
I believe that many children’s shoes working on the Linux platform are familiar with the pipe symbol’|’. Through it, we can flexibly combine several different commands to complete a task. It is like the following command:
But this time let’s not talk about these usages, but to discuss some more interesting ones, that is, the «real-time performance» of the data flow on both sides of the pipeline and the tips for the use of the pipeline.
In fact, when we are using pipelines, we may inadvertently think about whether the output of my previous command is all processed and then passed to the second command through the pipeline, or is it output while processing it? Maybe it is in the experiment or In work experience, it should be that all the commands on the left are processed and then handed over to the commands on the right for processing at one time.Not only everyone, but when I first contacted the pipeline, I also had such a misunderstanding, because we saw this through the phenomenon.
But in fact, as long as you have a simple understanding of the pipeline tool, it should not be difficult to explain:
The pipeline is performed at the same time on both sides, that is, the command on the left is output to the pipeline, and the right of the pipeline will be processed immediately.
Definition of pipeline
A pipe is a buffer managed by the kernel, which is equivalent to a piece of paper we put in memory. One end of the pipe is connected to the output of a process. This process will put information into the pipeline. The other end of the pipe is connected to the input of a process, and this process takes the information that was put into the pipe. A buffer does not need to be large, it is designed as a ring data structure so that the pipeline can be recycled. When there is no information in the pipe, the process reading from the pipe will wait until the process at the other end puts the information. When the pipe is full of information, the process trying to put the information will be blocked until the process at the other end takes out the information. When both processes are terminated, the pipeline automatically disappears.
Pipeline workflow

As can be seen from the above explanation, assuming COMMAND1 | COMMAND2, then the standard output of COMMAND1 will be bound to the write end of the pipe, and the standard input of COMMAND2 will be bound to the read end of the pipe, so when COMMAND1 has The output will be passed to COMMAND2 through the pipeline immediately, let’s do an experiment to verify it:
In the above command, we can guess the output result: after sleeping for 6 seconds, output «1111222», or output «1111» sleep for 3 seconds, output «2222», then sleep for 3 seconds, output «1111» What? The answer is: No! what! This is impossible, you can try it, we will see that the terminal does not respond, why? This is about the buffering method of file IO, for file IO, please refer to me Another article by: Talking about file descriptors 1 and 2, mention three buffering methods of file IO at the bottom:
- Full buffering: The system I/O function is not called until the buffer is filled, (usually for files)
- Line buffering: output when a newline character is encountered (standard output)
- Unbuffered: Without a buffer, the data will be immediately read or output to the external storage file and device (standard error
Because python uses buffered fputs by default (refer to the py27 source code: fileobject.c: PyFile_WriteString function), and because the standard output is rewritten to the pipeline, it will adopt a fully buffered method (the shell command depends on the implementation, because some are Use write without buffering, if there is no buffer, it will be written directly to the pipeline), so the full buffering method will be adopted, that is, until the buffer is filled, or the flush is manually displayed, it can be read To the output. Then we can rewrite the code into the following two ways
Here we have been able to get the result. If, as we thought before, we have to wait until COMMAND1 is completely executed before outputting it to COMMAND2 at one time, then the result should be infinitely blocked.. Because my program has not been executed.. It should be inconsistent with the original intention of the older generations, because this may cause the pipeline to become larger and larger. However, the pipeline also has a size
You can see the posix standard for details, so we conclude that: as long as the output of COMMAND1 is written At the write end of the pipeline (whether the buffer is full or manual flush), COMMAND2 will get the data immediately and process it immediately.
Then the discussion of the «real-time nature» of the data flow on both sides of the pipeline will come to an end. Next, we will continue the discussion on this basis: Tips for using the pipeline.
Before starting the discussion, I want to introduce a technical term, which we occasionally encounter, that is: SIGPIPE
Or a more specific description: broken pipe (broken pipe)
The above technical terms are closely related to the pipe read and write rules. Let’s take a look at the pipe read and write rules:
1. When there is no data to read
- O_NONBLOCK (not set): The read call is blocked, that is, the process suspends execution and waits until data arrives.
- O_NONBLOCK (set): The read call returns -1, and the errno value is EAGAIN.
2. When the pipeline is full
- O_NONBLOCK (not set): The write call is blocked until a process reads the data
- O_NONBLOCK (set): the call returns -1, the errno value is EAGAIN
3. If all file descriptors corresponding to the write end of the pipe are closed, read returns 0
4. If all file descriptors corresponding to the read end of the pipe are closed, the write operation will generate the signal SIGPIPE
5. When the amount of data to be written is not greater than PIPE_BUF, linux will guarantee the atomicity of writing.
6. When the amount of data to be written is greater than PIPE_BUF, Linux will no longer guarantee the atomicity of writing.
As we can see above, if we receive the SIGPIPE signal, then the general situation is that the reading end is closed, but the writing end still tries to write
Let’s reproduce SIGPIPE
The execution of the command this time needs to test the hand speed, because we have to kill the reader process before py wakes up
From the above figure, we can verify two points:
- When we kill the reader, the writer will receive SIGPIPE and exit by default, and the pipeline ends
- When we kill the read end, the program on the write end will not receive SIGPIPE immediately, on the contrary, this error will only be triggered when the write end of the pipeline is actually written
If you write to a pipe that has been closed on the read end, you will receive a SIGPIPE, what about reading a pipe that has been closed on the write end?
The above-mentioned read and write rules have also been proved above: If all the file descriptors corresponding to the write end of the pipe are closed, an EOF end flag will be generated, read returns 0, and the program exits.
to sum up
Through the above theories and experiments, we know that when using the pipeline, the data transmission process of the commands on both sides, as well as the preliminary understanding of the pipeline read and write rules, hope that we can be more confident when we work and contact the pipeline in the future. Take advantage of this powerful tool.
Источник



